Inmersión Profunda Vision Transformers en Hugging Face Optimum Graphcore
'Visión Transformers en Hugging Face Optimum Graphcore'
Esta publicación del blog mostrará lo fácil que es ajustar modelos Transformer pre-entrenados para su conjunto de datos utilizando la biblioteca Hugging Face Optimum en las Unidades de Procesamiento de Inteligencia (IPUs) de Graphcore. Como ejemplo, mostraremos una guía paso a paso y proporcionaremos un cuaderno que toma un conjunto de datos grande de radiografías de tórax ampliamente utilizado y entrena un modelo de transformer de visión (ViT).
Presentación de los modelos de transformer de visión (ViT)
En 2017, un grupo de investigadores de Google AI publicó un artículo presentando la arquitectura del modelo Transformer. Caracterizado por un mecanismo de auto-atención novedoso, los transformers se propusieron como un grupo nuevo y eficiente de modelos para aplicaciones de lenguaje. De hecho, en los últimos cinco años, los transformers han visto una popularidad explosiva y ahora se aceptan como el estándar de facto para el procesamiento del lenguaje natural (PLN).
Los transformers para el lenguaje están representados de manera notable por las familias de modelos GPT y BERT, que evolucionan rápidamente. Ambos pueden ejecutarse fácilmente y de manera eficiente en las IPUs de Graphcore como parte de la creciente biblioteca Optimum de Hugging Face Graphcore).
![]()
- OpenRAIL Hacia marcos de licencias de IA abiertos y responsables
- Entrena tu primer Decision Transformer
- ¿Qué hay de nuevo en los Difusores? 🎨
Se puede encontrar una explicación detallada sobre la arquitectura del modelo Transformer (con un enfoque en el PLN) en el sitio web de Hugging Face.
Aunque los transformers han tenido éxito inicialmente en el lenguaje, son extremadamente versátiles y se pueden utilizar para una variedad de otros propósitos, incluida la visión por computadora (CV), como veremos en esta publicación del blog.
La CV es un área donde las redes neuronales convolucionales (CNN) son, sin duda, la arquitectura más popular. Sin embargo, la arquitectura del transformer de visión (ViT), presentada por primera vez en un artículo de 2021 de Google Research, representa un avance en el reconocimiento de imágenes y utiliza el mismo mecanismo de auto-atención que BERT y GPT como su componente principal.
Mientras que BERT y otros modelos de procesamiento de lenguaje basados en transformers toman una oración (es decir, una lista de palabras) como entrada, los modelos ViT dividen una imagen de entrada en varios pequeños fragmentos, equivalentes a palabras individuales en el procesamiento del lenguaje. Cada fragmento es codificado linealmente por el modelo Transformer en una representación vectorial que se puede procesar individualmente. Este enfoque de dividir las imágenes en fragmentos o tokens visuales contrasta con las matrices de píxeles utilizadas por las CNN.
Gracias al pre-entrenamiento, el modelo ViT aprende una representación interna de las imágenes que luego se puede utilizar para extraer características visuales útiles para tareas posteriores. Por ejemplo, se puede entrenar un clasificador en un nuevo conjunto de datos de imágenes etiquetadas colocando una capa lineal encima del codificador visual pre-entrenado. Normalmente, se coloca una capa lineal encima del token [CLS], ya que el último estado oculto de este token se puede ver como una representación de una imagen completa.
