Uplift Modeling – Una guía para científicos de datos sobre cómo optimizar una campaña de renovación de tarjetas de crédito
Uplift Modeling - Guía para optimizar campaña de renovación de tarjetas de crédito
Aplicando el aprendizaje causal para ajustar el público objetivo de la campaña
Como científico de datos en ciernes, mi formación académica me enseñó a dar importancia a la precisión como señal de un proyecto exitoso. Por otro lado, la industria se preocupa por ganar y ahorrar dinero a corto y largo plazo. Este artículo es una lección sobre el ROI (retorno de inversión), el Santo Grial de las acciones empresariales.
Una gran parte de las campañas promocionales se dirigen a segmentos de clientes en lugar de al individuo directamente. Ejemplos de esto son la búsqueda pagada, los anuncios de display, las redes sociales pagadas, etc. Por otro lado, las campañas de negocio a consumidor (D2C, por sus siglas en inglés) están dirigidas directamente a los clientes individuales. Estas pueden ser correo directo, correo electrónico, mensajes de texto o incluso notificaciones push. Las empresas en el sector bancario y fintech son capaces de llevar a cabo grandes campañas D2C porque todos tienen la aplicación. Pero en la actualidad, estas empresas buscan ser eficientes en sus gastos promocionales (¿cómo?).
Entendiendo el Problema
Con ese trasfondo, hablemos de una emisora de tarjetas de crédito, Flex, que ofrece el primer año gratis, es decir, sin tarifa anual. A partir del segundo año de uso, cobra una tarifa anual completa. Durante los últimos 3 años, observaron una baja tasa de retención anual, con solo un 30% de los titulares que continúan usando la tarjeta después del primer año. Flex decide experimentar con ofertas de renovación para clientes seleccionados con el objetivo de seguir creciendo su base de clientes. El problema es que esta estrategia puede ser costosa si no tenemos cuidado.
Como científicos de datos, se nos encarga preparar el grupo más pequeño de clientes objetivo para extender estas ofertas a partir de una lista de 5 millones de clientes que deben renovar.
- Conoce DeepOnto Un paquete de Python para la ingeniería de ontologías con Aprendizaje Profundo
- Google AI propone un nuevo método para reducir la carga en los LLMs Estímulo de clasificación por pares
- Simplificando las pruebas de ingeniería de instrucciones mediante el uso de esta herramienta
Una Breve Explicación del Modelado de Impacto
Durante muchos años, los científicos de datos se han dedicado a construir modelos de respuesta para predecir la probabilidad de que un cliente responda a una campaña directa. Esto puede funcionar para negocios nuevos, pero a medida que las marcas maduran, sus preguntas evolucionan.
Algunos problemas que no se resuelven con los modelos de respuesta son:
- ¿Cuánto más probable es que un cliente responda si se expone a una campaña?
- ¿Cómo podemos priorizar a los clientes que corren el riesgo de abandonar? ¿Quiénes son?
- ¿Existen clientes que podrían responder de manera negativa a los mensajes promocionales? ¿Quiénes son?
- ¿Cómo podemos reducir el número de clientes objetivo en la campaña sin afectar los ingresos incrementales?
Entra en juego el modelado de impacto. Es una técnica de aprendizaje automático que predice el impacto incremental de un tratamiento en el comportamiento de compra de una persona, en lugar de solo la probabilidad del comportamiento. De esta manera, puedes dirigirte a los clientes que tienen más probabilidades de verse influenciados por tu campaña y evitar desperdiciar recursos en aquellos que no lo harán. Esto aumenta el retorno de inversión y la satisfacción del cliente de la campaña.
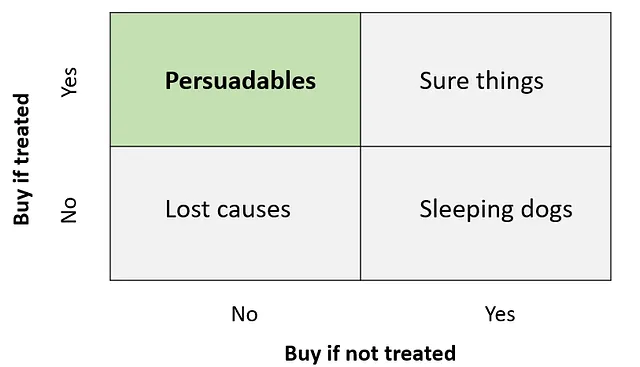
Tal vez hayas visto esta clasificación de clientes antes. Los “Seguros” tienen una fuerte afinidad por tu marca o producto y comprarían de todos modos. Los “Causas Perdidas” no tienen necesidad de tu producto. La campaña promocional es poco probable que influya en estos dos tipos de clientes. Los “Durmientes” son aquellos que comprarían si no fueran molestados por la promoción. Son los “Persuadables” quienes presentan la mayor oportunidad: solo comprarían si se les hace marketing. Ellos aumentan el ROI de la campaña.
