Visualización del efecto de la multicolinealidad en el modelo de regresión múltiple.
Visualizing the effect of multicollinearity in multiple regression model.
Utilizando la visualización de datos con Python para explicar el efecto de la multicolinealidad en la regresión múltiple
¿Qué es la multicolinealidad?
En la regresión múltiple, la multicolinealidad ocurre cuando un predictor (variable independiente) se correlaciona altamente con uno o más de los otros predictores en el modelo.
¿Por qué es importante?
### Ecuación de regresión múltiple: Y = β₀ + β₁X₁ + β₂X₂ + ... + βᵢXᵢ + εTeóricamente, como se puede ver en la ecuación, la regresión múltiple utiliza más de un predictor para predecir el valor de la variable dependiente.
Por cierto, la regresión múltiple funciona determinando el efecto del cambio promedio de una unidad en un predictor en la variable dependiente mientras se mantienen constantes otros predictores.
Si un predictor se correlaciona altamente con los demás, será difícil cambiar ese predictor sin cambiar los demás.
- Pandas potenciado Encriptando archivos de Excel escritos desde DataFrames
- Control Sintético ¿Y si pudiéramos simular realidades alternativas?
- Investigadores crean una herramienta para simular con precisión sistemas complejos.
El efecto de la multicolinealidad
En pocas palabras, la multicolinealidad afecta los coeficientes del modelo. Con pequeños cambios en los datos, puede afectar las estimaciones de los coeficientes. Por lo tanto, se vuelve difícil interpretar el papel de cada variable independiente.
Este artículo explicará y mostrará el fenómeno aplicando la visualización de datos. Antes de comenzar, discutamos cómo determinar si el modelo tiene multicolinealidad.

¿Cómo detectar la multicolinealidad?
### Ecuación de VIF (Factor de Inflación de la Varianza): VIF = 1 / (1 - Rᵢ²)Podemos usar VIF (Factor de Inflación de la Varianza) para estimar cuánto se infla la varianza de un coeficiente de regresión debido a la multicolinealidad.
El cálculo se realiza mediante la regresión de un predictor contra otros predictores para obtener los valores de R al cuadrado. Luego, los valores de R al cuadrado obtenidos se utilizarán para calcular los valores de VIF. La “i” en la ecuación representa el predictor.
Se pueden usar los siguientes criterios para interpretar el resultado:
#1 : no correlacionado#1–5 : moderadamente correlacionado#> 5 : altamente correlacionadoAhora que hemos terminado con la parte de explicación. Continuemos con la creación del modelo.
Modelos de regresión múltiple
Comencemos preparando modelos de regresión múltiple para trazar. En primer lugar, crearemos dos modelos a partir de un conjunto de datos; uno con variables moderadamente correlacionadas y otro con variables altamente correlacionadas.
Luego modificaremos ligeramente los datos para ver cuál de los modelos se verá más afectado por la pequeña modificación. Comenzamos importando bibliotecas.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlineObteniendo datos
Por ejemplo, este artículo trabajará con el conjunto de datos Cars Data, que tiene una licencia de dominio público. Se puede descargar libre y directamente desde la biblioteca Seaborn con la función seaborn.load_dataset().
El conjunto de datos contiene precios y características de 392 automóviles entre 1970-1982 en EE. UU., Europa y Japón. Se puede encontrar más información sobre el conjunto de datos aquí: enlace.
data = sns.load_dataset('mpg')data.dropna(inplace=True) #eliminar filas nulasdata.head()
Hacer un análisis exploratorio de datos para entender el conjunto de datos es siempre una buena idea.
data.describe()
Los rangos (valor máximo – valor mínimo) en las columnas son bastante diferentes. Por lo tanto, realizar la estandarización puede ayudar a interpretar los coeficientes más tarde.
data = data.iloc[:,0:-2] # seleccionar columnasfrom sklearn.preprocessing import StandardScalerscaler = StandardScaler()df_s = scaler.fit_transform(data)df = pd.DataFrame(df_s, columns=data.columns)df.head()
Continúe con la creación de un mapa de calor para mostrar la correlación entre las variables.
plt.figure(figsize=(9, 6))sns.heatmap(df.corr(), cmap='coolwarm', annot=True)plt.show()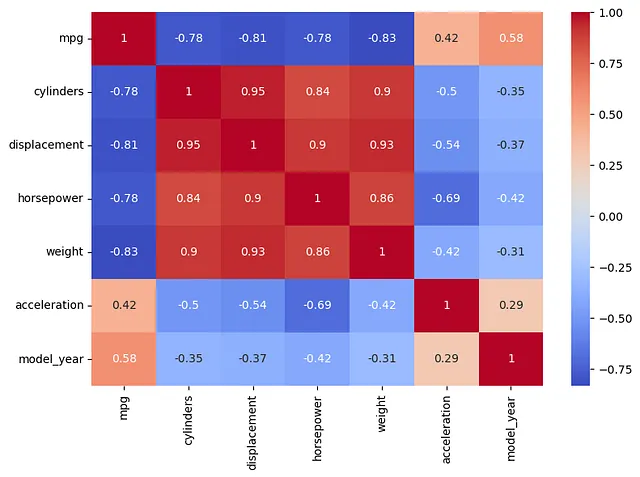
El resultado muestra que algunas variables están altamente correlacionadas con otras variables. Si cada predictor se incluye en un modelo de regresión múltiple para predecir el valor de ‘mpg’, la multicolinealidad afectará el modelo.