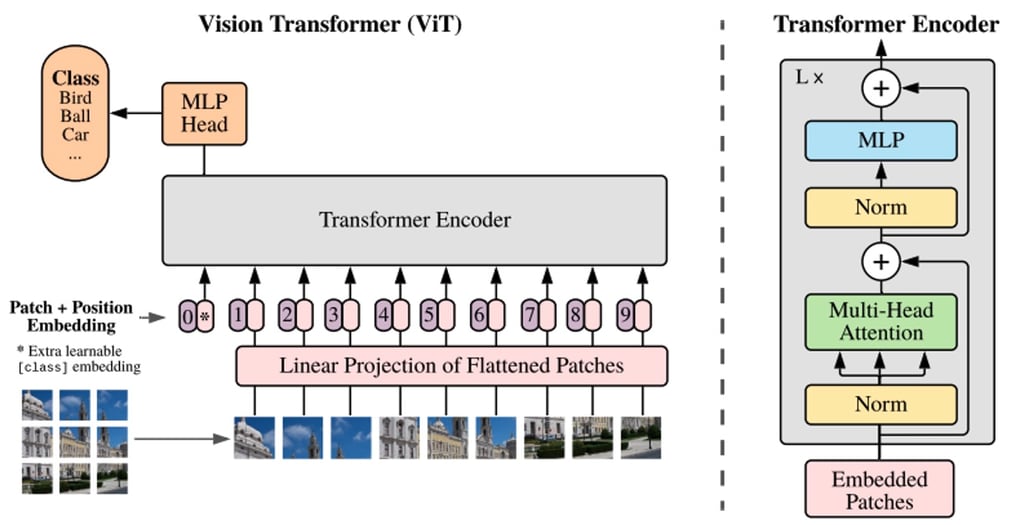
En comparación con las CNN, los modelos ViT han mostrado una mayor precisión de reconocimiento con un menor costo computacional, y se aplican a una variedad de aplicaciones que incluyen clasificación de imágenes, detección de objetos y segmentación. Los casos de uso en el ámbito de la atención médica incluyen la detección y clasificación de COVID-19, fracturas de fémur, enfisema, cáncer de mama y enfermedad de Alzheimer, entre muchos otros.
Modelos ViT – un ajuste perfecto para IPU
Las IPUs de Graphcore son particularmente adecuadas para los modelos ViT debido a su capacidad para paralelizar el entrenamiento mediante una combinación de canalización de datos y paralelismo de modelos. La aceleración de este proceso masivamente paralelo es posible gracias a la arquitectura MIMD de la IPU y su solución de escalamiento centrada en la IPU-Fabric.
Al introducir el paralelismo de canalización, se aumenta el tamaño del lote que se puede procesar por instancia de paralelismo de datos, se mejora la eficiencia de acceso al área de memoria manejada por una IPU y se reduce el tiempo de comunicación de agregación de parámetros para el aprendizaje paralelo de datos.
Gracias a la adición de una variedad de modelos de transformer pre-optimizados a la biblioteca Optimum de Graphcore de código abierto de Hugging Face, es increíblemente fácil alcanzar un alto grado de rendimiento y eficiencia al ejecutar y ajustar modelos como ViT en IPUs.
A través de Hugging Face Optimum, Graphcore ha lanzado puntos de control de modelos IPU pre-entrenados y archivos de configuración listos para usar para facilitar el entrenamiento de modelos con máxima eficiencia. Esto es particularmente útil ya que los modelos ViT generalmente requieren pre-entrenamiento en una gran cantidad de datos. Esta integración le permite utilizar los puntos de control lanzados por los propios autores originales dentro del repositorio de modelos de Hugging Face, por lo que no tendrá que entrenarlos usted mismo. Al permitir a los usuarios conectar y usar cualquier conjunto de datos público, Optimum acorta el ciclo de desarrollo general de los modelos de IA y permite una integración perfecta con el hardware de última generación de Graphcore, lo que proporciona un tiempo de valoración más rápido.
Para esta publicación de blog, utilizaremos un modelo ViT pre-entrenado en ImageNet-21k, basado en el artículo “Una imagen vale 16×16 palabras: Transformers para reconocimiento de imágenes a gran escala” de Dosovitskiy et al. Como ejemplo, le mostraremos el proceso de uso de Optimum para ajustar finamente ViT en el conjunto de datos ChestX-ray14.
