SQL en Pandas con Pandasql
SQL en Pandas Cómo utilizar pandasql para análisis de datos

Si solo puedes agregar una habilidad, y sin argumento el más importante, en tu caja de herramientas de ciencia de datos, es SQL. En el ecosistema de análisis de datos en Python, sin embargo, pandas es una biblioteca poderosa y popular.
Pero, si eres nuevo en pandas, aprender a usar las funciones de pandas, como agrupación, agregación, uniones y más, puede resultar abrumador. Sería mucho más fácil hacer consultas a tus dataframes con SQL en su lugar. La biblioteca pandasql te permite hacer precisamente eso.
Así que aprendamos a usar la biblioteca pandasql para ejecutar consultas SQL en un dataframe de pandas con un conjunto de datos de muestra.
- VoAGI Noticias, 5 de octubre 5 libros gratuitos para ayudarte a dominar Python • Los 7 mejores cuadernos de nube gratuitos para Ciencia de Datos
- Combatir la suplantación de identidad por la IA
- ¿Qué tan cerca estamos de la IA generalizada?
Primeros pasos con Pandasql
Antes de continuar, prepararemos nuestro entorno de trabajo.
Instalando pandasql
Si estás usando Google Colab, puedes instalar pandasql usando `pip` y seguir el código:
pip install pandasql
Si estás utilizando Python en tu máquina local, asegúrate de tener instalados pandas y Seaborn en un entorno virtual dedicado para este proyecto. Puedes usar el paquete integrado venv para crear y administrar entornos virtuales.
Ejecutaré Python 3.11 en Ubuntu LTS 22.04. Por lo tanto, las siguientes instrucciones son para Ubuntu (también deberían funcionar en Mac). Si estás en una máquina con Windows, sigue estas instrucciones para crear y activar entornos virtuales.
Para crear un entorno virtual (v1 aquí), ejecuta el siguiente comando en tu directorio de proyectos:
python3 -m venv v1
Luego, activa el entorno virtual:
source v1/bin/activate
Ahora instala pandas, seaborn y pandasql:
pip3 install pandas seaborn pandasql
Nota: Si aún no tienes `pip` instalado, puedes actualizar los paquetes del sistema e instalarlo ejecutando: apt install python3-pip.
La función `sqldf`
Para ejecutar consultas SQL en un dataframe de pandas, puedes importar y usar sqldf con la siguiente sintaxis:
from pandasql import sqldfsqldf(query, globals())
Aquí,
queryrepresenta la consulta SQL que deseas ejecutar en el dataframe de pandas. Debe ser una cadena que contenga una consulta SQL válida.globals()especifica el espacio de nombres global donde se definen los dataframe(s) utilizados en la consulta.
Consulta de un dataframe de pandas con Pandasql
Comencemos importando los paquetes necesarios y la función sqldf de pandasql:
import pandas as pdimport seaborn as snsfrom pandasql import sqldf
Como ejecutaremos varias consultas en el dataframe, podemos definir una función para llamarla pasando la consulta como argumento:
# Define una función reutilizable para ejecutar consultas SQLrun_query = lambda query: sqldf(query, globals())
Para todos los ejemplos que siguen, vamos a ejecutar la función run_query (que utiliza sqldf() internamente) para ejecutar la consulta SQL en el dataframe tips_df. Luego mostraremos el resultado devuelto.
Cargando el conjunto de datos
Para este tutorial, vamos a usar el conjunto de datos “tips” que se encuentra incorporado en la biblioteca Seaborn. El conjunto de datos “tips” contiene información sobre propinas en restaurantes, incluyendo el total de la cuenta, el monto de la propina, el género del pagador, el día de la semana y más.
