Utilice Amazon SageMaker Canvas para construir modelos de aprendizaje automático utilizando datos Parquet de Amazon Athena y AWS Lake Formation.
Use Amazon SageMaker Canvas to build ML models using Amazon Athena Parquet data and AWS Lake Formation.
Los datos son la base para los algoritmos de aprendizaje automático (ML). Uno de los formatos más comunes para almacenar grandes cantidades de datos es Apache Parquet debido a su formato compacto y altamente eficiente. Esto significa que los analistas de negocios que desean extraer información de los grandes volúmenes de datos en su almacén de datos deben usar frecuentemente datos almacenados en Parquet.
Para simplificar el acceso a los archivos Parquet, Amazon SageMaker Canvas ha agregado capacidades de importación de datos desde más de 40 fuentes de datos, incluyendo Amazon Athena, que admite Apache Parquet.
Canvas ofrece conectores a fuentes de datos de AWS como Amazon Simple Storage Service (Amazon S3), Athena y Amazon Redshift. En esta publicación, describimos cómo consultar archivos Parquet con Athena utilizando AWS Lake Formation y usar la salida de Canvas para entrenar un modelo.
Descripción general de la solución
Athena es un servicio de análisis interactivo sin servidor construido sobre marcos de trabajo de código abierto, que admite formatos de archivo y tabla abiertos. Muchos equipos están recurriendo a Athena para permitir la consulta interactiva y analizar sus datos en los respectivos almacenes de datos sin crear múltiples copias de datos.
- Vuelva a entrenar los modelos de aprendizaje automático y automatice las predicciones por lotes en Amazon SageMaker Canvas utilizando conjuntos de datos actualizados.
- 4 Funciones de Pandas para la comparación elemento a elemento de DataFrames
- Una guía completa para empezar su propio Homelab para análisis de datos.
Athena permite que las aplicaciones usen SQL estándar para consultar cantidades masivas de datos en un lago de datos S3. Athena admite varios formatos de datos, incluyendo:
- CSV
- TSV
- JSON
- archivos de texto
- formatos columnares de código abierto, como ORC y Parquet
- datos comprimidos en formatos Snappy, Zlib, LZO y GZIP
Los archivos Parquet organizan los datos en columnas y utilizan esquemas de compresión y codificación eficientes para un almacenamiento y recuperación de datos rápidos. Puede reducir el tiempo de importación en Canvas mediante el uso de archivos Parquet para importaciones de datos a granel y con columnas específicas.
Lake Formation es un servicio integrado de lago de datos que facilita la ingestión, limpieza, catalogación, transformación y seguridad de sus datos y los hace disponibles para el análisis y el aprendizaje automático (ML). Lake Formation administra automáticamente el acceso a los datos registrados en Amazon S3 a través de servicios que incluyen AWS Glue, Athena, Amazon Redshift, Amazon QuickSight y Amazon EMR utilizando blocs de notas de Zeppelin con Apache Spark para garantizar el cumplimiento de sus políticas definidas.
En esta publicación, le mostramos cómo importar datos Parquet a Canvas desde Athena, donde Lake Formation habilita la gobernanza de datos.
Para ilustrar, usamos los datos de operaciones de un negocio de electrónica de consumo. Creamos un modelo para estimar la demanda de productos electrónicos utilizando sus datos de series temporales históricos.
Esta solución se ilustra en tres pasos:
- Configuración del Lake Formation.
- Conceda permisos de acceso del Lake Formation a Canvas.
- Importe los datos Parquet a Canvas usando Athena.
- Use los datos Parquet importados para crear modelos de ML con Canvas.
El siguiente diagrama ilustra la arquitectura de la solución.
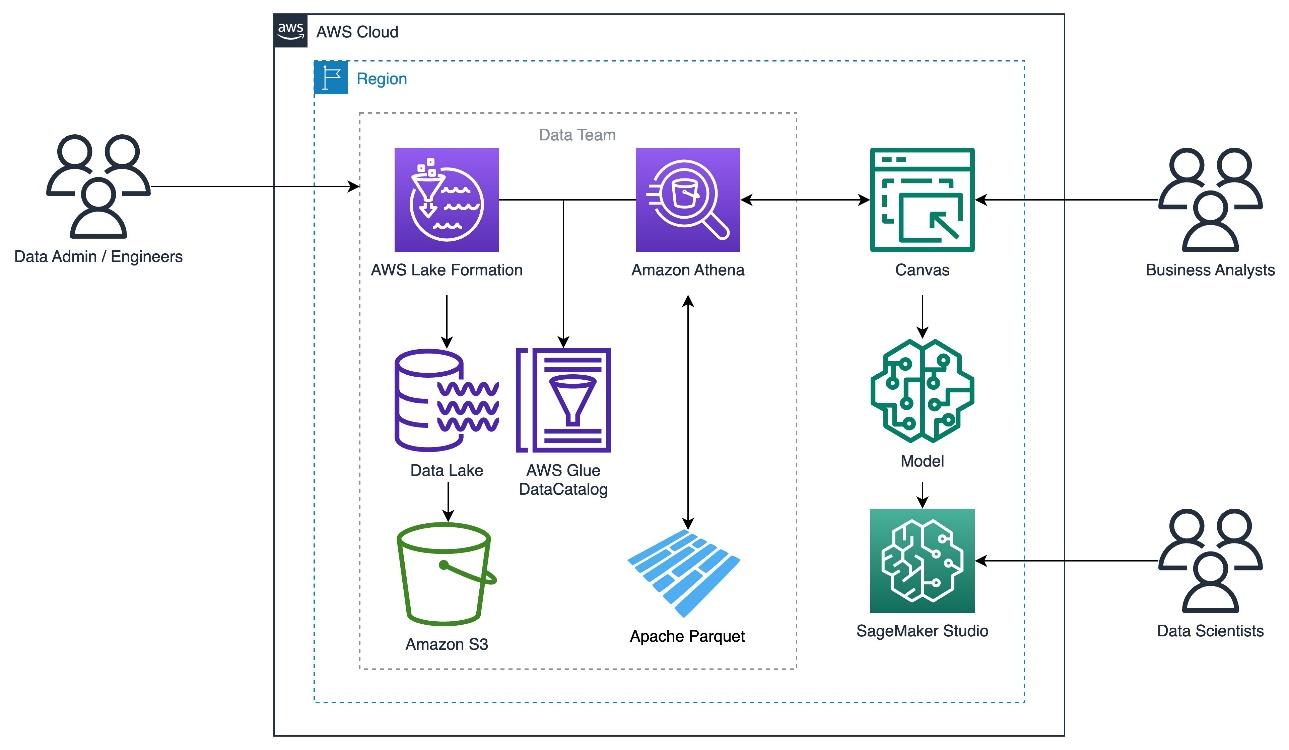
Configurar la base de datos de Lake Formation
Los pasos enumerados aquí forman una configuración única para mostrarle el lago de datos que aloja los datos Parquet, que pueden ser consumidos por sus analistas para obtener información utilizando Canvas. Los ingenieros o administradores en la nube pueden realizar mejor estos requisitos previos. Los analistas pueden ir directamente a Canvas e importar los datos de Athena.
Los datos utilizados en esta publicación consisten en dos conjuntos de datos obtenidos de Amazon S3. Estos conjuntos de datos se han generado sintéticamente para esta publicación.
- Series de tiempo objetivo de electrónica de consumo (TTS): Los datos históricos de la cantidad a pronosticar se llaman la Serie de tiempo objetivo (TTS). En este caso, es la demanda de un artículo.
- Series de tiempo relacionadas con electrónica de consumo (RTS): Otros datos históricos que se conocen exactamente al mismo tiempo que cada transacción de venta se llaman Serie de tiempo relacionada (RTS). En nuestro caso de uso, es el precio de un artículo. Un conjunto de datos de RTS incluye datos de series temporales que no se incluyen en un conjunto de datos TTS y que podrían mejorar la exactitud de su predictor.