Calculando los valores de VIF
Esto se puede demostrar rápidamente calculando los valores de VIF con la biblioteca Statsmodels.
from statsmodels.stats.outliers_influence import variance_inflation_factor as vifvif_data = pd.DataFrame()vif_data["característica"] = df.columns# calculando VIF para cada característicavif_data["VIF"] = [vif(df.values, i) for i in range(len(df.columns))]print(vif_data)
Algunos valores de VIF son bastante altos (> 5), lo que puede interpretarse como altamente correlacionados. Si ponemos directamente cada predictor en un modelo de regresión múltiple, el modelo puede sufrir el problema de multicolinealidad.
A continuación, solo se seleccionarán algunos predictores. Este artículo trabajará con dos modelos: uno con predictores moderadamente correlacionados y otro con predictores altamente correlacionados.
El primer modelo de regresión múltiple utiliza ‘cylinders’ y ‘acceleration’ para predecir el ‘mpg’, mientras que el segundo utiliza ‘cylinders’ y ‘displacement’. Calculemos los valores de VIF de nuevo.
df1 = df[['mpg', 'cylinders', 'acceleration']]df2 = df[['mpg', 'cylinders', 'displacement']]# dataframe de VIF1vif_data1 = pd.DataFrame()vif_data1['característica'] = df1.columnsvif_data1['VIF'] = [vif(df1.values, i) for i in range(len(df1.columns))]print('modelo 1')print(vif_data1)# dataframe de VIF2vif_data2 = pd.DataFrame()vif_data2['característica'] = df2.columnsvif_data2['VIF'] = [vif(df2.values, i) for i in range(len(df2.columns))]print('modelo 2') print(vif_data2)
La diferencia entre estos dos modelos es cambiar de la variable ‘acceleration’ a ‘displacement’. Sin embargo, se puede observar que ninguno de los valores de VIF en el primer modelo es mayor que 5, mientras que el segundo modelo tiene valores de VIF relativamente altos, más de 10.
Creando un modelo de regresión múltiple
Usaremos la función OLS de la biblioteca statsmodels para crear un modelo de regresión múltiple.
import statsmodels.api as smy1 = df1[['mpg']]X1 = df1[['cylinders', 'acceleration']]lm1 = sm.OLS(y1, X1)model1 = lm1.fit()model1.summary()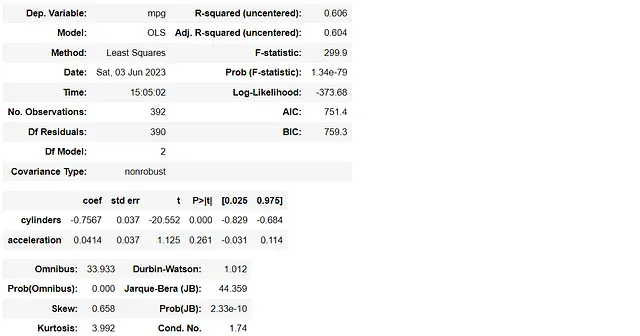
Graficando el modelo
A partir del modelo obtenido, definiremos una función para ejecutar el modelo en una malla de puntos para su uso en el siguiente paso.
def run_model(v1, v2, pd_): mesh_size = 0.02 x_min, x_max = pd_[[v1]].min()[0], pd_[[v1]].max()[0] y_min, y_max = pd_[[v2]].min()[0], pd_[[v2]].max()[0] xrange = np.arange(x_min, x_max, mesh_size) yrange = np.arange(y_min, y_max, mesh_size) xx, yy = np.meshgrid(xrange, yrange) return xx, yy, xrange, yrangeAquí viene la parte divertida. Grafiquemos el modelo con la biblioteca Plotly, que ayuda a crear una visualización interactiva fácilmente. De esta manera, podemos interactuar con la visualización, como hacer zoom o rotar.
import plotly.express as pximport plotly.graph_objects as gofrom sklearn.svm import SVR# ejecuta y aplica el modeloxx1, yy1, xr1, yr1 = run_model('cylinders', 'acceleration', X1)pred1 = model1.predict(np.c_[xx1.ravel(), yy1.ravel()])pred1 = pred1.reshape(xx1.shape)# grafica el resultadofig = px.scatter_3d(df1, x='cylinders', y='acceleration', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr1, y=yr1, z=pred1, name='pred1'))fig.show()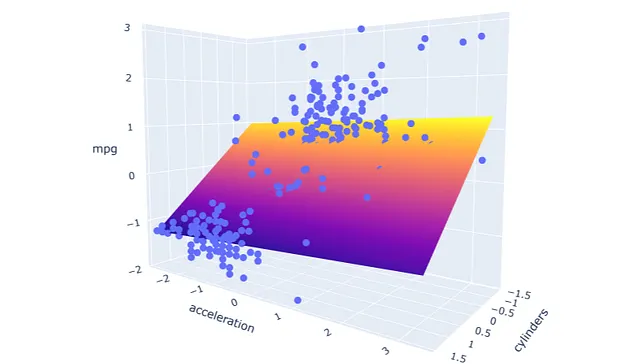
Podemos realizar el mismo proceso con el segundo modelo, que tiene el problema de multicolinealidad.
