Revelando patrones ocultos Una introducción al agrupamiento jerárquico
Revelando patrones ocultos Una introducción al agrupamiento jerárquico
Cuando te familiarices con el paradigma de aprendizaje no supervisado, aprenderás sobre los algoritmos de clustering.
El objetivo del clustering es comprender los patrones en el conjunto de datos no etiquetado dado. O puede ser encontrar grupos en el conjunto de datos y etiquetarlos para poder realizar aprendizaje supervisado en el conjunto de datos ahora etiquetado. Este artículo cubrirá los conceptos básicos del clustering jerárquico.
- La Inteligencia Artificial está controlando la lucha contra el robo de paquetes de UPS
- Dispositivo óptico portátil muestra promesa para detectar hemorragias postparto
- Vínculo de datos de dispositivos portátiles vincula la reducción del sueño y la actividad durante el embarazo con el riesgo de parto prematuro
¿Qué es el Clustering Jerárquico?
El algoritmo de clustering jerárquico tiene como objetivo encontrar similitudes entre instancias, cuantificadas por una métrica de distancia, para agruparlas en segmentos llamados clusters.
El objetivo del algoritmo es encontrar clusters de manera que los puntos de datos en un cluster sean más similares entre sí que a los puntos de datos en otros clusters.
Hay dos algoritmos comunes de clustering jerárquico, cada uno con su propio enfoque:
- Clustering Aglomerativo
- Clustering Divisivo
Clustering Aglomerativo
Supongamos que hay n puntos de datos distintos en el conjunto de datos. El clustering aglomerativo funciona de la siguiente manera:
- Comienza con n clusters; cada punto de datos es un cluster en sí mismo.
- Agrupa los puntos de datos en función de su similitud. Significa que los clusters similares se fusionan según la distancia.
- Repite el paso 2 hasta que solo quede un cluster.
Clustering Divisivo
Como sugiere el nombre, el clustering divisivo intenta realizar la inversa del clustering aglomerativo:
- Todos los n puntos de datos están en un solo cluster.
- Divide este solo cluster grande en grupos más pequeños. Ten en cuenta que la agrupación de puntos de datos en el clustering aglomerativo se basa en la similitud. Pero dividirlos en diferentes clusters se basa en la disimilaridad; los puntos de datos en diferentes clusters son disimilares entre sí.
- Repite este paso hasta que cada punto de datos sea un cluster en sí mismo.
Métricas de Distancia
Como se mencionó, la similitud entre los puntos de datos se cuantifica utilizando la distancia. Las métricas de distancia comúnmente utilizadas incluyen la distancia euclidiana y la distancia de Manhattan.
Para cualquier par de puntos de datos en el espacio de características de n dimensiones, la distancia euclidiana entre ellos está dada por:
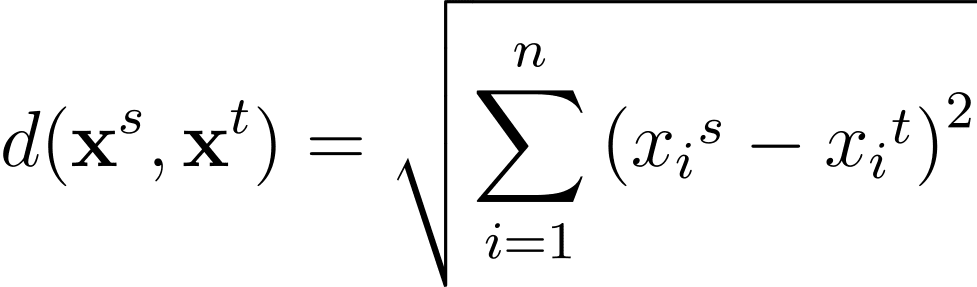
Otra métrica de distancia comúnmente utilizada es la distancia de Manhattan, que se calcula así:
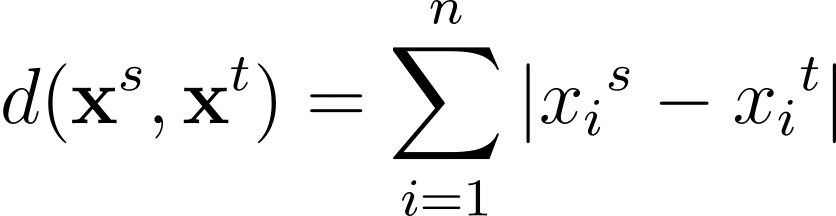
La distancia de Minkowski es una generalización, para un p general mayor o igual a 1, de estas métricas de distancia en un espacio de n dimensiones:
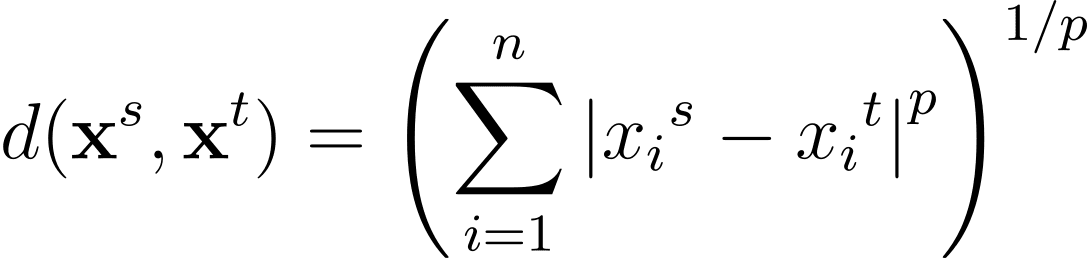
Distancia entre Clusters: Entendiendo los Criterios de Enlace
Usando las métricas de distancia, podemos calcular la distancia entre cualquier par de puntos de datos en el conjunto de datos. Pero también necesitas definir una distancia para determinar “cómo” agrupar juntos los clusters en cada paso.