En esta tarea, primero tenemos que identificar a los “Persuadables”. Segundo, encontrar la oferta más adecuada para cada uno de ellos.
Preparando el Conjunto de Datos de Clientes de Tarjetas de Crédito
Tenemos un conjunto de datos de 5 millones de clientes que tienen una antigüedad de 10 meses, lo que significa que les quedan 2 meses para renovar. Estos son datos simulados que puedes crear tú mismo con este código de Python.

Aquí tenemos que hacer un análisis exploratorio de datos (EDA) y he utilizado la herramienta ydata-profiling (anteriormente llamada Pandas Profiling) para generar un informe interactivo.
Tenemos 20 variables de clientes, tanto cualitativas (como edad, nivel de ingresos) como cuantitativas (transacciones, gasto en categorías). Algunas de las variables están altamente correlacionadas.
El Piloto: Un análisis más detallado de la campaña de renovación anterior
Flex ya ha llevado a cabo una campaña piloto en 50,000 clientes con un mensaje como el siguiente.
Nos complace informarle que su tarjeta de crédito es elegible para su renovación con una oferta especial. Por tiempo limitado, puede renovar su tarjeta de crédito con una tarifa anual reducida de solo $49, ahorrando hasta un 50% en comparación con la tarifa regular. Esta oferta es exclusiva para nuestros clientes leales como usted, que han estado utilizando nuestra tarjeta de crédito durante más de un año.
Hubo 3 ofertas basadas en cuánto pagan los clientes en el segundo año: 30%, 50% o 70%. A partir de la campaña, se concluyó que los segmentos tratados tenían una tasa de retención del 55%, lo cual es un aumento del 25% (55 menos 30) en comparación con el grupo de control que pagó la tarifa anual completa. Esto se llama el Efecto Promedio del Tratamiento (ATE).
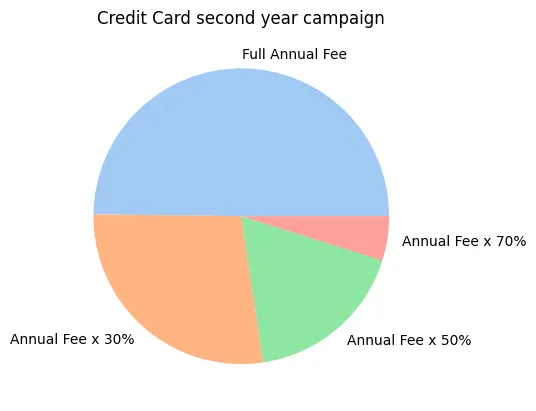
Tenemos los resultados de la campaña y estos datos se pueden utilizar para optimizar la próxima campaña. Para hacer esto, tenemos que calcular el Efecto Promedio del Tratamiento Condicional (CATE) para cada cliente, que es un nombre elegante para el efecto a nivel de cliente.
Nota: Una campaña piloto es una prueba a pequeña escala de una estrategia promocional o de marketing antes de lanzarla a gran escala. Permite a los especialistas en marketing evaluar la efectividad, viabilidad y costos de la estrategia, así como identificar y resolver cualquier problema o desafío. Una campaña piloto puede ayudar a optimizar el plan de marketing, aumentar el retorno de la inversión y reducir los riesgos de fracaso.
Propensity Score Matching: Obteniendo un grupo de control representativo
El Propensity Score Matching (PSM) tiene como objetivo emparejar clientes que tienen probabilidades similares de recibir el tratamiento basándose en sus características observadas. El PSM puede ayudar a reducir el sesgo causado por variables de confusión en estudios observacionales, donde no es posible asignar el tratamiento de forma aleatoria. Implica estimar los propensity scores para cada cliente, que son las probabilidades condicionales de ser tratado dadas las covariables, y luego emparejar clientes tratados y no tratados con puntajes similares.
Dado que tenemos 3 tratamientos diferentes en la campaña piloto, utilizaré el PSM para aproximar un grupo de control idéntico para cada grupo de tratamiento. Por ejemplo, un conjunto de clientes en el grupo de control (que pagaron la tarifa anual completa) que son similares a los clientes que recibieron el tratamiento Tarifa Anual x 30%. Y de manera similar, para los grupos Tarifa Anual x 50% y Tarifa Anual x 70%. Esto eliminaría cualquier variable de confusión y en un entorno experimental podríamos identificar el verdadero aumento para cada grupo de tratamiento.
Típicamente, los propensity scores se calculan utilizando modelos de regresión logística simples. También recomendaría paquetes como psmpy que hacen esto bien y también manejan el desequilibrio de clases por usted.