y2 = df2[['mpg']]X2 = df2[['cylinders', 'displacement']]lm2 = sm.OLS(y2, X2)model2 = lm2.fit()model2.summary()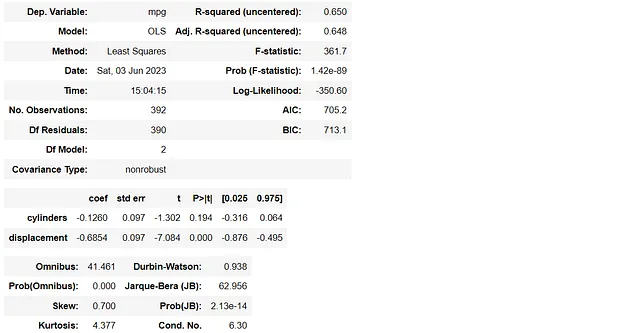
# ejecuta y aplica el modeloxx2, yy2, xr2, yr2 = run_model('cylinders', 'displacement', X2)pred2 = model2.predict(np.c_[xx2.ravel(), yy2.ravel()])pred2 = pred2.reshape(xx2.shape)# grafica el resultadofig = px.scatter_3d(df2, x='cylinders', y='displacement', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr2, y=yr2, z=pred2, name='pred2'))fig.show()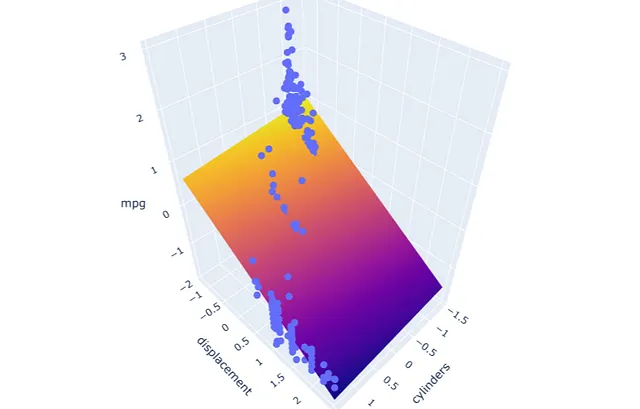
Modificando el conjunto de datos
Como se mencionó anteriormente, pequeñas modificaciones en los datos pueden afectar las estimaciones de los coeficientes. Para demostrarlo, seleccionaremos aleatoriamente una fila y cambiaremos los valores. Por ejemplo, los multiplicaremos por 1.25.
Después de eso, podemos realizar el mismo proceso y graficar los nuevos y los modelos de regresión múltiple originales en la misma gráfica para ver el resultado.
# modificar aleatoriamente una fila en el dataframe desde random import *x = randint(1, len(df))mod_list = [i*1.25 for i in df.iloc[x,:]] #multiplicar por 1.25df_m = df.copy()df_m.iloc[x] = mod_listdf_m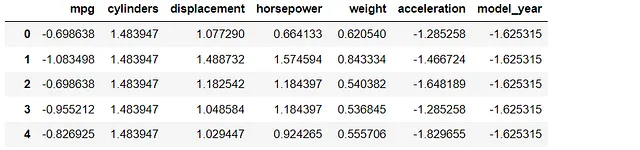
Calculando los valores de VIF
A partir del conjunto de datos modificado, calcular los valores de VIF para comparar las diferencias.
df_m1 = df_m[['mpg', 'cylinders', 'acceleration']]df_m2 = df_m[['mpg', 'cylinders', 'displacement']]# VIF dataframe1vif_data1 = pd.DataFrame()vif_data1['característica'] = df_m1.columnsvif_data1['VIF'] = [vif(df_m1.values, i) for i in range(len(df_m1.columns))]print('modelo m1')print(vif_data1)#### VIF dataframe2vif_data2 = pd.DataFrame()vif_data2['característica'] = df_m2.columnsvif_data2['VIF'] = [vif(df_m2.values, i) for i in range(len(df_m2.columns))]print('modelo m2') print(vif_data2)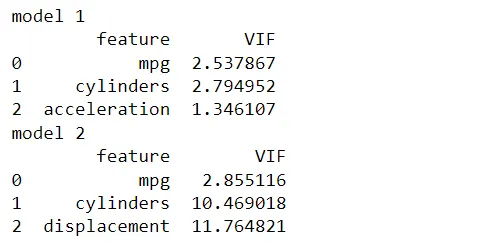

Los nuevos valores de VIF calculados a partir de los conjuntos de datos modificados son ligeramente diferentes. Ambos modelos siguen teniendo las mismas condiciones: los predictores del primer y segundo modelo están moderadamente y altamente correlacionados, respectivamente.
Creando modelos de regresión múltiple
Para comparar el cambio en los coeficientes del modelo, construyamos los modelos a partir de los nuevos conjuntos de datos para representarlos.