Recuerda que en cada paso del clustering aglomerativo, elegimos los dos grupos más cercanos para fusionar. Esto se captura mediante el criterio de enlace. Los criterios de enlace comúnmente utilizados incluyen:
- Enlace Simple
- Enlace Completo
- Enlace Promedio
- Enlace de Ward
Enlace Simple
En el enlace simple o clustering de enlace simple, la distancia entre dos grupos/clusters se toma como la distancia más pequeña entre todos los pares de puntos de datos en los dos clusters. 
Agrupamiento de enlace completo
En el agrupamiento de enlace completo, la distancia entre dos grupos se elige como la distancia más grande entre todos los pares de puntos en los dos grupos.
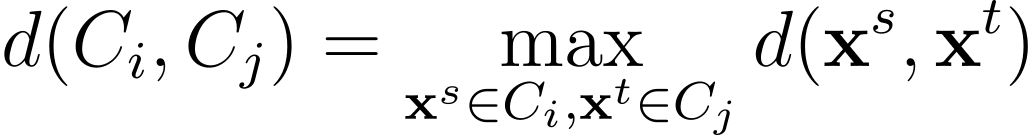
Agrupamiento de enlace promedio
A veces se utiliza el agrupamiento de enlace promedio, que utiliza el promedio de las distancias entre todos los pares de puntos de datos en los dos grupos.
Agrupamiento de enlace de Ward
El agrupamiento de enlace de Ward tiene como objetivo minimizar la varianza dentro de los grupos fusionados: fusionar grupos debe minimizar el aumento general de la varianza después de la fusión. Esto conduce a grupos más compactos y bien separados.
La distancia entre dos grupos se calcula considerando el aumento en la suma total de desviaciones al cuadrado (varianza) respecto a la media del grupo fusionado. La idea es medir cuánto aumenta la varianza del grupo fusionado en comparación con la varianza de los grupos individuales antes de la fusión.
Cuando codificamos el agrupamiento jerárquico en Python, también utilizamos el enlace de Ward.
¿Qué es un dendrograma?
Podemos visualizar el resultado del agrupamiento como un dendrograma. Es una estructura de árbol jerárquico que nos ayuda a comprender cómo se agrupan o fusionan los puntos de datos y, posteriormente, los grupos a medida que avanza el algoritmo.
En la estructura de árbol jerárquico, las hojas representan las instancias o los puntos de datos en el conjunto de datos. Las distancias correspondientes en las que ocurre la fusión o agrupación se pueden inferir del eje y.
Debido a que el tipo de enlace determina cómo se agrupan los puntos de datos, los diferentes criterios de enlace generan dendrogramas diferentes.
Según la distancia, podemos usar el dendrograma, cortarlo o dividirlo en un punto específico para obtener el número de grupos requerido.
A diferencia de algunos algoritmos de agrupamiento como el agrupamiento k-means, el agrupamiento jerárquico no requiere que especifiques el número de grupos de antemano. Sin embargo, el agrupamiento aglomerativo puede ser computacionalmente muy costoso cuando se trabaja con conjuntos de datos grandes.
Agrupamiento jerárquico en Python con SciPy
A continuación, realizaremos el agrupamiento jerárquico en el conjunto de datos de vinos incorporado wine dataset, paso a paso. Para hacerlo, aprovecharemos el paquete de agrupamiento clustering package (paquete de agrupamiento) de scipy.cluster de SciPy.