El valor de los modelos ViT para la clasificación de rayos X
Al igual que con todas las tareas de imágenes médicas, los radiólogos pasan muchos años aprendiendo a detectar problemas de manera confiable y eficiente y a realizar diagnósticos tentativos en base a imágenes de rayos X. En gran medida, esta dificultad surge de las diferencias muy pequeñas y las limitaciones espaciales de las imágenes, por eso las técnicas de detección y diagnóstico asistido por computadora (CAD) han demostrado un gran potencial para mejorar los flujos de trabajo de los médicos y los resultados de los pacientes.
Al mismo tiempo, desarrollar cualquier modelo para la clasificación de rayos X (ViT u otro) conlleva sus propios desafíos:
- Entrenar un modelo desde cero requiere una gran cantidad de datos etiquetados;
- Los requisitos de alta resolución y volumen implican que se necesita una potencia informática poderosa para entrenar tales modelos; y
- La complejidad de los problemas de múltiples clases y múltiples etiquetas, como el diagnóstico pulmonar, se ve incrementada exponencialmente debido al número de categorías de enfermedades.
Como se mencionó anteriormente, para el propósito de nuestra demostración utilizando Hugging Face Optimum, no necesitamos entrenar ViT desde cero. En su lugar, utilizaremos los pesos del modelo alojados en el repositorio de modelos de Hugging Face.
Dado que una imagen de rayos X puede tener múltiples enfermedades, trabajaremos con un modelo de clasificación de múltiples etiquetas. El modelo en cuestión utiliza puntos de control google/vit-base-patch16-224-in21k. Se ha convertido desde el repositorio TIMM y se ha pre-entrenado en 14 millones de imágenes de ImageNet-21k. Para paralelizar y optimizar el trabajo para IPU, la configuración se ha puesto a disposición a través de la tarjeta de modelo Graphcore-ViT.
Si es la primera vez que utiliza IPUs, lea la Guía del programador de IPU para aprender los conceptos básicos. Para ejecutar su propio modelo de PyTorch en la IPU, consulte el tutorial básico de Pytorch y aprenda cómo utilizar Optimum a través de nuestros Cuadernos de Hugging Face Optimum.
Entrenando ViT en el conjunto de datos ChestXRay-14
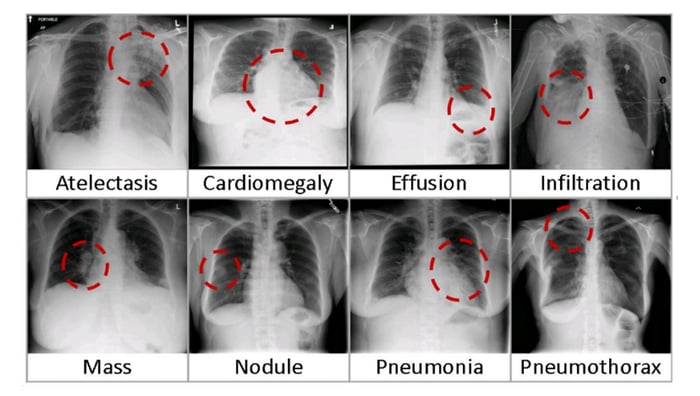
Primero, necesitamos descargar el conjunto de datos de Rayos X del Centro Clínico de los Institutos Nacionales de Salud (NIH). Este conjunto de datos contiene 112,120 rayos X de vista frontal desidentificados de 30,805 pacientes en un período desde 1992 hasta 2015. El conjunto de datos cubre una variedad de 14 enfermedades comunes basadas en etiquetas extraídas del texto de los informes de radiología utilizando técnicas de procesamiento del lenguaje natural (NLP).
Configuración del entorno
Aquí están los requisitos para ejecutar este tutorial:
- Un servidor de Jupyter Notebook con el último SDK de Poplar y el entorno PopTorch habilitado (consulte nuestra guía sobre cómo utilizar IPUs desde cuadernos Jupyter)
- El Cuaderno de entrenamiento ViT del repositorio de tutoriales de Graphcore
El repositorio de tutoriales de Graphcore contiene el cuaderno de tutorial paso a paso y el script en Python discutidos en esta guía. Clone el repositorio y ejecute el cuaderno walkthrough.ipynb que se encuentra en tutorials/tutorials/pytorch/vit_model_training/.