Cargar el conjunto de datos “tips” en el dataframe tips_df:
# Cargar el conjunto de datos "tips" en un dataframe de pandas
tips_df = sns.load_dataset("tips")
Ejemplo 1 – Selección de datos
Aquí tenemos nuestra primera consulta: una simple sentencia SELECT:
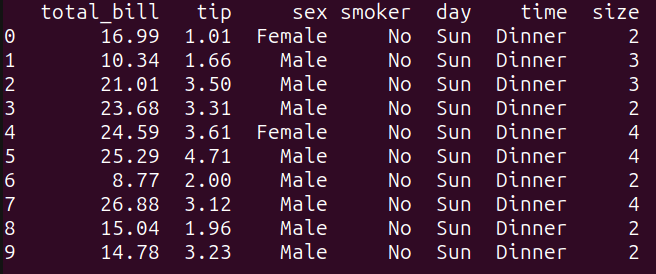
# Consulta de selección simplersult_1 = """SELECT *FROM tips_dfLIMIT 10;"""resultado_1 = run_query(consulta_1)print(resultado_1)
Como se puede ver, esta consulta selecciona todas las columnas del dataframe tips_df y limita el resultado a las primeras 10 filas utilizando la palabra clave `LIMIT`. Es equivalente a ejecutar tips_df.head(10) en pandas:
Ejemplo 2 – Filtrar según una condición
A continuación, vamos a escribir una consulta para filtrar los resultados según condiciones:
# Filtrar según una condición
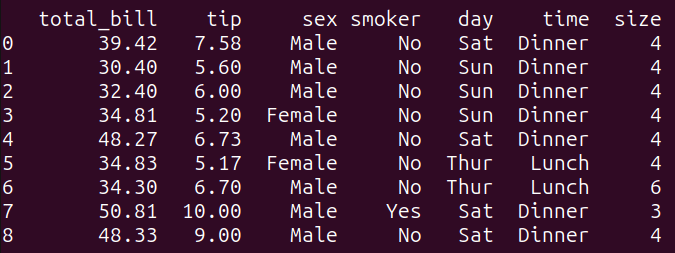
consulta_2 = """SELECT *FROM tips_dfWHERE total_bill > 30 AND tip > 5;"""resultado_2 = run_query(consulta_2)print(resultado_2)
Esta consulta filtra el dataframe tips_df según la condición especificada en la cláusula WHERE. Se seleccionan todas las columnas del dataframe tips_df donde el valor de ‘total_bill’ es mayor a 30 y el valor de ‘tip’ es mayor a 5.
Al ejecutar consulta_2, se obtiene el siguiente resultado:
Ejemplo 3 – Agrupación y agregación
Vamos a ejecutar la siguiente consulta para obtener el promedio del monto de la cuenta agrupado por día:
# Agrupación y agregación
consulta_3 = """SELECT day, AVG(total_bill) as promedio_cuenta FROM tips_df GROUP BY day;"""resultado_3 = run_query(consulta_3)print(resultado_3)
Aquí está el resultado:
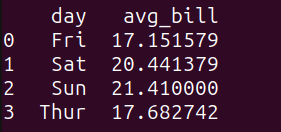
Podemos observar que el monto promedio de la cuenta los fines de semana es ligeramente mayor.
Veamos otro ejemplo de agrupación y agregaciones. Considera la siguiente consulta:
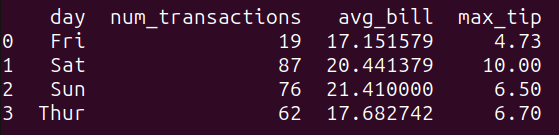
consulta_4 = """SELECT day, COUNT(*) as num_transacciones, AVG(total_bill) as promedio_cuenta, MAX(tip) as max_propina FROM tips_df GROUP BY day;"""resultado_4 = run_query(consulta_4)print(resultado_4)
La consulta consulta_4 agrupa los datos del dataframe tips_df por la columna ‘day’ y calcula las siguientes funciones agregadas para cada grupo:
num_transacciones: el número de transacciones,promedio_cuenta: el promedio de la columna ‘total_bill’, ymax_propina: el valor máximo de la columna ‘tip’.
Como se muestra, obtenemos las cantidades anteriores agrupadas por día:
Ejemplo 4 – Subconsultas
Agreguemos una consulta de ejemplo que utilice una subconsulta:
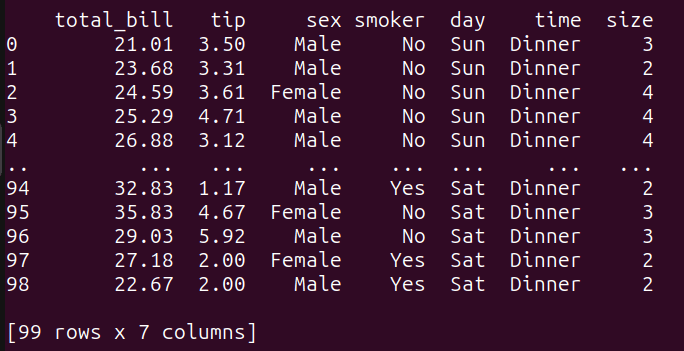
# subconsultasquery_5 = """SELECT *FROM tips_dfWHERE total_bill > (SELECT AVG(total_bill) FROM tips_df);"""result_5 = run_query(query_5)print(result_5)Aquí,
- La subconsulta interna calcula el valor promedio de la columna ‘total_bill’ del dataframe
tips_df. - La consulta externa luego selecciona todas las columnas del dataframe
tips_dfdonde ‘total_bill’ es mayor que el valor promedio calculado.
