Desentrañando el patrón de diseño de redes neuronales informadas por la física Parte 06.
Unraveling the design pattern of physics-informed neural networks Part 06.
Traer causalidad al entrenamiento de PINN
Bienvenidos al sexto blog de esta serie, donde continuaremos nuestro emocionante viaje explorando los patrones de diseño de las redes neuronales con información física (PINN) 🙌
En este episodio, hablaremos de cómo traer causalidad al entrenamiento de las redes neuronales con información física. Según el artículo que veremos hoy: ¡respetar la causalidad es todo lo que se necesita!
Como siempre, comenzaremos hablando de los asuntos actuales en cuestión, luego pasaremos a los remedios sugeridos, el procedimiento de evaluación y las ventajas y desventajas del método propuesto. Finalmente, concluiremos el blog explorando las posibles oportunidades que se presentan.
A medida que esta serie continúa expandiéndose, la colección de patrones de diseño de PINN se enriquece aún más 🙌 Aquí hay un adelanto de lo que les espera:
- Búsqueda de similitud, Parte 1 kNN e Índice de Archivo Invertido
- Explorando la afinación de instrucciones en modelos de lenguaje conoce Tülu, una suite de modelos de lenguaje grandes (LLMs) afinados.
- Aprendizaje por Refuerzo Profundo mejora algoritmos de ordenamiento
Patrón de diseño de PINN 01: Optimización de la distribución del punto residual
Patrón de diseño de PINN 02: Expansión dinámica del intervalo de solución
Patrón de diseño de PINN 03: Entrenamiento de PINN con aumento de gradiente
Patrón de diseño de PINN 04: Aprendizaje mejorado por gradiente en PINN
Patrón de diseño de PINN 05: Ajuste automático de los hiperparámetros
¡Vamos a sumergirnos!
1. Artículo en resumen 🔍
- Título : Respetar la causalidad es todo lo que se necesita para entrenar redes neuronales con información física
- Autores : S. Wang, S. Sankaran, P. Perdikaris
- Instituciones : Universidad de Pensilvania
- Enlace : arXiv , GitHub
2. Patrón de diseño 🎨
2.1 Problema 🎯
Las redes neuronales con información física (PINN) son un gran avance en la combinación de datos observacionales y leyes físicas en varios campos. En la práctica, sin embargo, a menudo se observa que no pueden abordar problemas altamente no lineales, dinámicas a múltiples escalas o caóticas, y tienden a converger hacia soluciones erróneas.
¿Por qué sucede esto?
Bueno, el problema fundamental radica en la violación de la causalidad en las formulaciones de PINN, como lo revela el artículo actual.
La causalidad, en el sentido físico, implica que el estado en un punto de tiempo futuro depende del estado en los puntos de tiempo presentes o pasados. En el entrenamiento de PINN, sin embargo, este principio puede no ser verdadero; estas redes pueden estar implícitamente sesgadas hacia la aproximación de las soluciones de las EDP en los estados futuros antes de resolver las condiciones iniciales, esencialmente “saltando hacia adelante” en el tiempo y violando así la causalidad.
Por el contrario, los métodos numéricos tradicionales preservan inherentemente la causalidad a través de una estrategia de marcha en el tiempo. Por ejemplo, al discretizar las EDP en el tiempo, estos métodos aseguran que se resuelva la solución en el tiempo t antes de aproximar la solución en el tiempo t + ∆ t . Por lo tanto, cada estado futuro se construye secuencialmente sobre los estados pasados resueltos, preservando así el principio de causalidad.
Esta comprensión del problema nos lleva a una pregunta intrigante: ¿cómo rectificamos esta violación de la causalidad en las PINN, alineándolas con las leyes físicas fundamentales?

2.2 Solución 💡
La idea clave aquí es reformular la función de pérdida de PINN.
Específicamente, podemos introducir un esquema de ponderación dinámico para tener en cuenta las diferentes contribuciones de la pérdida residual de la EDP evaluada en diferentes ubicaciones temporales. Vamos a desglosarlo usando ilustraciones.
Para simplificar, supongamos que los puntos de colocación se muestrean uniformemente en el dominio espacio-temporal de nuestra simulación, como se ilustra en la figura a continuación:
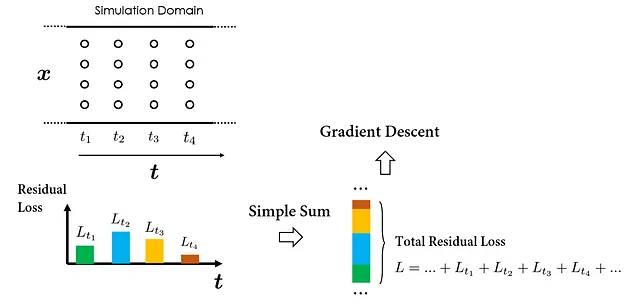
Para proceder con un paso de descenso de gradiente, primero debemos calcular la pérdida residual acumulativa de la EDP en todos los puntos de colocación. Una forma específica de hacerlo es calculando primero las pérdidas relacionadas con los puntos de colocación muestreados en instancias de tiempo individuales, y luego realizando una “simple suma” para obtener la pérdida total. El siguiente paso de descenso del gradiente puede entonces llevarse a cabo en función de la pérdida total calculada para optimizar los pesos de la PINN.
Por supuesto, el orden exacto de la suma sobre los puntos de colocación no influye en el cálculo de la pérdida total; todos los métodos producen el mismo resultado. Sin embargo, la decisión de agrupar los cálculos de pérdida por orden temporal es intencional, diseñada para enfatizar el elemento de ‘temporalidad’. Este concepto es crucial para entender la estrategia de entrenamiento causal propuesta.
En este proceso, las pérdidas residuales de la EDP evaluadas en diferentes ubicaciones temporales se tratan por igual, lo que significa que todas las pérdidas residuales temporales se minimizan simultáneamente.
Sin embargo, este enfoque corre el riesgo de que la PINN viole la causalidad temporal, ya que no impone una regularización cronológica para minimizar la pérdida residual temporal en intervalos de tiempo sucesivos.
Entonces, ¿cómo podemos hacer que la PINN se adhiera a la precedencia temporal durante el entrenamiento?
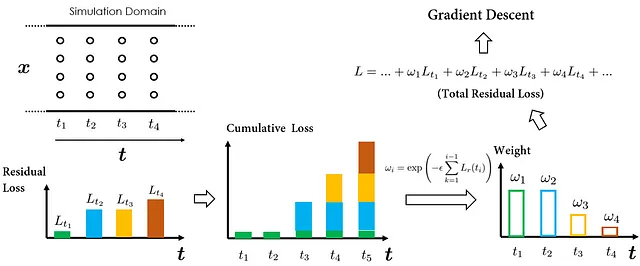
El secreto está en ponderar selectivamente las pérdidas residuales temporales individuales. Por ejemplo, supongamos que en la iteración actual, queremos que la PINN se centre en aproximar las soluciones en el momento t₁. Entonces, podríamos simplemente poner un peso mayor en Lᵣ(t₁), que es la pérdida residual temporal en t₁. De esta manera, Lᵣ(t₁) se convertirá en un componente dominante en la pérdida total final, y como resultado, el algoritmo de optimización priorizará la minimización de Lᵣ(t₁), lo que se alinea con nuestro objetivo de aproximar soluciones en el momento t₁ primero.