Incluso lo hemos facilitado y creado el HF Optimum Gradient para que pueda lanzar el tutorial de inicio rápido en IPUs gratuitas. Regístrese y ejecute el entorno: ![]()
Obteniendo el conjunto de datos
Descargue el directorio /images del conjunto de datos. Puede utilizar bash para extraer los archivos: for f in images*.tar.gz; do tar xfz “$f”; done.
A continuación, descargue el archivo Data_Entry_2017_v2020.csv, que contiene las etiquetas. Por defecto, el tutorial espera que la carpeta /images y el archivo .csv estén en la misma carpeta que el script que se está ejecutando.
Una vez que su entorno Jupyter tiene los conjuntos de datos, necesita instalar e importar el último paquete de Optimum Graphcore de Hugging Face y otras dependencias en requirements.txt:
%pip install -r requirements.txt
` `
Los exámenes contenidos en el conjunto de datos de radiografías de tórax consisten en imágenes de rayos X (escala de grises, 224×224 píxeles) con metadatos correspondientes: Etiquetas de búsqueda, Seguimiento #, ID de paciente, Edad del paciente, Género del paciente, Posición de visualización, Imagen original[Ancho Alto] y Espaciado de píxeles de imagen original[x y].
A continuación, definimos las ubicaciones de las imágenes descargadas y el archivo con las etiquetas a descargar en Obteniendo el conjunto de datos:
Vamos a entrenar el modelo Graphcore Optimum ViT para predecir enfermedades (definidas por “Etiqueta de búsqueda”) a partir de las imágenes. “Etiqueta de búsqueda” puede ser cualquiera de las 14 enfermedades o una etiqueta “No se encontró”, lo que indica que no se detectó ninguna enfermedad. Para ser compatible con la biblioteca Hugging Face, las etiquetas de texto deben transformarse en matrices codificadas N-hot que representan las etiquetas múltiples necesarias para clasificar cada imagen. Una matriz codificada N-hot representa las etiquetas como una lista de booleanos, verdadero si la etiqueta corresponde a la imagen y falso si no.
Primero identificamos las etiquetas únicas en el conjunto de datos.
Ahora transformamos las etiquetas en matrices codificadas N-hot:
Cuando se carga datos usando la función datasets.load_dataset, las etiquetas pueden proporcionarse ya sea teniendo carpetas para cada una de las etiquetas (ver documentación de “ImageFolder”) o teniendo un archivo metadata.jsonl (ver documentación de “ImageFolder con metadatos”). Como las imágenes en este conjunto de datos pueden tener múltiples etiquetas, hemos elegido usar un archivo metadata.jsonl. Escribimos los nombres de los archivos de imagen y sus etiquetas asociadas en el archivo metadata.jsonl.
Creando el conjunto de datos
Ahora estamos listos para crear el conjunto de datos de PyTorch y dividirlo en conjuntos de entrenamiento y validación. Este paso convierte el conjunto de datos al formato de archivo Arrow que permite cargar los datos rápidamente durante el entrenamiento y la validación (sobre Arrow y Hugging Face). Debido a que se carga y preprocesa todo el conjunto de datos, puede llevar algunos minutos.
Vamos a importar el modelo ViT desde el punto de control google/vit-base-patch16-224-in21k. El punto de control es un modelo estándar alojado por Hugging Face y no es administrado por Graphcore.
Para ajustar finamente un modelo preentrenado, el nuevo conjunto de datos debe tener las mismas propiedades que el conjunto de datos original utilizado para el preentrenamiento. En Hugging Face, la información del conjunto de datos original se proporciona en un archivo de configuración cargado usando AutoFeatureExtractor. Para este modelo, las imágenes de rayos X se redimensionan a la resolución correcta (224×224), se convierten de escala de grises a RGB y se normalizan en los canales RGB con una media (0.5, 0.5, 0.5) y una desviación estándar (0.5, 0.5, 0.5).
