Funciones de Ventana Un conocimiento imprescindible para ingenieros de datos y científicos de datos.
Window Functions Essential knowledge for data engineers and data scientists.
Volviendo a lo básico | Desmitificando las funciones de ventana de SQL

El crecimiento de datos ha sido bastante extenso en los últimos años y aunque tenemos a nuestra disposición un conjunto diverso de herramientas y tecnologías, SQL sigue siendo el núcleo de la mayoría de ellas. Es uno de los lenguajes fundamentales para el análisis de datos y es ampliamente empleado por empresas de todas las escalas para resolver desafíos relacionados con los datos.
Siempre creo que no necesitas conocer ciertos conceptos sólo por el hecho de despejar la entrevista o resolver un problema particular. Si te importa aprender el concepto y la arquitectura subyacente, te ayudará a conquistar cualquier trabajo donde vayas. Las funciones de ventana son un poco complicadas y uno podría sentirse un poco intimidado al principio, pero una vez que las tengas, son muy divertidas de trabajar.
Sería más fácil entender el concepto de las funciones de ventana si estás familiarizado con las funciones de agregación de SQL. Las funciones de agregación realizan el cálculo en un conjunto de valores y devuelven un valor; cuando se emparejan con la cláusula GROUP BY, devuelve un único valor para cada grupo. Puedes leer más al respecto aquí:
- Haz que tus gráficos sean excelentes con UTF-8.
- Haz que cada dólar de marketing cuente con la ciencia de datos.
- Cómo medir el desvío en las incrustaciones de ML
Funciones de agregación de SQL para tu próxima entrevista de Ciencia de Datos
Volviendo a lo básico | Fundamentos de SQL para principiantes
towardsdatascience.com
Antes de continuar, permíteme presentarte la base de datos de muestra. Estaremos utilizando datos de una empresa ficticia de venta de vehículos, puedes encontrar los datos fuente en mi repositorio de GitHub,
¿Qué son las funciones de ventana?
La definición tradicional de una función de ventana es,
Una función de ventana realiza cálculos en un conjunto de filas de tabla que están de alguna manera relacionadas con la fila actual.
Si lo desgloso, las funciones de ventana nos permiten realizar cálculos contra particiones. La partición es simplemente un conjunto, subgrupo o cubo de filas definido por el usuario en el que la función de ventana realizará cálculos.
También son ampliamente conocidas como funciones analíticas.
¿Por qué necesitamos funciones de ventana?
