Usando RAPIDS cuDF para aprovechar la GPU en la ingeniería de características.
Using RAPIDS cuDF to leverage GPU in feature engineering.
Mejorando el rendimiento reemplazando Pandas con cuDF en la creación de marcos de datos, la ingeniería de características e integración con Google Colab.
El hecho de que ciertos métodos hayan logrado resolver un problema puede no llevar al mismo resultado en una escala diferente. Cuando las distancias cambian, los zapatos también deben cambiar.
En el aprendizaje automático, los datos y el procesamiento de datos son cruciales para garantizar el éxito del modelo, y la ingeniería de características es parte de ese proceso. Cuando los datos son pequeños, la biblioteca clásica de Pandas puede manejar fácilmente cualquier tarea de procesamiento en la CPU. Sin embargo, Pandas puede ser demasiado lento en el procesamiento de grandes cantidades de datos. Una solución para mejorar la velocidad y eficiencia en el procesamiento de datos y la ingeniería de características es RAPIDS.
“RAPIDS es un conjunto de bibliotecas de software de código abierto para la ejecución de tuberías de ciencia de datos y análisis de extremo a extremo completamente en unidades de procesamiento gráfico (GPU). RAPIDS acelera las tuberías de ciencia de datos para crear flujos de trabajo más productivos. [1]”

Una herramienta de RAPIDS para manipular eficientemente datos tabulares en la ingeniería de características y el preprocesamiento de datos es cuDF. RAPIDS cuDF permite la creación de marcos de datos GPU y el rendimiento de varias operaciones de Pandas, como la indexación, el agrupamiento, la fusión y el manejo de cadenas. Como define el sitio web de RAPIDS:
“cuDF es una biblioteca de marcos de datos GPU de Python (construida sobre el formato de memoria columnar Apache Arrow) para cargar, unir, agregar, filtrar y manipular de otra manera datos tabulares utilizando una API de estilo de marco de datos al estilo de pandas. [2]”
Este artículo intenta explicar cómo crear y manipular marcos de datos y aplicar la ingeniería de características con cuDF en GPU utilizando un conjunto de datos reales.
Nuestro conjunto de datos pertenece a la Predicción de Volatilidad Real de Optiver de Kaggle. Contiene datos del mercado de valores relevantes para la ejecución práctica de operaciones en los mercados financieros e incluye instantáneas de libros de órdenes y operaciones ejecutadas [3].
Descubriremos más sobre los datos en la siguiente sección. Luego, integraremos Google Colab con Kaggle y RAPIDS. En la tercera sección, veremos cómo realizar la ingeniería de características en este conjunto de datos utilizando Pandas y cuDF. Eso nos proporcionará una revisión comparativa del rendimiento de ambas bibliotecas. En la última sección, trazaremos y evaluaremos los resultados.
Datos
Los datos que vamos a utilizar consisten en dos conjuntos de archivos [3]:
- book_[train/test].parquet: Un archivo parquet, que se divide por stock_id, proporciona datos del libro de órdenes sobre las órdenes de compra y venta más competitivas introducidas en el mercado. Este archivo contiene actualizaciones pasivas de compra / venta.
Columnas de características en book_[train/test].parquet:
- stock_id: código de identificación para la acción. Parquet convierte esta columna al tipo de datos categóricos cuando se carga.
- time_id: código de identificación para el intervalo de tiempo. Los ID de tiempo no son necesariamente secuenciales, pero son consistentes en todas las existencias.
- seconds_in_bucket: número de segundos desde el inicio del intervalo, siempre comenzando desde 0.
- bid_price[1/2]: precios normalizados del nivel de compra más / segundo más competitivo.
- ask_price[1/2]: precios normalizados del nivel de venta más / segundo más competitivo.
- bid_size[1/2]: el número de acciones en el nivel de compra más / segundo más competitivo.
- ask_size[1/2]: el número de acciones en el nivel de venta más / segundo más competitivo.
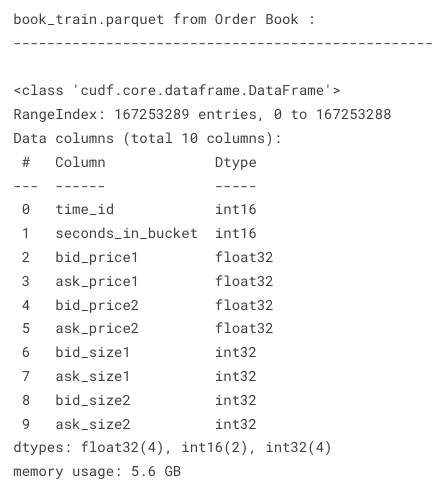
Este archivo tiene 5.6 GB y contiene más de 167 millones de entradas. Hay 112 acciones y 3830 ventanas de tiempo de 10 minutos (time_id). Cada ventana de tiempo (intervalo) tiene un máximo de 600 segundos. Como una intención de transacción puede ocurrir por segundo en cada ventana de tiempo para cada acción, la multiplicación de los números mencionados puede explicar por qué tenemos millones de entradas. Una advertencia es que no ocurre una intención de transacción en cada segundo, lo que significa que faltan algunos segundos en una ventana de tiempo particular.
- trade_[train/test].parquet: un archivo parquet, que se divide por stock_id, contiene datos sobre operaciones que se ejecutan realmente.
Columnas de características en trade_[train/test].parquet:
- stock_id: igual que arriba.
- time_id: igual que arriba.
- seconds_in_bucket: igual que arriba. Tenga en cuenta que como los datos de operaciones y de libros se toman del mismo intervalo de tiempo y los datos de operaciones son más dispersos en general, este campo no necesariamente comienza desde 0.
- price: el precio promedio de las transacciones ejecutadas que ocurren en un segundo. Los precios se han normalizado y el promedio se ha ponderado por el número de acciones negociadas en cada transacción.
- size: el número total de acciones negociadas.
- order_count: el número de órdenes de negociación únicas que tienen lugar.

El archivo trade_[train/test].parquet es mucho menor que el archivo book_[train/test].parquet. El primero es de 512.5 MB y tiene más de 38 millones de entradas. Dado que las transacciones reales no tienen que coincidir con las intenciones, los datos de transacción son más dispersos y, por lo tanto, tienen menos entradas.
El objetivo es predecir la volatilidad real del precio de las acciones calculada en la próxima ventana de 10 minutos a partir de los datos de características bajo la misma stock_id/time_id. Este proyecto involucra una gran cantidad de ingeniería de características que deben realizarse en un conjunto de datos grande. El desarrollo de nuevas características también aumentará el tamaño de los datos y la complejidad computacional. Un remedio es utilizar cuDF en lugar de la biblioteca Pandas.
En este blog, veremos algunas tareas de ingeniería de características y manipulaciones de marcos de datos probando tanto Pandas como cuDF para comparar sus rendimientos. Sin embargo, no utilizaremos todos los datos, sino solo los registros de una sola acción para ver una implementación ejemplar. Uno puede revisar el cuaderno para ver todo el trabajo de ingeniería de características realizado en todos los datos.
Dado que ejecutamos el código en Google Colab, debemos configurar nuestro cuaderno para integrar Kaggle y RAPIDS.
Configuración del cuaderno de Google Colab
Hay algunos pasos para configurar el cuaderno Colab:
- Cree un token de API en la cuenta de Kaggle para autenticar el cuaderno con los servicios de Kaggle.
