Web LLM Trae los Chatbots de LLM al Navegador.
Web LLM brings LLM chatbots to the browser.
¿No sería genial si pudieras ejecutar LLMs y chatbots de LLM de forma nativa en tu navegador? Aprendamos más sobre el proyecto Web LLM, un paso interesante en esta dirección.

Los chatbots basados en LLM son accesibles a través de un front-end y requieren un gran número de llamadas a la API costosas en el lado del servidor. Pero ¿qué pasaría si pudiéramos hacer que los LLM se ejecutaran completamente en el navegador, utilizando la potencia informática del sistema subyacente?
De esta manera, la funcionalidad completa del LLM está disponible en el lado del cliente, sin tener que preocuparse por la disponibilidad del servidor, la infraestructura y similares. Web LLM es un proyecto que tiene como objetivo lograr esto.
- 12 consejos y trucos de VSCode para el desarrollo en Python
- 4 Lecciones de carrera que me ayudaron a navegar en el difícil mercado laboral.
- ¿Qué tan difícil es ingresar a empresas FAANG?
Aprendamos más sobre lo que impulsa a Web LLM y los desafíos de construir un proyecto así. También analizaremos las ventajas y limitaciones de Web LLM.
¿Qué es Web LLM?
Web LLM es un proyecto que utiliza WebGPU y WebAssembly, y mucho más, para permitir la ejecución de LLM y aplicaciones de LLM completamente en el navegador. Con Web LLM, puedes ejecutar chatbots LLM en el navegador aprovechando la GPU del sistema subyacente a través de WebGPU.
Utiliza la pila de compiladores del proyecto Apache TVM y utiliza WebGPU que se lanzó recientemente. Además de la renderización de gráficos en 3D y similares, la API de WebGPU también admite cálculos de GPU de propósito general (cálculos GPGPU).
Desafíos de construir Web LLM
Dado que Web LLM se ejecuta completamente en el lado del cliente sin ningún servidor de inferencia, se asocian los siguientes desafíos con el proyecto:
- Los modelos de lenguaje grandes utilizan frameworks de Python para el aprendizaje profundo que también admiten nativamente el aprovechamiento de la GPU para operaciones en tensores.
- Cuando se construye Web LLM para que se ejecute completamente en el navegador, no podremos usar los mismos frameworks de Python. Y se tuvieron que explorar alternativas de tecnologías que permitieran ejecutar LLM en la web mientras se seguía utilizando Python para el desarrollo.
- La ejecución de aplicaciones LLM típicamente requiere servidores de inferencia grandes, pero cuando todo se ejecuta en el lado del cliente, en el navegador, ya no podemos tener servidores de inferencia grandes.
- Requiere una compresión inteligente de los pesos del modelo para que se ajuste en la memoria disponible.
¿Cómo funciona Web LLM?
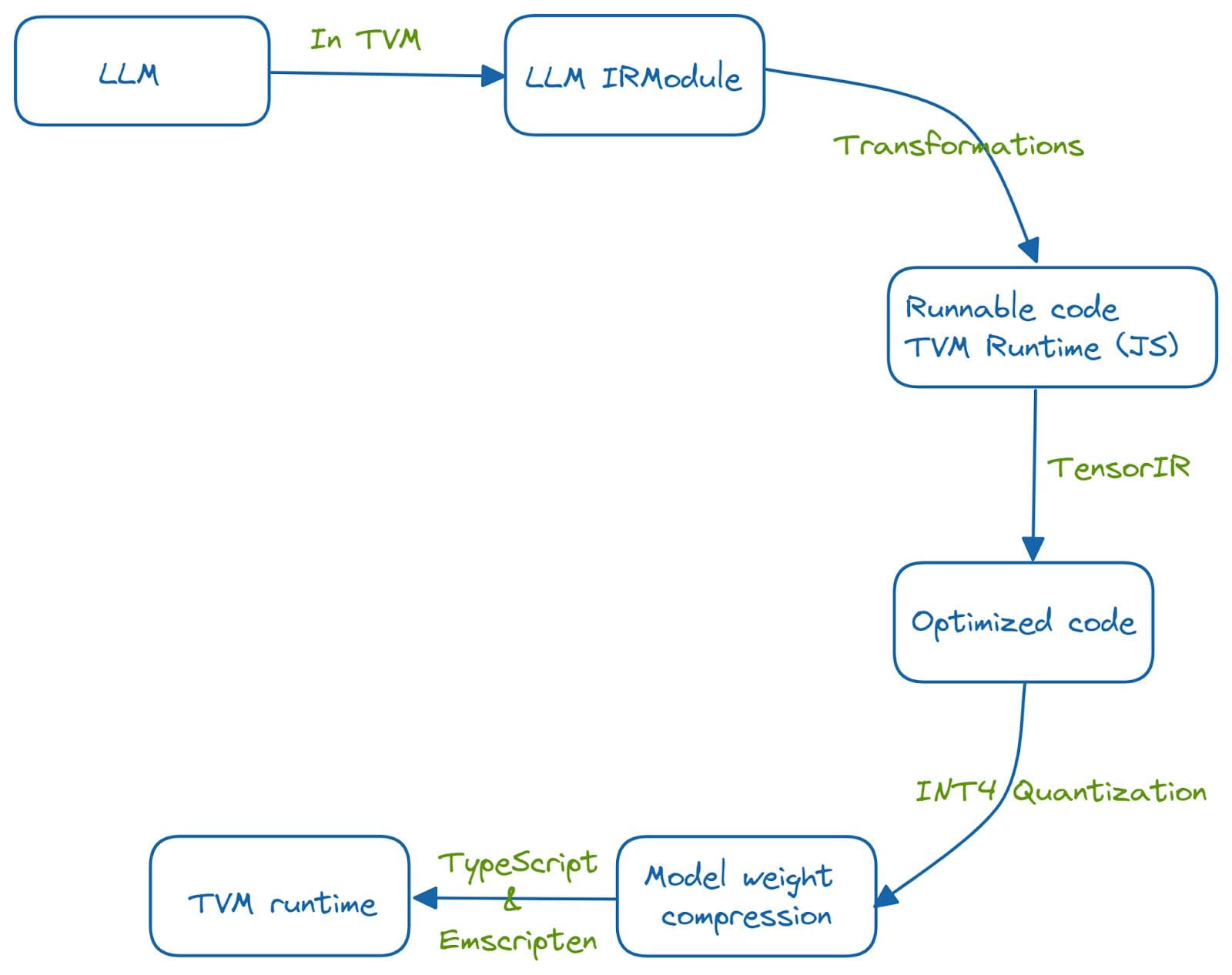
El proyecto Web LLM utiliza la GPU y las capacidades de hardware del sistema subyacente para ejecutar grandes modelos de lenguaje en el navegador. El proceso de compilación del aprendizaje automático ayuda a integrar la funcionalidad de LLM en el lado del navegador aprovechando TVM Unity y un conjunto de optimizaciones.