Como sabemos, las funciones de agregación resumen los datos de varias filas en una sola fila (si se usan junto con la cláusula GROUP BY, entonces una sola fila para cada grupo); mientras que, las funciones de ventana también realizan cálculos en un conjunto de filas pero a diferencia de las funciones de agregación, no resumen el conjunto de resultados en una sola fila. En su lugar, todas las filas mantienen su forma/identidad original y se agrega la fila calculada al conjunto de resultados para cada fila.
¿Suena gracioso, eh? Desglosemos esto. Aquí está la muestra de datos de la tabla PRODUCTOS,
--query tabla PRODUCTOSSELECT * FROM PRODUCTOS LIMIT 10;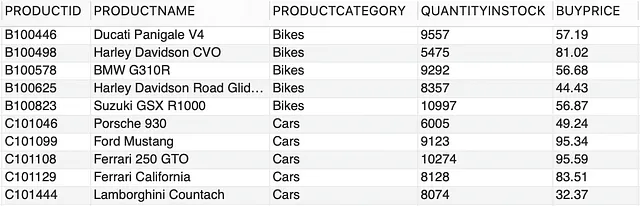
Supongamos que necesitamos información sobre el precio medio de compra para cada CATEGORÍA DE PRODUCTOS,
--precio medio de compra para cada categoría de productoSELECT CATEGORÍA DE PRODUCTOS, FORMAT(AVG(PRECIO DE COMPRA),2) COMO PRECIO MEDIO DE COMPRAFROM PRODUCTOSGROUP BY CATEGORÍA DE PRODUCTOS;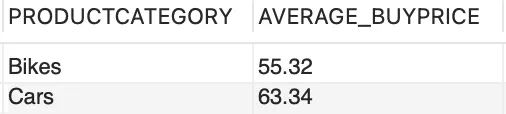
Ahora, esta información por sí sola no sería de mucha utilidad. ¡Sí! Ahora sabes el precio medio de compra para cada CATEGORÍA DE PRODUCTOS, pero ¿qué sigue? ¿Cómo produce esta información una visión empresarial? ¿Qué pasa si quiero comparar el precio de compra de cada producto con el precio medio de compra de la CATEGORÍA DE PRODUCTOS en particular? Permíteme reformular mi nueva necesidad,
- Mostrar el precio de compra de cada producto dentro de la CATEGORÍAPRODUCTO junto con el precio promedio de compra para esa CATEGORÍAPRODUCTO.
- Organizar el conjunto de resultados agrupado por CATEGORÍAPRODUCTO.
¿Serías capaz de lograr esto con solo funciones agregadas normales? El requisito establecido anteriormente quiere mostrar cierta información tal como está (por ejemplo, CATEGORÍAPRODUCTO, NOMBREPRODUCTO, PRECIOCOMPRA en la forma original) y además quiere una nueva columna que muestre el precio promedio de compra para cada CATEGORÍAPRODUCTO también. Ahí es donde la heroica función de ventana viene al rescate,
--usando función de ventanaSELECT CATEGORÍAPRODUCTO, NOMBREPRODUCTO, PRECIOCOMPRA, FORMAT(AVG(PRECIOCOMPRA) OVER (PARTITION BY CATEGORÍAPRODUCTO),2) COMO PRECIOCOMPRA_PROMEDIOFROM PRODUCTOS; 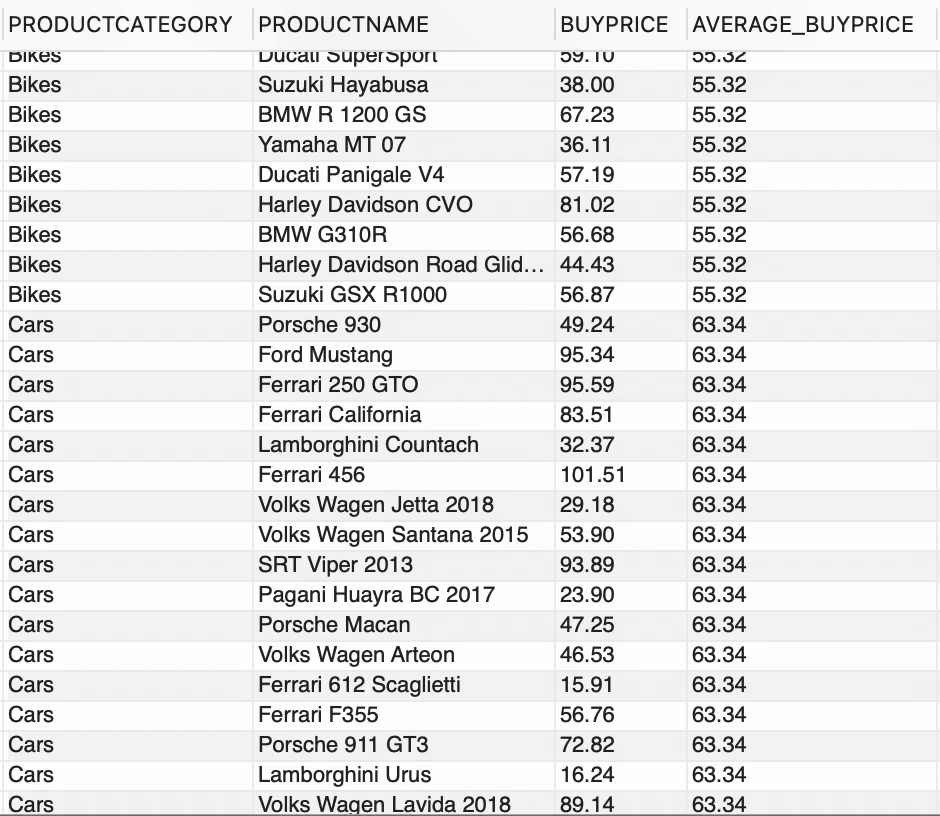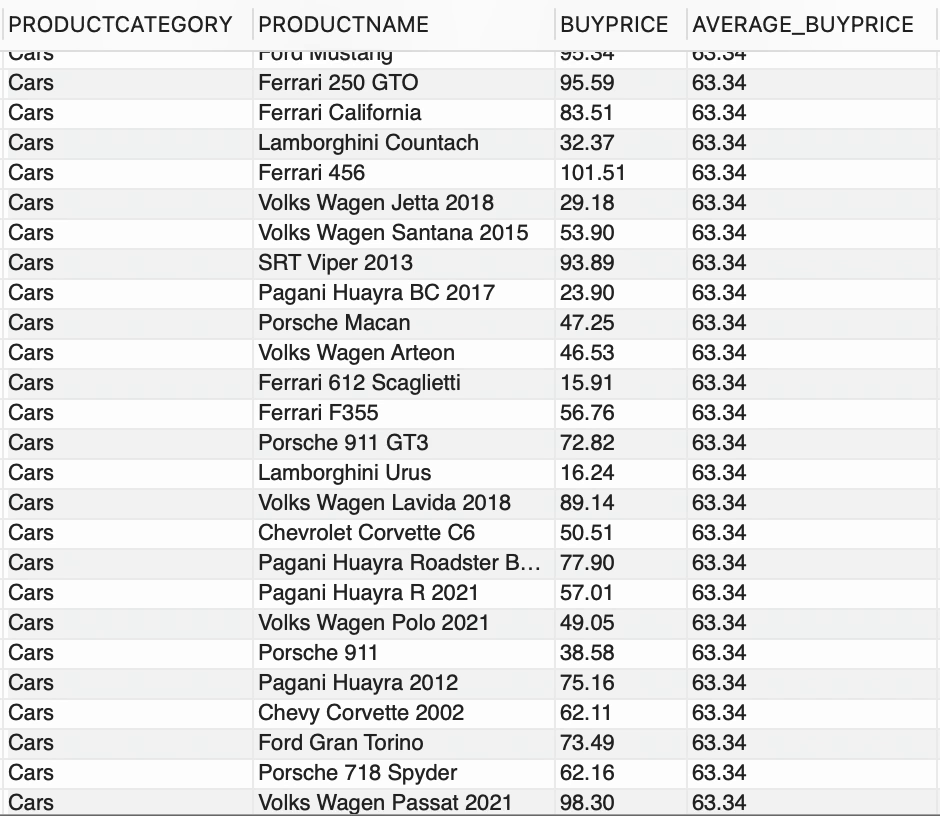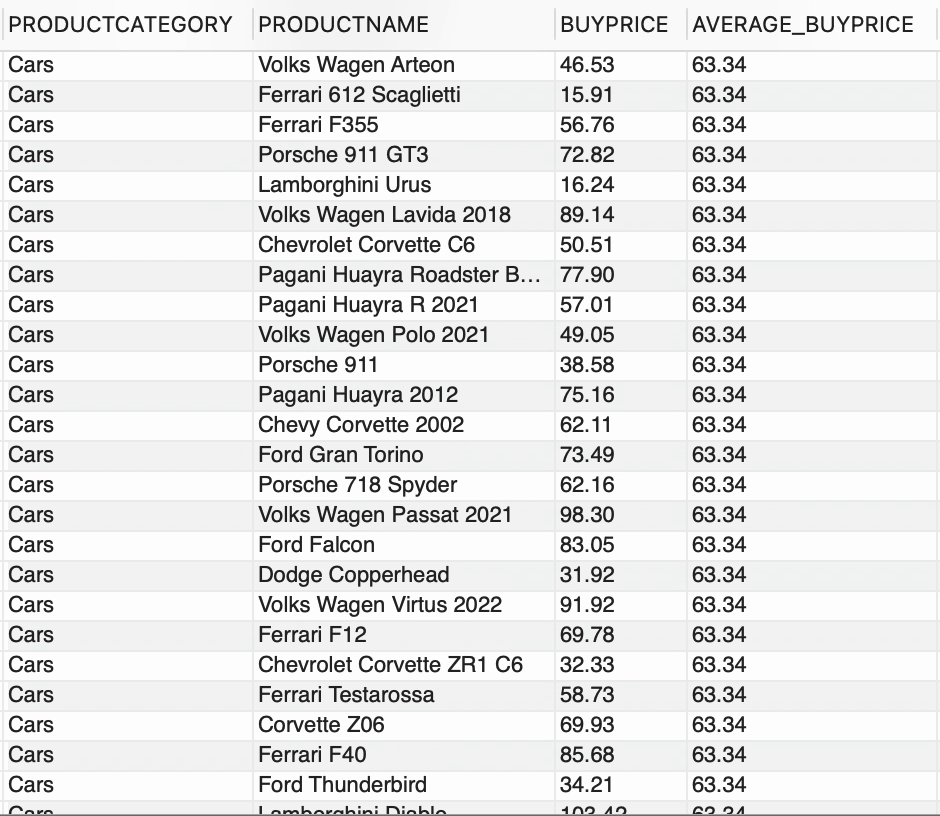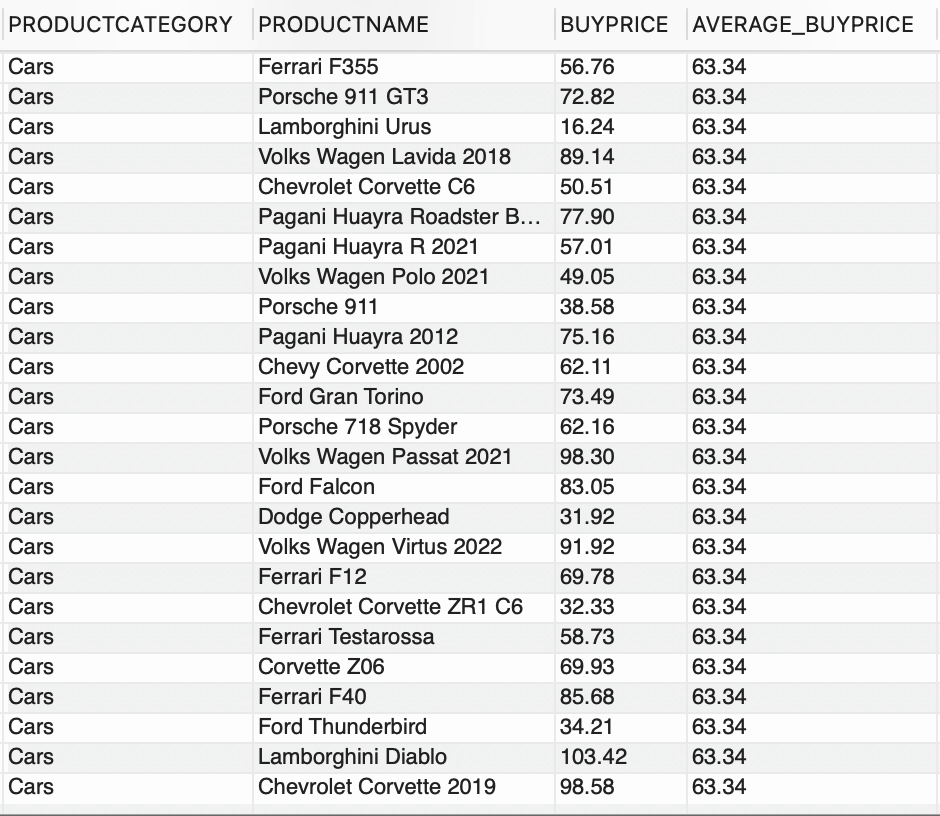
Antes de pasar a las funciones de ventana comúnmente utilizadas, entendamos la sintaxis básica y las cláusulas asociadas.
