V-Net, el hermano mayor de U-Net en la segmentación de imágenes
V-Net, el hermano mayor de U-Net en segmentación de imágenes.
Bienvenido a esta guía sobre el V-Net, el primo del bien conocido U-Net, para la segmentación de imágenes 3D. ¡Lo conocerás a fondo!
¡Bienvenido a un emocionante viaje por el mundo de las arquitecturas de aprendizaje profundo! Es posible que ya estés familiarizado con U-Net, un cambio de juego en la visión por computadora que ha remodelado significativamente el panorama de la segmentación de imágenes.
Hoy, pongamos el foco en el hermano mayor de U-Net, el V-Net.
Publicado por los investigadores Fausto Milletari, Nassir Navab y Seyed-Ahmad Ahmadi, el artículo “VNet: Redes neuronales completamente convolucionales para la segmentación de imágenes médicas volumétricas” introdujo una metodología innovadora para el análisis de imágenes 3D.
Este artículo te llevará en un recorrido por este revolucionario artículo, arrojando luz sobre sus contribuciones únicas y avances arquitectónicos. Ya seas un científico de datos experimentado, un entusiasta del IA incipiente o simplemente alguien interesado en las últimas tendencias tecnológicas, ¡aquí encontrarás algo para ti!
- Una Introducción Suave al Aprendizaje Profundo Bayesiano
- Olvida ChatGPT, este nuevo asistente de IA está a años luz y cambiará la forma en que trabajas para siempre
- Revisión de Synthesys ¿El mejor generador de videos de IA? (agosto de 2023)
Un recordatorio breve sobre U-Net
Antes de adentrarnos en el corazón de V-Net, tomémonos un momento para apreciar su inspiración arquitectónica: U-Net. No te preocupes si esta es tu primera introducción a U-Net; tengo todo cubierto con un tutorial rápido y sencillo sobre la arquitectura de U-Net. ¡Es tan conciso que comprenderás el concepto en no más de cinco minutos!
Aquí tienes una breve descripción general de U-Net para refrescar la memoria:
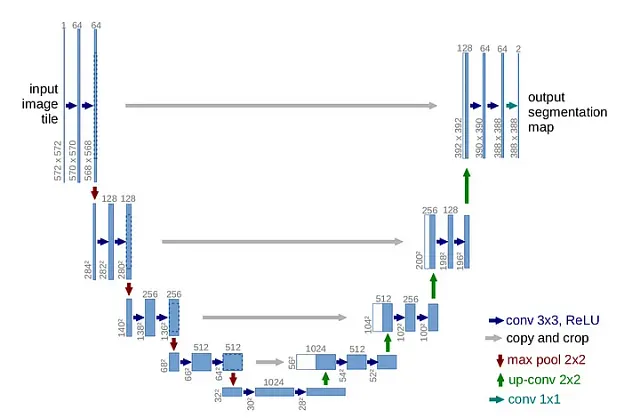
U-Net es famoso por su estructura simétrica, que adopta la forma de una ‘U’. Esta arquitectura se compone de dos vías distintas:
- Vía Contractiva (Izquierda): Aquí, disminuimos progresivamente la resolución de la imagen mientras aumentamos el número de filtros.
- Vía Expansiva (Derecha): Esta vía actúa como la imagen espejo de la vía contractiva. Disminuimos gradualmente el número de filtros mientras aumentamos la resolución hasta que se alinea con el tamaño original de la imagen.
La belleza de U-Net radica en su uso innovador de ‘conexiones residuales’ o ‘conexiones saltadas’. Estas conexiones conectan capas correspondientes en las vías contractivas y expansivas, permitiendo que la red retenga detalles de alta resolución que generalmente se pierden en el proceso contractivo.
