Problema del Gradiente Desvaneciente Causas, Consecuencias y Soluciones.
Vanishing Gradient Problem Causes, Consequences, and Solutions.
Esta publicación de blog tiene como objetivo describir el problema del gradiente desvaneciente y explicar cómo el uso de la función sigmoidea resultó en él.
La función sigmoidal es una de las funciones de activación más populares utilizadas para el desarrollo de redes neuronales profundas. El uso de la función sigmoidal restringió el entrenamiento de redes neuronales profundas porque causó el problema del gradiente desvaneciente. Esto hizo que la red neuronal aprendiera a un ritmo más lento o, en algunos casos, no aprendiera nada. Este blog tiene como objetivo describir el problema del gradiente desvaneciente y explicar cómo el uso de la función sigmoidal resultó en él.
Función sigmoidal
Las funciones sigmoidales se utilizan con frecuencia en redes neuronales para activar neuronas. Es una función logarítmica con una forma característica de S. El valor de salida de la función está entre 0 y 1. La función sigmoidal se utiliza para activar las capas de salida en problemas de clasificación binaria. Se calcula de la siguiente manera:
- Eliminación y destilación arquitectural Un camino hacia la compresión eficiente en modelos de difusión texto-imagen en IA.
- Google AI presenta Imagen Editor y EditBench para mejorar y evaluar el rellenado de imágenes guiado por texto.
- AI Ve lo que tú Ves Mind’s Eye es un Modelo de IA que Puede Reconstruir Escaneos Cerebrales en Imágenes.
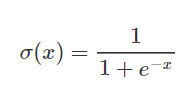
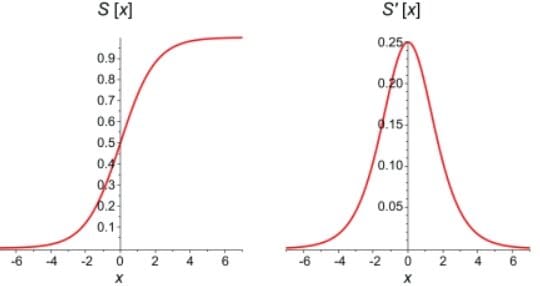
En el gráfico a continuación se puede ver una comparación entre la función sigmoidal en sí misma y su derivada. Las primeras derivadas de las funciones sigmoidales son curvas de campana con valores que van de 0 a 0,25.
Nuestro conocimiento de cómo las redes neuronales realizan la propagación hacia adelante y hacia atrás es esencial para comprender el problema del gradiente desvaneciente.
Propagación hacia adelante
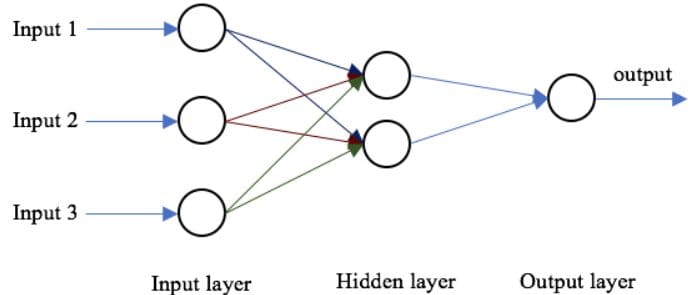
La estructura básica de una red neuronal es una capa de entrada, una o más capas ocultas y una sola capa de salida. Los pesos de la red se inicializan aleatoriamente durante la propagación hacia adelante. Las características de entrada se multiplican por los pesos correspondientes en cada nodo de la capa oculta, y se agrega un sesgo a la suma neta en cada nodo. Luego, este valor se transforma en la salida del nodo utilizando una función de activación. Para generar la salida de la red neuronal, la salida de la capa oculta se multiplica por los pesos más los valores del sesgo, y el total se transforma utilizando otra función de activación. Este será el valor predicho de la red neuronal para un valor de entrada dado.
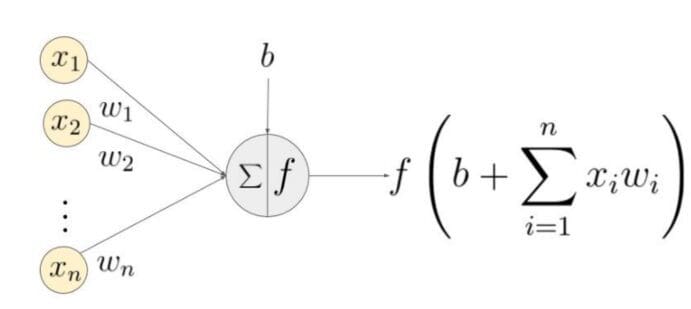
Propagación hacia atrás
A medida que la red genera una salida, la función de pérdida (C) indica qué tan bien predijo la salida. La red realiza una propagación hacia atrás para minimizar la pérdida. Un método de propagación hacia atrás minimiza la función de pérdida ajustando los pesos y sesgos de la red neuronal. En este método, se calcula el gradiente de la función de pérdida con respecto a cada peso en la red.