Para que el modelo se ejecute eficientemente, las imágenes deben agruparse en lotes. Para hacer esto, definimos la función vit_data_collator que devuelve lotes de imágenes y etiquetas en un diccionario, siguiendo el patrón default_data_collator en Transformers Data Collator.
Visualizando el conjunto de datos
Para examinar el conjunto de datos, mostramos las primeras 10 filas de metadatos.
También vamos a graficar algunas imágenes del conjunto de validación con sus etiquetas asociadas.
![]()
Nuestro conjunto de datos ahora está listo para ser utilizado.
Preparando el modelo
Para entrenar un modelo en la IPU, necesitamos importarlo desde Hugging Face Hub y definir un entrenador usando la clase IPUTrainer. La clase IPUTrainer toma los mismos argumentos que el entrenador Transformer original y funciona en conjunto con el objeto IPUConfig que especifica el comportamiento para la compilación y ejecución en la IPU.
Ahora importamos el modelo ViT desde Hugging Face.
Para usar este modelo en la IPU, necesitamos cargar la configuración de la IPU, IPUConfig, que proporciona el control de todos los parámetros específicos de las IPUs de Graphcore (las configuraciones de IPU existentes se pueden encontrar aquí). Vamos a utilizar Graphcore/vit-base-ipu.
Configuremos nuestros hiperparámetros de entrenamiento usando IPUTrainingArguments. Esto es una subclase de la clase TrainingArguments de Hugging Face, que agrega parámetros específicos para el IPU y sus características de ejecución.
Implementando una métrica de desempeño personalizada para evaluación
El desempeño de modelos de clasificación multi-etiqueta puede ser evaluado utilizando el área bajo la curva ROC (característica de operación del receptor) (AUC_ROC). El AUC_ROC es una gráfica de la tasa de verdaderos positivos (TPR) versus la tasa de falsos positivos (FPR) de diferentes clases y en diferentes valores de umbral. Esta es una métrica de desempeño comúnmente utilizada para tareas de clasificación multi-etiqueta, ya que es insensible al desbalance de clases y fácil de interpretar.
Para este conjunto de datos, el AUC_ROC representa la habilidad del modelo para separar las diferentes enfermedades. Un puntaje de 0.5 significa que tiene un 50% de probabilidad de obtener la enfermedad correcta y un puntaje de 1 significa que puede separar perfectamente las enfermedades. Esta métrica no está disponible en Datasets, por lo tanto necesitamos implementarla nosotros mismos. El paquete HuggingFace Datasets permite el cálculo de métricas personalizadas a través de la función load_metric(). Definimos una función compute_metrics y la exponemos a la función de evaluación del Transformer, al igual que las otras métricas admitidas a través del paquete datasets. La función compute_metrics recibe las etiquetas predichas por el modelo ViT y calcula el área bajo la curva ROC. La función compute_metrics recibe un objeto EvalPrediction (una tupla con los campos predictions y label_ids) y debe devolver un diccionario de cadena a flotante.
Para entrenar el modelo, definimos un entrenador usando la clase IPUTrainer, que se encarga de compilar el modelo para ejecutarse en IPUs, y de realizar el entrenamiento y la evaluación. La clase IPUTrainer funciona de manera similar a la clase Trainer de Hugging Face, pero toma el argumento adicional ipu_config.
Ejecutando el entrenamiento
Para acelerar el entrenamiento, cargaremos el último punto de control si existe.
Ahora estamos listos para entrenar.
Graficando la convergencia
Ahora que hemos completado el entrenamiento, podemos formatear y graficar la salida del entrenador para evaluar el comportamiento del entrenamiento.
Graficamos la pérdida de entrenamiento y la tasa de aprendizaje.