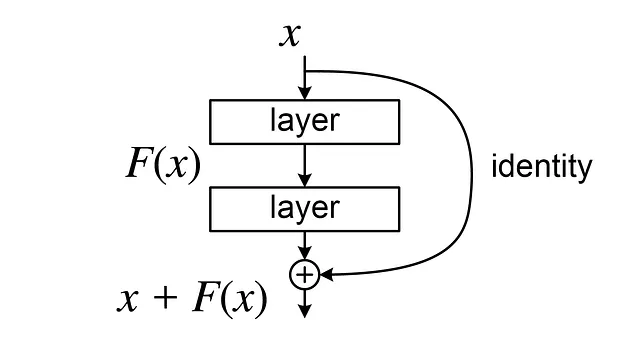
¿Por qué es esto importante? Porque facilita el flujo de gradientes durante la retropropagación, especialmente en las capas iniciales. En esencia, evitamos el riesgo de gradientes desvanecientes, un problema común en el que los gradientes se acercan a cero, dificultando el proceso de aprendizaje:
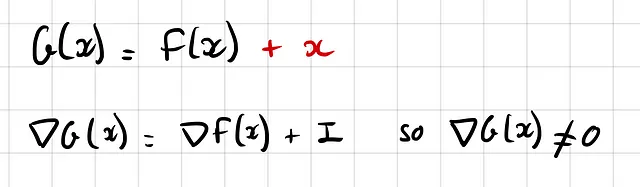
Ahora, teniendo en cuenta esta comprensión de U-Net, pasemos al mundo de V-Net. En su núcleo, V-Net comparte una filosofía similar de codificador-decodificador. Pero como descubrirás pronto, viene con su propio conjunto de rasgos únicos que lo diferencian de su hermano, U-Net.
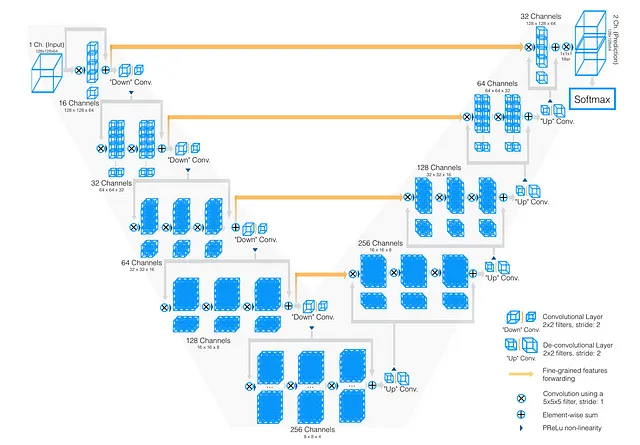
¿Qué diferencia a V-Net de U-Net?
¡Vamos a sumergirnos!
Diferencia 1: Convoluciones 3D en lugar de convoluciones 2D
La primera diferencia es clara como el día. Mientras que U-Net fue diseñado para la segmentación de imágenes 2D, las imágenes médicas a menudo requieren una perspectiva en 3D (piensa en exploraciones cerebrales volumétricas, tomografías computarizadas, etc.).
Aquí es donde entra en juego V-Net. La ‘V’ en V-Net significa ‘Volumétrico’, y este cambio de dimensionalidad requiere reemplazar las convoluciones 2D por convoluciones 3D.
Diferencia 2: Funciones de activación, PreLU en lugar de ReLU
El campo del aprendizaje profundo se ha enamorado de la función ReLU, debido a su simplicidad y eficiencia computacional. En comparación con otras funciones como la sigmoide o la tangente hiperbólica, ReLU es “no saturante”, lo que significa que reduce el problema de los gradientes que desaparecen.
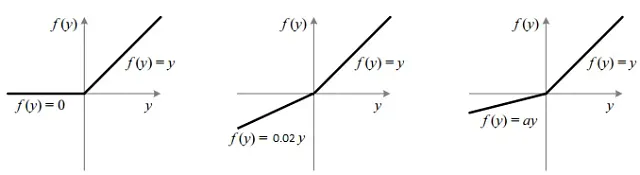
Pero ReLU no es perfecto. Es conocido por un fenómeno conocido como el “problema de ReLU moribundo”, donde muchas neuronas siempre producen cero, convirtiéndose en “neuronas muertas”. Para contrarrestar esto, se introdujo LeakyReLU, que tiene una pendiente pequeña pero distinta de cero en el lado izquierdo de cero.
Llevando el razonamiento aún más lejos, V-Net utiliza la ReLU Paramétrica (PReLU). ¿Por qué codificar la pendiente de LeakyReLU de forma rígida, cuando podemos permitir que la red la aprenda?
Después de todo, esta es una filosofía fundamental del aprendizaje profundo: queremos poner la menor cantidad de sesgo inductivo posible y permitir que el modelo aprenda todo por sí mismo, asumiendo que tenemos suficientes datos.
Diferencia 3: Función de pérdida diferente basada en el coeficiente de Dice
Ahora, llegamos quizás a la contribución más impactante de V-Net: un cambio en la función de pérdida. A diferencia de la función de pérdida de entropía cruzada de U-Net, V-Net utiliza la función de pérdida de Dice.