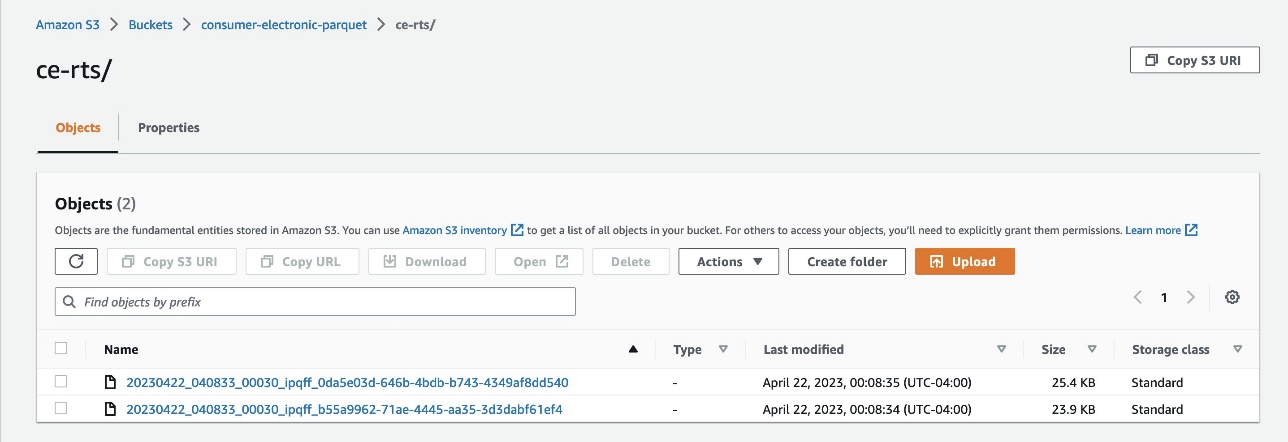
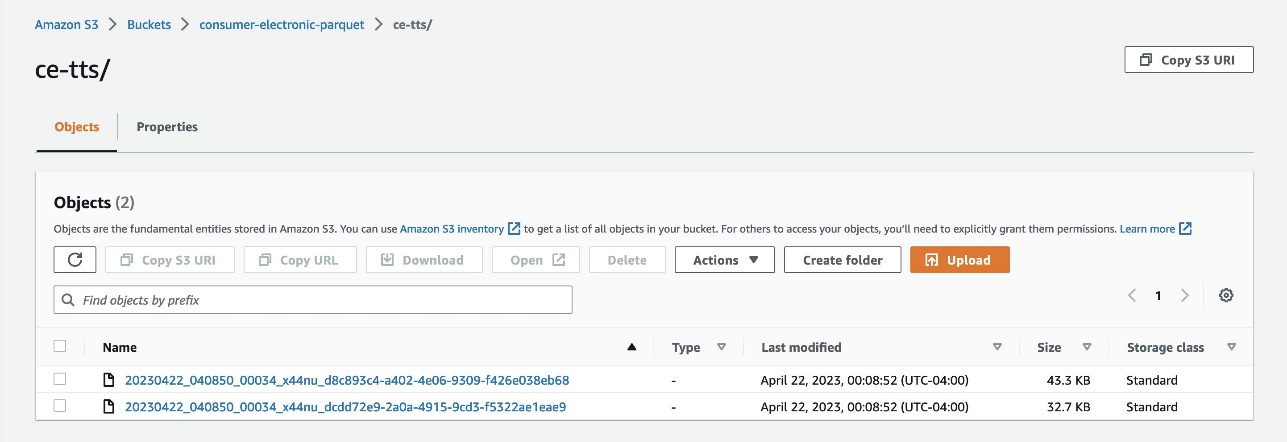
- Cargue los datos en Amazon S3 como archivos Parquet de estas dos carpetas:
- ce-rts: Contiene la Serie de tiempo relacionada con electrónica de consumo (RTS).
- ce-tts: Contiene la Serie de tiempo objetivo de electrónica de consumo (TTS).
- Crea un lago de datos con Lake Formation.
- En la consola de Lake Formation, crea una base de datos llamada
consumer-electronics.
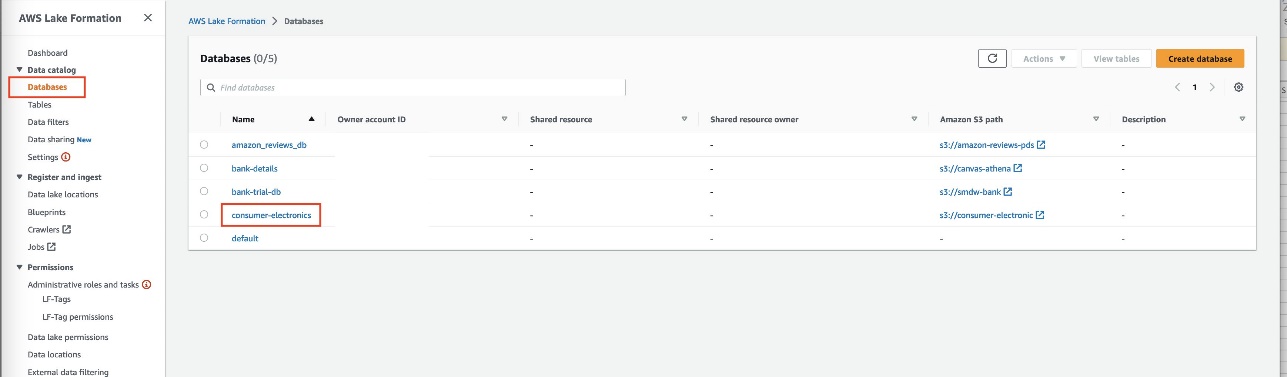
- Crea dos tablas para el conjunto de datos de electrónica de consumo con los nombres
ce-rts-Parquetyce-tts-Parquetcon los datos obtenidos del bucket de S3.
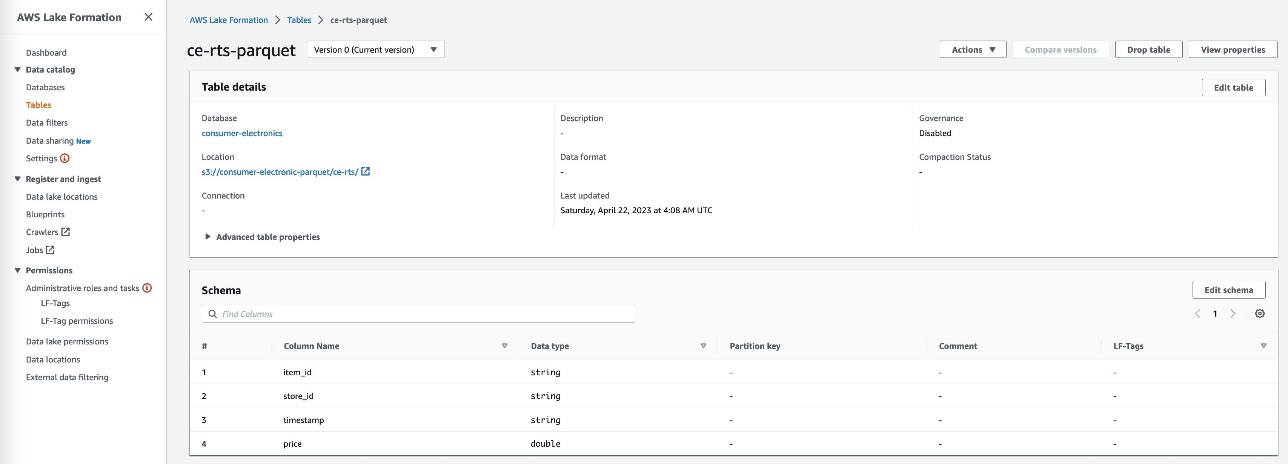
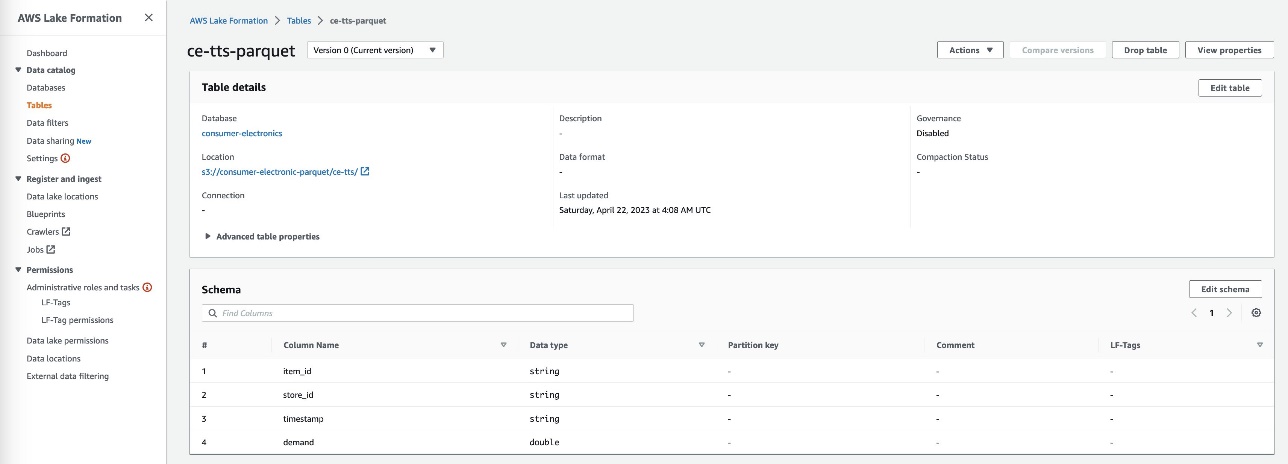
Usamos la base de datos que creamos en este paso en un paso posterior para importar los datos Parquet en Canvas utilizando Athena.