Ejecutar consulta_5 da lo siguiente:
Ejemplo 5 – Unir dos DataFrames
Solo tenemos un dataframe. Para realizar una unión simple, creemos otro dataframe de la siguiente manera:
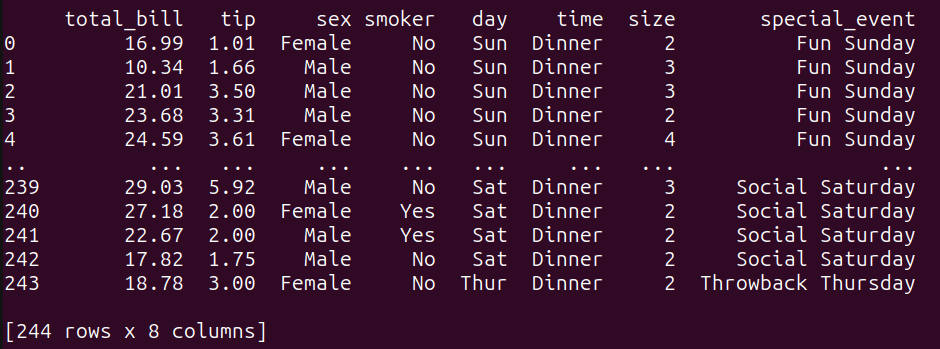
# Crear otro DataFrame para unir con tips_dfother_data = pd.DataFrame({ 'day': ['Thur','Fri', 'Sat', 'Sun'], 'special_event': ['Throwback Thursday', 'Feel Good Friday', 'Social Saturday','Fun Sunday', ]})El dataframe other_data asocia cada día con un evento especial.
Ahora realicemos un LEFT JOIN entre los dataframes tips_df y other_data en la columna ‘day’ común:
query_6 = """SELECT t.*, o.special_eventFROM tips_df tLEFT JOIN other_data o ON t.day = o.day;"""result_6 = run_query(query_6)print(result_6)Aquí está el resultado de la operación de unión:
Resumen y Próximos Pasos
En este tutorial, repasamos cómo ejecutar consultas SQL en dataframes de pandas utilizando pandasql. Aunque pandasql facilita la consulta de dataframes con SQL, tiene algunas limitaciones.
La limitación clave es que pandasql puede ser varias órdenes más lento que pandas nativo. Entonces, ¿qué deberías hacer? Bueno, si necesitas realizar análisis de datos con pandas, puedes usar pandasql para consultar dataframes cuando estás aprendiendo pandas y avanzando rápidamente. Luego puedes cambiar a pandas u otra biblioteca como Polars una vez que te sientas cómodo con pandas.
Para dar los primeros pasos en esta dirección, intenta escribir y ejecutar los equivalentes de pandas de las consultas SQL que hemos ejecutado hasta ahora. Todos los ejemplos de código utilizados en este tutorial se encuentran en GitHub. ¡Sigue programando! Bala Priya C es una desarrolladora y escritora técnica de India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir su conocimiento con la comunidad de desarrolladores mediante la redacción de tutoriales, guías prácticas, artículos de opinión y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Revelando patrones ocultos Una introducción al agrupamiento jerárquico
- Maximizar el rendimiento en aplicaciones de IA de borde
- La Inteligencia Artificial está controlando la lucha contra el robo de paquetes de UPS
- Dispositivo óptico portátil muestra promesa para detectar hemorragias postparto
- Vínculo de datos de dispositivos portátiles vincula la reducción del sueño y la actividad durante el embarazo con el riesgo de parto prematuro
- Procyon Photonics La startup dirigida por estudiantes de secundaria que podría revolucionar la informática
- ChatGPT ahora puede responder con palabras habladas






