Cómo utilizar el método loc de Pandas para trabajar eficientemente con su DataFrame.
Utilice el método loc de Pandas para trabajar eficientemente con su DataFrame.
PYTHON
Consejos para explorar y limpiar un nuevo conjunto de datos utilizando Pandas con ejemplos de código y explicaciones
Una parte clave de trabajar con un nuevo conjunto de datos es entenderlo.
Descubrir cosas básicas como qué columnas hay en los datos, cuáles son los tipos de datos en bruto y las estadísticas descriptivas de los datos son importantes para trabajar adecuadamente con los datos en el futuro.
Pandas tiene varios métodos integrados que puedes usar para explorar tus datos en un cuaderno de notas de inmediato. A medida que avanzas en los primeros pasos de la exploración de datos, puedes empezar a hacer que tus datos sean utilizables para un análisis posterior o para prepararlos para la formación de un modelo de aprendizaje automático.
En este artículo, trabajaremos con un conjunto de datos universitarios para responder las siguientes preguntas y mostrar cómo se ve cuando se explora y limpia datos al mismo tiempo:
- Cómo crear gráficos de violín con estilo Cyberpunk utilizando Seaborn con un mínimo de código Python.
- ¿Qué es la Gestión de Datos y por qué es importante?
- Más allá de la precisión Abrazando la serendipia y la novedad en recomendaciones para la retención a largo plazo del usuario.
- ¿Qué universidades solo ofrecen asistencia en persona?
- ¿Cuál es el rango de años entre las universidades más antiguas y las más nuevas fundadas?
Principalmente, vamos a utilizar el método loc combinado con algunos otros métodos integrados de Pandas para responder a estas preguntas. Primero, echaremos un vistazo rápido a lo que hace el método loc, luego pasaremos por cada uno de estos ejemplos paso a paso.
¡Siéntete libre de seguir en un cuaderno de notas! Puedes descargar el conjunto de datos de Kaggle disponible de forma gratuita para su uso bajo la Dedicatoria y Licencia de Dominio Público de Datos Abiertos (PDDL) v1.0. Luego, importa y ejecuta lo siguiente y podemos empezar:
import pandas as pddf_raw = pd.read_csv("Top-Largest-Universities.csv")Una breve introducción al método loc
Básicamente, el método loc en Pandas te permite seleccionar un subconjunto de filas o columnas del DataFrame objetivo en función de una condición dada.
Hay algunas entradas diferentes que puedes pasar a loc. Por ejemplo, cuando quieres seleccionar una sección del DataFrame basada en su índice, puedes usar la misma sintaxis en Python cuando estás trabajando con una lista como: [inicio:fin]. Sin embargo, en este artículo, nos centraremos principalmente en el uso de loc con una declaración condicional. Si has utilizado SQL antes, esto es similar a escribir la parte WHERE de una consulta para filtrar tus datos.
En general, usar loc de esta manera se verá así:
df.loc[df["columna"] == "condición"]Esto devolverá un subconjunto de tus datos en los que la columna es igual a la condición.
A continuación, pasemos a algunos ejemplos prácticos de uso del método loc durante el análisis exploratorio de datos para ver qué más puedes hacer con él.
Respondiendo preguntas sobre la asistencia universitaria usando el método Pandas loc
¿Qué universidades solo ofrecen asistencia en persona?
Primero, veamos cómo podemos usar loc para seleccionar una parte de tus datos para usar en un análisis posterior.
Si los datos ya estuvieran limpios, pensarías que para responder a la pregunta, puedes usar un groupby en la columna para contar el número de instituciones que ofrecen asistencia en persona. Hacer esto en Pandas se vería así:
df.groupby("Distancia / En Persona")["Institución"].count()
Desafortunadamente, los valores de la columna “Distancia / En Persona” no están muy limpios. Hay algunos problemas con los espacios en blanco y algunas instituciones ofrecen tanto asistencia a distancia como en persona, aunque la forma en que se registra no es estándar.
Lo primero que podemos hacer para limpiar esto es cambiar el nombre de la columna para que no tenga espacios ni caracteres especiales.
df = df.rename(columns={"Distance / In-Person": "distance_or_in_person"})A continuación, podemos verificar que se realizó el cambio seleccionando todas las columnas en el DataFrame.
df.columns
Ahora, al menos todas las columnas no tienen espacios ni caracteres especiales. Si lo desea, podría estandarizar esto aún más cambiando todas las demás columnas a minúsculas, pero lo omitiremos por ahora.
Anteriormente, realizamos una operación de agrupamiento en la columna objetivo y contamos los valores para cada institución. Otra manera de obtener el mismo resultado es usar el método value_counts en Pandas. Esto devuelve una serie con el recuento de valores únicos de la columna objetivo que se llama.
df["distance_or_in_person"].value_counts()
Observará que en este caso no tuvimos que llamar a la columna “Institutions” esta vez, pero eso se debe a que, en nuestro DataFrame original, cada fila representa una institución.