y_m1 = df_m1[['mpg']]X_m1 = df_m1[['cylinders', 'acceleration']]lm_m1 = sm.OLS(y_m1, X_m1)model_m1 = lm_m1.fit()model_m1.summary()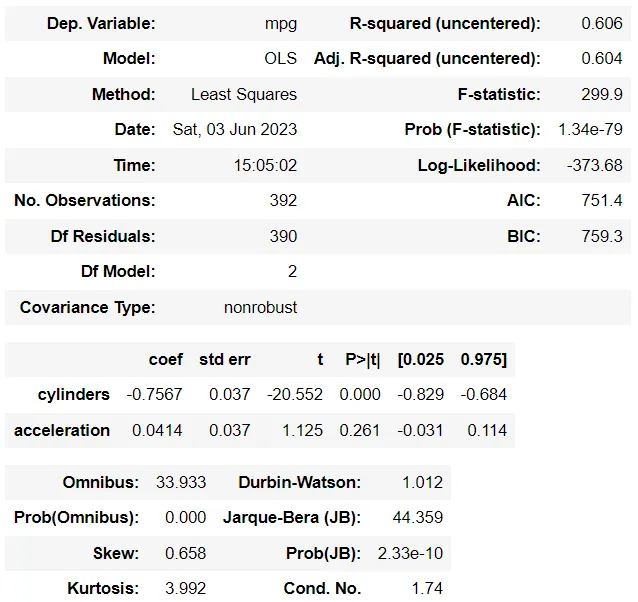
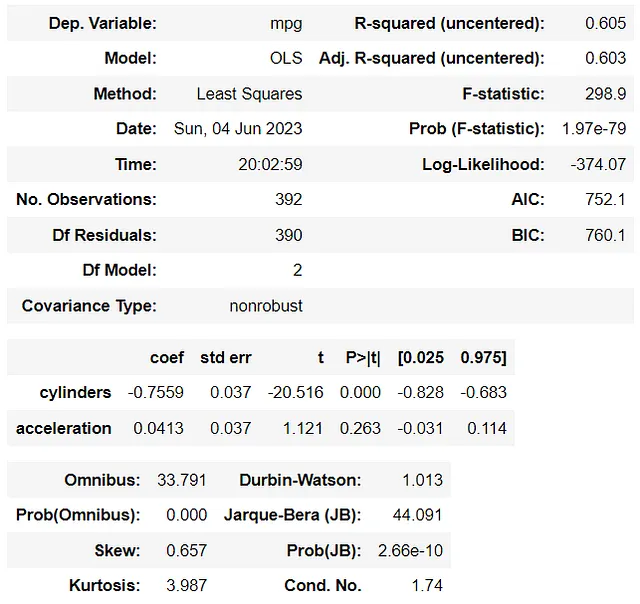
A continuación, realice el mismo proceso con el segundo modelo que tiene predictores altamente correlacionados.
y_m2 = df_m2[['mpg']]X_m2 = df_m2[['cylinders', 'displacement']]lm_m2 = sm.OLS(y_m2, X_m2)model_m2 = lm_m2.fit()model_m2.summary()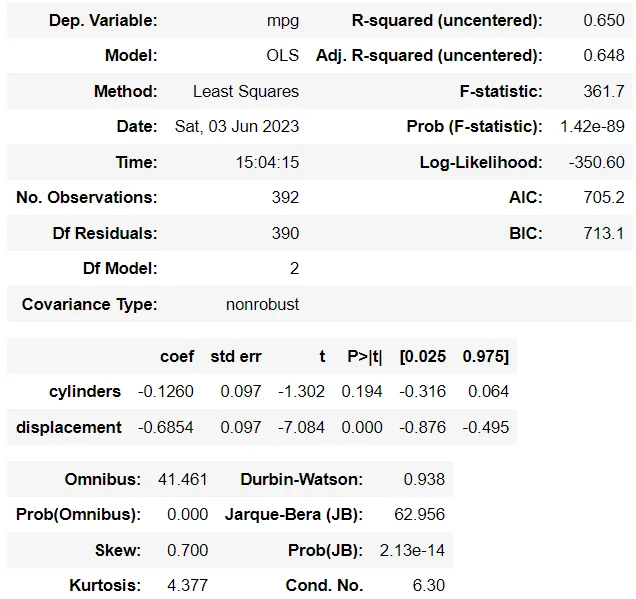
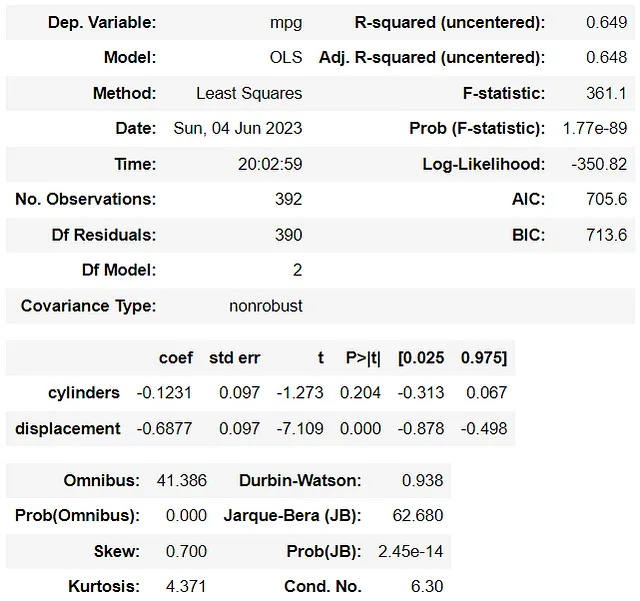
A partir de las tablas anteriores, pueden parecer que hay pequeños cambios en los coeficientes. Sin embargo, esto sucede porque modificamos aleatoriamente solo una fila del conjunto de datos. Esto no es suficiente y es demasiado pronto para asumir que la multicolinealidad afecta los coeficientes del modelo.
Con el concepto y el código que hemos hecho hasta ahora, la función de bucle for en Python se aplicará para modificar los valores en cada fila, uno a la vez. Luego, se comparará el cambio absoluto en los coeficientes con el modelo original.