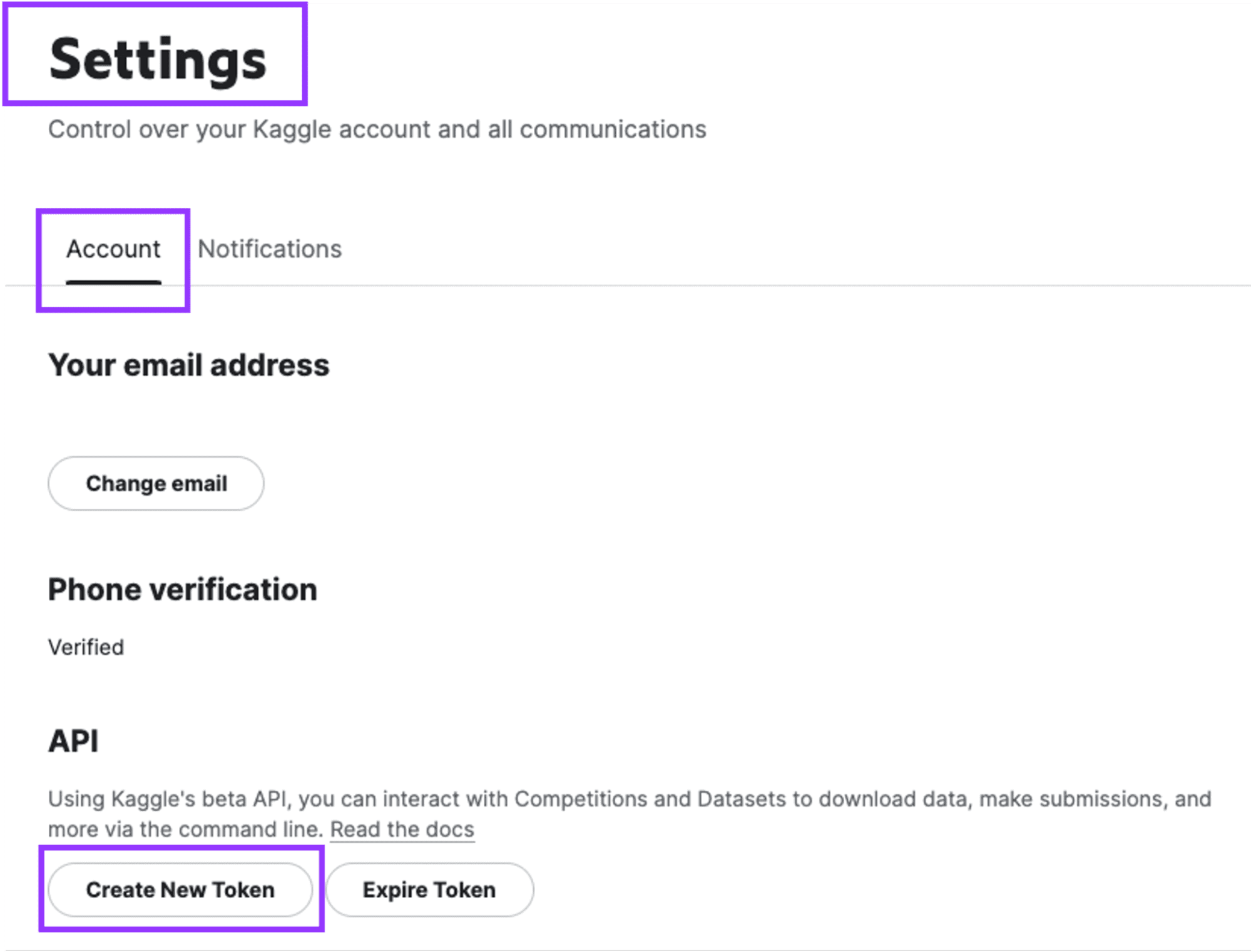
Vaya a Configuración y haga clic en “Crear nuevo token”. Se descargará un archivo llamado “kaggle.json” que contiene el nombre de usuario y la clave API.
- Inicie un nuevo cuaderno en Google Colab y cargue el archivo kaggle.json.
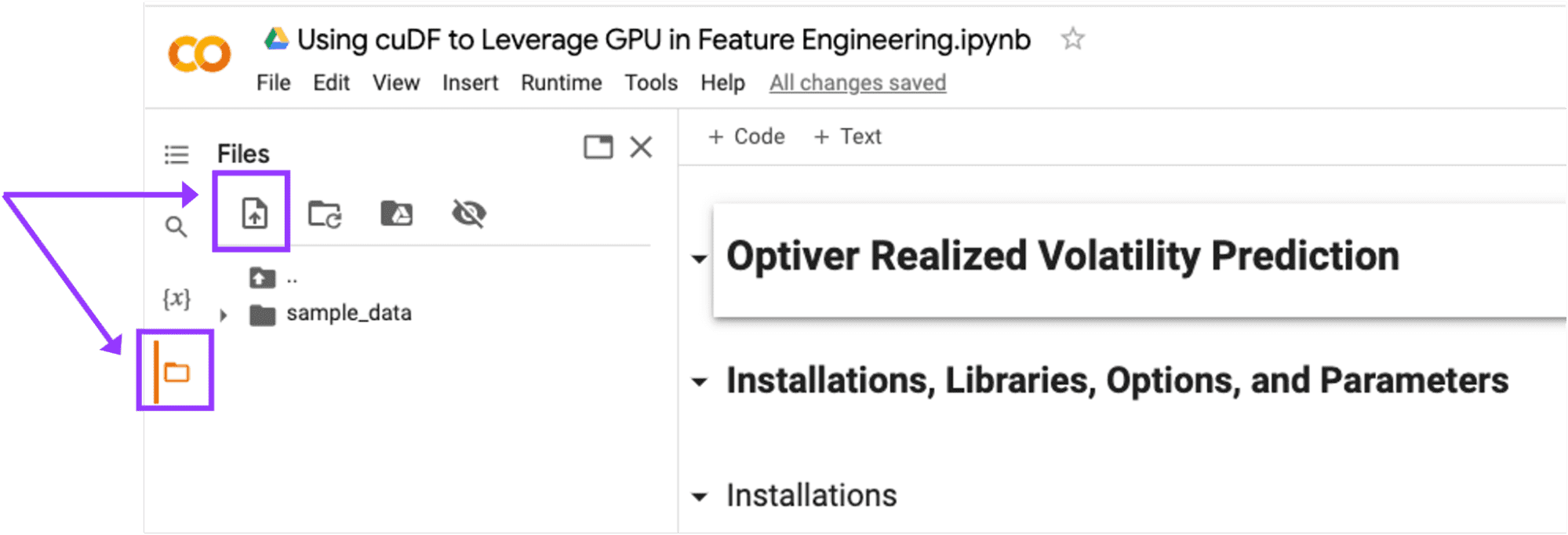
Cargue el archivo kaggle.json en Google Colab haciendo clic en el icono “Cargar en el almacenamiento de la sesión”.
- Haga clic en el menú desplegable “Entorno de ejecución” en la parte superior de la página, luego en “Cambiar tipo de entorno de ejecución” y confirme que el tipo de instancia es GPU.
- Ejecute el siguiente comando y verifique la salida para asegurarse de que se le haya asignado un Tesla T4, P4 o P100.
!nvidia-smi- Obtenga los archivos de instalación de RAPIDS-Colab y verifique su GPU:
!git clone https://github.com/rapidsai/rapidsai-csp-utils.git
!python rapidsai-csp-utils/colab/pip-install.pyAsegúrese de que su instancia de Colab sea compatible con RAPIDS en la salida de esta celda.
- Verifique si las bibliotecas de RAPIDS se han instalado correctamente:
import cudf, cuml
cudf.__version__Si la configuración no produce errores, ya hemos configurado Google Colab. Ahora, podemos cargar el conjunto de datos de Kaggle.
Importación y carga del conjunto de datos de Kaggle
Necesitamos hacer algunas disposiciones en nuestra instancia de Colab para importar el conjunto de datos de Kaggle.