Selección de características: Factores que llevan a un aumento en el impacto
Después del propensity score matching, tenemos 3 pares de conjuntos de datos: (Control₃₀, Tratamiento₃₀) (Control₅₀, Tratamiento₅₀) (Control₇₀, Tratamiento₇₀)
He utilizado estos pares para construir 3 modelos, uno para cada grupo de tratamiento, utilizando el algoritmo X-learner en la biblioteca CausalML. Los valores SHAP se pueden utilizar para verificar qué características están relacionadas con el impacto.
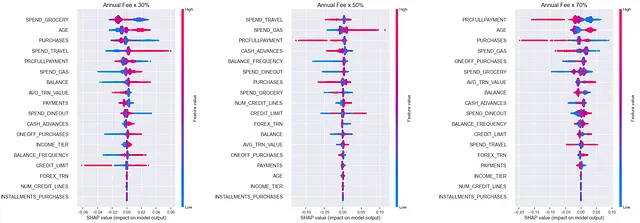
Evaluando los Modelos X-learner
Construimos 3 curvas de Qini, donde vemos el aumento acumulativo al agregar clientes al objetivo, comenzando desde el CATE más alto hasta el más bajo. Es similar a una curva ROC en el aprendizaje automático tradicional. La línea inferior es el aumento por asignación aleatoria al tratamiento/control. Aquí informamos el Área bajo la Curva de Uplift o Puntaje Qini, cuanto mayor, mejor.

Como se esperaba, el tratamiento de Tarifa Anual x 30% tiene el puntaje Qini más alto. Ahora los modelos están listos y podemos aplicarlos en nuevos datos.
Prediciendo el Uplift Fuera de Muestra – Diseñando la próxima campaña
Pasamos a los 5 millones de clientes que están por renovarse. Tenemos la opción de ofrecerles Tarifa Anual x 30%, Tarifa Anual x 50% o Tarifa Anual x 70%. O no ofrecerles nada, Tarifa Anual Completa. Con los tres X-learners, predigo el CATE de cada uno de ellos. El tratamiento con el mayor CATE será el mejor tratamiento. Si todos los tratamientos tienen un CATE similar (dentro de +-10% entre sí), entonces elegimos el tratamiento de Tarifa Anual x 70% (por supuesto, queremos mayores ingresos). Si el CATE máximo es negativo, entonces no nos dirigimos a este cliente (es un durmiente).
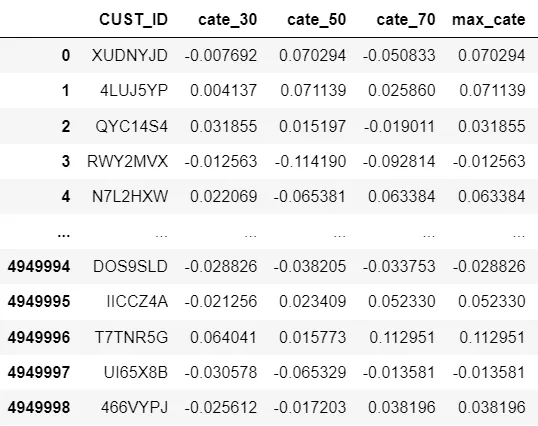
Aquí están nuestras mejores asignaciones. Aproximadamente medio millón de clientes no son recomendados para el tratamiento.
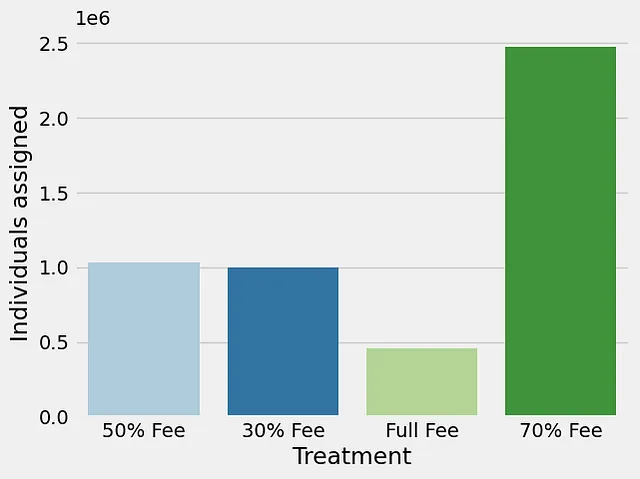
En este tipo de representación (ver abajo), dividimos a los clientes en deciles basados en el CATE. El decil 1 tiene el CATE más alto y el decil 10 el más bajo. Si damos a todos los clientes un solo tipo de tratamiento, podemos ver que los deciles más bajos caen por debajo de 0 más temprano. Por lo tanto, nos adheriremos al mejor tratamiento para nuestra próxima campaña.