Comience definiendo una función para comparar los valores de los coeficientes.
def compare_cef(base_m, mod_m, col): val_base = base_m.summary().tables[1].as_html() ml = pd.read_html(val_base, header=0, index_col=0)[0] val_diff = mod_m.summary().tables[1].as_html() ml_m = pd.read_html(val_diff, header=0, index_col=0)[0] df_ = pd.DataFrame(abs(ml.iloc[:,0] - ml_m.iloc[:,0])) df_.rename(columns={'coef': 'r '+str(col+1)}, inplace=True) return df_Use la función de bucle for para modificar las filas, una fila a la vez.
keep_df1, keep_df2 = [], []for n in range(len(df)): mod_list = [i*1.25 for i in df.iloc[n,:]] df_m = df.copy() df_m.iloc[n] = mod_list df_m1 = df_m[['mpg', 'cylinders', 'acceleration']] y_m1, X_m1 = df_m1[['mpg']], df_m1[['cylinders', 'acceleration']] lm_m1 = sm.OLS(y_m1, X_m1) mdl_m1 = lm_m1.fit() df_m2 = df_m[['mpg', 'cylinders', 'displacement']] y_m2, X_m2 = df_m2[['mpg']], df_m2[['cylinders', 'displacement']] lm_m2 = sm.OLS(y_m2, X_m2) mdl_m2 = lm_m2.fit() df_diff1 = compare_cef(model1, mdl_m1, n) df_diff2 = compare_cef(model2, mdl_m2, n) keep_df1.append(df_diff1) keep_df2.append(df_diff2) df_t1 = pd.concat(keep_df1, axis=1)df_t2 = pd.concat(keep_df2, axis=1)df_t = pd.concat([df_t1, df_t2], axis=0)df_t
Visualice el DataFrame obtenido con un mapa de calor.
plt.figure(figsize=(16,2.5))sns.heatmap(df_t, cmap='Reds')plt.xticks([])plt.show()
Desde el gráfico de mapa de calor, las dos primeras filas muestran el cambio absoluto en los coeficientes entre los modelos con variables moderadamente correlacionadas antes y después de un pequeño cambio en los datos.
Las dos últimas filas comparan lo mismo entre los modelos con variables altamente correlacionadas antes y después de una ligera modificación en los datos.