- Instale la biblioteca de Kaggle:
!pip install -q kaggle- Cree un directorio llamado “.kaggle”:
!mkdir ~/.kaggle- Copie “kaggle.json” en este nuevo directorio:
!cp kaggle.json ~/.kaggle/- Asigne los permisos necesarios para este archivo:
!chmod 600 ~/.kaggle/kaggle.json- Descargue el conjunto de datos de Kaggle:
!kaggle competitions download optiver-realized-volatility-prediction- Crea un directorio para los datos descomprimidos:
!mkdir train- Descomprime los datos en el nuevo directorio:
!unzip optiver-realized-volatility-prediction.zip -d train- Importa todas las bibliotecas que necesitamos:
import glob
import numpy as np
import pandas as pd
from cudf import DataFrame
import matplotlib.pyplot as plt
from matplotlib import style
from collections import defaultdict
from IPython.display import display
import gc
import time
import warnings
%matplotlib inline- Configura las opciones de Pandas:
pd.set_option("display.max_colwidth", None)
pd.set_option("display.max_columns", None)
warnings.filterwarnings("ignore")
print("Umbral:", gc.get_threshold())
print("Conteo:", gc.get_count())- Define los parámetros:
# Directorio de datos que contiene archivos
DIR = "/content/train/"
# Número de ciclos de ejecución
ROUNDS = 30- Obtén los archivos:
# Obtén los libros de órdenes y comercio
order_files = glob.glob(DIR + "book_train.parquet" + "/*")
trade_files = glob.glob(DIR + "trade_train.parquet" + "/*")
print(order_files[:5])
print("\n")
print(trade_files[:5])
print("\n")
# Obtén los identificadores de las acciones como una lista
stock_ids = sorted([int(file.split('=')[1]) for file in order_files])
print(f"{len(stock_ids)} acciones: \n {stock_ids} \n")Ahora, nuestro cuaderno está listo para ejecutar todas las tareas del marco de datos y realizar la ingeniería de características.
Ingeniería de características
Esta sección discutirá 13 operaciones típicas de ingeniería en Pandas y cuDF. Veremos cuánto tiempo tardan estas operaciones y cuánta memoria usan. Comencemos por cargar los datos primero.
1. Carga de datos
def load_dataframe(files, dframe=0):
print("CARGANDO MARCOS DE DATOS", "\n")
# Cargar el marco de datos de Pandas
if dframe == 0:
print("Cargando el marco de datos de Pandas..", "\n")
start = time.time()
df_pandas = pd.read_parquet(files[0])
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Para el marco de datos de Pandas: \n tiempo de inicio: {start} \n tiempo de finalización: {end} \n tiempo transcurrido: {elapsed_time} \n")
return df_pandas, elapsed_time
# Cargar el marco de datos de cuDF
else:
print("Cargando el marco de datos de cuDF..", "\n")
start = time.time()
df_cudf = cudf.read_parquet(files[0])
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Para el marco de datos de cuDF: \n tiempo de inicio: {start} \n tiempo de finalización: {end} \n tiempo transcurrido: {elapsed_time} \n ")
return df_cudf, elapsed_timeCuando dframe=0, los datos se cargarán como un marco de datos de Pandas, de lo contrario cuDF. Por ejemplo,
Pandas:
# Carga el marco de datos de órdenes de pandas y calcula el tiempo
df_pd_order, _ = load_dataframe(order_files, dframe=0)
display(df_pd_order.head())Esto devolverá los primeros cinco registros del Libro de órdenes (book_[train/test].parquet):
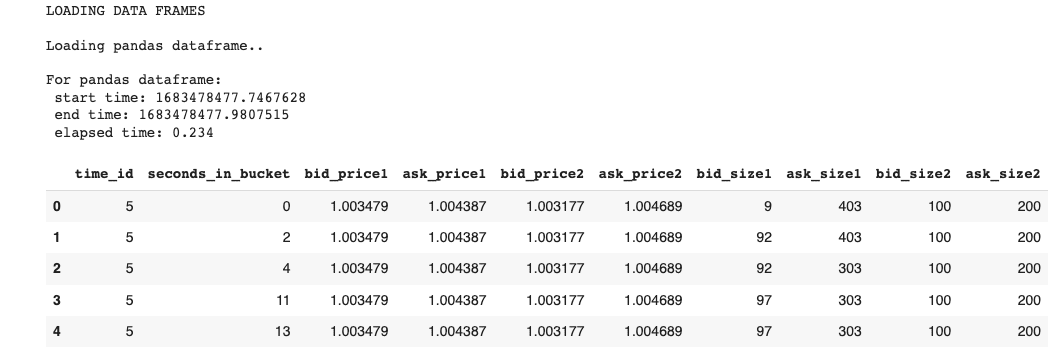
cuDF:
# Cargar el marco de datos de libros de cuDF y calcular el tiempo
df_cudf_order, _ = load_dataframe(order_files, dframe=1)
display(df_cudf_order.head())Salida:
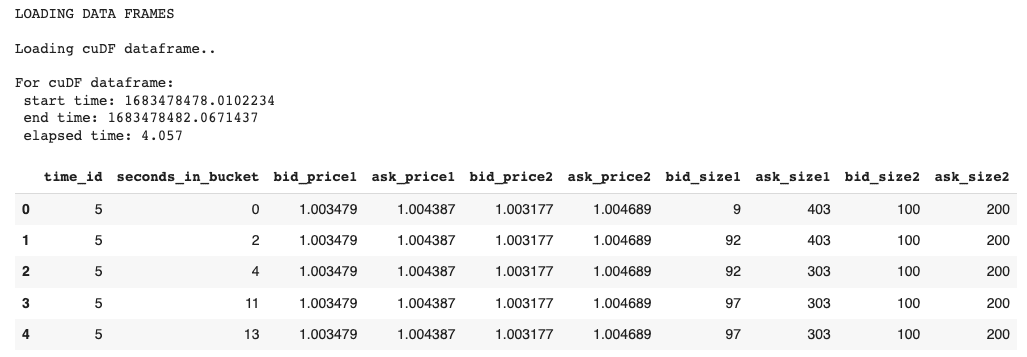 Exhibit-7: Cargando los datos como cuDF (Imagen por el autor)
Exhibit-7: Cargando los datos como cuDF (Imagen por el autor)
Obtengamos información sobre los datos del Libro de Órdenes desde la versión de Pandas:
# Información del dataframe de órdenes
display(df_pd_order.info())Resultado:
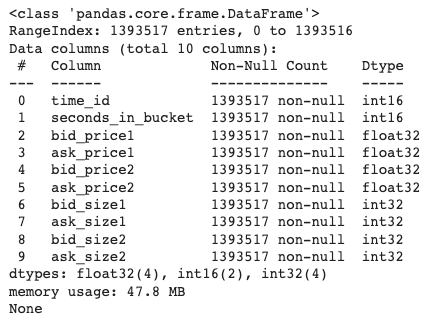 Exhibición 8: Información sobre los datos del Libro de Órdenes del Primer Stock (Imagen del Autor)
Exhibición 8: Información sobre los datos del Libro de Órdenes del Primer Stock (Imagen del Autor)
La imagen anterior nos indica que el primer stock tiene alrededor de 1,4 millones de entradas y ocupa 47,8 MB de espacio en memoria. Para reducir el espacio y aumentar la velocidad, debemos convertir los tipos de datos a formatos más pequeños, lo cual haremos más tarde.
De manera similar, cargamos los datos del Libro de Operaciones (trade_[train/test].parquet) en ambas bibliotecas de data frames como lo hicimos para los datos del Libro de Órdenes. Los datos y su información se verán así:
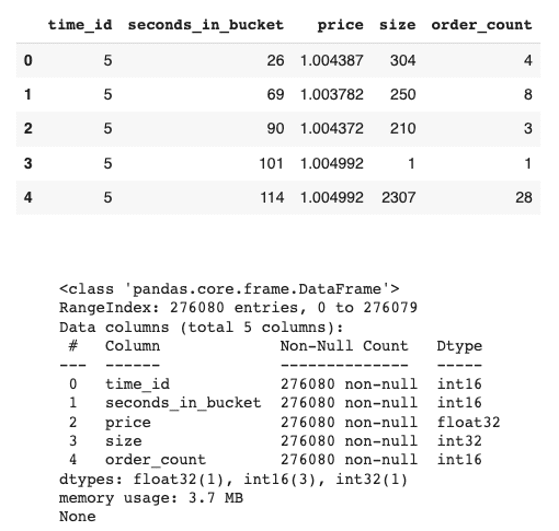 Exhibición 9: Datos y su información del Libro de Operaciones del Primer Stock (Imagen del Autor)
Exhibición 9: Datos y su información del Libro de Operaciones del Primer Stock (Imagen del Autor)
Los datos de operaciones del primer stock ocupan 3,7 MB y tienen más de 276 mil registros.