En la propagación hacia atrás, el nuevo peso (w new ) de un nodo se calcula utilizando el peso antiguo (w old ) y el producto de la tasa de aprendizaje (ƞ) y el gradiente de la función de pérdida 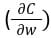
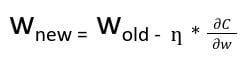
Con la regla de la cadena de derivadas parciales, podemos representar el gradiente de la función de pérdida como un producto de gradientes de todas las funciones de activación de los nodos con respecto a sus pesos. Por lo tanto, los pesos actualizados de los nodos en la red dependen de los gradientes de las funciones de activación de cada nodo.
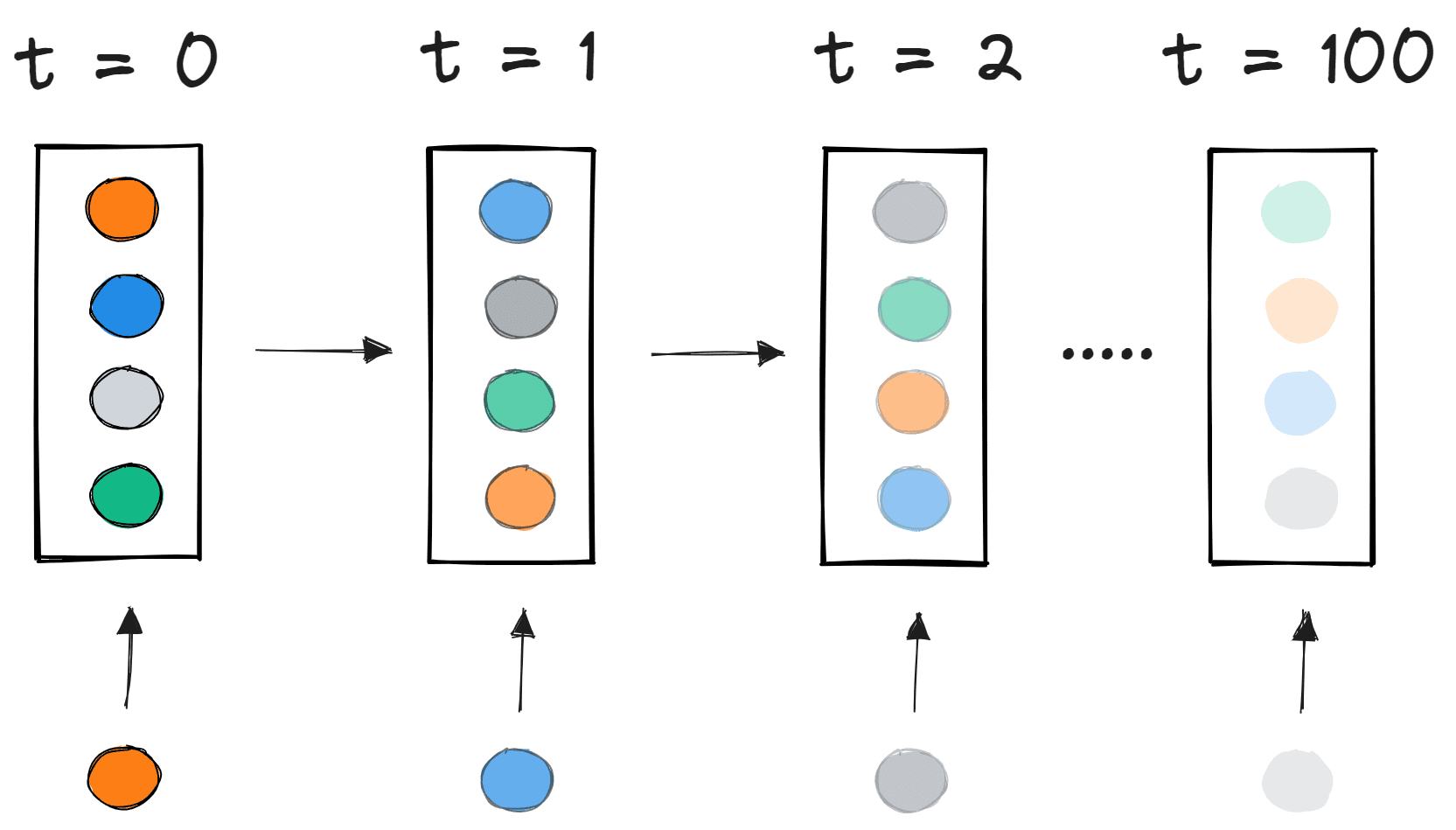
Para los nodos con funciones de activación sigmoidales, sabemos que la derivada parcial de la función sigmoidal alcanza un valor máximo de 0,25. Cuando hay más capas en la red, el valor del producto de la derivada disminuye hasta que en algún punto la derivada parcial de la función de pérdida se acerca a un valor cercano a cero, y la derivada parcial desaparece. A esto lo llamamos problema del gradiente desvaneciente.