Paso 1: importar las bibliotecas necesarias
Primero, importemos las bibliotecas y los módulos necesarios de las bibliotecas scikit-learn y SciPy:
# importsimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_winefrom sklearn.preprocessing import MinMaxScalerfrom scipy.cluster.hierarchy import dendrogram, linkage
Paso 2: cargar y preprocesar el conjunto de datos
A continuación, cargamos el conjunto de datos de vinos en un dataframe de pandas. Es un conjunto de datos sencillo que forma parte del módulo datasets de scikit-learn y es útil para explorar el agrupamiento jerárquico.
# Load the datasetdata = load_wine()X = data.data# Convert to DataFramewine_df = pd.DataFrame(X, columns=data.feature_names)
Veamos las primeras filas del dataframe:
wine_df.head()
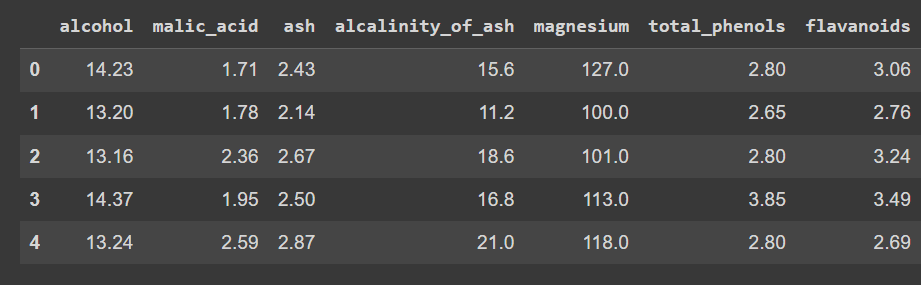 Salida truncada de wine_df.head()
Salida truncada de wine_df.head()
Observa que hemos cargado solo las características, y no la etiqueta de salida, para poder realizar la agrupación y descubrir grupos en el conjunto de datos.
Vamos a verificar la forma del dataframe:
print(wine_df.shape)
Hay 178 registros y 14 características:
Salida >>> (178, 14)
Como el conjunto de datos contiene valores numéricos que están distribuidos en diferentes rangos, vamos a preprocesar el conjunto de datos. Usaremos MinMaxScaler para transformar cada una de las características y que tomen valores en el rango [0, 1].