En ambos archivos (Libro de Órdenes y Libro de Operaciones), no cada ventana de tiempo tiene 600 puntos de segundos. En otras palabras, un intervalo de tiempo particular puede tener transacciones o ofertas solo en algunos segundos del intervalo de 10 minutos. Eso nos lleva a enfrentar datos dispersos en ambos archivos donde faltan algunos segundos. Debemos solucionarlo rellenando hacia adelante todas las columnas para los segundos que faltan. Si bien Pandas nos permite hacer eso, cuDF no tiene esa función. Por lo tanto, haremos el rellenado hacia adelante en Pandas y volveremos a crear cuDF a partir del data frame de Pandas rellenado hacia adelante. Nos sentimos arrepentidos por esto ya que el objetivo central de este blog es mostrar cómo cuDF supera a Pandas. He investigado el asunto varias veces en el pasado, pero hasta donde yo sé, no he encontrado el método en cuDF como se implementa en Pandas. Por lo tanto, podemos hacer el rellenado hacia adelante de la siguiente manera[4]:
# Rellenado hacia adelante de datos
def ffill(df, df_name="order"):
# Rellenado hacia adelante
df_pandas = df.set_index(['time_id', 'seconds_in_bucket'])
if df_name == "order":
df_pandas = df_pandas.reindex(pd.MultiIndex.from_product([df_pandas.index.levels[0], np.arange(0,600)], names = ['time_id', 'seconds_in_bucket']), method='ffill')
df_pandas = df_pandas.reset_index()
else:
df_pandas = df_pandas.reindex(pd.MultiIndex.from_product([df_pandas.index.levels[0], np.arange(0,600)], names = ['time_id', 'seconds_in_bucket']))
# Rellenar valores nan con 0
df_pandas = df_pandas.fillna(0)
df_pandas = df_pandas.reset_index()
# Convertir en un data frame de cudf
df_cudf = cudf.DataFrame.from_pandas(df_pandas)
return df_pandas, df_cudfTomemos los datos de órdenes como ejemplo y veamos cómo se procesan:
# Rellenado hacia adelante de los data frames de órdenes
expanded_df_pd_order, expanded_df_cudf_order = ffill(df_pd_order, df_name="order")
display(expanded_df_cudf_order.head()) Exhibición 10: Rellenado hacia adelante de los Datos de Órdenes (Imagen del Autor)
Exhibición 10: Rellenado hacia adelante de los Datos de Órdenes (Imagen del Autor)
A diferencia de los datos en la Exhibición 7, los datos rellenados hacia adelante de la Exhibición 10 tienen los 600 segundos en el intervalo de tiempo “5” desde el 0 hasta el 599, inclusive. Hacemos la misma operación en los datos de operaciones también.
2. Uniendo Data Frames
Tenemos dos conjuntos de datos, órdenes y operaciones, y ambos están rellenados hacia adelante. Ambos conjuntos de datos están representados en los marcos de trabajo de Pandas y cuDF. A continuación, uniremos los conjuntos de datos de órdenes y operaciones en time_id y seconds_in_buckets.
def merge_dataframes(df1, df2, dframe=0):
print("UNIENDO DATA FRAMES", "\n")
if dframe == 0:
df_type = "Pandas"
else:
df_type = "cuDF"
# Unir data frames
print(f"Uniendo data frames de {df_type}..", "\n")
start = time.time()
df = df1.merge(df2, how="left", on=["time_id", "seconds_in_bucket"], sort=True)
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Para los data frames de {df_type}: \n hora de inicio: {start} \n hora de finalización: {end} \n tiempo transcurrido: {elapsed_time} \n")
return df, elapsed_timecuDF ejecutará el siguiente comando:
# Combinar los cuadros de datos de orden y comercio de cuDF
df_cudf, cudf_merge_time = merge_dataframes(expanded_df_cudf_order, expanded_df_cudf_trade, dframe=1)
display(df_cudf.head())expanded_df_cudf_trade es el comercio de datos de relleno hacia adelante y se obtiene de la misma manera que expanded_df_pd_order o expanded_df_cudf_order. La operación de combinación creará un marco de datos combinado como se muestra a continuación:
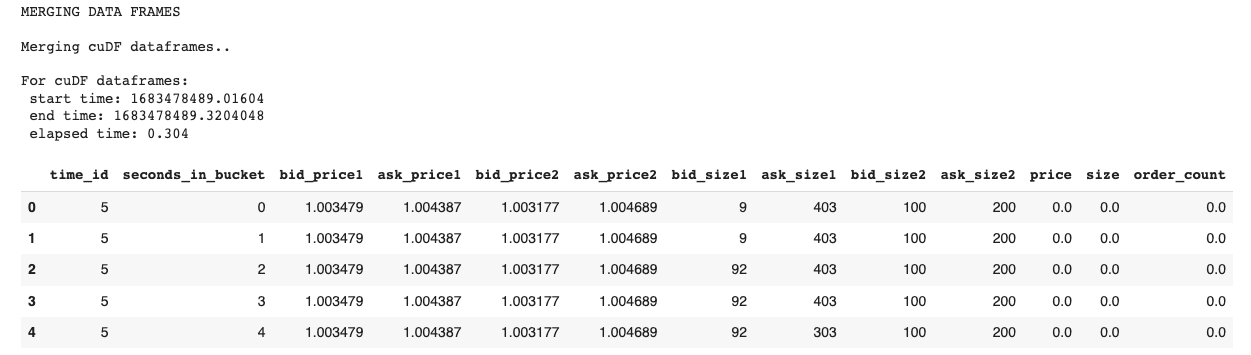 Exhibición-11: Combinando marcos de datos (Imagen por Autor)
Exhibición-11: Combinando marcos de datos (Imagen por Autor)
Todas las columnas de los dos conjuntos de datos se combinan en uno. La operación de combinación se repite también para los marcos de datos de Pandas.

3. Cambiando Dtype
Queremos cambiar el tipo de datos de algunas columnas para reducir el espacio de memoria y aumentar la velocidad de cálculo.
# Hacer cambios de tipo de datos
def change_dtype(df, dframe=0):
print("CAMBIANDO DTYPES", "\n")
convert_dict = {"time_id": "int16",
"seconds_in_bucket": "int16",
"bid_size1": "int16",
"ask_size1": "int16",
"bid_size2": "int16",
"ask_size2": "int16",
"size": "int16",
"order_count": "int16"
}
df = df.astype(convert_dict)
return df, dframeCuando ejecutamos el siguiente comando:
# Hacer cambios de tipo de datos para el marco de datos de cuDF
df_cudf, _ = change_dtype(df_cudf)
display(df_cudf.info())obtenemos la siguiente salida:
 Exhibición-12: Cambiando Dtype (Imagen por Autor)
Exhibición-12: Cambiando Dtype (Imagen por Autor)
Los datos en la Exhibición 12 ocuparían más espacio de memoria si no se realizara la conversión de tipo de datos. Todavía tiene 78,9 MB, pero eso fue después de las operaciones de relleno hacia adelante y combinación, que resultaron en 13 columnas y 2,3 millones de entradas.
Realizamos todas las tareas de ingeniería de características tanto para Pandas DF como para cuDF. Aquí, solo mostramos la de cuDF como ejemplo.
4. Obteniendo identificadores de tiempo únicos
Usaremos el método único para extraer los time_ids en esta sección.
# Obtener valores únicos en la columna time_id y ponerlos en una lista
def get_unique_timeids(df, dframe=0):
global time_ids
print("OBTENIENDO VALORES ÚNICOS", "\n")
# Obtener time_ids únicos
if dframe == 0:
print(f"Obteniendo time_ids únicos ordenados del marco de datos de Pandas..", "\n")
start = time.time()
time_ids = sorted(df['time_id'].unique().tolist())
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Time_ids únicos del marco de datos de Pandas: \n hora de inicio: {start} \n hora de finalización: {end} \n tiempo transcurrido: {elapsed_time} \n")
else:
print(f"Obteniendo time_ids únicos ordenados del marco de datos de cuDF..", "\n")
start = time.time()
time_ids = sorted(df['time_id'].unique().to_arrow().to_pylist())
end = time.time()
elapsed_time = round(end-start, 3)
print(f"Time_ids únicos del marco de datos de cuDF: \n hora de inicio: {start} \n hora de finalización: {end} \n tiempo transcurrido: {elapsed_time} \n")
print(f"{len(time_ids)} intervalos de tiempo: \n {time_ids[:10]}...")
print("\n")
return df, time_idsEl código anterior obtendrá los time_ids únicos de Pandas DF y cuDF.
