Usando GANs en TensorFlow para generar imágenes
'Using GANs in TensorFlow to generate images'
Introducción
En este artículo, exploramos la aplicación de GANs en TensorFlow para generar representaciones únicas de dígitos escritos a mano. El marco de trabajo GAN consta de dos componentes clave: el generador y el discriminador. El generador genera nuevas imágenes de manera aleatoria, mientras que el discriminador está diseñado para diferenciar entre imágenes auténticas y falsificadas. A través del entrenamiento de GAN, obtenemos una colección de imágenes que se asemejan de cerca a dígitos escritos a mano. El objetivo principal de este artículo es describir el procedimiento para construir y evaluar GANs utilizando el conjunto de datos MNIST.
Objetivos de Aprendizaje
- Este artículo proporciona una introducción completa a las Redes Generativas Adversarias (GANs) y explora sus aplicaciones en la generación de imágenes.
- El objetivo principal de este tutorial es guiar a los lectores a través del proceso paso a paso de construir un GAN utilizando la biblioteca TensorFlow. Cubre el entrenamiento del GAN en el conjunto de datos MNIST para generar nuevas imágenes de dígitos escritos a mano.
- El artículo discute la arquitectura y los componentes de los GANs, incluyendo generadores y discriminadores, para mejorar la comprensión de los lectores sobre su funcionamiento fundamental.
- Para facilitar el aprendizaje, el artículo incluye ejemplos de código que demuestran diversas tareas, como la lectura y el preprocesamiento del conjunto de datos MNIST, la construcción de la arquitectura del GAN, el cálculo de las funciones de pérdida, el entrenamiento de la red y la evaluación de los resultados.
- Además, el artículo explora el resultado esperado de los GANs, que es una colección de imágenes que se asemejan de manera sorprendente a dígitos escritos a mano.
Este artículo fue publicado como parte del Data Science Blogathon.
¿Qué estamos construyendo?
Generar imágenes novedosas utilizando bases de datos de imágenes preexistentes es una característica destacada de modelos especializados llamados Redes Generativas Adversarias (GANs). Las GANs destacan en la producción de imágenes no supervisadas o semisupervisadas aprovechando conjuntos de datos de imágenes diversos.
Este artículo aprovecha el potencial de generación de imágenes de las GANs para crear dígitos escritos a mano. La metodología implica entrenar la red en una base de datos de dígitos escritos a mano. En esta pieza instructiva, construiremos un GAN rudimentario utilizando la biblioteca Tensorflow, realizaremos el entrenamiento en el conjunto de datos MNIST y generaremos imágenes frescas de dígitos escritos a mano.
- ¿Qué es la simulación de robótica?
- Una guía para mejorar la transformación digital a través de la limpieza de datos
- Ejecución de tareas de Python Wheel en contenedores Docker personalizados en Databricks
¿Cómo lo configuramos?
El énfasis principal de este artículo gira en torno al aprovechamiento del potencial de generación de imágenes de las GANs. El procedimiento comienza con la carga y el preprocesamiento de la base de datos de imágenes para facilitar el proceso de entrenamiento del GAN. Una vez que los datos se cargan correctamente, procedemos a construir el modelo del GAN y desarrollar el código necesario para el entrenamiento y la prueba. En la siguiente sección, se proporcionan instrucciones detalladas sobre la implementación de esta funcionalidad y la generación de una imagen fresca utilizando la base de datos MNIST.
Construcción del Modelo
El modelo del GAN que pretendemos construir consta de dos componentes importantes:
- Generador: Este componente es responsable de generar nuevas imágenes.
- Discriminador: Este componente evalúa la calidad de la imagen generada.
La arquitectura general que desarrollaremos para generar imágenes utilizando GAN se muestra en el siguiente diagrama. La siguiente sección proporciona una breve descripción de cómo leer la base de datos, crear la arquitectura requerida, calcular la función de pérdida y entrenar la red. Además, se proporciona código para inspeccionar la red y generar nuevas imágenes.