La sintaxis general de una función de ventana es,

Donde,
- OVER() define un conjunto de filas específico para el usuario. Una función de ventana realiza un cálculo solo en ese conjunto específico. Se utiliza específicamente con funciones de ventana; sin embargo, también se puede utilizar con funciones agregadas, al igual que lo usamos con la función AVG() anterior, y al hacerlo, lo convertimos en una función de ventana. Si no proporciona nada dentro de OVER(), la función de ventana se aplicará a todo el conjunto de resultados.
- PARTITION BY se utiliza con la cláusula OVER. Divide el conjunto de resultados de la consulta en particiones y luego la función de ventana se aplica a cada partición. Es opcional, por lo que si no especifica la cláusula PARTITION BY, la función trata todas las filas como una sola partición.
- La cláusula ORDER BY se utiliza para ordenar el conjunto de resultados en orden ascendente o descendente dentro de cada partición del conjunto de resultados. Por defecto, es en orden ascendente.
- ROWS/RANGE es parte de la cláusula FRAME que define un subconjunto dentro de la partición.
Puede leer una comparación detallada de las funciones de ventana vs funciones agregadas y las cláusulas de las funciones de ventana aquí, Anatomía de las funciones de ventana SQL.
Ahora que estamos familiarizados con la anatomía básica de una función de ventana, exploremos la más comúnmente utilizada,
ROW_NUMBER()
ROW_NUMBER() asigna un número entero secuencial a cada fila de una tabla o una partición en caso de que estemos usando la cláusula PARTITION BY. La sintaxis común es,
ROW_NUMBER() OVER ([cláusula PARTITION BY] [cláusula ORDER BY])
Aquí está la muestra de datos de la tabla PRODUCTOS, contiene los datos de una variedad de productos disponibles en el minorista de vehículos.
--consulta de la tabla PRODUCTOSSELECT * FROM PRODUCTOS LIMIT 10;Comencemos básico,
--asigna un número de fila a cada fila en una tablaSELECT *, ROW_NUMBER() OVER() AS ROW_NUMFROM PRODUCTOS;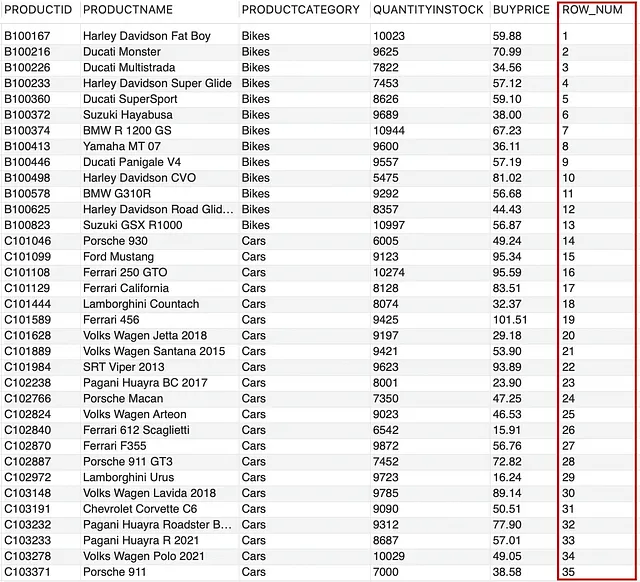
Aquí, ROW_NUMBER() ha asignado un número entero secuencial comenzando desde 1 a cada fila de la tabla PRODUCTOS. Subámoslo un poco agregando números de fila para cada CATEGORÍAPRODUCTO, para eso tendremos que usar la cláusula PARTITION BY.