Se puede interpretar que el modelo con predictores altamente correlacionados tiende a tener coeficientes más inestables cuando ocurre el cambio en los datos, mientras que el que tiene predictores moderadamente correlacionados sufre menos.
Representación gráfica de los modelos de regresión múltiple
Para visualizar el cambio en los coeficientes, como ejemplo, modificaré una fila en el conjunto de datos, crearé un nuevo modelo y lo graficaré con el modelo original. Los nuevos modelos se mostrarán con la paleta de colores ‘viridis’ (amarillo-verde), mientras que los modelos originales se representan en el color por defecto (naranja-azul).
Si desea seleccionar y modificar otras filas manualmente, cambie el código a continuación.
x = 6 #seleccionar el número de fila mod_list = [i*1.25 for i in df.iloc[x,:]]df_m = df.copy()df_m.iloc[x] = mod_listy_m1 = df_m[['mpg']]X_m1 = df_m[['cylinders', 'acceleration']]lm_m1 = sm.OLS(y_m1, X_m1)model_m1 = lm_m1.fit()y_m2 = df_m[['mpg']]X_m2 = df_m[['cylinders', 'displacement']]lm_m2 = sm.OLS(y_m2, X_m2)model_m2 = lm_m2.fit()Ejecutar y graficar los modelos de regresión múltiple con predictores moderadamente correlacionados.
# ejecutar el modelopred_m1 = model_m1.predict(np.c_[xx1.ravel(), yy1.ravel()])pred_m1 = pred_m1.reshape(xx1.shape)# graficar el resultadofig = px.scatter_3d(df_m, x='cylinders', y='acceleration', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr1, y=yr1, z=pred1, name='pred'))fig.add_traces(go.Surface(x=xr1, y=yr1, z=pred_m1, name='pred_m1', colorscale = 'viridis_r'))fig.show()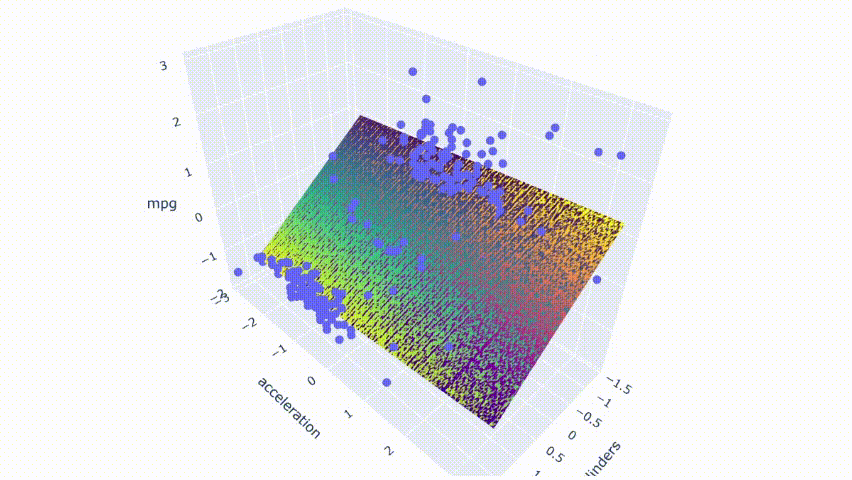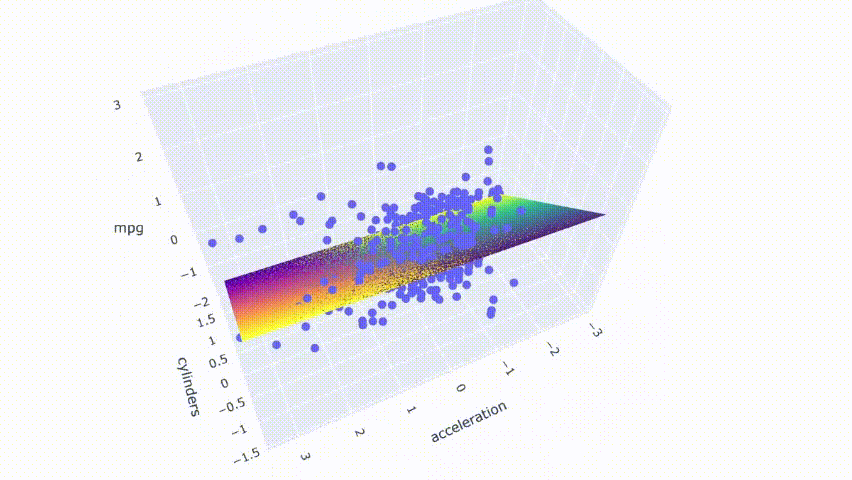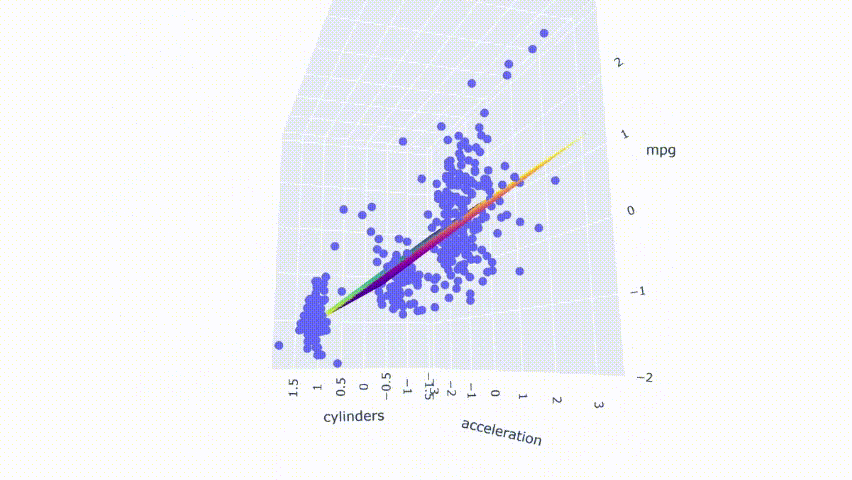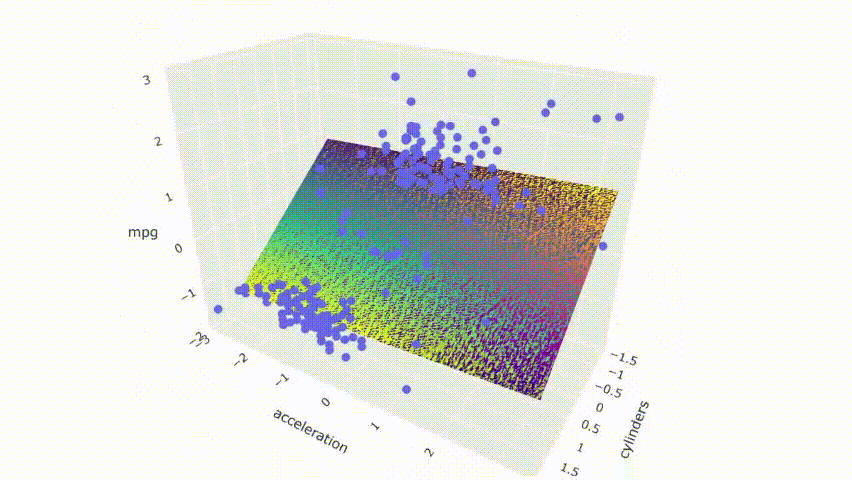
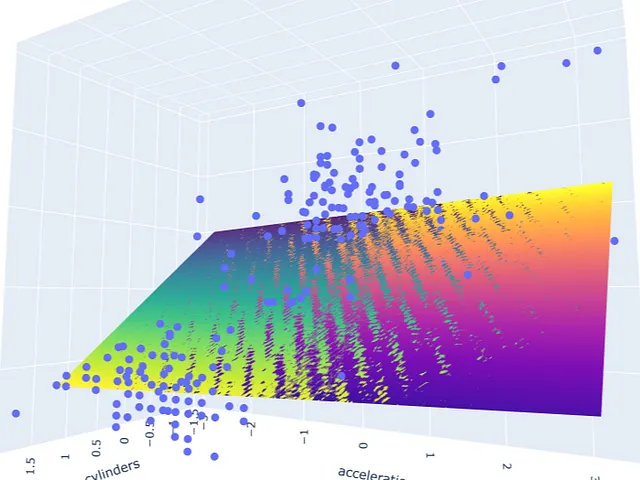
Se puede observar que ambos modelos se superponen ya que los colores de los dos planos están mezclados en el resultado. Por último, haga el mismo proceso con los modelos con predictores moderadamente correlacionados.