Ahora, para limpiar esta columna para que los valores de las instituciones que ofrecen tanto asistencia en persona como a distancia se agrupen en un valor, podemos hacer uso de la columna loc para filtrar el DataFrame en aquellos valores y asignar el valor de la columna distance_or_in_person a un nuevo valor “Ambos”.
df.loc[ ~df["distance_or_in_person"].isin(["In-Person", "Distance"]), "distance_or_in_person"] = "Ambos"Aquí, filtramos la columna actual de distance_or_in_person que no es igual a “In-Person” o “Distance” usando el operador ~ y luego seleccionamos la columna distance_or_in_person. Luego lo establecemos igual a “Ambos”, lo que actualiza el DataFrame original. Podemos verificar los cambios revisando el DataFrame nuevamente:
df.head()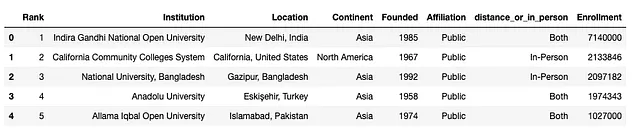
Ahora, verá que la columna actualizada solo contendrá tres valores posibles, y podemos llamar nuevamente a value_counts para obtener la respuesta a nuestra pregunta original:
df["distance_or_in_person"].value_counts()
Ahora sabemos que, según los datos limpios, 59 universidades ofrecen solo asistencia en persona.
Con esta nueva condición, si quisiera saber qué instituciones específicas ofrecen asistencia en persona, podemos filtrar el DataFrame nuevamente usando el método loc y luego usar el método tolist para obtener todos los valores en una lista de Python:
df.loc[df["distance_or_in_person"] == "In-Person"]["Institution"].tolist()
Ahora tenemos una lista de instituciones, pero hay algunos caracteres especiales que podemos eliminar. El “\xa0” en Python representa un espacio no separable, lo que significa que podemos deshacernos de él usando el método strip en Pandas, que elimina los espacios en blanco al final o al principio del valor de cadena.
Podemos editar nuestro código inicial de tolist para limpiar la salida final de esta manera:
df.loc[df["distance_or_in_person"] == "In-Person"]["Institution"].str.strip().tolist()
¡Ahora tenemos una lista final de universidades que solo ofrecen asistencia presencial!
¿Cuál es el rango de años entre las universidades más antiguas y las más nuevas fundadas?
A continuación, usemos el método loc y algunos otros métodos nativos de Pandas para filtrar nuestro DataFrame y responder una pregunta específica de análisis de datos.
Primero, podemos echar un vistazo a la columna de Fundación para ver con qué estamos trabajando:
df["Founded"]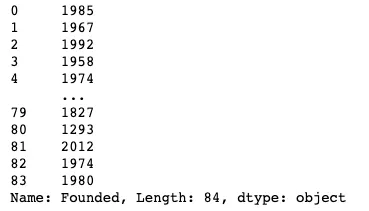
Parece que tenemos una columna llena de valores de año. Dado que queremos comparar fechas entre sí, podríamos convertir la columna en un tipo datetime para facilitar el análisis.
pd.to_datetime(df["Founded"])
Sin embargo, al usar el método to_datetime en la columna, obtenemos un ParserError.
Parece que hay una cadena que no coincide con lo que vimos inicialmente en la columna Fundación. Podemos verificar la fila utilizando el método loc para filtrar el DataFrame en el valor de fundación que específicamente es igual a lo que vimos en el ParserError:
df.loc[df["Founded"] == "1948 and 2014"]
Hay una universidad aparentemente que tiene dos años de fundación diferentes. Además, ahora que conocemos el índice de la fila (9), también hay un ejemplo de cómo usar el método loc para filtrar el DataFrame en el valor de índice específicamente:
df.loc[9]
Parece que esta es la única fila en el DataFrame donde el valor de la columna “Fundación” tiene más de un año.
Dependiendo de lo que quieras hacer con los datos, podrías intentar limpiar los datos eligiendo un año (la primera fecha de fundación) o tal vez creando dos filas para esta institución para que ambas fechas de fundación estén en filas separadas.