--número de fila por CATEGORÍAPRODUCTOSELECT *, ROW_NUMBER() OVER(PARTITION BY CATEGORÍAPRODUCTO) AS ROW_NUMFROM PRODUCTOS;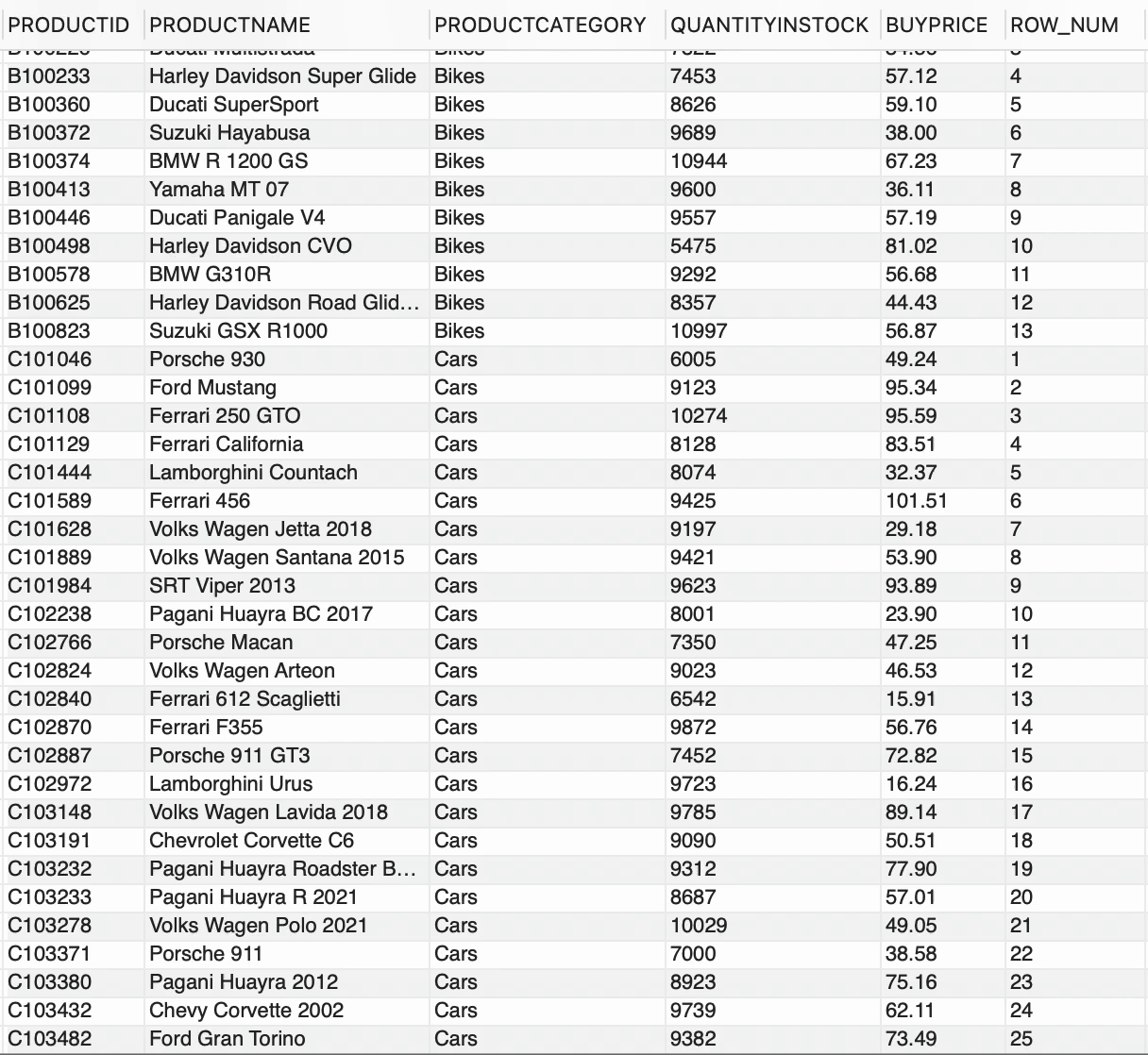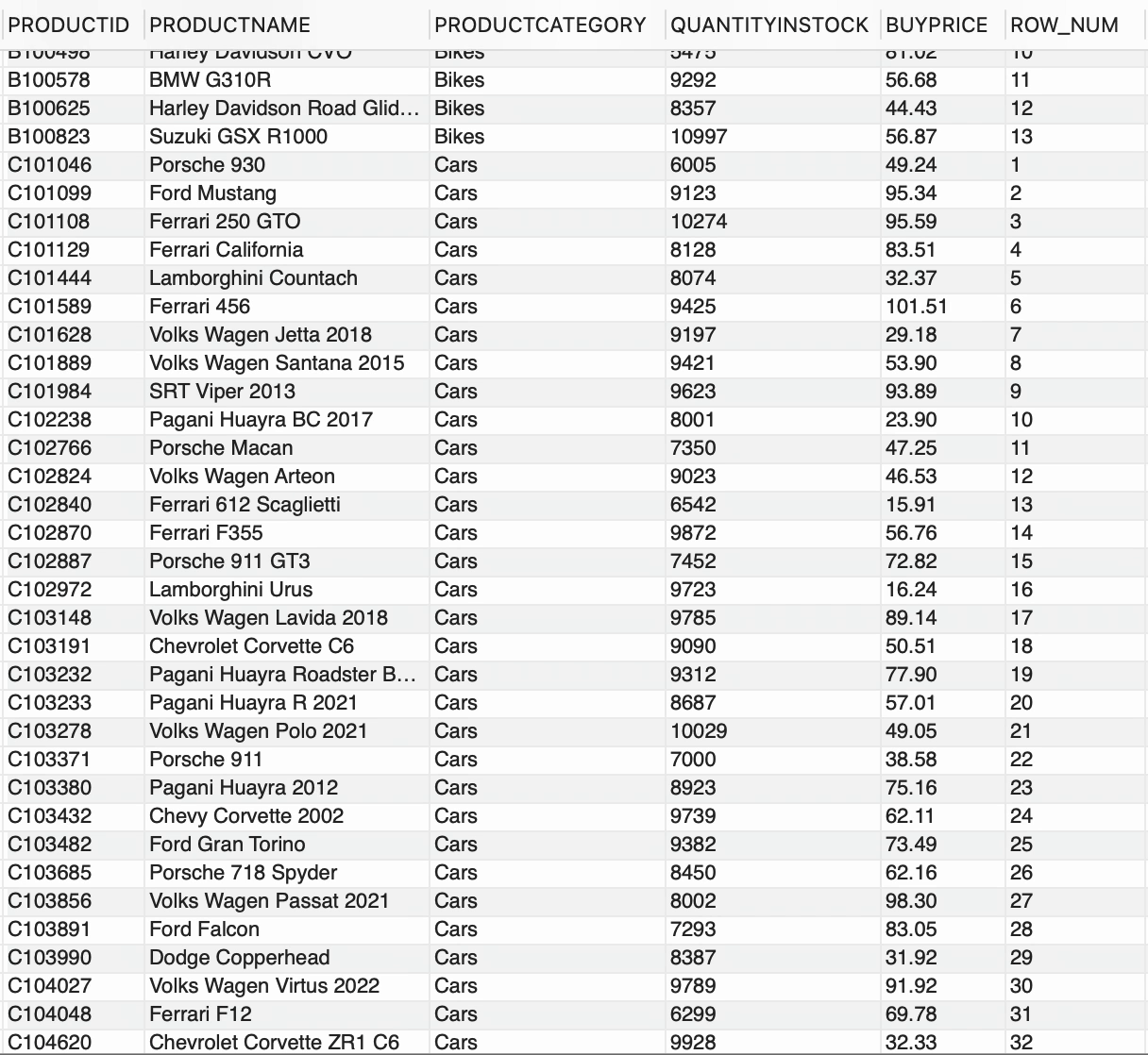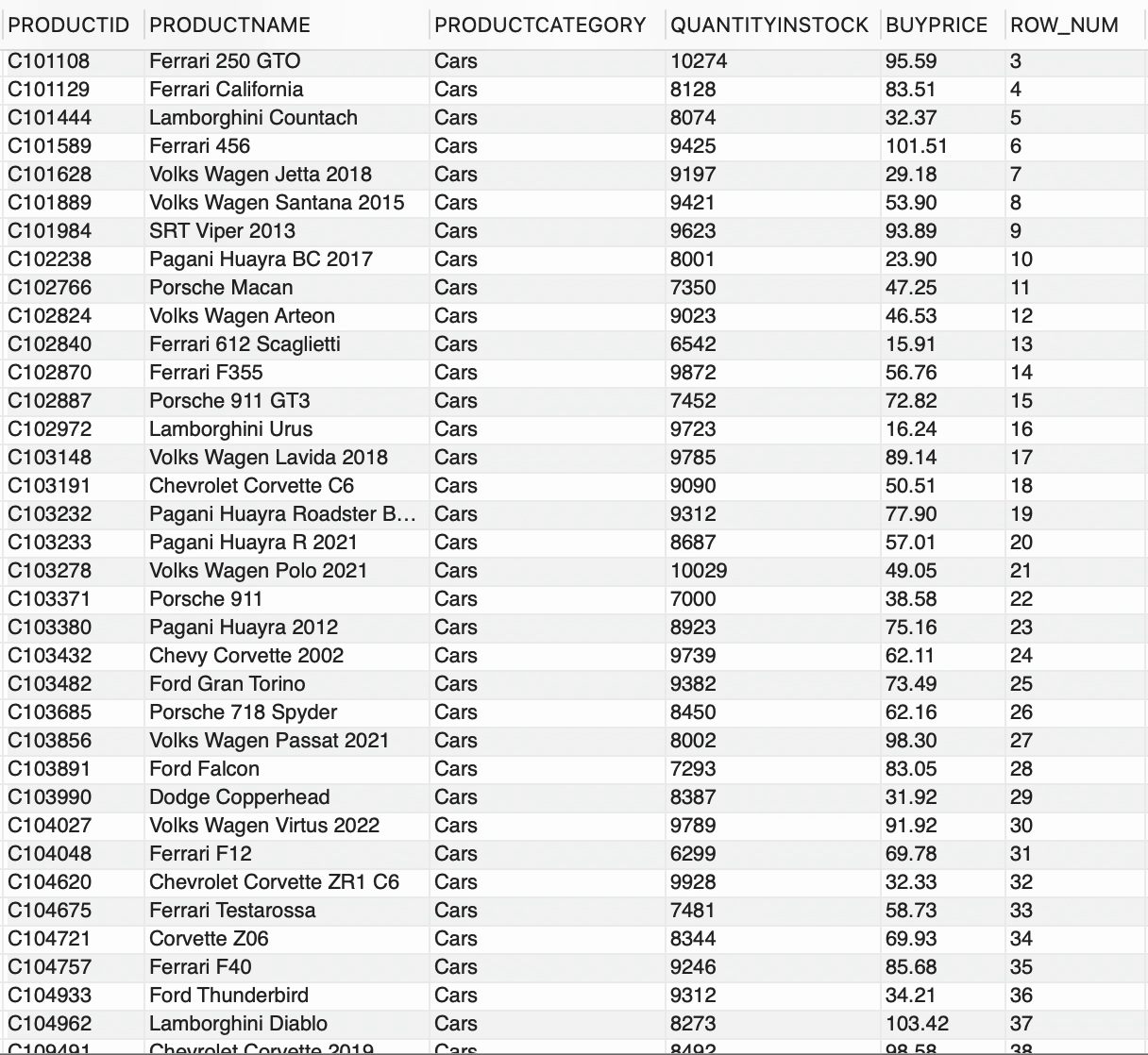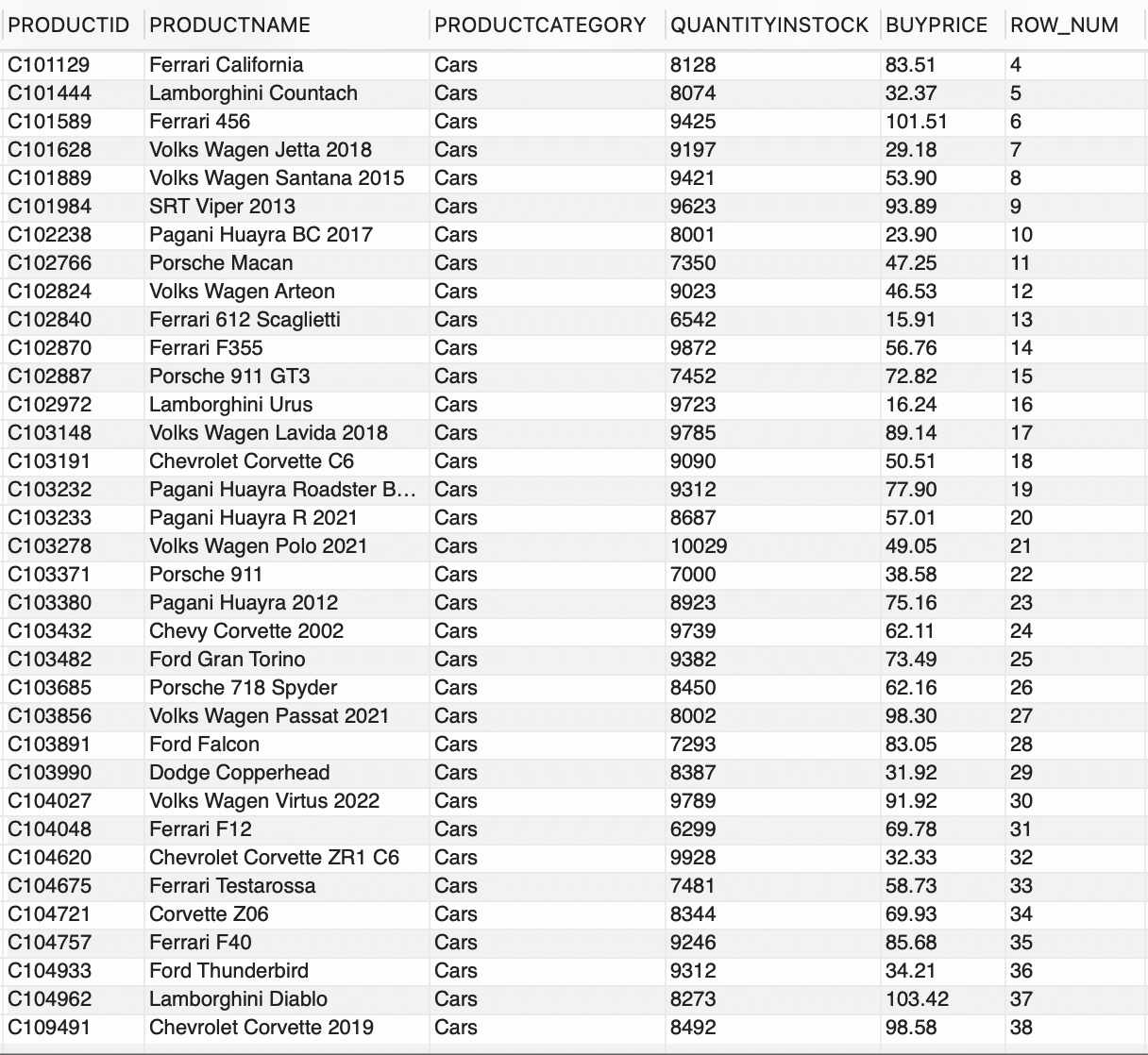
Tenemos 2 PRODUCTCATEGORY distintas disponibles en la tabla PRODUCTS,
ROW_NUMBER() generó un número entero secuencial para cada fila y la cláusula PARTITION BY dividió el conjunto de resultados en grupos basados en PRODUCTCATEGORY. Básicamente, ROW_NUMBER() junto con OVER y la cláusula PARTITION BY, generó una secuencia única de números para cada PRODUCTCATEGORY.