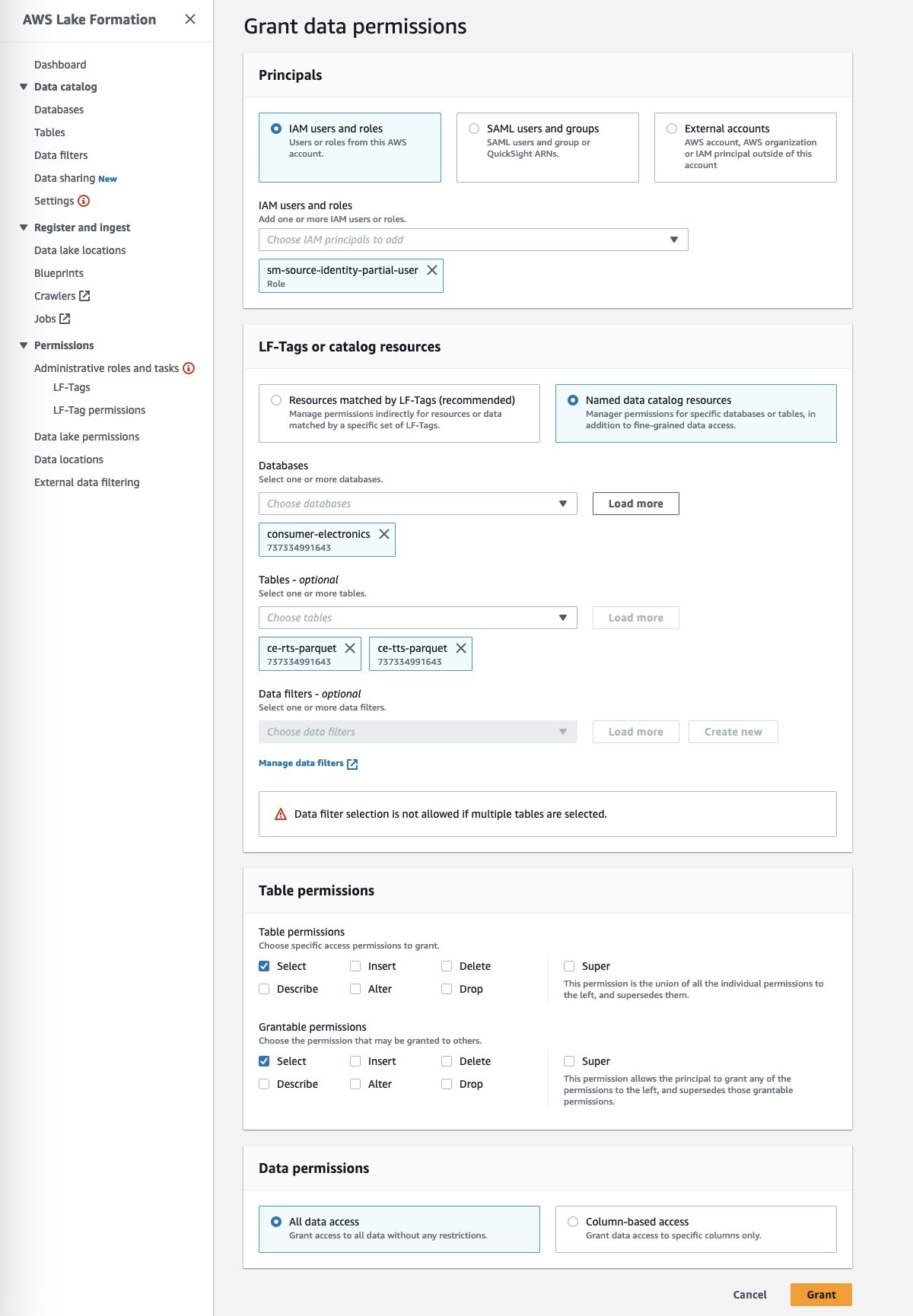
Conceder permisos de acceso de Lake Formation a Canvas
Esta es una configuración única que debe ser realizada por ingenieros o administradores en la nube.
- Concede permisos de lago de datos para acceder a Canvas y acceder a los datos Parquet de electrónica de consumo.
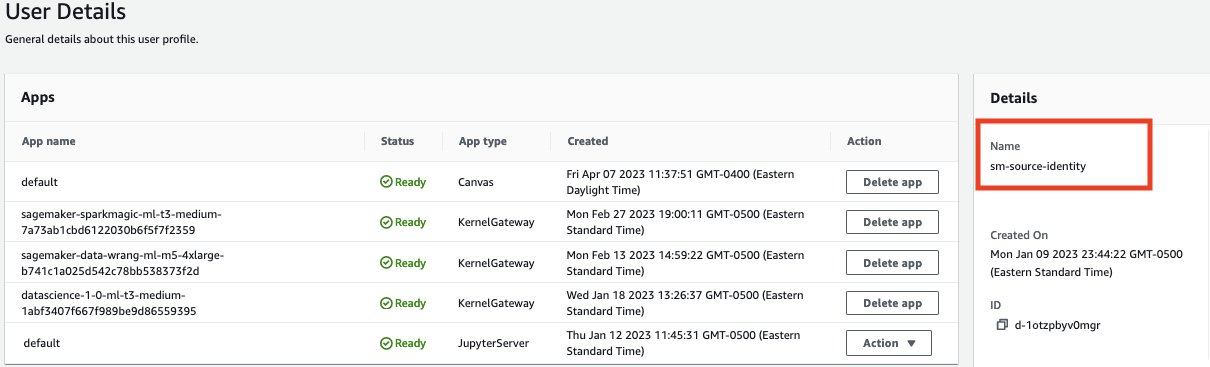
- En el dominio de SageMaker Studio, ve los detalles del usuario de Canvas.
- Copia el nombre del rol de ejecución.
- Asegúrate de que el rol de ejecución tenga suficientes permisos para acceder a los siguientes servicios:
- Canvas.
- El bucket de S3 donde se almacenan los datos Parquet.
- Athena para conectarse desde Canvas.
- AWS Glue para acceder a los datos Parquet utilizando el conector Athena.
- En Lake Formation, elige Permisos de lago de datos en el panel de navegación.
- Elige Conceder.
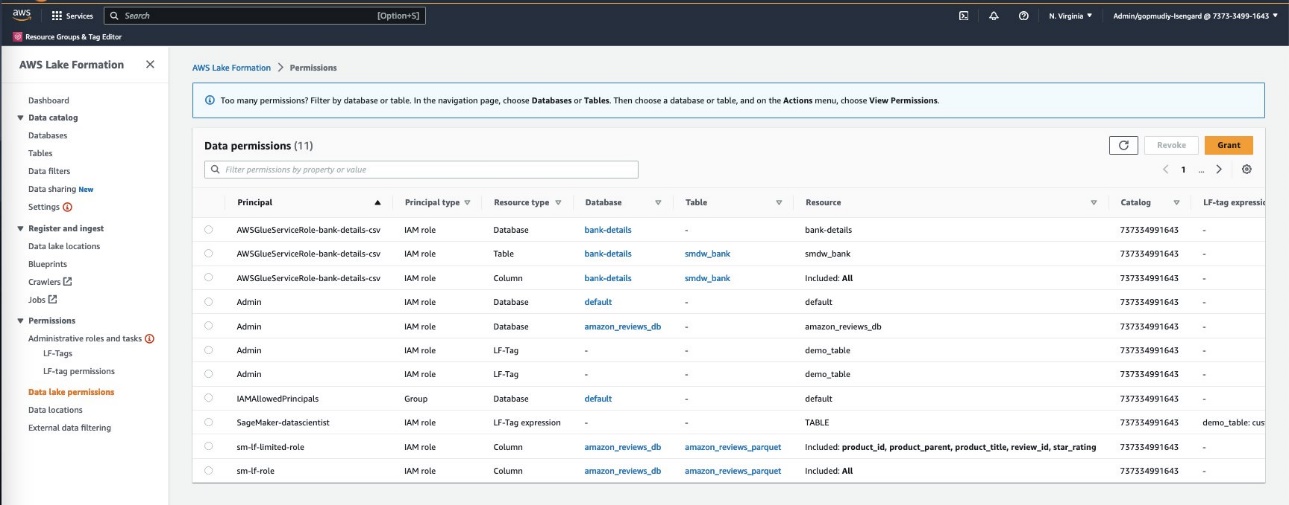
- Para Principales, selecciona Usuarios y roles de IAM para proporcionar acceso de Canvas a tus artefactos de datos.
- Especifica el rol de ejecución del usuario de SageMaker Studio de Canvas.
- Especifica la base de datos y las tablas.
- Elige Conceder.
Puedes conceder acciones granulares en las tablas, columnas y datos. Esta opción proporciona una configuración de acceso granular de tus datos sensibles mediante la segregación de roles que hayas definido.
Después de configurar el entorno necesario para la integración de Canvas y Athena, procede al siguiente paso para importar los datos en Canvas utilizando Athena.
Importar datos utilizando Athena
Complete los siguientes pasos para importar los archivos Parquet administrados por Lake Formation:
- En Canvas, elija Conjuntos de datos en el panel de navegación.
- Elija + Importar para importar los conjuntos de datos Parquet administrados por Lake Formation.
- Elija Athena como origen de datos.