Pero el principal problema con esta función es que no maneja bien las clases desequilibradas. Y este problema es muy frecuente en las imágenes médicas, porque la mayoría de las veces el fondo está mucho más presente que la zona de interés.
Por ejemplo, considera esta imagen:
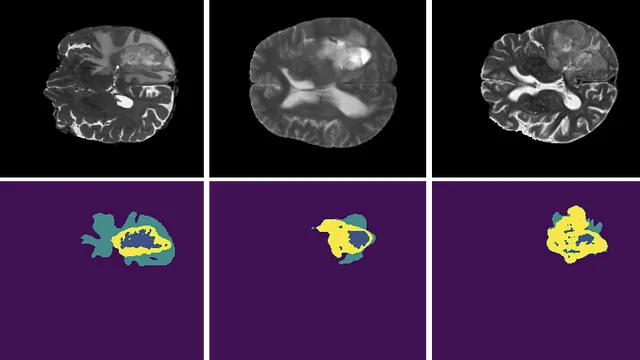
Como resultado, algunos modelos pueden volverse “perezosos” y predecir el fondo en todas partes porque aún obtendrán una pérdida pequeña.
Entonces, V-Net utiliza una función de pérdida que es mucho más efectiva para este problema: el coeficiente de Dice.
La razón por la que es mejor es que mide la superposición entre la zona predicha y la verdad fundamental como una proporción, por lo que se tiene en cuenta el tamaño de la clase.
Aunque el fondo está casi en todas partes, el coeficiente de Dice mide la superposición entre la predicción y la verdad fundamental, por lo que todavía obtenemos un número entre 0 y 1 incluso si la clase es preponderante.
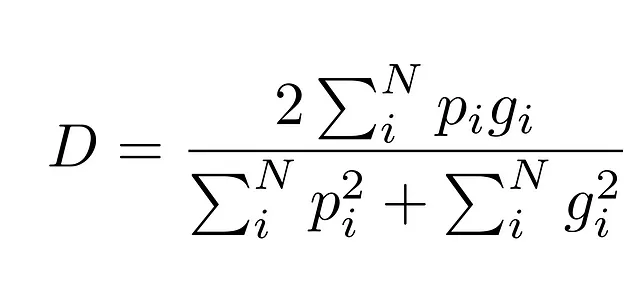
Digo que esta es tal vez la principal contribución del artículo porque pasar de convoluciones 2D a 3D es una idea muy natural para manejar imágenes 3D. Sin embargo, esta función de pérdida se ha adoptado ampliamente en las tareas de segmentación de imágenes.
En la práctica, a menudo se demuestra que un enfoque híbrido es efectivo, combinando la Pérdida de Entropía Cruzada y la Pérdida de Dado para aprovechar las fortalezas de ambos.
El rendimiento de la V-Net
Entonces, hemos recorrido los aspectos únicos de V-Net, pero probablemente estés pensando, “Toda esta teoría es genial, ¿pero realmente V-Net cumple en la práctica?” Bueno, ¡pongamos a prueba a V-Net!
Los autores evaluaron el rendimiento de V-Net en el conjunto de datos PROMISE12.
El conjunto de datos PROMISE12 se puso a disposición para el desafío de segmentación de próstata MICCAI 2012.
V-Net se entrenó con 50 imágenes de Resonancia Magnética (RM), ¡esto no es mucho!
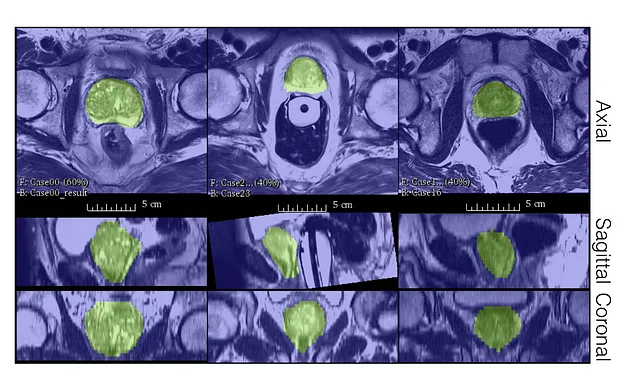
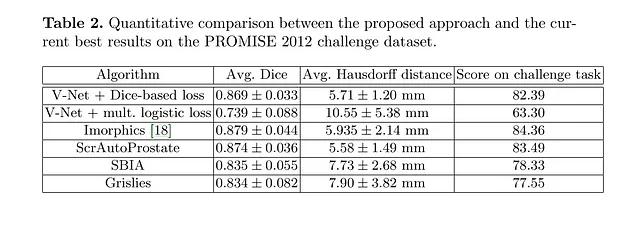
Como podemos ver, incluso con pocas etiquetas, V-Net es capaz de producir segmentaciones cualitativas buenas y obtener un puntaje de Dice muy bueno.