El sistema está desarrollado en Python y se ejecuta en la web utilizando el tiempo de ejecución de TVM. Esta portabilidad al navegador web se logra ejecutando una serie de optimizaciones.
La funcionalidad de LLM se integra primero en un IRModule en TVM. Se ejecutan varias transformaciones en las funciones del IRModule para obtener un código optimizado y ejecutable. TensorIR es una abstracción de compilador para optimizar programas con cálculos de tensores. Además, se utiliza la cuantificación INT-4 para comprimir los pesos del modelo. Y se hace posible un tiempo de ejecución de TVM utilizando TypeScript y emscripten, un compilador de LLVM que transforma el código C y C++ a WebAssembly.
Necesitas tener la última versión de Chrome o Chrome Canary para probar Web LLM. Al momento de escribir este artículo, Web LLM admite los LLM Vicuna y LLaMa.
Cargar el modelo lleva tiempo la primera vez que se ejecuta el modelo. Debido a que el almacenamiento en caché está completo después de la primera ejecución, las ejecuciones posteriores son considerablemente más rápidas y tienen un mínimo sobrecarga.

Ventajas y Limitaciones de Web LLM
Concluyamos nuestra discusión enumerando las ventajas y limitaciones de Web LLM.
Ventajas
Además de explorar la sinergia de Python, WebAssembly y otras tecnologías, Web LLM tiene las siguientes ventajas:
- La principal ventaja de ejecutar LLM en el navegador es privacidad. Debido a que el servidor se elimina por completo en este diseño centrado en la privacidad, ya no tenemos que preocuparnos por el uso de nuestros datos. Debido a que Web LLM aprovecha la potencia de cómputo de la GPU del sistema subyacente, no tenemos que preocuparnos por que los datos lleguen a entidades malintencionadas.
- Podemos construir asistentes personales de IA para actividades cotidianas. Por lo tanto, el proyecto Web LLM ofrece un alto grado de personalización.
- Otra ventaja de Web LLM es el costo reducido. Ya no necesitamos llamadas de API costosas y servidores de inferencia, y Web LLM utiliza la GPU y las capacidades de procesamiento del sistema subyacente. Por lo tanto, ejecutar Web LLM es posible a una fracción del costo.
Limitaciones
Aquí hay algunas de las limitaciones de Web LLM:
- Aunque Web LLM alivia las preocupaciones sobre la entrada de información confidencial, aún es susceptible a ataques en el navegador.
- Hay un alcance adicional para la mejora al agregar soporte para múltiples modelos de lenguaje y elección de navegadores. Actualmente, esta función solo está disponible en Chrome Canary y la última versión de Chrome. Ampliar esto a un conjunto más grande de navegadores admitidos será útil.
- Debido a las verificaciones de robustez ejecutadas por el navegador, Web LLM utilizando WebGPU no tiene el rendimiento nativo de un tiempo de ejecución de GPU. Opcionalmente, puede desactivar la bandera que ejecuta las verificaciones de robustez para mejorar el rendimiento.
Conclusión
Hemos intentado entender cómo funciona Web LLM. Puede intentar ejecutarlo en su navegador o incluso implementarlo localmente. Considere jugar con el modelo en su navegador y compruebe qué tan efectivo es cuando se integra en su flujo de trabajo diario. Si está interesado, también puede consultar el proyecto MLC-LLM, que le permite ejecutar LLM de forma nativa en cualquier dispositivo de su elección, incluidas laptops e iPhones.
Referencias y Lecturas Adicionales
[1] API WebGPU, MDN Web Docs
[2] TensorIR: Una abstracción para la optimización automática de programas tensorizados
[3] MLC-LLM Bala Priya C es una desarrolladora y escritora técnica de India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir sus conocimientos con la comunidad de desarrolladores mediante la redacción de tutoriales, guías prácticas, artículos de opinión y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- MLOps Esencial Un eBook gratuito.
- Un manual para escalar MLOps.
- Diez años de revisión de la Inteligencia Artificial.
- El Arte de la Ingeniería de Respuesta Rápida Decodificando ChatGPT
- Empezando con ReactPy
- Convierta ideas en música con MusicLM.
- Potenciando la búsqueda con inteligencia artificial generativa