Ahora, utilicemos también la cláusula ORDER BY. Esta fue también una de las preguntas más frecuentes en las entrevistas de nivel básico/intermedio. Digamos que queremos conocer los 3 productos principales de cada PRODUCTCATEGORY con la mayor cantidad de stock disponible.
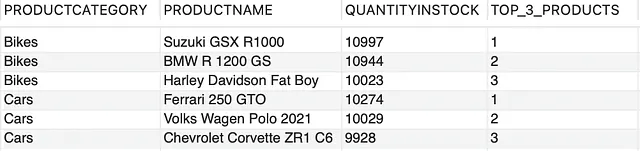
--top 3 productos con la mayor cantidad de stock en cada categoría de productoCON INVENTARIO_DE_PRODUCTOS COMO (SELECCIONAR PRODUCTCATEGORY, PRODUCTNAME, QUANTITYINSTOCK, ROW_NUMBER() OVER (PARTITION BY PRODUCTCATEGORY ORDER BY QUANTITYINSTOCK DESC) COMO ROW_NUMDE PRODUCTOS)SELECCIONAR PRODUCTCATEGORY, PRODUCTNAME, QUANTITYINSTOCK, ROW_NUM COMO TOP_3_PRODUCTOSDE INVENTARIO_DE_PRODUCTOSDONDE ROW_NUM <= 3;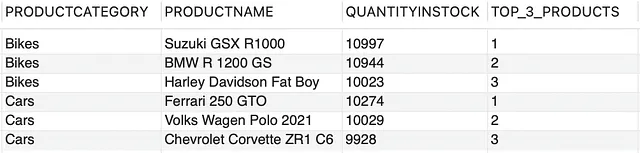
Primero desglosemos la consulta completa en dos partes, como se muestra en la siguiente imagen; primero, estamos creando un INVENTARIO_DE_PRODUCTOS. Los datos de la tabla se dividirán en particiones/grupos de cada PRODUCTCATEGORY, ordenados en orden descendente por la cantidad disponible en stock para cada categoría de producto. ROW_NUMBER() generará entonces números enteros secuenciales para cada partición. La parte interesante aquí es que el número de fila para cada fila se restablece para cada PRODUCTCATEGORY.
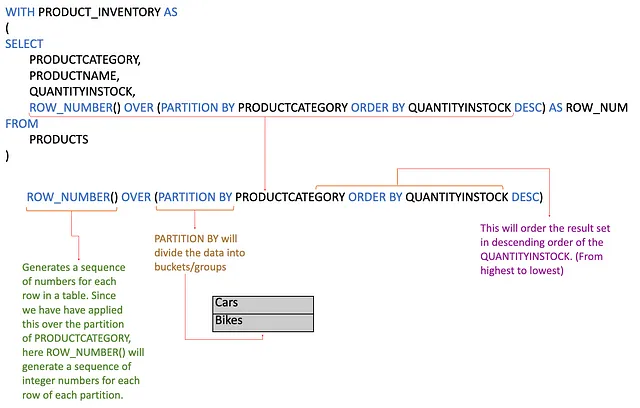
La consulta anterior devolverá el siguiente resultado,

Ahora la segunda parte de nuestra consulta es bastante sencilla. Utilizará este conjunto de resultados como entrada y recogerá los 3 productos principales de cada PRODUCTCATEGORY basados en la condición ROW_NUM ≤ 3. El resultado final es el siguiente,

Lo que nos lleva al resultado final como,
RANK()
Como su nombre indica, RANK() asigna un rango a cada fila de la tabla o cada fila en una partición. La sintaxis general es,
RANK() OVER ([PARTITION BY cláusula] [ORDER BY cláusula])
Continuando con nuestro ejemplo de la tabla PRODUCTS, asignemos un rango a los productos basados en la cantidad disponible en stock en orden descendente, particionado por PRODUCTCATEGORY.
--generar rango para cada categoría de productoSELECCIONAR PRODUCTCATEGORY, PRODUCTNAME, QUANTITYINSTOCK, RANK() OVER (PARTITION BY PRODUCTCATEGORY ORDER BY QUANTITYINSTOCK DESC) COMO "RANGO"DE PRODUCTOS;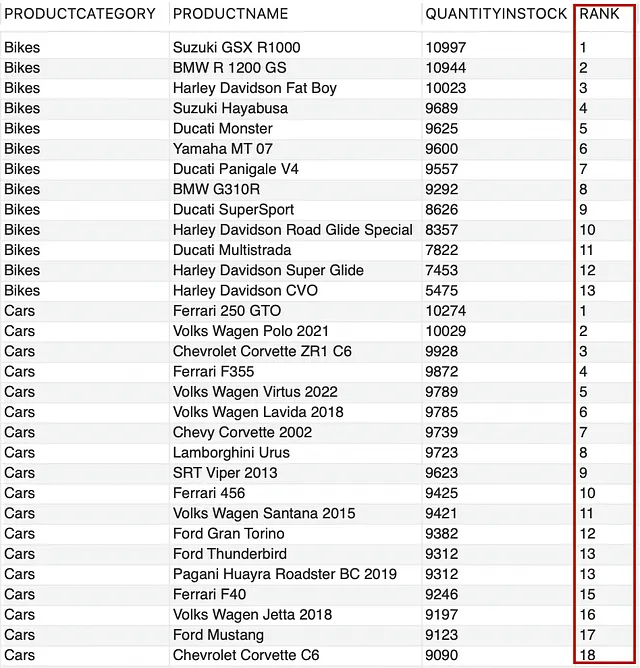
He limitado el conjunto de resultados con fines de demostración. Ahora, no te confundas entre ROW_NUMBER() y RANK(). El conjunto de resultados para ambos puede parecer similar; sin embargo, hay una diferencia. ROW_NUMBER() asigna un número entero secuencial único a cada fila de una tabla o en una partición; mientras que, RANK() también genera un número entero secuencial para cada fila de una tabla o en una partición, pero asigna el mismo rango para las filas con los mismos valores.
Veamos esto con un ejemplo, aquí está el conjunto de datos de muestra de la tabla CUSTOMERS,
-- datos de muestra de la tabla customersSELECT CUSTOMERID, CUSTOMERNAME, CREDITLIMITFROM CUSTOMERSLIMIT 10; 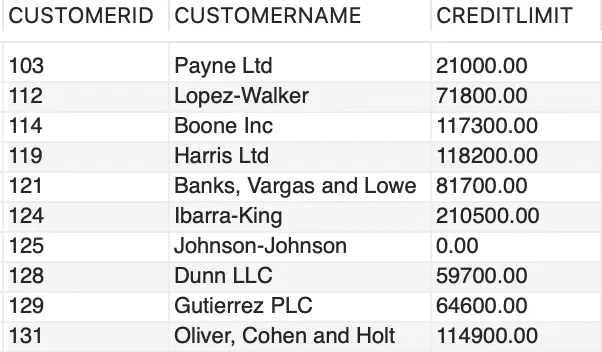
En la siguiente demostración, he generado ROW_NUMBER() y RANK() para la tabla CUSTOMERS, ordenada en orden descendente de su CREDITLIMIT.