# Obtener time_ids del marco de datos de cuDF
time_ids = get_unique_timeids(df_cudf_order, dframe=1)La salida de cuDF se ve así:
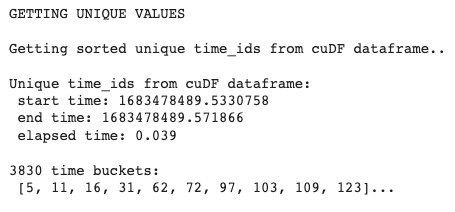 Exhibición-13: Obteniendo identificadores de tiempo únicos (Imagen por Autor)
Exhibición-13: Obteniendo identificadores de tiempo únicos (Imagen por Autor)
5. Comprobación de valores nulos
A continuación, comprobaremos los valores nulos en los marcos de datos.
# Comprobar valores nulos en df
def comprobar_valores_nulos(df, dframe=0):
print("COMPROBANDO VALORES NULOS", "\n")
print("Comprobando valores nulos en el marco de datos..", "\n")
display(df.isna().values.any())
display(df.isnull().sum())
return df, dframeEjemplo de comprobación de valores nulos en cuDF:
# Comprobar valores nulos para el marco de datos de cuDF
df_cudf, _ = comprobar_valores_nulos(df_cudf, dframe=0)Y la salida es:
 Exhibición-14: Comprobación de valores nulos (Imagen por el autor)
Exhibición-14: Comprobación de valores nulos (Imagen por el autor)
6. Agregar una columna
Queremos crear más características, así que agreguemos algunas columnas.
# Agregar columnas
def agregar_columna(df, dframe=0):
print("AGREGANDO COLUMNAS", "\n")
# Calcular WAPs
df['wap1'] = (df['bid_price1'] * df['ask_size1'] + df['ask_price1'] * df['bid_size1']) / (df['bid_size1'] + df['ask_size1'])
df['wap2'] = (df['bid_price2'] * df['ask_size2'] + df['ask_price2'] * df['bid_size2']) / (df['bid_size2'] + df['ask_size2'])
# Calcular volúmenes de orden
df['bid1_volume'] = df['bid_price1'] * df['bid_size1']
df['bid2_volume'] = df['bid_price2'] * df['bid_size2']
df['ask1_volume'] = df['ask_price1'] * df['ask_size1']
df['ask2_volume'] = df['ask_price2'] * df['ask_size2']
# Calcular desequilibrio de volumen
df['imbalance'] = np.absolute((df['ask_size1'] + df['ask_size2']) - (df['bid_size1'] + df['bid_size2']))
# Calcular desequilibrio de volumen comercial
df['volume_imbalance'] = np.absolute((df['bid_price1'] * df['bid_size1']) - (df['ask_price1'] * df['ask_size1']))
return df, dframeEso creará nuevas características como el precio promedio ponderado (wap1 y wap2), volumen de orden y desequilibrio de volumen. En total, se agregarán ocho columnas a los marcos de datos ejecutando lo siguiente:
# Agregar una columna al marco de datos de cuDF
df_cudf, _ = agregar_columna(df_cudf)
display(df_cudf.head())Lo que nos dará:
 Exhibición-15: Agregar columnas y características (Imagen por el autor)
Exhibición-15: Agregar columnas y características (Imagen por el autor)
7. Eliminar una columna
Decidimos deshacernos de dos características, wap1 y wap2, eliminando sus columnas:
# Eliminar columnas
def eliminar_columna(df, dframe=0):
print("ELIMINANDO COLUMNAS", "\n")
df.drop(columns=['wap1', 'wap2'], inplace=True)
return df, dframeLa implementación de eliminación de columnas es:
# Agregar una columna al marco de datos de cuDF
df_cudf, _ = eliminar_columna(df_cudf)
display(df_cudf.head())¡Eso nos deja con los marcos de datos en los que las columnas wap1 y wap2 han desaparecido!
8. Cálculo de estadísticas por grupo
A continuación, calculamos la media, mediana, máximo, mínimo, desviación estándar y la suma de algunas características por time_id. Para esto, usaremos los métodos groupby y agg.
# Calcular estadísticas por características seleccionadas
def calcular_estadisticas(df, dframe=0):
print("CALCULANDO ESTADÍSTICAS", "\n")
# Cálculos estadísticos a realizar
operaciones = ["mean", "median", "max", "min", "std", "sum"]
# Características para las que se realizarán cálculos estadísticos
lista_caracteristicas = ["bid1_volume", "bid2_volume", "ask1_volume", "ask2_volume"]
# Crear un diccionario para almacenar pares característica-cálculo
diccionario_estadisticas = defaultdict(list)
for caracteristica in lista_caracteristicas:
diccionario_estadisticas[caracteristica].extend(operaciones)
# Calcular estadísticas agregadas
df_estadisticas = df.groupby('time_id', as_index=False, sort=True).agg(diccionario_estadisticas)
return df, df_estadisticasCreamos una lista llamada features_list para especificar las características en las que se realizarán los cálculos matemáticos.
# Calcular estadísticas por características seleccionadas en el marco de datos de cuDF
_, df_cudf_stats = calc_agg_stats(df_cudf)
display(df_cudf_stats.head()) A cambio, obtenemos la siguiente salida:  Exhibit-16: Calculating Statistics (Image by Author)
Exhibit-16: Calculating Statistics (Image by Author)
La tabla devuelta es un nuevo marco de datos. Debemos fusionarlo con el original (df_cudf). Lo lograremos a través de Pandas:
# Merge data frame with stats
def merge_dataframes_2(df, dframe=0):
if dframe == 0:
df = df.merge(df_pd_stats, how="left", on="time_id", sort=True)
else:
df = df.to_pandas()
df = df.merge(df_pd_stats, how="left", on="time_id", sort=True)
df = cudf.DataFrame.from_pandas(df)
return df, dframe
# Merge cuDF data frames
df_cudf, _ = merge_dataframes_2(df_cudf, dframe=1)
display(df_cudf.head())El fragmento anterior colocará df_pd_stats y df_pd en un marco de datos y lo guardará como df_cudf.
Como de costumbre, repetimos la misma tarea para Pandas.
El siguiente paso es calcular la correlación entre dos columnas:
# Calcular la correlación entre dos características seleccionadas
def calc_corr(df, dframe=0):
correlation = df[["bid1_volume", "ask1_volume"]].corr()
print(f"La correlación entre 'bid1_volume' y 'ask1_volume' es {correlation} \n")
return df, correlationEste código
# Calculate correlation in cuDF dataframe
_ = calc_corr(df_cudf)devolverá la siguiente salida:
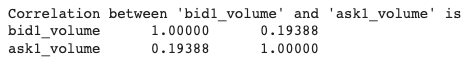 Exhibit-17: Calculating Correlation Between Two Features (Image by Author)
Exhibit-17: Calculating Correlation Between Two Features (Image by Author)
9. Renombrando Columnas
Para eliminar cualquier confusión, debemos renombrar dos de nuestras columnas.
# Renombrar columnas
def rename_cols(df, dframe=0):
print("RENOMBRANDO COLUMNAS", "\n")
df = df.rename(columns={"imbalance": "volume_imbalance", "volume_imbalance": "trade_volume_imbalance"})
return df, dframeLas columnas imbalance y volume_imbalance se renombrarán como volume_imbalance y trade_volume_imbalance, respectivamente.
10. Agrupando una columna
Otra manipulación de datos que queremos hacer es agrupar bid1_volume y almacenar los grupos en una nueva columna.