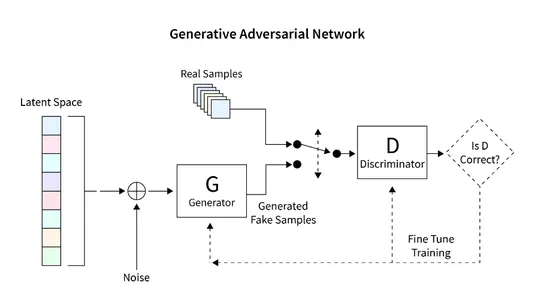
Lectura del Conjunto de Datos
El conjunto de datos MNIST tiene una gran importancia en el campo de la visión por computadora y consta de una vasta colección de dígitos escritos a mano con dimensiones de 28×28 píxeles. Este conjunto de datos resulta ideal para nuestra implementación de GAN debido a su formato de imagen en escala de grises de un solo canal.
El fragmento de código siguiente muestra la utilización de una función incorporada en Tensorflow para cargar el conjunto de datos MNIST. Una vez que se carga correctamente, procedemos a normalizar y remodelar las imágenes en un formato tridimensional. Esta transformación permite el procesamiento eficiente de los datos de imagen 2D dentro de la arquitectura del GAN. Además, se asigna memoria tanto para los datos de entrenamiento como para los de validación.
La forma de cada imagen se define como una matriz de 28x28x1, donde la última dimensión representa el número de canales en la imagen. Como el conjunto de datos MNIST consta de imágenes en escala de grises, solo tenemos un canal.
En este caso particular, establecemos el tamaño del espacio latente, denominado “zsize”, en 100. Este valor se puede ajustar según requisitos o preferencias específicas.
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np
num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100
(train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))Definición del Generador
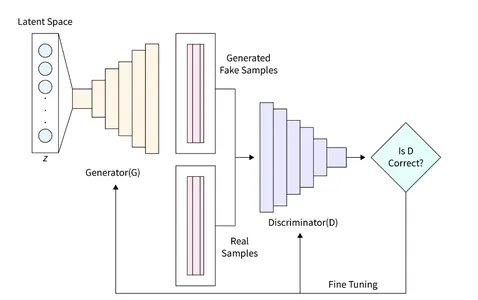
El Generador (D) desempeña un papel crucial en las GANs ya que es responsable de generar imágenes realistas que pueden engañar al discriminador. Sirve como el componente principal para la formación de imágenes en las GANs. En este estudio, utilizamos una arquitectura específica para el Generador, que incorpora una capa completamente conectada (FC) y utiliza la activación Leaky ReLU. Sin embargo, cabe destacar que la última capa del Generador utiliza la activación TanH en lugar de LeakyReLU. Esta ajuste se realizó para asegurar que la imagen generada se encuentre dentro del mismo intervalo (-1, 1) que la base de datos MNIST original.
def build_generator():
gen_model = Sequential()
gen_model.add(Dense(256, input_dim=z_size))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(512))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(1024))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(np.prod(input_shape), activation='tanh'))
gen_model.add(Reshape(input_shape))
gen_noise = Input(shape=(z_size,))
gen_img = gen_model(gen_noise)
return Model(gen_noise, gen_img)Definición del Discriminador
En una Red Generativa Adversaria (GAN), el Discriminador (D) realiza la tarea crítica de diferenciar entre imágenes reales e imágenes generadas evaluando su autenticidad y probabilidad. Este componente puede verse como un problema de clasificación binaria. Para abordar esta tarea, podemos utilizar una arquitectura de red simplificada que incluye capas completamente conectadas (FC), activación Leaky ReLU y capas de Dropout. Es importante mencionar que la capa final del Discriminador incluye una capa FC seguida de una activación Sigmoid. La función de activación Sigmoid produce la probabilidad de clasificación deseada.
def build_discriminator():
disc_model = Sequential()
disc_model.add(Flatten(input_shape=input_shape))
disc_model.add(Dense(512))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(256))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(1, activation='sigmoid'))
disc_img = Input(shape=input_shape)
validity = disc_model(disc_img)
return Model(disc_img, validity)Cálculo de la Función de Pérdida
Para asegurar un buen proceso de generación de imágenes en las GANs, es importante determinar las métricas adecuadas para evaluar su rendimiento. Defina este parámetro mediante la función de pérdida.
El discriminador es responsable de dividir la imagen generada en real o falsa y dar la probabilidad de ser real. Para lograr esta diferencia, el Discriminador busca maximizar la función D(x) cuando se le presenta una imagen real y minimizar D(G(z)) cuando se le presenta una imagen falsa.