# ejecutar el modelopred_m2 = model_m2.predict(np.c_[xx2.ravel(), yy2.ravel()])pred_m2 = pred_m2.reshape(xx2.shape)# graficar el resultadofig = px.scatter_3d(df_m, x='cylinders', y='displacement', z='mpg')fig.update_traces(marker=dict(size=5))fig.add_traces(go.Surface(x=xr2, y=yr2, z=pred2, name='pred'))fig.add_traces(go.Surface(x=xr2, y=yr2, z=pred_m2, name='pred_m2', colorscale = 'viridis_r'))fig.show()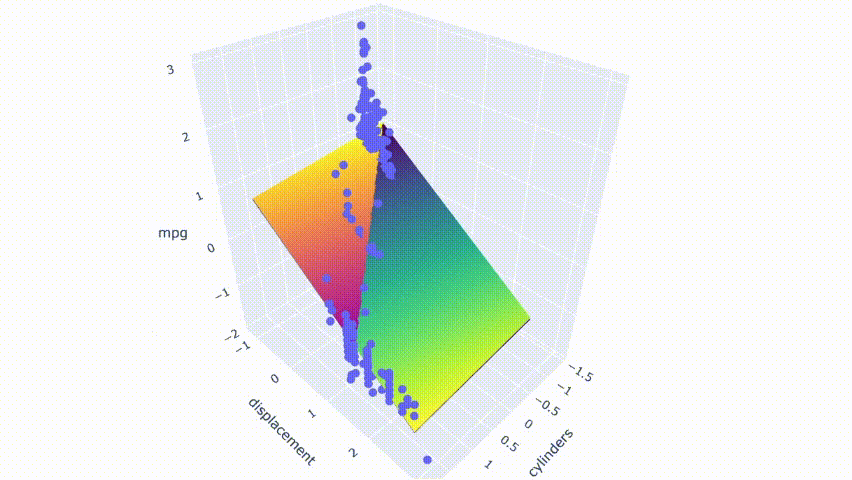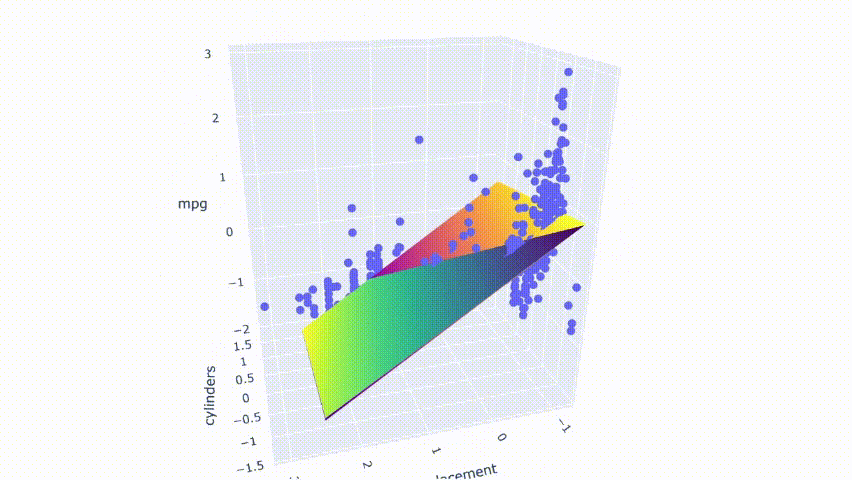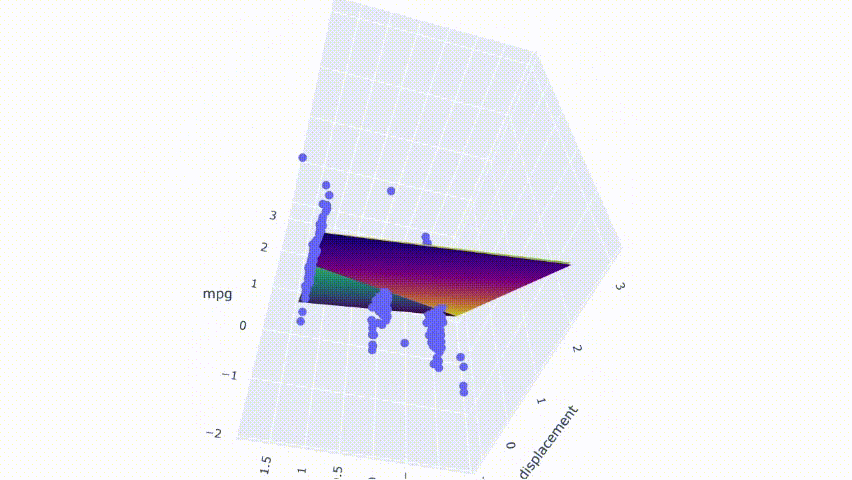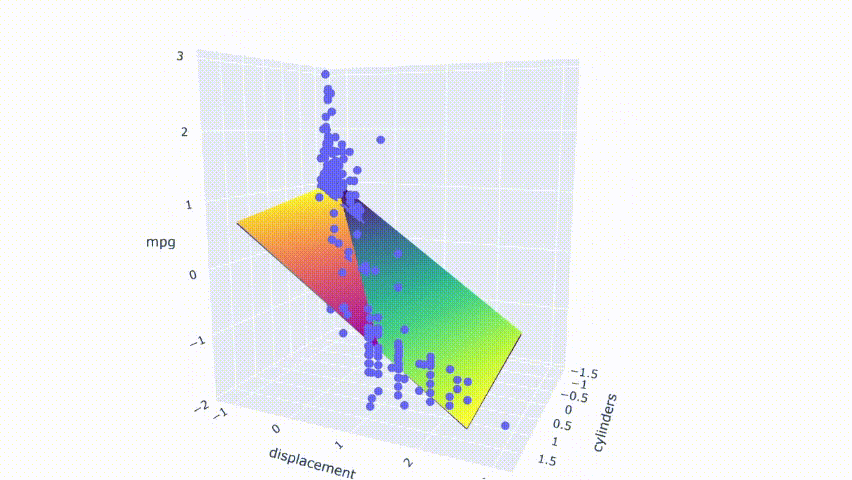
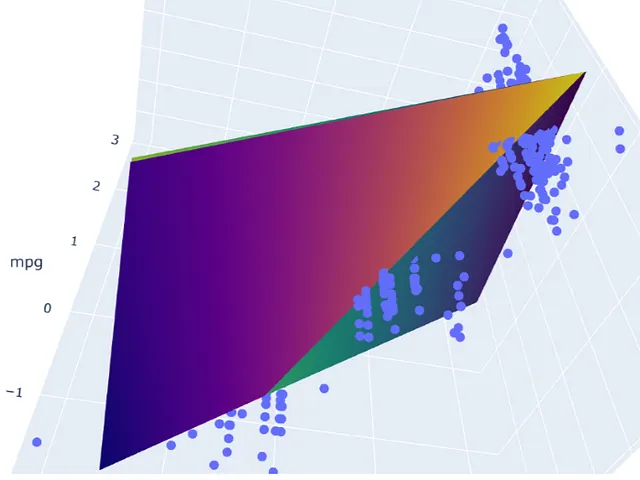
El resultado muestra que ambos modelos no se superponen perfectamente. Se cortan entre sí y producen una pequeña brecha entre los modelos.
Tenga en cuenta que estos gráficos se seleccionan modificando aleatoriamente una fila en el conjunto de datos. El primer modelo no está libre de multicolinealidad. Todavía tiene predictores moderadamente correlacionados. A partir del mapa de calor, también se ve afectado por el cambio en algunos casos. Sin embargo, el cambio produce menos consecuencias en comparación con el segundo modelo.
Resumen
Este artículo aplica la visualización de datos para expresar el efecto de la multicolinealidad en los modelos de regresión múltiple comparando dos modelos, uno con predictores moderadamente correlacionados y otro con predictores altamente correlacionados. También se realiza la modificación de los datos originales para ver qué modelos sufrirán más por los pequeños cambios en los datos.
El resultado muestra que cuanto más un modelo tiene predictores altamente correlacionados, más los coeficientes del modelo sufren por los datos cambiantes e inestables. Por lo tanto, explicar cada predictor en el modelo con el problema de multicolinealidad puede ser difícil.
Estos son mis artículos de visualización de datos que pueden resultar interesantes:
- 8 Visualizaciones con Python para manejar datos de series de tiempo múltiples (enlace)