# Escalar las características usando MinMaxScalerscaler = MinMaxScaler()X_scaled = scaler.fit_transform(X)
Paso 3 – Realizar la Agrupación Jerárquica y Graficar el Dendrograma
Vamos a calcular la matriz de enlace, realizar la agrupación y graficar el dendrograma. Podemos usar linkage del módulo hierarchy para calcular la matriz de enlace basada en el enlace de Ward (establecer method en ‘ward’).
Como se mencionó, el enlace de Ward minimiza la varianza dentro de cada grupo. Luego, graficamos el dendrograma para visualizar el proceso de agrupación jerárquica.
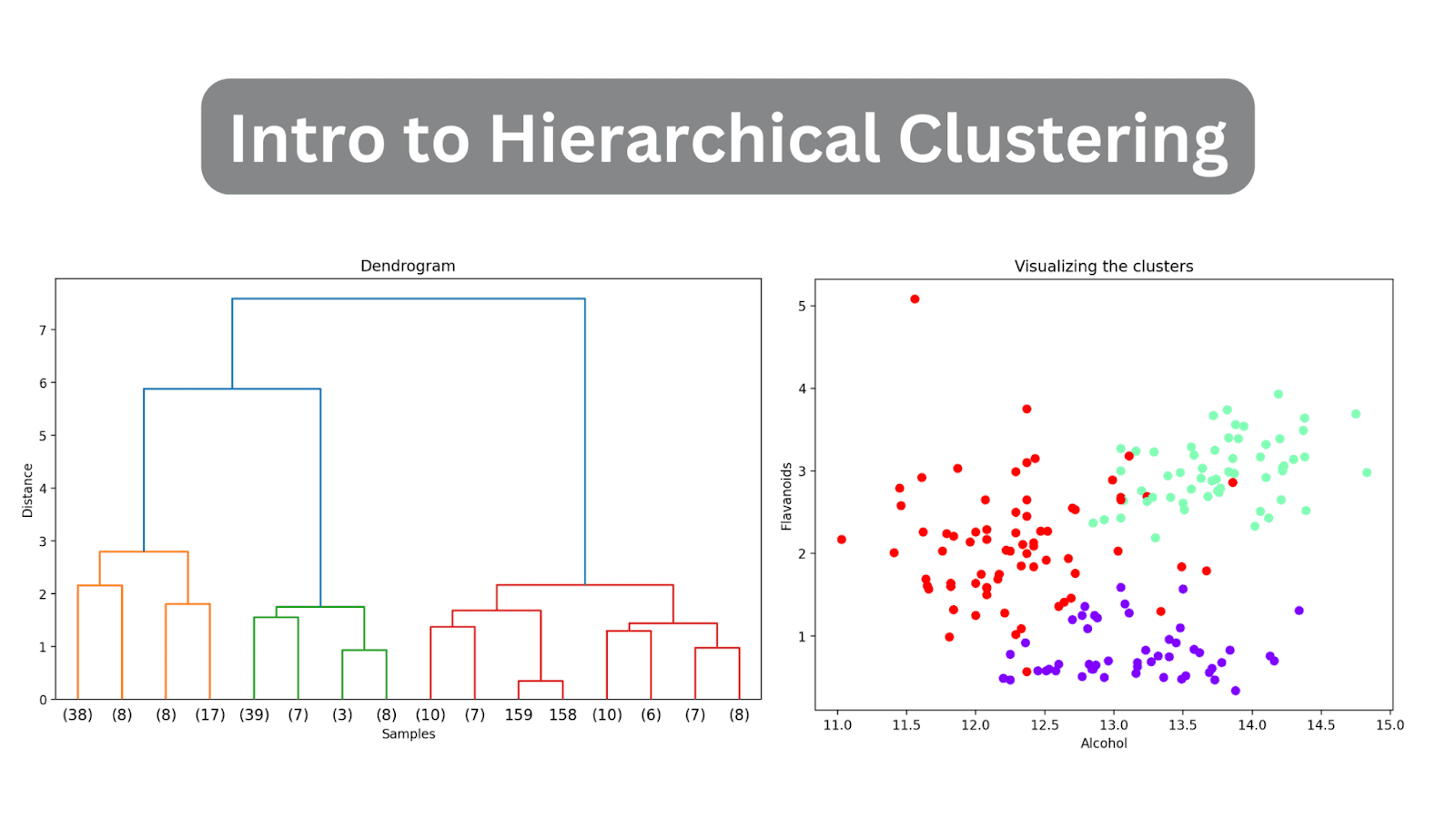
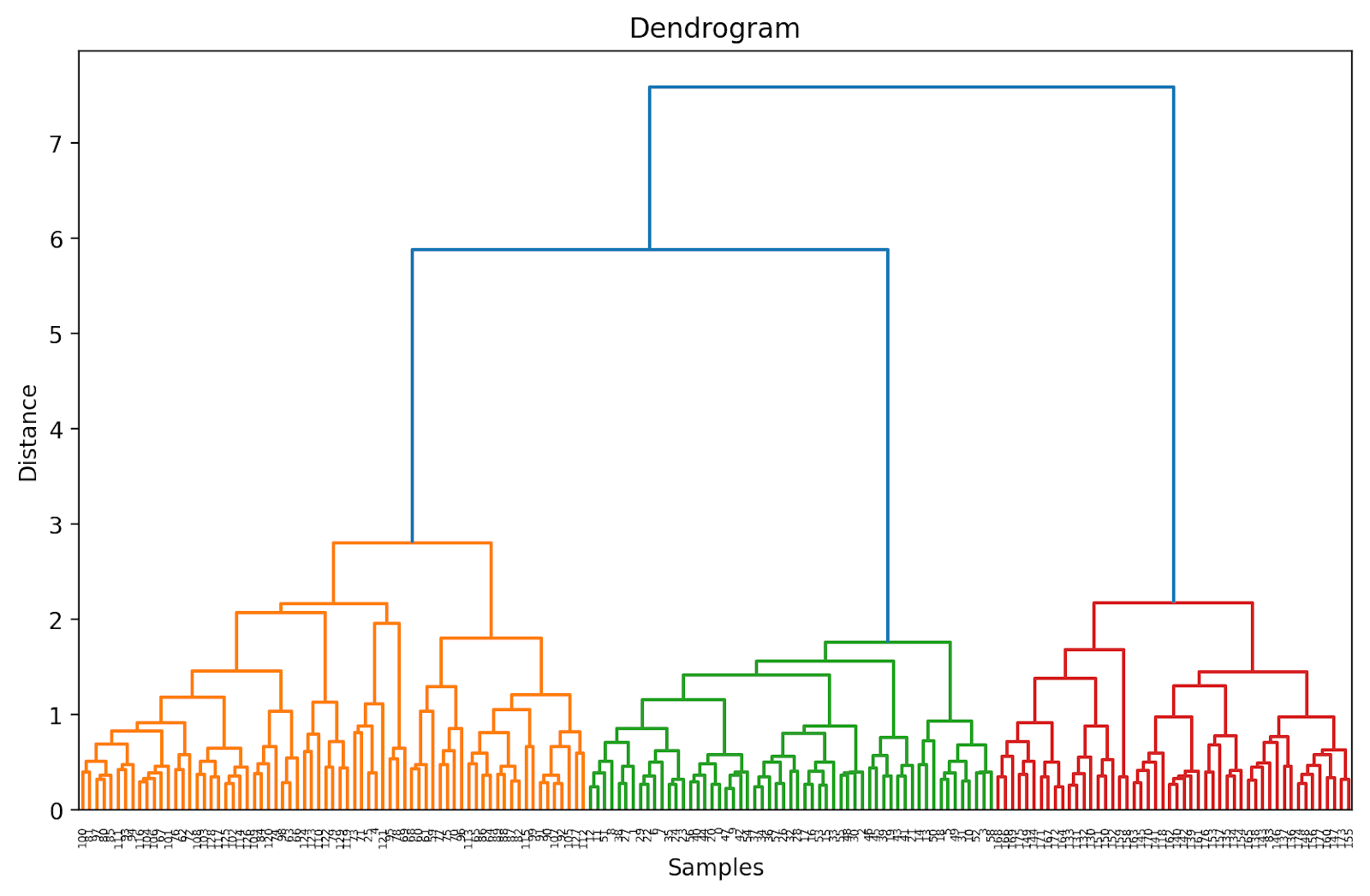
# Calcular la matriz de enlacedend = linkage(X_scaled, method='ward')# Graficar el dendrogramaplt.figure(figsize=(10, 