Por otro lado, el objetivo del Generador es engañar al Discriminador creando una imagen realista que pueda ser malinterpretada. Matemáticamente, esto implica escalar D(G(z)). Sin embargo, depender únicamente de este componente como función de pérdida puede hacer que la red sea demasiado confiada con resultados incorrectos. Para resolver este problema, utilizamos el logaritmo de la función de pérdida (D(G(z)).
La función de costo general del GAN para generar una imagen se puede expresar como un juego mínimo:
min_G max_D V(D,G) = E(xp_data(x))(log(D(x))] + E(zp(z))(log(1 – D(G(z)))])
Este entrenamiento del GAN requiere un equilibrio delicado y puede considerarse como un enfrentamiento entre dos oponentes. Cada lado busca influir y superar al otro jugando el juego MinMax.
Podemos utilizar la Pérdida de Entropía Cruzada Binaria para implementar el Generador y el Discriminador.
Para la implementación del Generador y el Discriminador, podemos utilizar la Pérdida de Entropía Cruzada Binaria.
# discriminador
disc = build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
z = Input(shape=(z_size,))
# generador
img = generator(z)
disc.trainable = False
validity = disc(img)
# modelo combinado
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')Optimizando la Pérdida
Para facilitar el entrenamiento de la red, nuestro objetivo es involucrar al GAN en un juego MinMax. Este proceso de aprendizaje gira en torno a la optimización de los pesos de la red utilizando el Descenso de Gradiente. Con el fin de acelerar el proceso de aprendizaje y evitar la convergencia a paisajes de pérdida subóptimos, se utiliza el Descenso de Gradiente Estocástico (SGD).
Dado que el Discriminador y el Generador tienen pérdidas distintas, una única función de pérdida no puede optimizar simultáneamente ambos sistemas. En consecuencia, utilizamos funciones de pérdida separadas para cada sistema.
def inicializar_modelo():
disc = build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
generator = build_generator()
z = Input(shape=(z_size,))
img = generator(z)
disc.trainable = False
validity = disc(img)
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
return disc, generator y combinedDespués de especificar todas las características necesarias, podemos entrenar el sistema y optimizar la pérdida. Los pasos para entrenar un GAN para generar una imagen son los siguientes:
- Cargar la imagen y generar un sonido aleatorio del mismo tamaño que la imagen cargada.
- Diferenciar entre la imagen cargada y el sonido producido y considerar la posibilidad de que sea real o falso.
- Producir otro ruido aleatorio de la misma magnitud y proporcionarlo como entrada al generador.
- Entrenar el generador durante un período específico.
- Repetir estos pasos hasta que la imagen sea satisfactoria.
def entrenar(epochs, batch_size=128, sample_interval=50):
# cargar imágenes
(train_ims, _), (_, _) = mnist.load_data()
# preprocesar
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# bucle de entrenamiento
for epoch in range(epochs):
batch_index = np.random.randint(0, train_ims.shape[0], batch_size)
imgs = train_ims[batch_index]
# crear ruido
noise = np.random.normal(0, 1, (batch_size, z_size))
# predecir utilizando un Generador
gen_imgs = gen.predict(noise)
# calcular las funciones de pérdida
real_disc_loss = disc.train_on_batch(imgs, valid)
fake_disc_loss = disc.train_on_batch(gen_imgs, fake)
disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss)
noise = np.random.normal(0, 1, (batch_size, z_size))
g_loss = full_model.train_on_batch(noise, valid)
# guardar salidas cada pocas épocas
if epoch % sample_interval == 0:
una_tanda(epoch)Generando Dígitos Manuscritos
Utilizando el conjunto de datos MNIST, podemos crear una función de utilidad para generar predicciones para un conjunto de imágenes utilizando el Generador. Esta función genera un sonido aleatorio, lo suministra al generador, lo ejecuta para mostrar la imagen generada y la guarda en una carpeta especial. Se recomienda ejecutar esta función de utilidad periódicamente, como cada 200 ciclos, para supervisar el progreso de la red. La implementación es la siguiente:
def una_tanda(epoch):
r, c = 5, 5
noise_model = np.random.normal(0, 1, (r * c, z_size))
gen_images = gen.predict(noise_model)
# Escalar las imágenes de 0 a 1
gen_images = gen_images*(0.5) + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()En nuestro experimento, entrenamos el GAN durante aproximadamente 10,000 épocas usando un tamaño de lote de 32. Para seguir el progreso del entrenamiento, guardamos las imágenes generadas cada 200 épocas y las almacenamos en una carpeta designada llamada “imágenes”.