- 9 Visualizaciones con Python que llaman más la atención que un gráfico de barras (enlace)
- 7 Visualizaciones con Python para expresar cambios en la clasificación con el tiempo (enlace)
- Battle Royale – Comparación de 7 bibliotecas de Python para gráficos financieros interactivos (enlace)
Referencias
- Wikimedia Foundation. (2023, 22 de febrero). Multicolinealidad. Wikipedia. https://en.wikipedia.org/wiki/Multicollinearity
- Choueiry, G. (2020, 1 de junio). Quantifying health. QUANTIFYING HEALTH. https://quantifyinghealth.com/vif-threshold/
- Frost, J. (2023, 29 de enero). Multicollinearity in regression analysis: Problems, detection, and solutions. Statistics By Jim. https://statisticsbyjim.com/regression/multicollinearity-in-regression-analysis/
- Rob Taylor, P. (2022, 1 de diciembre). Multicollinearity: Problem, or not? Zepes. https://towardsdatascience.com/multicollinearity-problem-or-not-d4bd7a9cfb91
- Stephanie. (2020, 16 de diciembre). Variance inflation factor. Statistics How To. https://www.statisticshowto.com/variance-inflation-factor/
- Cars data – conjunto de datos de dataman-udit. data.world. (24 de mayo de 2020). https://data.world/dataman-udit/cars-data
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Estudio Los modelos de IA no logran reproducir los juicios humanos sobre violaciones de reglas.
- Celebrando el impacto de IDSS
- Herramientas de Análisis de Datos que Necesitas Conocer en 2023
- Dominando el arte de la narración de datos Una guía para científicos de datos.
- Utilice Amazon SageMaker Canvas para construir modelos de aprendizaje automático utilizando datos Parquet de Amazon Athena y AWS Lake Formation.
- Vuelva a entrenar los modelos de aprendizaje automático y automatice las predicciones por lotes en Amazon SageMaker Canvas utilizando conjuntos de datos actualizados.
- 4 Funciones de Pandas para la comparación elemento a elemento de DataFrames