6),dpi=200)dendrogram(dend, orientation='top', distance_sort='descending', show_leaf_counts=True)plt.title('Dendrograma')plt.xlabel('Muestras')plt.ylabel('Distancia')plt.show()
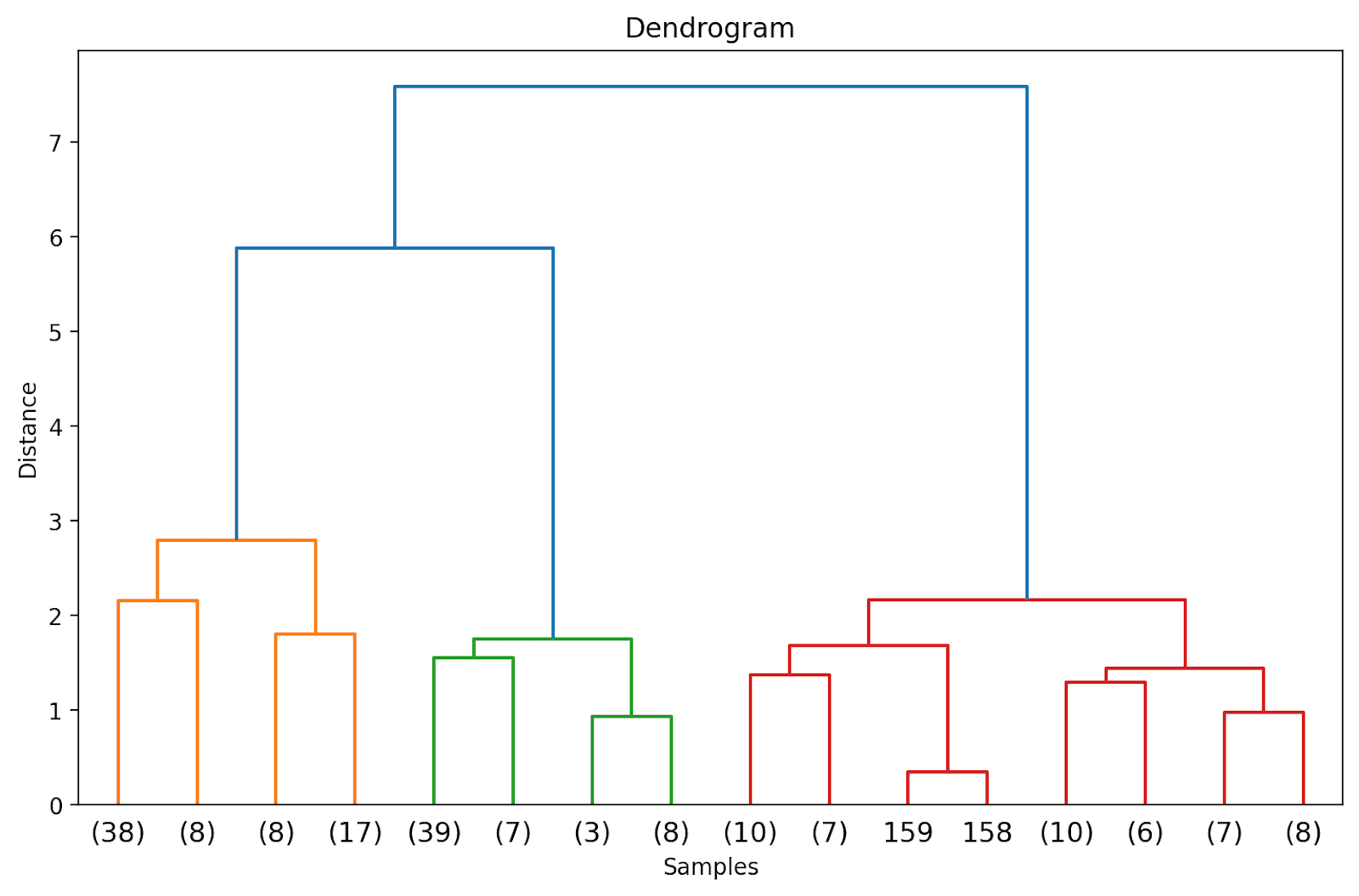
Dado que aún no hemos truncado el dendrograma, podemos visualizar cómo se agrupan los 178 puntos de datos en un solo grupo. Aunque esto parece difícil de interpretar, aún podemos ver que hay tres grupos diferentes.
Truncar el Dendrograma para una Visualización más Sencilla
En la práctica, en lugar de utilizar todo el dendrograma, podemos visualizar una versión truncada que sea más fácil de interpretar y comprender.
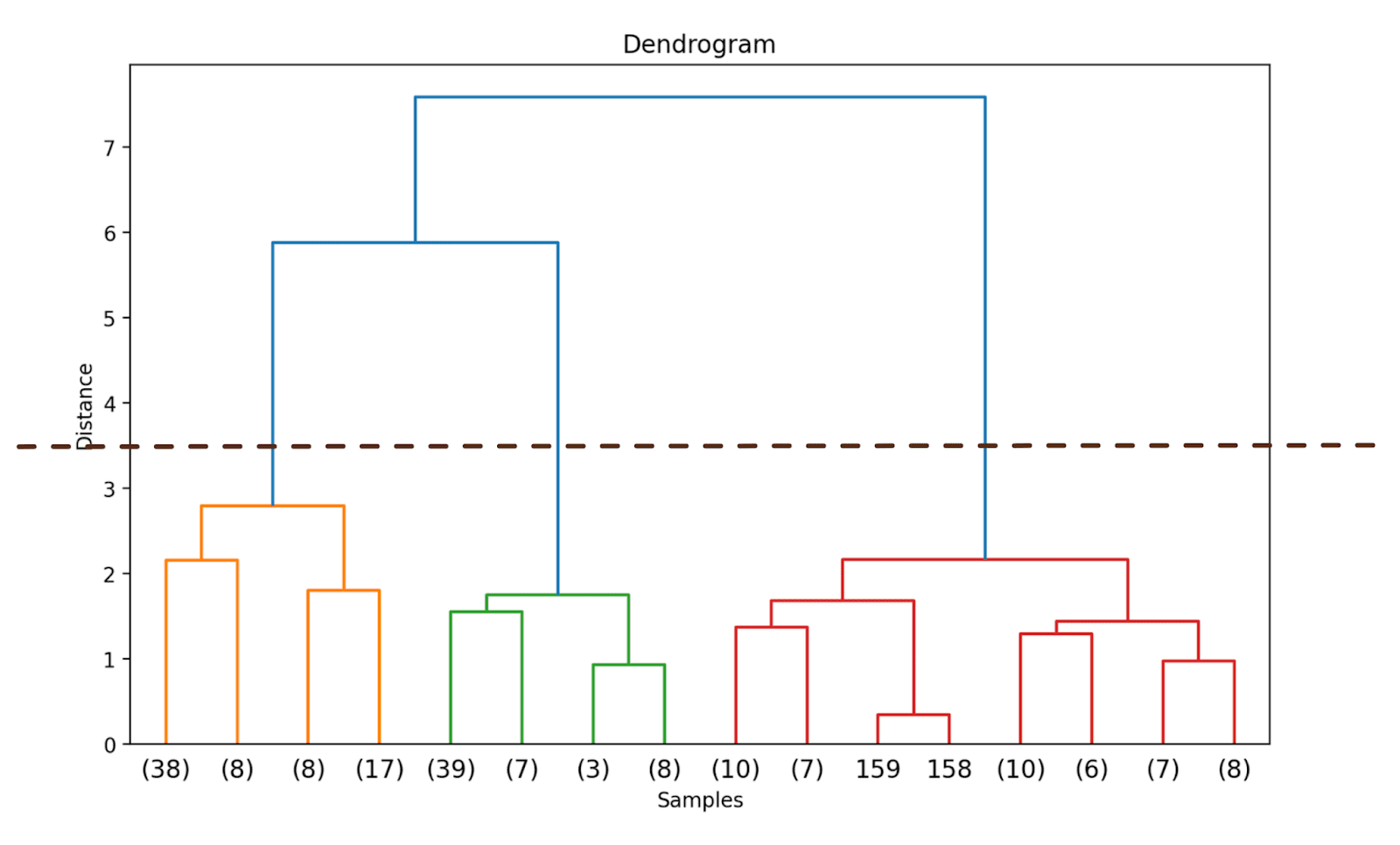
Para truncar el dendrograma, podemos establecer truncate_mode en ‘level’ y p = 3.