Principales limitaciones de V-Net
De hecho, V-Net ha establecido un nuevo referente en el ámbito de la segmentación de imágenes, especialmente en imágenes médicas. Sin embargo, toda innovación tiene margen de mejora. Aquí discutiremos algunas de las áreas prominentes en las que V-Net podría mejorar:
Limitación 1: Tamaño del modelo
La transición de 2D a 3D conlleva un aumento significativo en el consumo de memoria. Los efectos de esta aumento son múltiples:
- El modelo requiere un espacio de memoria sustancial.
- Limita severamente el tamaño del lote (cargar múltiples tensores 3D en la memoria de la GPU se vuelve desafiante).
- Los datos de imágenes médicas son dispersos y costosos de etiquetar, lo que dificulta ajustar un modelo con tantos parámetros.
Limitación 2: No utiliza aprendizaje no supervisado o aprendizaje auto-supervisado
- V-Net opera puramente en un contexto de aprendizaje supervisado, descuidando el potencial del aprendizaje no supervisado. En un campo donde las exploraciones no etiquetadas superan significativamente a las anotadas, incorporar el aprendizaje no supervisado podría ser un cambio de juego.
Limitación 3: No hay estimación de incertidumbre
- V-Net no estima incertidumbres, lo que significa que no puede evaluar su propia confianza en sus predicciones. Esta es un área donde brilla el Aprendizaje Profundo Bayesiano. (Consulta esta publicación para una Introducción Sencilla al Aprendizaje Profundo Bayesiano).
Limitación 4: Falta de robustez
- Las Redes Neuronales Convolucionales (CNN) tradicionalmente tienen dificultades con la generalización. No son robustas ante variaciones como el cambio de contraste, las distribuciones multimodales o las diferentes resoluciones. Esta es otra área en la que V-Net podría mejorar.
Conclusión
V-Net, el contraparte menos conocido pero poderoso de U-Net, ha revolucionado la visión por computadora, especialmente la segmentación de imágenes. Su transición de imágenes 2D a 3D y la introducción del coeficiente de Dice, ahora una herramienta ubicua, establecieron nuevos estándares en el campo.
A pesar de sus limitaciones, V-Net debería ser el modelo preferido para cualquier persona que se embarque en una tarea de segmentación de imágenes 3D. Para una mejora adicional, explorar el aprendizaje no supervisado y la integración de mecanismos de atención parece ser un camino prometedor.
Ya sea que tengas comentarios, ideas para compartir, quieras trabajar conmigo o simplemente quieras saludar, completa el formulario a continuación y comencemos una conversación.
Di hola 🌿
No dudes en dejar un aplauso o seguirme para más!
Referencias
- Cocinando tu primer U-Net para Segmentación de Imágenes
- Una Introducción Sencilla al Aprendizaje Profundo Bayesiano
- Milletari, F., Navab, N., & Ahmadi, S. A. (2016). V-Net: Redes Neuronales Totalmente Convolucionales para Segmentación de Imágenes Médicas Volumétricas. En Visión 3D (3DV), Cuarta Conferencia Internacional de 2016 sobre (pp. 565–571). IEEE.
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Redes Convolucionales para Segmentación de Imágenes Biomédicas. En Conferencia Internacional sobre Informática Médica y Asistencia Asistida por Computadora (pp. 234–241). Springer, Cham.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Despacho basado en datos
- Lectura de playa una breve historia de los modelos pre-entrenados
- La evolución de OpenAI Una carrera hacia GPT5
- ¿Qué puedes hacer cuando la inteligencia artificial miente sobre ti?
- OpenAI presenta 6 emocionantes características de ChatGPT para revolucionar la experiencia del usuario
- Clasificación Multietiqueta Una Introducción con Scikit-Learn de Python
- Fraude impulsado por IA ‘Deepfake’ La batalla continua de Kerala contra los estafadores