# Agrupar una columna seleccionada
def bin_col(df, dframe=0):
print("AGRUPANDO UNA COLUMNA", "\n")
if dframe == 0:
df['bid1_volume_cut'] = pd.cut(df["bid1_volume"], bins=5, labels=["muy alto", "alto", "promedio", "bajo", "muy bajo"], ordered=True)
else:
df['bid1_volume_cut'] = cudf.cut(df["bid1_volume"], bins=5, labels=["muy alto", "alto", "promedio", "bajo", "muy bajo"], ordered=True)
return df, dframeEjecutando las líneas
# Agrupar una columna seleccionada en el marco de datos de cuDF
df_cudf, _ = bin_col(df_cudf, dframe=1)
display(df_cudf.head())obtendremos un marco de datos como salida, del que podemos ver una parte a continuación:
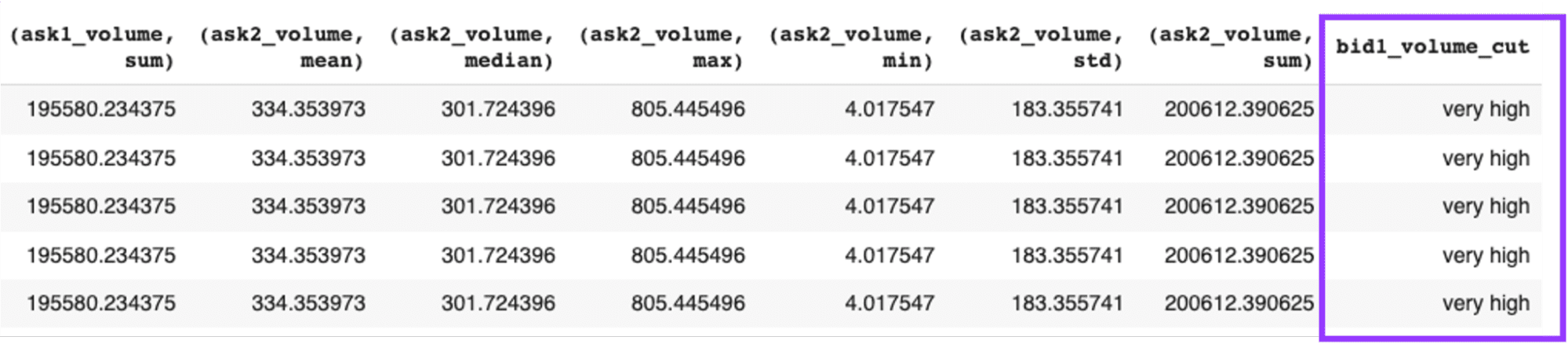 Exhibit-18: Binning A Column (Image by Author)
Exhibit-18: Binning A Column (Image by Author)
11. Mostrando Marcos de Datos
Después de completar los pasos de ingeniería de características, podemos presentar los marcos de datos. Esta sección contiene tres operaciones: mostrar el marco de datos, obtener información sobre él y describirlo.
# Mostrar data frame
def display_df(df, dframe=0):
print("MOSTRANDO DATA FRAMES", "\n")
display(df.head())
print("\n")
return df, dframe
# Mostrar información del data frame
def display_info(df, dframe=0):
print("MOSTRANDO INFORMACIÓN DEL DATA FRAME", "\n")
display(df.info())
print("\n")
return df, dframe
# Describir data frame
def describe_df(df, dframe=0):
print("DESCRIBIENDO DATA FRAMES", "\n")
display(df.describe())
print("\n")
return df, dframeEl siguiente código finalizará estas tres tareas:
# Mostrar el data frame cuDF y la información
_, _ = display_df(df_cudf, dframe=1)
_, _ = display_info(df_cudf, dframe=1)
_, _ = describe_df(df_cudf, dframe=1)Hemos terminado con la ingeniería de características.
Ejecución Única
En resumen, nuestros esfuerzos de ingeniería de características se han centrado en las siguientes tareas:
- Cargar los data frames
- Unir los data frames
- Cambiar el tipo de datos
- Obtener time_ids únicos.
- Verificar valores nulos
- Añadir columnas
- Eliminar columnas
- Calcular estadísticas
- Calcular una correlación
- Cambiar nombres de columnas
- Agrupar una columna
- Mostrar data frames
- Mostrar información del data frame
- Describir data frames
Fueron 13 tareas en total, pero mencionamos “Calcular una correlación” como una entidad separada aquí. Ahora, queremos ejecutar estas tareas secuencialmente en una única ejecución, como se muestra a continuación:
def run_and_report():
# Crear un diccionario para almacenar los tiempos transcurridos
time_dict = defaultdict(list)
# Lista de operaciones a realizar
labels = ["cambiando_tipo_dato",
"obteniendo_timeids_unicos",
"verificando_valores_nulos",
"añadiendo_columna",
"eliminando_columna",
"calculando_estadisticas_agr",
"unir_dataframes",
"renombrando_columnas",
"agrupando_col",
"calculando_corr",
"mostrando_dfs",
"mostrando_info",
"describiendo_dfs"]
# Cargar el dataframe de pandas y calcular el tiempo
df_pd_order, pd_order_loading_time = load_dataframe(order_files, dframe=0)
print("-"*150, "\n")
# Cargar el dataframe de cuDF y calcular el tiempo
df_cudf_order, cudf_order_loading_time = load_dataframe(order_files, dframe=1)
print("-"*150, "\n")
# Cargar el dataframe de pandas trade y calcular el tiempo
df_pd_trade, pd_trade_loading_time = load_dataframe(trade_files, dframe=0)
print("-"*150, "\n")
# Cargar el dataframe de cuDF trade y calcular el tiempo
df_cudf_trade, cudf_trade_loading_time = load_dataframe(trade_files, dframe=1)
print("-"*150, "\n")
# Obtener time_ids del dataframe Pandas
_, time_ids = get_unique_timeids(df_pd_order, dframe=0)
print("-"*150, "\n")
# Obtener time_ids del dataframe cuDF
_, time_ids = get_unique_timeids(df_cudf_order, dframe=1)
print("-"*150, "\n")
# Almacenar tiempos de carga
time_dict["carga_dfs"].extend([pd_order_loading_time, cudf_order_loading_time])
# Forward fill order dataframes
expanded_df_pd_order, expanded_df_cudf_order = ffill(df_pd_order, df_name="order")
# Forward fill trade dataframes
expanded_df_pd_trade, expanded_df_cudf_trade = ffill(df_pd_trade, df_name="trade")
# Unir los dataframes de pandas order y trade
df_pd, pd_merge_time = merge_dataframes(expanded_df_pd_order, expanded_df_pd_trade, dframe=0)
print("-"*150, "\n")
# Unir los dataframes de cuDF order y trade
df_cudf, cudf_merge_time = merge_dataframes(expanded_df_cudf_order, expanded_df_cudf_trade, dframe=1)
print("-"*150, "\n")
# Almacenar tiempos de unión
time_dict["unión_dfs"].extend([pd_merge_time, cudf_merge_time])
# Aplicar funciones
functions = [change_dtype,
get_unique_timeids,
check_null_values,
add_column,
drop_column,
calc_agg_stats,
merge_dataframes_2,
rename_cols,
bin_col,
calc_corr,
display_df,
display_info,
describe_df]
for label, function in enumerate(functions):
# Función para pandas
start_pd = time.time()
df_pd, x = function(df_pd, dframe=0)
end_pd = time.time()
elapsed_time_for_pd = round(end_pd-start_pd, 3)
print(f"Para el dataframe de pandas: \n tiempo de inicio: {start_pd} \n tiempo final: {end_pd} \n tiempo transcurrido: {elapsed_time_for_pd} \n")
# Función para cuDF
start_cudf = time.time()
df_cudf, x = function(df_cudf, dframe=1)
end_cudf = time.time()
elapsed_time_for_cudf = round(end_cudf-start_cudf, 3)
print(f"Para el dataframe de cuDF: \n tiempo de inicio: {start_cudf} \n tiempo final: {end_cudf} \n tiempo transcurrido: {elapsed_time_for_cudf} \n")
print("-"*150, "\n")
# Almacenar tiempos transcurridos
time_dict[labels[label]].extend([elapsed_time_for_pd, elapsed_time_for_cudf])
# Eliminar la duración de tiempo no solicitada
del time_dict["unir_dataframes"]
labels.remove("unir_dataframes")
labels.insert(0, "unión_dfs")
labels.insert(0, "carga_dfs")
print(time_dict)
return time_dict, labels, df_pd, df_cudfLa función “run_and_report” dará las mismas salidas que antes, pero en un informe completo con un solo comando de ejecución. Ejecutará las 14 tareas en ambos Pandas y cuDF y registrará los tiempos que llevan ambos data frames.
time_dict, labels, df_pd, df_cudf = run_and_report()Podríamos tener que ejecutar múltiples ciclos para ver la diferencia de rendimiento entre ambas bibliotecas de datos de manera más clara.