# Calcular la matriz de enlacedend = linkage(X_scaled, method='ward')# Graficar el dendrogramaplt.figure(figsize=(10, 6),dpi=200)dendrogram(dend, orientation='top', distance_sort='descending', truncate_mode='level', p=3, show_leaf_counts=True)plt.title('Dendrograma')plt.xlabel('Muestras')plt.ylabel('Distancia')plt.show()
Al hacerlo, truncaremos el dendrograma para incluir solo aquellos grupos que estén dentro de 3 niveles desde la unión final.
En el dendrograma anterior, puedes ver que algunos puntos de datos como 158 y 159 se representan individualmente. Mientras que otros se mencionan entre paréntesis; estos no son puntos de datos individuales, sino el número de puntos de datos en un grupo. (k) denota un grupo con k muestras.
Paso 4 – Identificar el Número Óptimo de Grupos
El dendrograma nos ayuda a elegir el número óptimo de grupos.
Podemos observar dónde aumenta drásticamente la distancia a lo largo del eje y, elegir truncar el dendrograma en ese punto y utilizar esa distancia como umbral para formar los grupos.
Para este ejemplo, el número óptimo de grupos es 3.
Paso 5 – Formar los grupos
Una vez que hayamos decidido el número óptimo de grupos, podemos utilizar la distancia correspondiente a lo largo del eje y, una distancia umbral. Esto asegura que por encima de la distancia umbral, los grupos ya no se fusionen. Elegimos una threshold_distance de 3.5 (como se infiere del dendrograma).
Luego utilizamos fcluster con criterion establecido en ‘distance’ para obtener la asignación de grupos para todos los puntos de datos:
from scipy.cluster.hierarchy import fcluster# Elige una distancia umbral basada en el dendrogramathreshold_distance = 3.5 # Cortar el dendrograma para obtener etiquetas de grupocluster_labels = fcluster(linked, threshold_distance, criterion='distance')# Asignar etiquetas de grupo al DataFrame wine_df['cluster'] = cluster_labels
Ahora deberías poder ver las etiquetas de grupo (una de {1, 2, 3}) para todos los puntos de datos:
print(wine_df['cluster'])