Con redes poco profundas, la función sigmoidal se puede utilizar ya que el pequeño valor del gradiente no se convierte en un problema. Cuando se trata de redes profundas, el gradiente desvaneciente podría tener un impacto significativo en el rendimiento. Los pesos de la red permanecen sin cambios a medida que la derivada desaparece. Durante la propagación hacia atrás, una red neuronal aprende actualizando sus pesos y sesgos para reducir la función de pérdida. En una red con gradiente desvaneciente, los pesos no se pueden actualizar, por lo que la red no puede aprender. El rendimiento de la red disminuirá como resultado.
Método para superar el problema
El problema del gradiente desvaneciente se debe a la derivada de la función de activación utilizada para crear la red neuronal. La solución más sencilla al problema es reemplazar la función de activación de la red. En lugar de sigmoidal, utilice una función de activación como ReLU.
Las unidades lineales rectificadas (ReLU) son funciones de activación que generan una salida lineal positiva cuando se aplican a valores de entrada positivos. Si la entrada es negativa, la función devolverá cero.
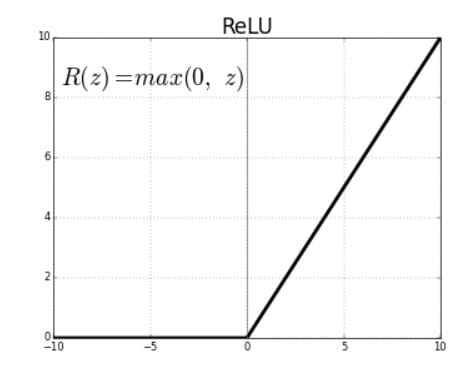
La derivada de una función ReLU se define como 1 para entradas que son mayores que cero y 0 para entradas que son negativas. El gráfico compartido a continuación indica la derivada de una función ReLU
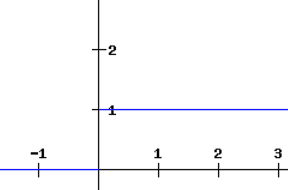
Si la función ReLU se utiliza para la activación en una red neuronal en lugar de una función sigmoide, el valor de la derivada parcial de la función de pérdida tendrá valores de 0 o 1 lo que impide que el gradiente desaparezca. El uso de la función ReLU evita que el gradiente desaparezca. El problema con el uso de ReLU es cuando el gradiente tiene un valor de 0. En tales casos, el nodo se considera como un nodo muerto ya que los valores antiguos y nuevos de los pesos permanecen iguales. Esta situación puede evitarse mediante el uso de una función de ReLU con fugas que impide que el gradiente caiga al valor cero.
Otra técnica para evitar el problema del gradiente desvaneciente es la inicialización de pesos. Este es el proceso de asignar valores iniciales a los pesos en la red neuronal para que durante la retropropagación, los pesos nunca desaparezcan.
En conclusión, el problema del gradiente desvaneciente surge de la naturaleza de la derivada parcial de la función de activación utilizada para crear la red neuronal. El problema puede empeorar en redes neuronales profundas que utilizan la función de activación sigmoide. Se puede reducir significativamente mediante el uso de funciones de activación como ReLU y ReLU con fugas.
Tina Jacob es apasionada de la ciencia de datos y cree que la vida se trata de aprender y crecer sin importar lo que traiga.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Forjado en Llamas Startup fusiona la IA Generativa y la Visión por Computadora para Combatir los Incendios Forestales.
- Escribir canciones con GPT-4 Parte 3, Melodías
- Una historia de RAPIDS, de ida y vuelta…
- Desentrañando el patrón de diseño de redes neuronales informadas por la física Parte 06.
- Búsqueda de similitud, Parte 1 kNN e Índice de Archivo Invertido
- Explorando la afinación de instrucciones en modelos de lenguaje conoce Tülu, una suite de modelos de lenguaje grandes (LLMs) afinados.
- Aprendizaje por Refuerzo Profundo mejora algoritmos de ordenamiento