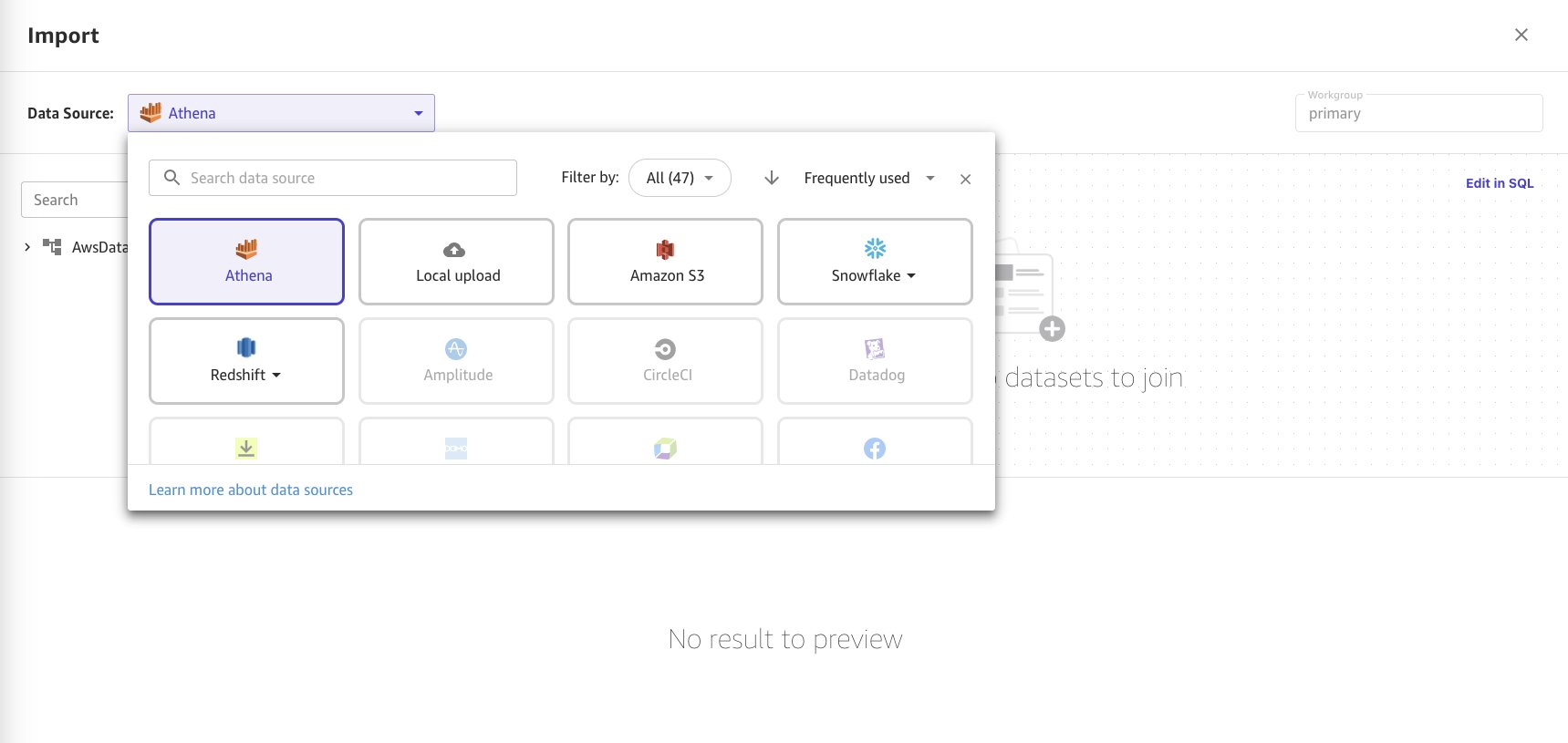
- Elija el conjunto de datos
consumer-electronicsen formato Parquet del catálogo de datos y detalles de la tabla de Athena en el menú. - Importe los dos conjuntos de datos. Arrastre y suelte la fuente de datos para seleccionar el primero.

Cuando arrastre y suelte el conjunto de datos, la vista previa de los datos aparecerá en el marco inferior de la página.
- Elija Importar datos.
- Ingrese
consumer-electronics-rtscomo el nombre del conjunto de datos que está importando.
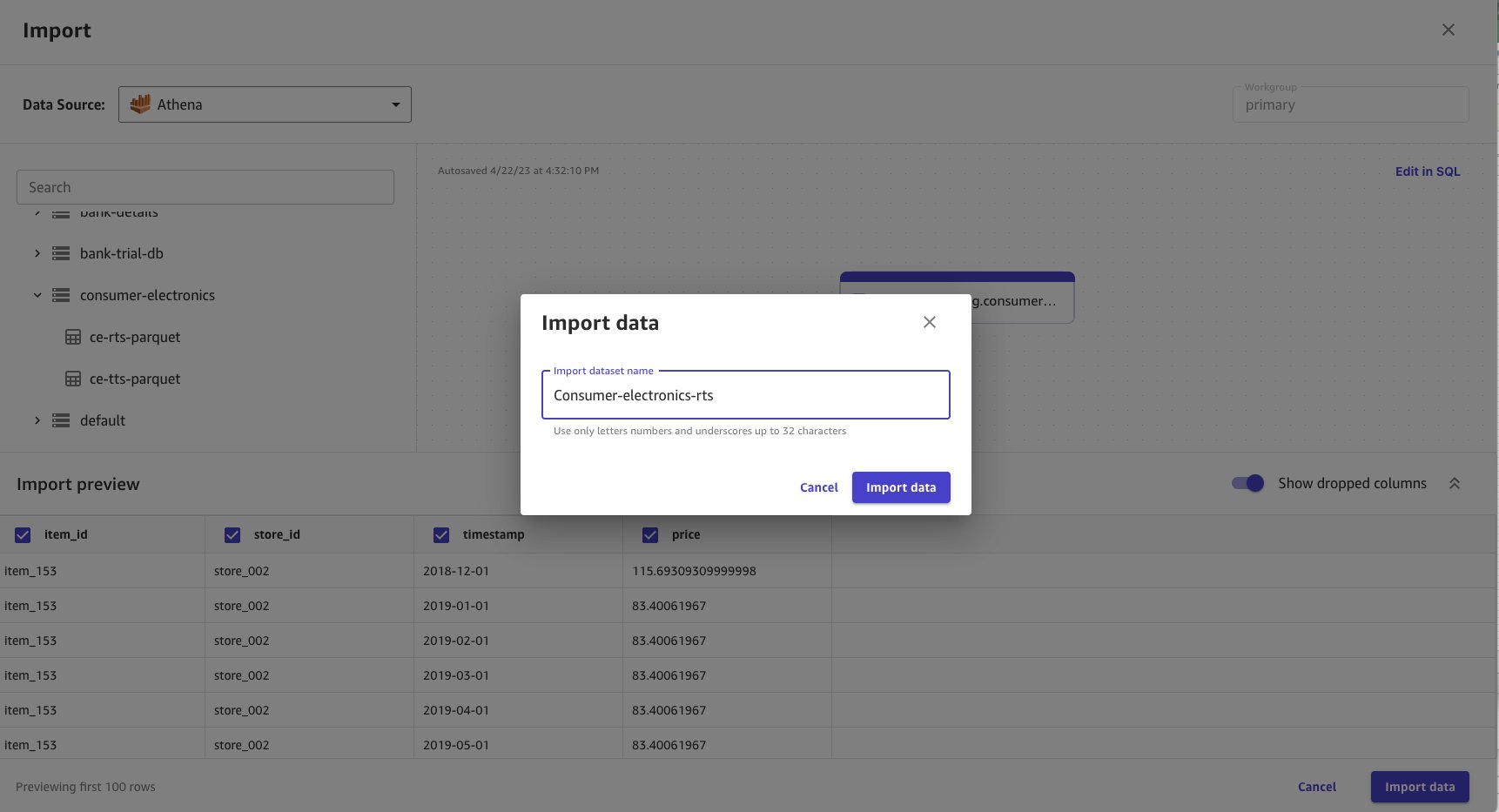
La importación de datos lleva tiempo en función del tamaño de los datos. El conjunto de datos en este ejemplo es pequeño, por lo que la importación tarda unos segundos. Cuando se completa la importación de datos, el estado cambia de Procesando a Listo.
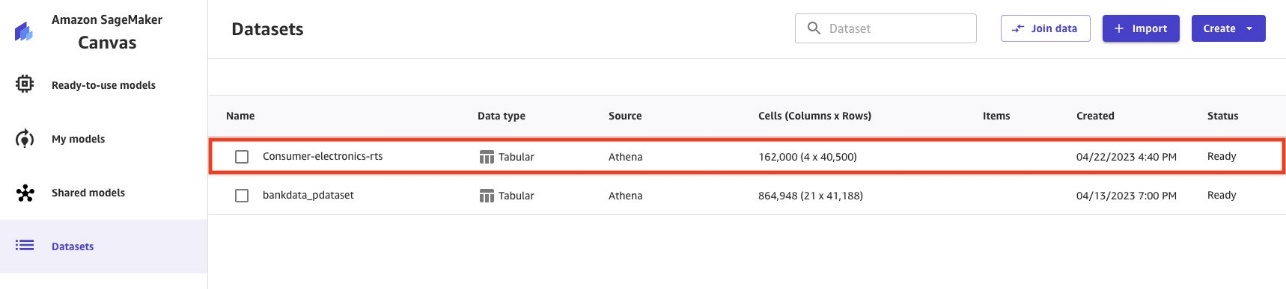
- Repita el proceso de importación para el segundo conjunto de datos (
ce-tts).