Resultado >>>0 21 22 23 24 3 ..173 1174 1175 1176 1177 1Name: cluster, Length: 178, dtype: int32
Paso 6 – Visualizar los Grupos
Ahora que cada punto de datos ha sido asignado a un grupo, puedes visualizar un subconjunto de características y sus asignaciones de grupos. Aquí está el gráfico de dispersión de dos de esas características junto con su asignación de grupos:
plt.figure(figsize=(8, 6))scatter = plt.scatter(wine_df['alcohol'], wine_df['flavanoids'], c=wine_df['cluster'], cmap='rainbow')plt.xlabel('Alcohol')plt.ylabel('Flavonoids')plt.title('Visualización de los grupos')# Agregar leyendaleyenda_etiquetas = [f'Grupo {i + 1}' for i in range(n_clusters)]plt.legend(handles=scatter.legend_elements()[0], labels=leyenda_etiquetas)plt.show() 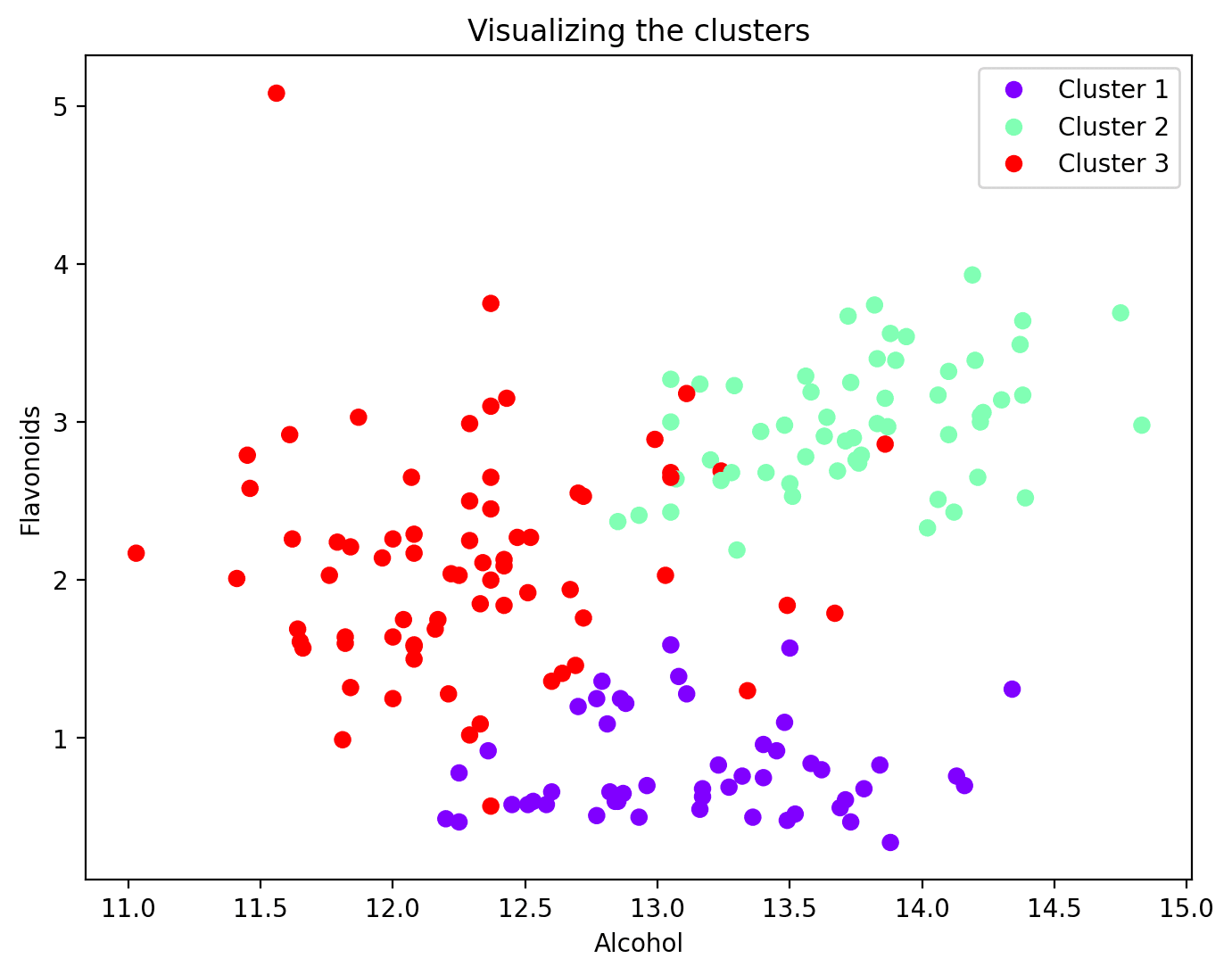
Conclusión
¡Y eso es todo! En este tutorial, utilizamos SciPy para realizar clustering jerárquico solo para cubrir los pasos involucrados en mayor detalle. Alternativamente, también puedes usar la clase AgglomerativeClustering del módulo de clustering de scikit-learn. ¡Feliz programación de clustering!
Referencias
[1] Introducción al Aprendizaje Automático
[2] Una Introducción al Aprendizaje Estadístico (ISLR) Bala Priya C es una desarrolladora y escritora técnica de India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente está trabajando en aprender y compartir sus conocimientos con la comunidad de desarrolladores mediante la creación de tutoriales, guías prácticas, opiniones y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Procyon Photonics La startup dirigida por estudiantes de secundaria que podría revolucionar la informática
- ChatGPT ahora puede responder con palabras habladas
- Se analiza el sonido de la tos para identificar la gravedad de los pacientes de COVID-19
- Fortaleciendo la industria de semiconductores de EE. UU.
- La Raspberry Pi rastrea drones invisibles utilizando sonido
- Científicos simulan la guerra de las hormigas utilizando el juego de ordenador Age of Empires
- AI diseña un nuevo robot desde cero en segundos