La curva Qini nos dice que esperamos bastante aumento al ejecutar esta campaña. No hay un punto de corte claro o punto de inflexión en la curva para separar a los Persuadables.

Respuesta Incremental – ¿A qué clientes debemos dirigirnos?
Se espera que el aumento promedio en la próxima campaña sea de 0.052. Los deciles que tienen un aumento por encima del promedio son los clientes objetivos. Pero, para ser frugales en esta campaña, solo tomaremos el 20% superior y los llamaremos Persuadables. Los deciles con aumento negativo son los Sleeping dogs. Los demás son o Sure things (cosas seguras) o Lost causes (causas perdidas).
Es más fácil visualizar a los Persuadables en este gráfico renovado del Mejor Tratamiento. En este caso, son los 5 deciles superiores.
No podemos informar a los equipos de negocios sobre el aumento, así que convirtamos esto en el ROI incremental y en la escala de ingresos. Para el decil d, el ROI incremental es
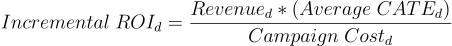
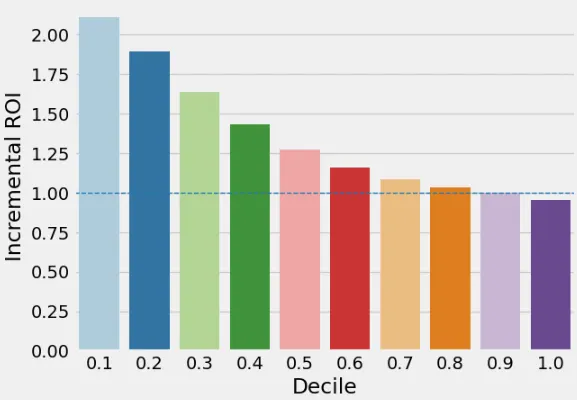
Los ingresos son el monto total de las tarifas de renovación del decil. El costo de la campaña es la parte de las tarifas de renovación que Flex asume por sí mismo. Vemos que solo es rentable ofrecer descuentos a los primeros 7 deciles o al 70% superior de los clientes.
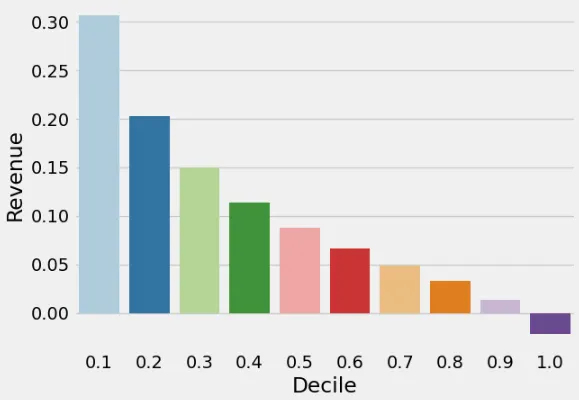
El 20% superior, o Persuadibles, se espera que aporte el 80% de los ingresos totales de la renovación de estos 5 millones de clientes. Esto se observa a menudo en los negocios y se le llama Principio de Pareto. También se pueden construir gráficos de barras para el CLV (Valor de Vida del Cliente) para aprender el ROI a largo plazo de la campaña.
Entonces, para responder a la pregunta: ¿a quién debemos dirigirnos? Son los Persuadibles, que son aproximadamente 1 millón de clientes. ¿Cómo personalizamos su oferta? Utilizamos el mejor tratamiento con el mayor Efecto Medio del Tratamiento Condicional.
Conclusión
De esta manera, el Modelado de Incremento identifica a los clientes que aportarán el ROI incremental más alto a la campaña y los dirige en consecuencia. Al hacerlo, el modelado de incremento optimiza el retorno de inversión de la campaña y reduce los gastos innecesarios.
Espero que hayas encontrado útil e informativa esta publicación, y que pruebes el modelado de incremento en tu próxima campaña promocional o de marketing.
El modelado de incremento se aplica típicamente a campañas D2C (Directo al Consumidor) como correo directo, correo electrónico, SMS o notificaciones de aplicaciones. Si estás buscando optimizar los medios pagados, dirígete a mi serie sobre Modelado de Mezcla de Marketing.
¡Gracias por leer! 😄
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La IA generativa imagina nuevas estructuras de proteínas
- MosaicML ayuda a los usuarios de IA a aumentar la precisión, reducir costos y ahorrar tiempo
- ¡Gol! El equipo de NVIDIA se lleva el trofeo en Sistemas de Recomendación
- Los fabricantes de chips apilan ‘chiplets’ como bloques de Lego para impulsar la IA
- El mundo natural potencia el futuro de la visión por computadora
- Dentro del acalorado centro del pesimismo de la IA
- Poniendo a prueba a un Analista de Datos impulsado por IA