Cuando se importan los datos Parquet de ce-tts, la página Conjuntos de datos muestra ambos conjuntos de datos.
Los conjuntos de datos importados contienen datos de series de tiempo dirigidos y relacionados. El conjunto de datos RTS puede ayudar a mejorar la precisión de las predicciones de los modelos de aprendizaje profundo.
Unamos los conjuntos de datos para prepararnos para nuestro análisis.
- Seleccione los conjuntos de datos.
- Elija Unir datos.
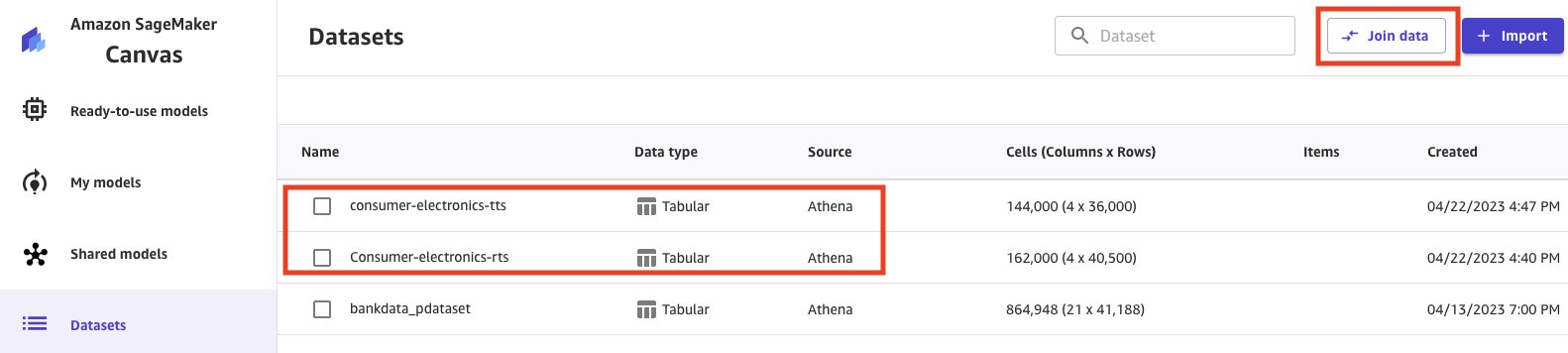
- Seleccione y arrastre ambos conjuntos de datos al panel central, lo que aplica una unión interna.
- Elija el icono Unir para ver las condiciones de unión aplicadas y asegurarse de que se aplique la unión interna y se unan las columnas correctas.
- Elija Guardar y cerrar para aplicar la condición de unión.
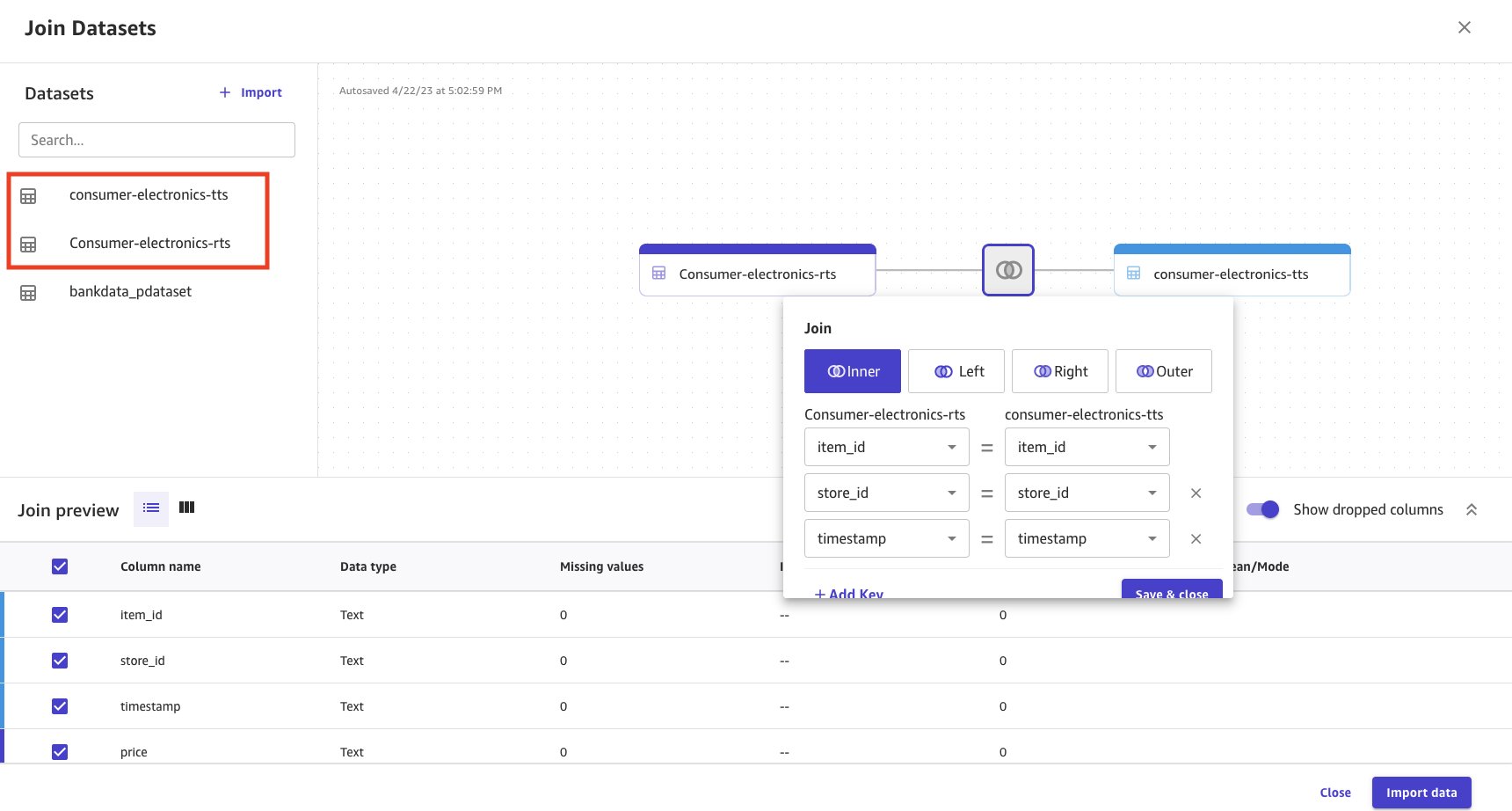
- Proporcione un nombre para el conjunto de datos unido.
- Seleccione Importar datos.
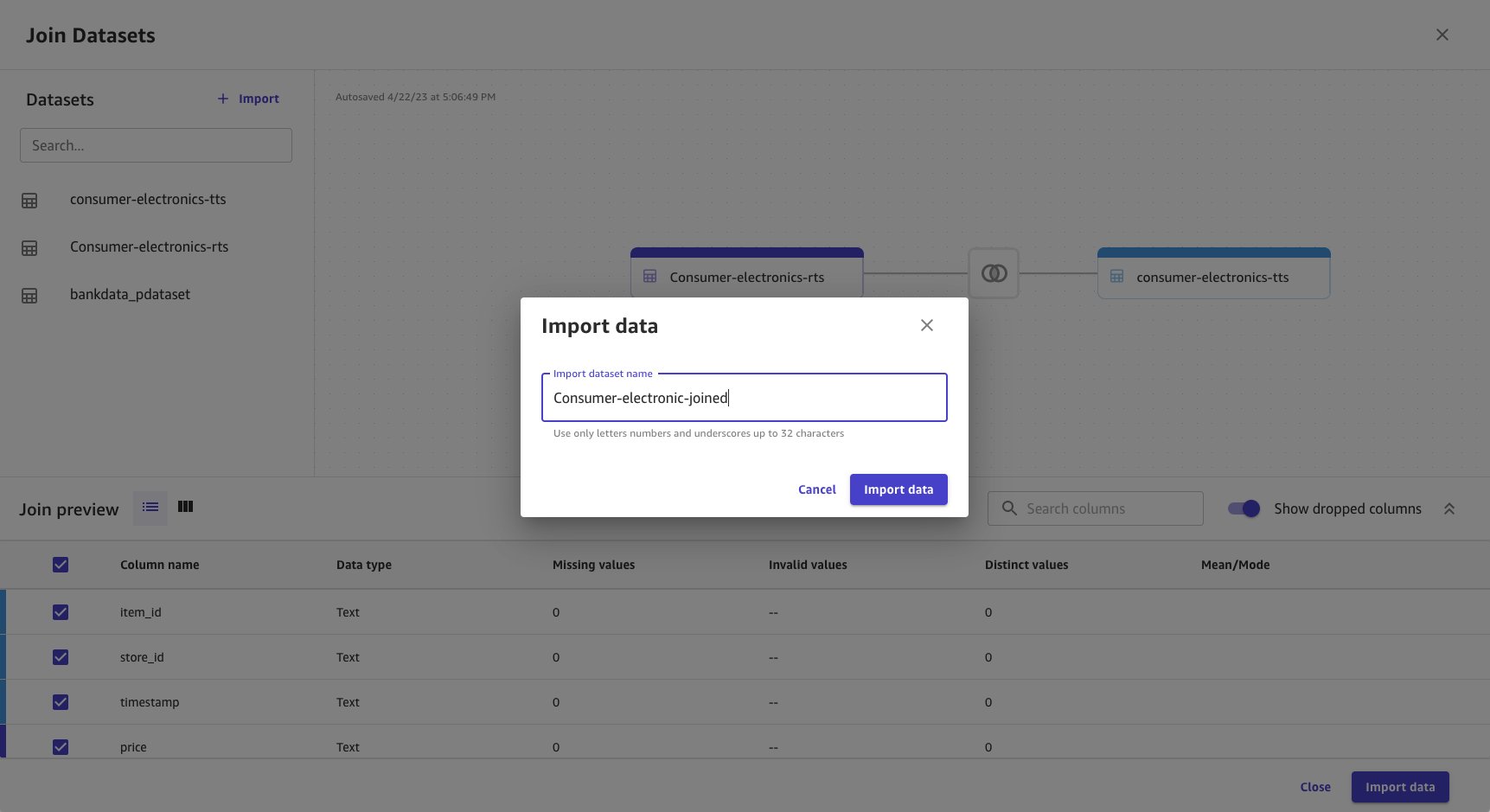
Los datos unidos se importan y crean como un nuevo conjunto de datos. La fuente del conjunto de datos unido se muestra como Unir.