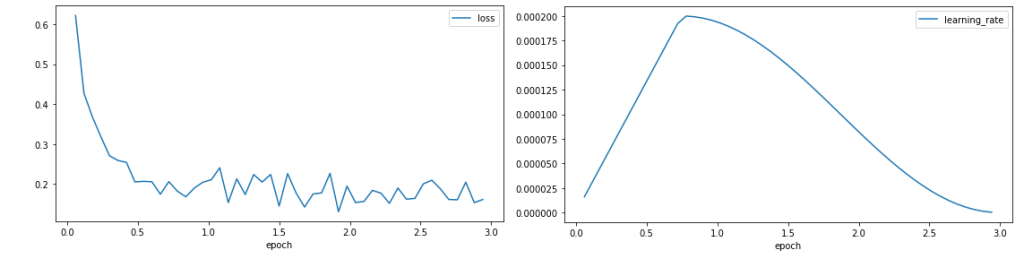 La curva de pérdida muestra una reducción rápida en la pérdida al comienzo del entrenamiento antes de estabilizarse alrededor de 0.1, lo que indica que el modelo está aprendiendo. La tasa de aprendizaje aumenta durante el período de calentamiento del 25% del período de entrenamiento, antes de seguir una decaída coseno.
La curva de pérdida muestra una reducción rápida en la pérdida al comienzo del entrenamiento antes de estabilizarse alrededor de 0.1, lo que indica que el modelo está aprendiendo. La tasa de aprendizaje aumenta durante el período de calentamiento del 25% del período de entrenamiento, antes de seguir una decaída coseno.
Ejecutando la evaluación
Ahora que hemos entrenado el modelo, podemos evaluar su capacidad para predecir las etiquetas de datos no vistos utilizando el conjunto de datos de validación.
Las métricas muestran el puntaje de AUC_ROC de validación que el tutorial logra después de 3 épocas.
Existen varias direcciones a explorar para mejorar la precisión del modelo, incluyendo un entrenamiento más largo. El desempeño de validación también podría mejorarse mediante cambios en los optimizadores, tasa de aprendizaje, programación de la tasa de aprendizaje, escalamiento de pérdida o uso de escalamiento automático de pérdida.
Prueba Hugging Face Optimum en IPUs gratis
En esta publicación, hemos presentado los modelos ViT y hemos proporcionado un tutorial para entrenar un modelo Hugging Face Optimum en el IPU utilizando un conjunto de datos local.
El proceso completo descrito anteriormente puede ejecutarse de principio a fin en cuestión de minutos de forma gratuita, gracias a la nueva asociación de Graphcore con Paperspace. A partir de hoy, el servicio proporcionará acceso a una selección de modelos Hugging Face Optimum con IPUs de Graphcore dentro de Gradient, los cuadernos basados en web de Jupyter de Paperspace.
![]()
Si estás interesado en probar Hugging Face Optimum con IPUs en Paperspace Gradient, incluyendo ViT, BERT, RoBERTa y más, puedes registrarte aquí y encontrar una guía de inicio aquí.
Más recursos para Hugging Face Optimum en IPUs
- Código de tutorial de ViT Optimum en GitHub de Graphcore
- Modelos y conjuntos de datos de Hugging Face de Graphcore
- Optimum Graphcore en GitHub
Esta inmersión profunda no hubiera sido posible sin el extenso apoyo, orientación y conocimientos de Eva Woodbridge, James Briggs, Jinchen Ge, Alexandre Payot, Thorin Farnsworth y todos los demás contribuyentes de Graphcore, así como Jeff Boudier, Julien Simon y Michael Benayoun de Hugging Face.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo entrenar un Modelo de Lenguaje con Megatron-LM
- SetFit Aprendizaje Eficiente de Pocos Ejemplos Sin Indicaciones
- Cómo 🤗 Accelerate ejecuta modelos muy grandes gracias a PyTorch
- Clasificación de imágenes con AutoTrain
- Difusión estable en japonés
- Presentamos DOI el Identificador de Objeto Digital para Conjuntos de Datos y Modelos
- Historia de optimización Inferencia de Bloom