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)Ahora, vamos a examinar los resultados de la simulación del GAN en diferentes etapas: inicialización, 400 épocas, 5000 épocas y el resultado final en 10000 épocas.
Inicialmente, comenzamos con ruido aleatorio como entrada para el Generador.

Después de 400 épocas de entrenamiento, podemos observar cierto progreso, aunque las imágenes generadas todavía difieren significativamente de los dígitos reales.

Después de entrenar durante 5000 épocas, podemos observar que las figuras generadas comienzan a parecerse al conjunto de datos MNIST.

Al completar las 10,000 épocas completas de entrenamiento, obtenemos las siguientes salidas.

Estas imágenes generadas se asemejan de cerca a los datos de números escritos a mano para entrenar la red. Es importante tener en cuenta que estas imágenes no forman parte del conjunto de entrenamiento y son generadas completamente por la red.
Próximos pasos
Ahora que hemos logrado buenos resultados en la generación de imágenes del GAN, hay muchas formas en las que podemos mejorar aún más. Dentro del alcance de esta discusión, podríamos considerar experimentar con diferentes parámetros. Aquí hay algunas sugerencias:
- Explorar diferentes valores para la variable de espacio latente z_size para ver si aumenta la eficiencia.
- Aumentar el número de épocas de entrenamiento a más de 10,000. Duplicar o triplicar la duración del entrenamiento puede revelar resultados mejorados o degradados.
- Intentar utilizar conjuntos de datos diferentes como fashion MNIST o moving MNIST. Dado que estos conjuntos de datos tienen la misma estructura que MNIST, adaptar nuestro código existente.
- Considerar experimentar con arquitecturas alternativas como CycleGun, DCGAN y otras. Modificar las funciones del generador y del discriminador puede ser suficiente para explorar estos modelos.
Implementando estos cambios, podemos mejorar aún más las capacidades de los GAN y explorar nuevas posibilidades en la generación de imágenes.
Estas imágenes generadas se asemejan de cerca a los datos de números escritos a mano que se utilizan para entrenar la red. Estas imágenes no forman parte del conjunto de entrenamiento y son generadas completamente por la red.
Conclusión
En resumen, GAN es un modelo de aprendizaje automático poderoso capaz de generar nuevas imágenes basadas en bases de datos existentes. En este tutorial, hemos mostrado cómo diseñar y entrenar un GAN simple utilizando la biblioteca Tensorflow como ejemplo y la base de datos MNIST.
Puntos clave
- GAN consta de dos componentes importantes: un generador, que se encarga de generar nuevas imágenes a partir de una entrada aleatoria, y el discriminador, que tiene como objetivo distinguir entre imágenes reales y falsas.
- A través del proceso de aprendizaje, hemos logrado crear un conjunto de imágenes que se asemejan de cerca a los dígitos escritos a mano, como se muestra en la imagen de ejemplo.
- Para optimizar el rendimiento de GAN, proporcionamos métricas de coincidencia y funciones de pérdida que ayudan a distinguir imágenes reales y falsas. Al evaluar los GAN en datos no vistos y utilizando generadores, podemos generar imágenes nuevas que no se han visto antes.
- En general, los GAN ofrecen posibilidades interesantes en la generación de imágenes y tienen un gran potencial para diversas aplicaciones como el aprendizaje automático y la visión por computadora.
Preguntas frecuentes
Los medios mostrados en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aprovechando los datos de precipitación y climatología en Sudamérica
- Manteniendo la Calidad de Datos en Sistemas de Aprendizaje Automático
- Las habilidades que ayudan a los científicos de datos a crecer
- Revelando el Precision@N y Recall@N en un Sistema de Recomendación
- ¿Cómo ayuda la inteligencia artificial en la generación de leads?
- Potenciando conocimientos sobre la Web 3.0 y Blockchain
- Un Análisis de Interesados que a los expertos en Ciencia de Datos les encantará