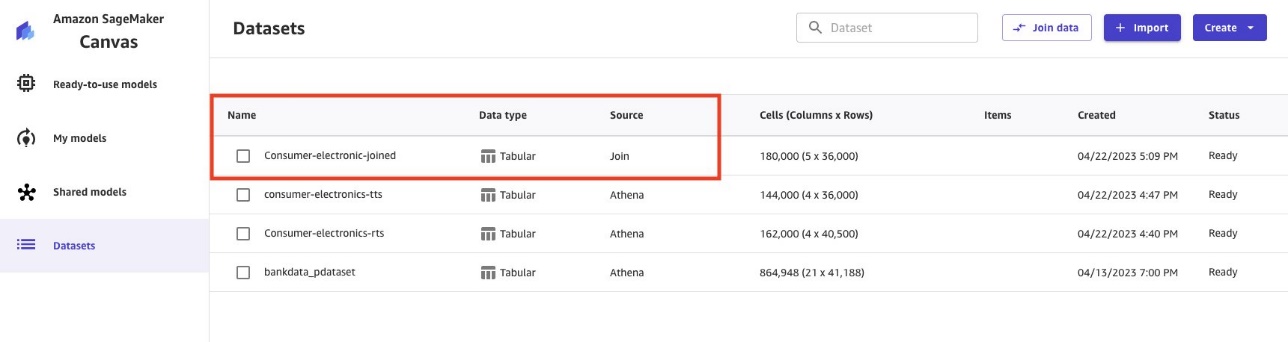
Usar los datos Parquet para construir modelos de ML con Canvas
Los datos Parquet de Lake Formation ahora están disponibles en Canvas. Ahora puede ejecutar su análisis de ML en los datos.
- Seleccione Crear un modelo personalizado en Modelos listos para usar de Canvas después de importar los datos con éxito.
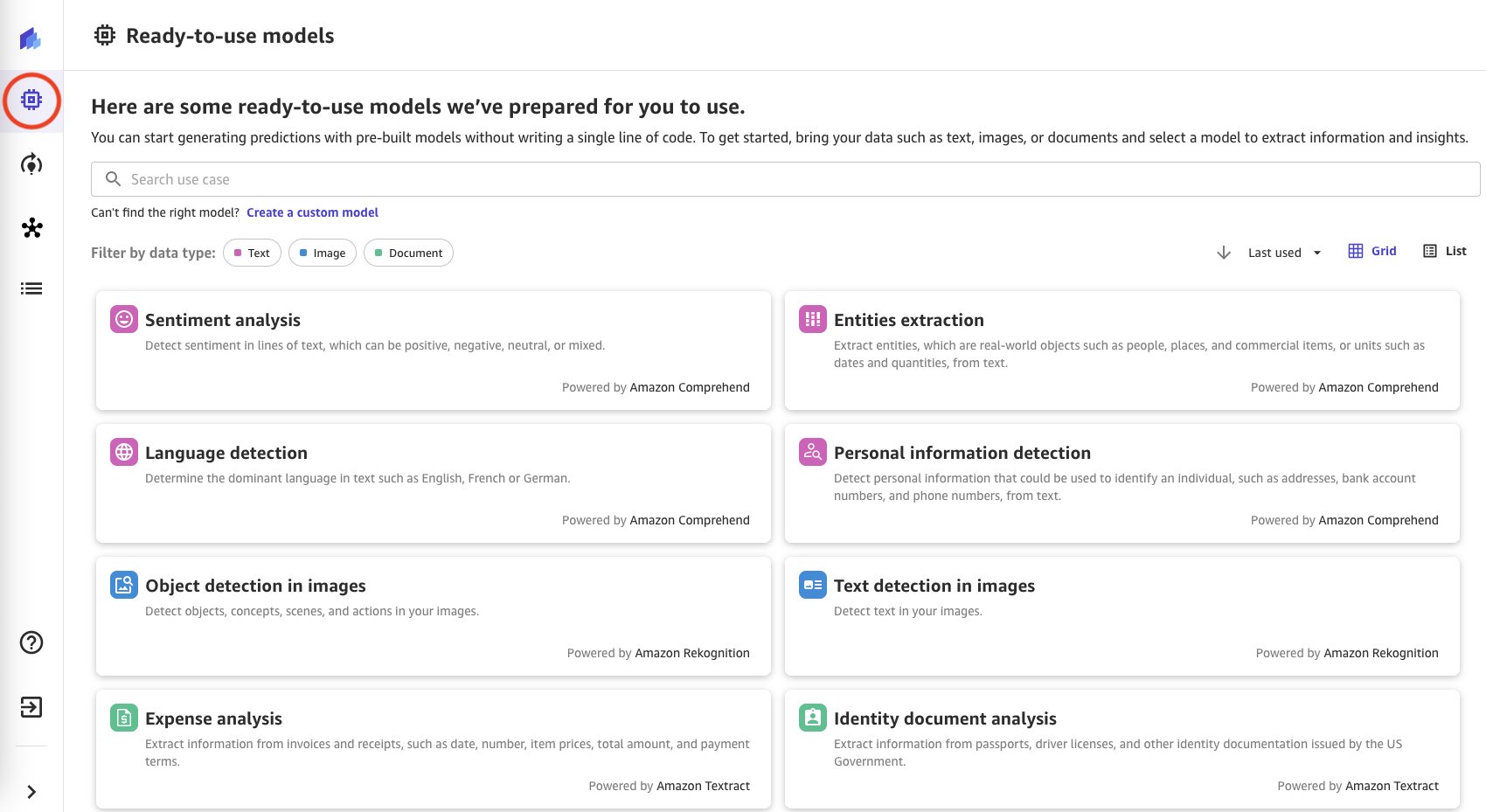
- Ingrese un nombre para el modelo.
- Seleccione su tipo de problema (para esta publicación, Análisis predictivo).
- Seleccione Crear.