Evaluación Final
Si ejecutamos “run_and_report” varias veces, como en rondas, podemos obtener una mejor idea de la diferencia de rendimiento entre Pandas y cuDF. Entonces, establecemos las rondas en 30. Luego, registramos todas las duraciones de tiempo para cada operación, ronda y biblioteca de datos y evaluamos los resultados:
def calc_exec_times():
exec_times_by_round = {}
# Calcular los tiempos de ejecución de las operaciones en cada ronda
for round_no in range(1, ROUNDS+1):
# cycle_no += 1
time_dict, labels, df_pd, df_cudf = run_and_report()
exec_times_by_round[round_no] = time_dict
print("exec_times_by_round: ", exec_times_by_round)
# Obtener las duraciones por operación para cada data frame
pd_summary, cudf_summary = get_statistics(exec_times_by_round, labels)
# Obtener las duraciones por rondas para cada data frame
round_total = get_total(exec_times_by_round)
print("\n"*3)
# Graficar las duraciones
plt.style.use('dark_background')
X_axis = np.arange(len(labels))
# Graficar la duración promedio de la operación
plot_avg_by_df(pd_summary, cudf_summary, labels, X_axis)
print("\n"*3)
# Graficar la duración total y la diferencia por operación
plot_diff_by_df(pd_summary, cudf_summary, labels)
print("\n"*3)
# Graficar la duración total y la diferencia por ronda
plot_total_by_df(round_total)
print("\n"*3)La función “calc_exec_times” ejecuta algunas tareas. Primero llama a “get_statistics” para obtener “la duración promedio y total por operación” para cada biblioteca de datos en 30 rondas.
def get_statistics(exec_times_by_round, labels):
# Separar y almacenar las estadísticas de duración por data frame
pd_performance = defaultdict(list)
cudf_performance = defaultdict(list)
# Obtener y almacenar las duraciones para cada operación por data frame
for label in labels:
for key, values in exec_times_by_round.items():
pd_performance[label].append(values[label][0])
cudf_performance[label].append(values[label][1])
print("pd_performance: ", pd_performance)
print("cudf_performance: ", cudf_performance)
# Calcular la duración promedio y total para cada operación por data frame
pd_summary = {key: [round(sum(value), 3), round(np.average(value), 3)] for key, value in pd_performance.items()}
cudf_summary = {key: [round(sum(value), 3), round(np.average(value), 3)] for key, value in cudf_performance.items()}
print("pd_summary: ", pd_summary)
print("cudf_summary: ", cudf_summary)
return pd_summary, cudf_summaryA continuación, calcula la “duración total por ronda” para cada marco de datos.
def get_total(exec_times_by_round):
def get_round_total(stat_list):
# Obtener la duración total por ronda para cada data frame
pd_round_total = round(sum([x[0] for x in stat_list]), 3)
cudf_round_total = round(sum([x[1] for x in stat_list]), 3)
return pd_round_total, cudf_round_total
# Recopilar las duraciones totales por ronda
for key, value in exec_times_by_round.items():
round_total = {key: get_round_total(list(value.values())) for key, value in exec_times_by_round.items()}
print("round_total", round_total)
return round_totalPor último, grafica los resultados. Aquí, el primer gráfico es para la “duración promedio por operación” para ambas bibliotecas.
def plot_avg_by_df(pd_summary, cudf_summary, labels, X_axis):
# Tamaño de la figura
fig = plt.subplots(figsize =(10, 4))
# Duración promedio por operación para cada data frame
pd_avg = [value[1] for key, value in pd_summary.items()]
cudf_avg = [value[1] for key, value in cudf_summary.items()]
plt.bar(X_axis - 0.2, pd_avg, 0.4, color = '#5A5AAF', label = 'pandas', align='center')
plt.bar(X_axis + 0.2, cudf_avg, 0.4, color = '#C8C8FF', label = 'cuDF', align='center')
plt.xticks(X_axis, labels, fontsize=9, rotation=90)
plt.yticks(fontsize=9)
plt.xlabel("Operaciones", fontsize=10)
plt.ylabel("Duración Promedio en Segundos", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Duración Promedio de la Operación por Data Frame", fontsize=12)
plt.legend()
plt.show()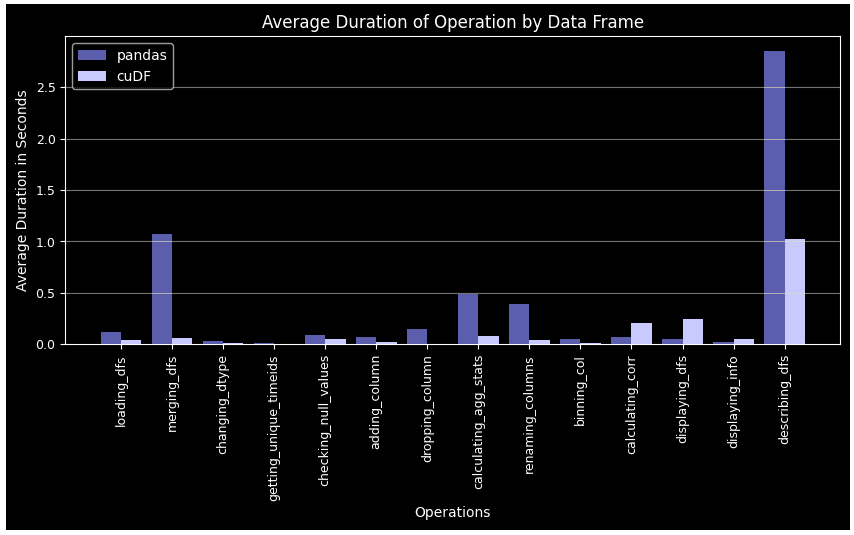 Exhibición-19: Duración promedio por operación para el marco de datos Pandas y cuDF (Imagen por Autor)
Exhibición-19: Duración promedio por operación para el marco de datos Pandas y cuDF (Imagen por Autor)
La segunda gráfica es para la “duración total por operación”, que muestra el tiempo total que cada tarea tomó en los 30 ciclos.