-- comparación de row_number() y rank()SELECT CUSTOMERID, CUSTOMERNAME, CREDITLIMIT, ROW_NUMBER() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_ROW_NUM, RANK() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_RANKFROM CUSTOMERS;
He limitado el conjunto de resultados con fines de demostración. En verde se resalta ROW_NUMBER() y en azul RANK().
Ahora, si te fijas en los 3 registros resaltados en rojo, ahí es donde difiere el conjunto de resultados para ambas funciones; ROW_NUMBER() generó un número entero secuencial único para todas las filas. Pero por otro lado, RANK() asignó el mismo rango, 20, para CUSTOMERID 239 y 321 ya que tienen el mismo límite de crédito, que es 105000.00. No solo eso, para el siguiente registro, que es CUSTOMERID 458, saltó el rango 21 y lo asignó al rango 22.
DENSE_RANK()
Ahora, si te estás preguntando, ¿por qué necesitamos DENSE_RANK() si ya estamos equipados con RANK()? Como ya presenciamos en el ejemplo anterior, RANK() genera el mismo rango para las filas con los mismos valores y luego salta el siguiente rango consecutivo (consulte la imagen anterior).
DENSE_RANK() es similar a RANK() excepto por esta diferencia, no salta ningún rango al clasificar las filas. La sintaxis común es,
DENSE_RANK() OVER ([PARTITION BY clause] [ORDER BY clause])
Volviendo a la tabla CUSTOMERS, comparemos el conjunto de resultados tanto para RANK() como para DENSE_RANK(),
-- comparación de dense_rank() y rank()SELECT CUSTOMERID, CUSTOMERNAME, CREDITLIMIT, RANK() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_RANK, DENSE_RANK() OVER (ORDER BY CREDITLIMIT DESC) AS CREDIT_DENSE_RANKFROM CUSTOMERS;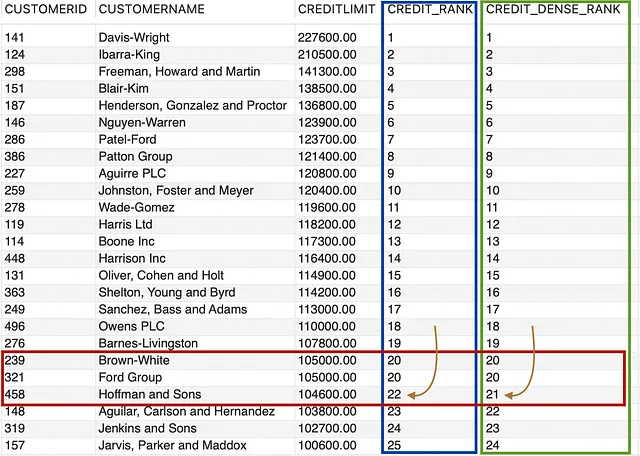
Similar a RANK() (resaltado en azul), DENSE_RANK() (resaltado en verde), generó el mismo rango para CUSTOMERID 239 y 321, lo que DENSE_RANK() hizo de manera diferente es, en lugar de saltar el siguiente número consecutivo como lo hizo RANK(), mantuvo la secuencia y asignó el rango 21 al CUSTOMERID 458.
NTH_VALUE()
Esto es un poco diferente a lo que hemos discutido hasta ahora. NTH_VALUE() devolverá el valor de la fila N de la expresión en una ventana especificada. La sintaxis común es:
NTH_VALUE(expresión, N) OVER (CLAUSULA [PARTITION BY] [ORDER BY] [ROW/RANGE])
‘N’ debe ser un valor entero positivo. Si los datos no existen en la posición N, la función devolverá NULL. Aquí, si te has dado cuenta, tenemos una cláusula adicional en la sintaxis que es la cláusula ROW/RANGE.
RAW/RANGE es parte de la cláusula Frame en la Función de Ventana que define un subconjunto dentro de una partición de ventana. ROW/RANGE define los puntos de inicio y finalización de este subconjunto con respecto a la fila actual, tomando la ubicación de la fila actual como punto de referencia, y con esa referencia, se define el frame dentro de la partición.
- ROWS – Esto define el comienzo y el final del frame especificando el número de filas que preceden o siguen a la fila actual.
- RANGE – A diferencia de ROWS, RANGE especifica el rango de valores en comparación con el valor de la fila actual para definir un frame dentro de la partición.
La sintaxis genérica es:
{ROWS | RANGE} BETWEEN <inicio_frame> AND <final_frame>

Cuando usas la cláusula ORDER BY, establece el frame predeterminado como:
{ROWS/RANGE} BETWEEN UNBOUNDED PRECEDING Y CURRENT ROW
Sin la cláusula ORDER BY, el frame predeterminado es:
{ROWS/RANGE} BETWEEN UNBOUNDED PRECEDING Y UNBOUNDED FOLLOWING
Puede parecer mucho por ahora, ¡pero no es necesario memorizar la sintaxis y su significado, solo practica! Puedes leer la detallada cláusula Frame con una serie de ejemplos aquí,
Anatomía de las Funciones de Ventana SQL
Volver a lo básico | Fundamentos de SQL para principiantes
towardsdatascience.com
Ahora, digamos que necesitamos encontrar el NOMBRE DEL PRODUCTO de cada CATEGORÍA DE PRODUCTO con el segundo precio de compra más alto,
--nombre del producto para cada categoría de producto con el segundo precio de compra más altoSELECT PRODUCTNAME, PRODUCTCATEGORY, BUYPRICE, NTH_VALUE(PRODUCTNAME,2) OVER(PARTITION BY PRODUCTCATEGORY ORDER BY BUYPRICE DESC) AS SECOND_HIGHEST_BUYPRICEFROM PRODUCTS;
Tenemos 2 funciones de valor más similares a NTH_VALUE(); FIRST_VALUE() y LAST_VALUE(). Como su nombre indica, devuelven los valores más altos (primeros) y más bajos (últimos) de una lista ordenada basada en la expresión del usuario, respectivamente. La sintaxis común es:
FIRST_VALUE(expresión) OVER (CLAUSULA [PARTITION BY] [ORDER BY] [ROW/RANGE])
LAST_VALUE(expresión) OVER (CLAUSULA [PARTITION BY] [ORDER BY] [ROW/RANGE])
Similar al ejemplo anterior, ¿puedes encontrar ahora el NOMBRE DEL PRODUCTO con el precio de compra más alto y más bajo para cada CATEGORÍA DE PRODUCTO?
NTILE()
A veces hay escenarios en los que querrás ordenar las filas dentro de la partición en un cierto número de grupos o buckets. NTILE() se usa para dicho propósito, divide las filas ordenadas en la partición en un número específico de buckets. A cada uno de estos buckets se le asigna un número de grupo comenzando desde 1. Intentará crear grupos de tamaño igual que sea posible. Para cada fila, la función NTILE() devuelve un número de grupo que representa el grupo al que pertenece esa fila.