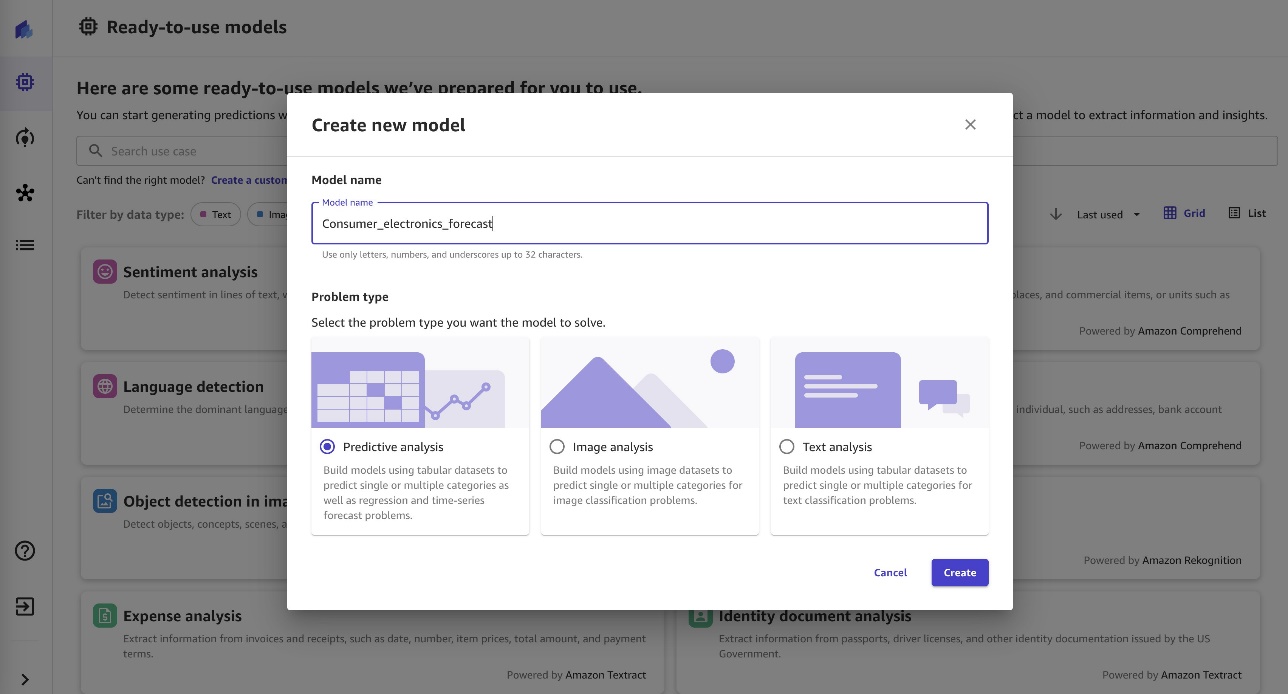
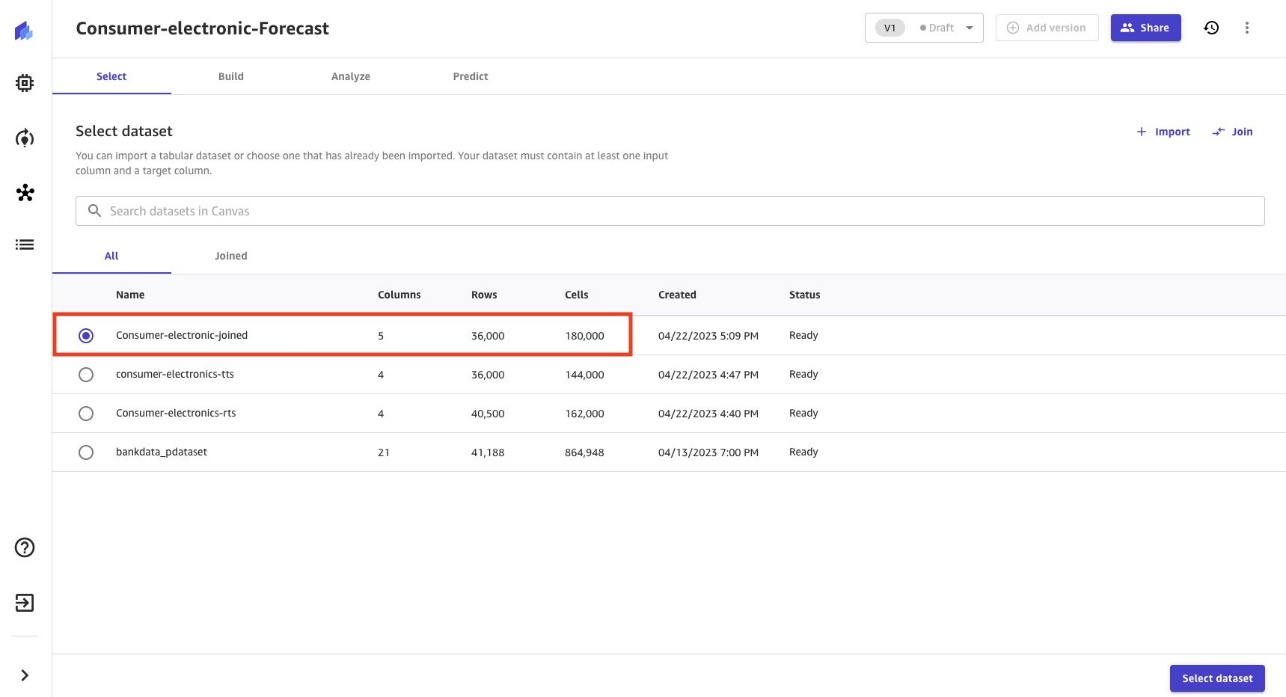
- Seleccione el conjunto de datos
consumer-electronic-joinedpara entrenar el modelo y predecir la demanda de artículos electrónicos de consumo.
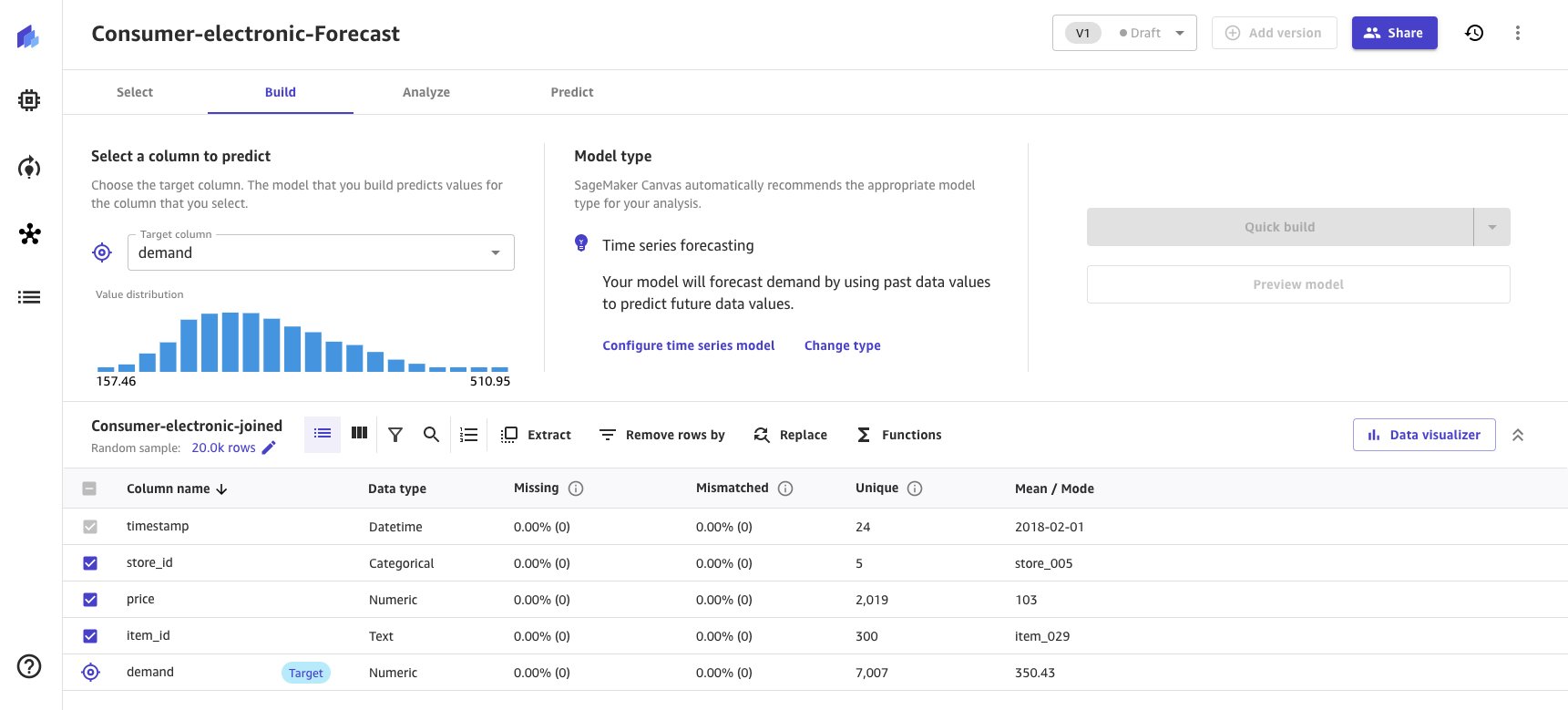
- Seleccione la demanda como la columna objetivo para pronosticar la demanda de artículos electrónicos de consumo.
En función de los datos proporcionados a Canvas, el Tipo de modelo se deriva automáticamente como Pronóstico de series temporales y proporciona una opción de Configurar modelo de series temporales.