def plot_diff_by_df(pd_summary, cudf_summary, labels):
# Tamaño de la figura
fig = plt.subplots(figsize =(12, 6))
# Duración total por operación para cada marco de datos
pd_total = [value[0] for key, value in pd_summary.items()]
cudf_total = [value[0] for key, value in cudf_summary.items()]
# Diferencia de la duración total por operación para cada marco de datos
diff = [x[0]-x[1] for x in zip(pd_total, cudf_total)]
# Ancho de la barra
barWidth = 0.25
# Posición de la barra en el eje X
br1 = np.arange(len(labels))
br2 = [x + barWidth for x in br1]
br3 = [x + barWidth for x in br2]
plt.bar(br1, pd_total, barWidth, color = '#5A5AAF', label = 'pandas', align='center')
plt.bar(br2, cudf_total, barWidth, color = '#C8C8FF', label = 'cuDF', align='center')
plt.bar(br3, diff, barWidth, color = '#AA1E1E', label = 'diferencia', align='center')
plt.xticks([r + barWidth for r in range(len(labels))], labels, fontsize=9, rotation=90)
plt.yticks(fontsize=9)
plt.xlabel("Operaciones", fontsize=10)
plt.ylabel("Duración total en segundos", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Duración total de la operación por marco de datos", fontsize=12)
plt.legend()
plt.show()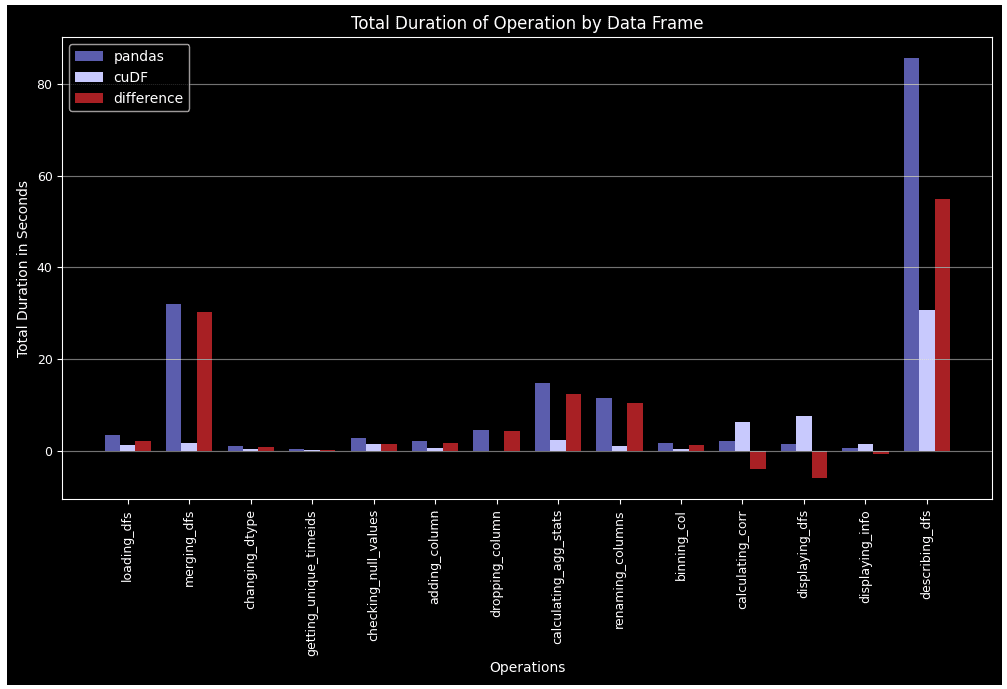 Exhibición-20: Duración total por operación durante 30 ciclos para el marco de datos Pandas y cuDF (Imagen por Autor)
Exhibición-20: Duración total por operación durante 30 ciclos para el marco de datos Pandas y cuDF (Imagen por Autor)
La última gráfica es “duración total por ciclo”, que muestra el tiempo total que todas las operaciones tomaron juntas para cada ciclo.
def plot_total_by_df(round_total):
# Tamaño de la figura
fig = plt.subplots(figsize =(10, 6))
X_axis = np.arange(1, ROUNDS+1)
# Duración total por ciclo para cada marco de datos
pd_round_total = [value[0] for key, value in round_total.items()]
cudf_round_total = [value[1] for key, value in round_total.items()]
# Diferencia de la duración total por ciclo para cada marco de datos
diff = [x[0]-x[1] for x in zip(pd_round_total, cudf_round_total)]
plt.plot(X_axis, pd_round_total, linestyle="-", linewidth=3, color = '#5A5AAF', label = "pandas")
plt.plot(X_axis, cudf_round_total, linestyle="-", linewidth=3, color = '#B0B05A', label = "cuDF")
plt.plot(X_axis, diff, linestyle="--", linewidth=3, color = '#AA1E1E', label = "diferencia")
plt.xticks(X_axis, fontsize=9)
plt.yticks(fontsize=9)
plt.xlabel("Ciclos", fontsize=10)
plt.ylabel("Duración total en segundos", fontsize=10)
plt.grid(axis='y', color="#E4E4E4", alpha=0.5)
plt.title("Duración total por ciclo", fontsize=12)
plt.legend()
plt.show()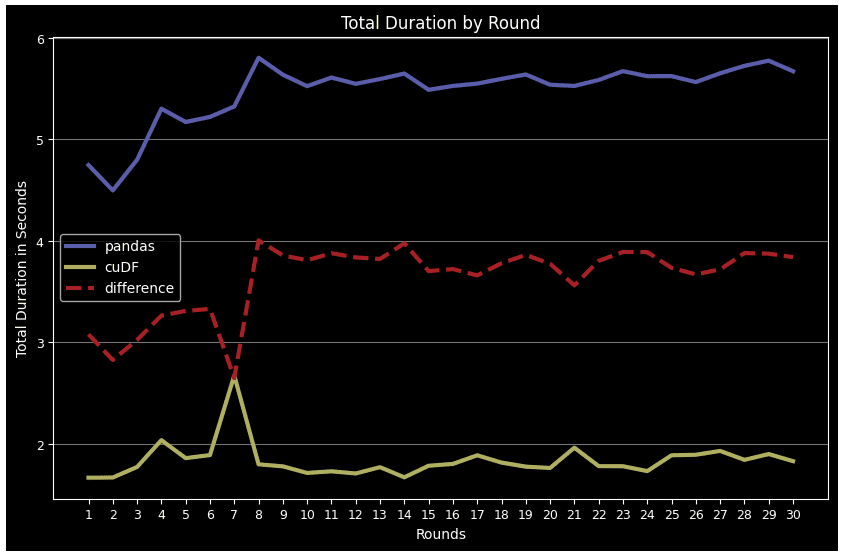 Exhibición-21: Duración total de todas las operaciones para cada ciclo para el marco de datos Pandas y cuDF (Imagen por Autor)
Exhibición-21: Duración total de todas las operaciones para cada ciclo para el marco de datos Pandas y cuDF (Imagen por Autor)
Aunque no hemos cubierto todas las tareas de ingeniería de características cumplidas en el conjunto de datos, son las mismas o similares a las que mostramos aquí. Al explicar 14 operaciones individualmente, intentamos documentar el rendimiento relativo del marco de datos Pandas y cuDF, y permitir la reproducibilidad.
En todos los casos excepto para el cálculo de correlación y la visualización del marco de datos, cuDF supera a Pandas. Esta ventaja de rendimiento se vuelve más notable en tareas complejas como groupby, merge, agg y describe. Otro punto es que Pandas DF se cansa con el tiempo cuando llegan más ciclos, mientras que cuDF sigue un patrón más estable.
Recordemos que hemos revisado solo una acción como ejemplo. Si procesamos las 112 acciones, podemos esperar una brecha de rendimiento aún mayor a favor de cuDF. Si la población de acciones aumenta a cientos, el rendimiento de cuDF puede ser aún más dramático. En el caso de big data, donde la ejecución de tareas paralelas es posible, un marco distribuido como Dask-cuDF, que extiende la computación paralela a los DataFrames de GPU de cuDF, puede ser la herramienta adecuada.
Referencias
[1] Definición de RAPIDS, https://www.heavy.ai/technical-glossary/rapids
[2] 10 minutos para cuDF y Dask-cuDF, https://docs.rapids.ai/api/cudf/stable/user_guide/10min/
[3] Optiver Realized Volatility Prediction, https://www.kaggle.com/competitions/optiver-realized-volatility-prediction/data
[4] Rellenando datos de libros hacia adelante, https://www.kaggle.com/competitions/optiver-realized-volatility-prediction/discussion/251277 Hasan Serdar Altan es científico de datos y arquitecto asociado de AWS Cloud.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce a TARDIS Un marco de trabajo de IA que identifica singularidades en espacios complejos y captura estructuras singulares y complejidad geométrica local en datos de imágenes.
- Predicción de rendimiento de cultivos utilizando Aprendizaje Automático e implementación de Flask.
- Cómo funciona GPT una explicación metafórica de Clave, Valor, Consulta en Atención, utilizando un cuento de pociones.
- JPL Crea Archivo PDF para Ayudar en la Investigación de Malware.
- Cuidado con los datos poco confiables en la evaluación de modelos un estudio de caso de selección de LLM Prompt con Flan-T5.
- Elegir el camino correcto Modelos de Churn vs. Modelos de Uplift
- Plotly y Python Creando Mapas de Calor Interactivos para Datos Petrofísicos y Geológicos