En este caso, dado que solo estamos trabajando con estos datos para responder una pregunta simple (¿cuál es el rango de la fecha de fundación para las instituciones en este conjunto de datos?), podemos simplemente eliminar esta fila así:
df.drop(9).head(10) # eliminando la fila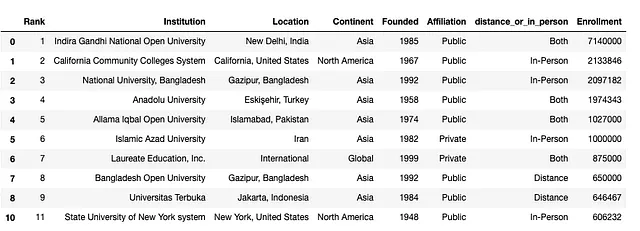
Al revisar el DataFrame resultante, puedes ver que la fila con el índice “9” que tenía múltiples valores para la columna Fundación ya no está en la tabla. Puedes hacer que la eliminación se mantenga volviendo a asignar el DataFrame después de eliminar la fila:
df = df.drop(9)A continuación, podemos volver a aplicar el método to_datetime en la columna de Fundación y ver qué sucede.
pd.to_datetime(df["Founded"], errors="coerce")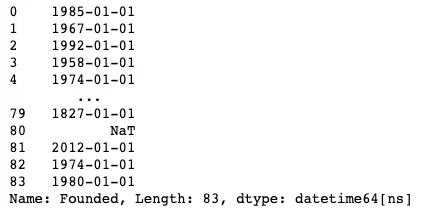
En realidad, hay otro error que aparece aquí, por lo que incluí errors="coerce" para asegurarme de que si hubiera algún otro problema al convertir la cadena en un tipo de fecha y hora, el valor simplemente se volvería nulo.
Finalmente, podemos asignar el tipo datetime de la columna Fundado a una nueva columna. Luego, para verificar la fecha de fundación más temprana de una institución, podemos usar el método min en Python:
df["founded_date"] = pd.to_datetime(df["Founded"], errors="coerce")min(df["founded_date"])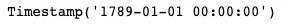
Puede ver las marcas de tiempo más tempranas y más recientes de la columna founded_date utilizando los métodos min y max para obtener el rango de años entre las universidades más antiguas y más nuevas.
Fue aquí donde me di cuenta de que podemos hacer todo esto mucho más rápido si todo lo que necesitamos es responder esa única pregunta rápida. En lugar de convertirlo en un tipo datetime, podríamos simplemente convertir la columna en un tipo entero y luego restar los valores máximos y mínimos entre sí para obtener el rango.
df["Founded"] = df["Founded"].astype("int")max(df["Founded"]) - min(df["Founded"])Esto da como resultado 719.
No siempre debe tomar el camino fácil y simplemente convertir la columna de años en un entero. En el caso en que desee hacer un análisis más complicado o cuando esté trabajando específicamente con una serie de tiempo, hay mucho valor agregado si limpia sus datos correctamente y obtiene la columna de fecha en un tipo datetime. Sin embargo, si solo necesita hacer un análisis rápidamente, puede ahorrarle tiempo y dolores de cabeza buscar errores para encontrar la manera más rápida de resolver un problema en lugar de la “mejor” manera de resolverlo.
Hay muchas formas diferentes de combinar los métodos de Pandas para limpiar y analizar su fecha. El método loc es versátil y le permite usar diferentes métodos juntos para filtrar, cortar y actualizar su DataFrame para que funcione para las preguntas y problemas específicos que desea resolver.
La limpieza de datos es un proceso iterativo que va de la mano con la exploración de datos. Espero que estos ejemplos con loc sean útiles para su propio análisis en el futuro.
Si disfruta de mi contenido, considere seguirme y registrarse para ser miembro de Zepes utilizando mi enlace de referencia a continuación. Cuesta solo $5 al mes y obtendrá acceso ilimitado a todo en Zepes. Registrarse usando mi enlace me permite ganar una pequeña comisión. Y si ya está registrado para seguirme, ¡muchas gracias por su apoyo!
Únase a Zepes con mi enlace de referencia – Byron Dolon
Como miembro de Zepes, una parte de su tarifa de membresía va a los escritores que lee, y obtiene acceso completo a cada historia…
byrondolon.medium.com
M ás de mi: – 3 Formas Eficientes de Filtrar una Columna de DataFrame de Pandas por Subcadena – 5 Consejos Prácticos para Analistas de Datos Aspirantes – Mejore sus Visualizaciones de Datos con Gráficos de Barras Apiladas en Python – Selección y Asignación Condicional con .loc en Pandas – 5 (y medio) Líneas de Código para Entender sus Datos con Pandas
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Ingrese sus innovaciones de síntesis de datos para reformar la policía y ganar dinero.
- Cercanía y Comunidades Analizando Redes Sociales con Python y NetworkX – Parte 3
- Cómo preparar tus datos para visualizaciones
- Aprendizaje Profundo en Sistemas de Recomendación Una introducción.
- ¿Reemplazará la inteligencia artificial a los humanos?
- ¿Quiénes son los Científicos de Datos Ciudadanos y qué hacen?
- La trayectoria de ingeniería de datos del Sr. Pavan impulsa el éxito empresarial.