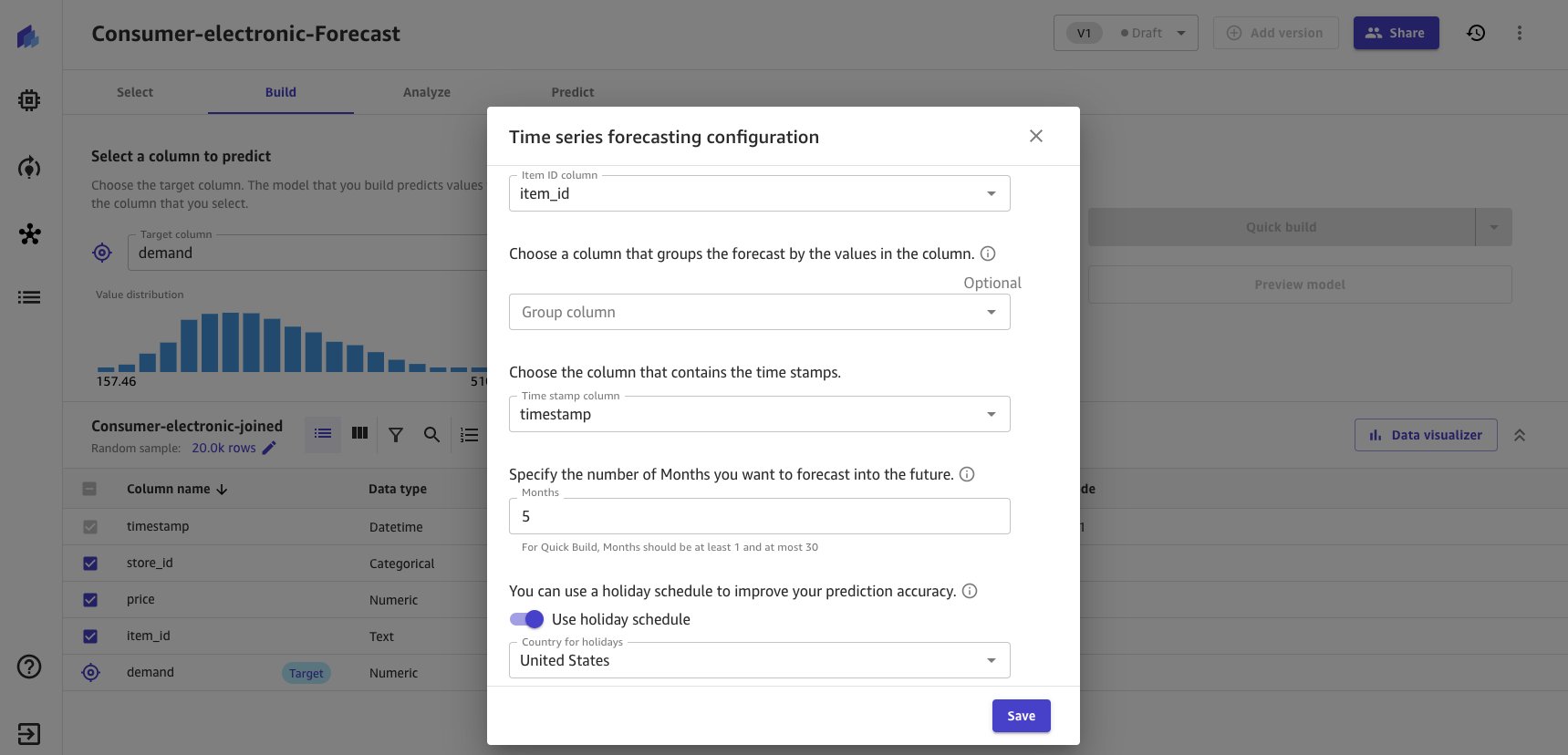
- Seleccione el enlace Configurar modelo de series temporales para proporcionar opciones de modelo de series temporales.
- Ingrese las configuraciones de pronóstico como se muestra en la siguiente captura de pantalla.
- Excluya la columna del grupo porque no se ejecuta un agrupamiento lógico para el conjunto de datos.
Para construir el modelo, Canvas ofrece dos opciones de construcción. Elija la opción según su preferencia. La construcción rápida generalmente tarda alrededor de 15-20 minutos, mientras que la estándar tarda alrededor de 4 horas.
-
- Construcción rápida: construye un modelo en una fracción del tiempo en comparación con una construcción estándar; se intercambia la precisión potencial por la velocidad
- Construcción estándar: construye el mejor modelo a partir de un proceso optimizado alimentado por AutoML; la velocidad se intercambia por la mayor precisión
- Para esta publicación, elegimos Construcción rápida con fines ilustrativos.

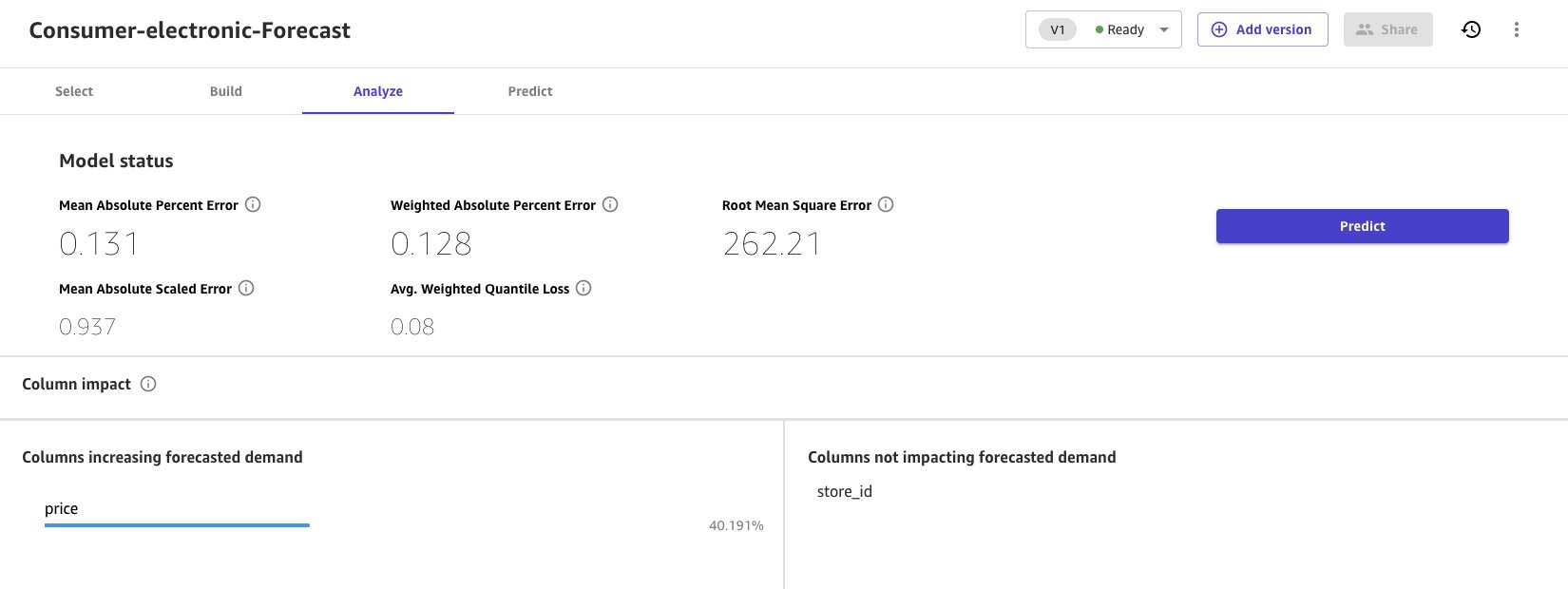
Cuando se completa la construcción rápida, las métricas de evaluación del modelo se presentan en la sección Analyze.
- Elija Predict para ejecutar una única predicción o una predicción por lotes.
Limpieza
Cierre sesión en Canvas para evitar cargos futuros.
Conclusión
Las empresas tienen datos en lagos de datos en varios formatos, incluido el formato Parquet altamente eficiente. Canvas ha lanzado más de 40 fuentes de datos, incluida Athena, desde la cual puede extraer fácilmente datos en varios formatos de lagos de datos. Para obtener más información, consulte Importar datos de más de 40 fuentes de datos para el aprendizaje automático sin código con Amazon SageMaker Canvas.
En esta publicación, tomamos archivos Parquet administrados por Lake Formation e importamos en Canvas usando Athena. El modelo de ML de Canvas pronosticó la demanda de electrónica de consumo utilizando datos históricos de demanda y precios. Gracias a una interfaz fácil de usar y visualizaciones vívidas, completamos esto sin escribir una sola línea de código. Ahora, Canvas permite a los analistas de negocios utilizar archivos Parquet de equipos de ingeniería de datos para construir modelos de ML, realizar análisis y extraer información independientemente de los equipos de ciencia de datos.
Para obtener más información sobre Canvas, consulte Predecir tipos de fallas de máquinas con aprendizaje automático sin código utilizando Canvas. Consulte Anuncio de Amazon SageMaker Canvas – Capacidades de aprendizaje automático visuales y sin código para analistas de negocios para obtener más información sobre cómo crear modelos de ML con una solución sin código.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Motivando la Autoatención
- 10 hiperparámetros confusos de XGBoost y cómo ajustarlos como un profesional en 2023.
- Cinco fuentes de datos meteorológicos gratuitas y confiables.
- Lo que aprendí al llevar la Ingeniería de Prompt al límite
- Los modelos de lenguaje grandes tienen sesgos. ¿Puede la lógica ayudar a salvarlos?
- Aprendiendo a hacer crecer modelos de aprendizaje automático
- Uniéndose a la lucha contra el sesgo en la atención médica