La sintaxis general es:
NTILE(N) OVER ([CLAUSULA DE PARTICIÓN] [CLAUSULA DE ORDEN])
Donde ‘N’ es un entero positivo que define el número de grupos que se quieren crear.
Supongamos que queremos segregar la categoría de PRODUCTO – “Cars” de tal manera que tengamos una lista de coches con alto rango, medio rango y bajo rango de precio de compra.
--segregue los 'Cars' para los precios de compra de alto rango, medio rango y bajo rangoSELECT PRODUCTNAME, BUYPRICE, NTILE(3) OVER (ORDER BY BUYPRICE DESC) AS BUYPRICE_BUCKETSFROM PRODUCTSWHERE PRODUCTCATEGORY = 'Cars';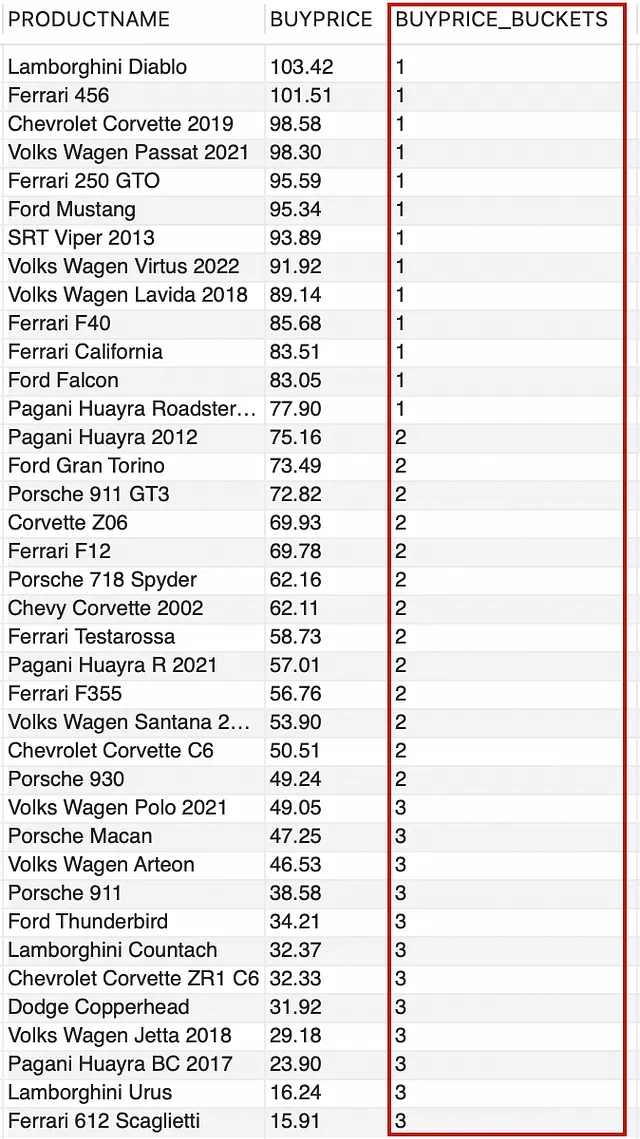
LAG() & LEAD()
A menudo encontramos escenarios donde se requiere algún tipo de análisis comparativo, como comparar las ventas del año seleccionado con las del año anterior o siguiente. Tales comparaciones son realmente útiles cuando se trabaja con datos de series temporales y se calculan las diferencias a través del tiempo.
LAG() extrae los datos de la fila que precede a la fila actual. Si no hay una fila anterior, entonces devuelve NULL. La sintaxis común es:
LAG(expresión, desplazamiento) OVER ([CLAUSULA DE PARTICIÓN] [CLAUSULA DE ORDEN])
LEAD() obtiene los datos de la fila que sigue a la fila actual. Si no hay una fila siguiente, entonces devuelve NULL. La sintaxis común es:
LEAD(expresión, desplazamiento) OVER ([CLAUSULA DE PARTICIÓN] [CLAUSULA DE ORDEN])
Donde desplazamiento es opcional pero cuando se usa su valor debe ser 0 o un entero positivo,
- Cuando se especifica como 0, LAG() y LEAD() evalúan la expresión para la fila actual.
- Cuando se omite, 1 se considera un valor predeterminado, que toma la fila inmediatamente anterior o siguiente a la fila actual.
--ventas totales anuales por cada categoría de productoWITH YEARLY_SALES AS(SELECT PROD.PRODUCTCATEGORY, YEAR(ORDERDATE) AS SALES_YEAR, SUM(ORDET.QUANTITYORDERED * ORDET.COSTPERUNIT) AS TOTAL_SALESFROM PRODUCTS PRODINNER JOIN ORDERDETAILS ORDET ON PROD.PRODUCTID = ORDET.PRODUCTIDINNER JOIN ORDERS ORD ON ORDET.ORDERID = ORD.ORDERIDGROUP BY PRODUCTCATEGORY, SALES_YEAR )SELECT PRODUCTCATEGORY, SALES_YEAR, LAG(TOTAL_SALES) OVER (PARTITION BY PRODUCTCATEGORY ORDER BY SALES_YEAR) AS LAG_PREVIOUS_YEAR, TOTAL_SALES, LEAD(TOTAL_SALES) OVER (PARTITION BY PRODUCTCATEGORY ORDER BY SALES_YEAR) AS LEAD_FOLLOWING_YEARFROM YEARLY_SALES;Aquí, primero usamos CTE (Expresión de tabla común) para obtener los datos de ventas totales para cada PRODUCTCATEGORY por año. Luego usamos estos datos con LAG() y LEAD() para buscar datos de ventas totales divididos por PRODUCTCATEGORY y ordenados por SALES_YEAR del año calendario anterior y siguiente, respectivamente.

Conclusión
Las funciones de ventana son realmente útiles cuando se desea analizar los datos de varias maneras. Los diferentes sabores de SQL pueden tener implementaciones ligeramente diferentes, por lo que siempre es una buena idea consultar la documentación oficial de un sabor de SQL en particular. Aquí hay algunos recursos para empezar:
- Anatomía de las funciones de ventana
- Conceptos y sintaxis de las funciones de ventana
- Restricciones de la función de ventana de MySQL
- Hoja de trucos de la función de ventana de SQL
Si recuerdas algo realmente bien, es porque lo has practicado bien,
- HackerRank o LeetCode para practicar problemas básicos/intermedios/avanzados de SQL.
Conviértete en miembro y lee todas las historias en Zepes.
¡Feliz aprendizaje!
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Incorpore SageMaker Autopilot en sus procesos de MLOps usando un Proyecto personalizado de SageMaker.
- Habilidades Suaves Superan las Habilidades Técnicas en Análisis de Datos.
- Utilizando pykrige y matplotlib para la visualización espacial de variaciones geológicas.
- Introducción al análisis de datos El Método Google
- En conversación con el Dr. Sagar Dhanraj Pande, Profesor Asistente de Ciencia de Datos.
- El Viaje de un Científico de Datos Senior y Ingeniero de Aprendizaje Automático en el Dominio de Fintech
- 12 Modelos Mentales para la Ciencia de Datos