En la iteración siguiente, cambiamos nuestro enfoque a las soluciones en el momento t₂. Al aumentar el peso en Lᵣ(t₂), ahora se convierte en el factor principal en el cálculo de la pérdida total. El algoritmo de optimización se dirige así hacia la minimización de Lᵣ(t₂), mejorando la precisión de la predicción de las soluciones en t₂.

Como se puede ver en nuestro recorrido anterior, variar los pesos asignados a las pérdidas residuales temporales en diferentes momentos nos permite dirigir la PINN para aproximar soluciones en nuestros momentos elegidos.
Entonces, ¿cómo ayuda esto a incorporar una estructura causal en el entrenamiento de la PINN? Resulta que podemos diseñar un algoritmo de entrenamiento causal (como se propone en el artículo), de tal manera que el peso para la pérdida residual temporal en el tiempo t, es decir, Lᵣ(t), solo es significativo cuando las pérdidas antes de t (Lᵣ(t-1), Lᵣ(t-2), etc.) son suficientemente pequeñas. Esto significa efectivamente que la red neuronal comienza a minimizar Lᵣ(t) sólo cuando ha logrado una precisión de aproximación satisfactoria para los pasos anteriores.
Para determinar el peso, el artículo propone una fórmula simple: el peso ωᵢ se establece inversamente exponencialmente proporcional a la magnitud de la pérdida residual temporal acumulativa de todas las instancias de tiempo anteriores. Esto asegura que el peso ωᵢ solo estará activo (es decir, con un valor lo suficientemente grande) cuando la pérdida acumulativa de todas las instancias de tiempo anteriores sea pequeña, es decir, PINN ya puede aproximar con precisión soluciones en los pasos de tiempo anteriores. Así es como se refleja la causalidad temporal en el entrenamiento de PINN.
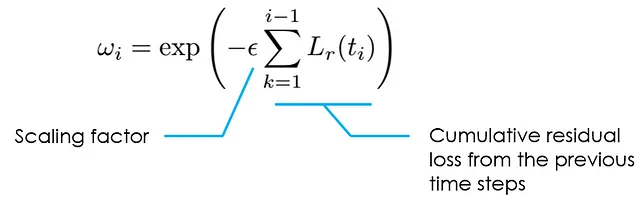
Con todos los componentes explicados, podemos armar el algoritmo completo de entrenamiento causal de la siguiente manera:
Antes de concluir esta sección, hay dos observaciones que vale la pena mencionar:
- El artículo sugiere utilizar la magnitud de ωᵢ como criterio de parada para el entrenamiento de PINN. Específicamente, cuando todos los ωᵢ son mayores que un umbral predefinido δ, el entrenamiento puede considerarse completo. El valor recomendado para δ es 0.99.
- Seleccionar un valor adecuado para ε es importante. Aunque este valor se puede ajustar mediante la sintonización de hiperparámetros convencionales, el artículo recomendó una estrategia de enfriamiento para ajustar ε. Los detalles se pueden encontrar en el artículo original (sección 3).
2.3 Por qué la solución podría funcionar 🛠️
Al ponderar dinámicamente las pérdidas residuales temporales evaluadas en diferentes instancias de tiempo, el algoritmo propuesto es capaz de orientar el entrenamiento de PINN para que primero aproxime las soluciones de las EDP en momentos anteriores antes de intentar resolver la solución en momentos posteriores.
Esta propiedad facilita la incorporación explícita de la causalidad temporal en el entrenamiento de PINN y constituye el factor clave en las simulaciones potencialmente más precisas de sistemas físicos.
2.4 Referencia ⏱️
El artículo consideró un total de 3 ecuaciones de referencia diferentes. Todos los problemas son problemas directos donde se usa PINN para resolver las EDP.
- Sistema Lorenz: estas ecuaciones surgen en estudios de convección e inestabilidad en la convección atmosférica planetaria. El sistema Lorenz exhibe una fuerte sensibilidad a sus condiciones iniciales y se sabe que es un desafío para el PINN convencional.

- Ecuación Kuramoto-Sivashinsky: esta ecuación describe la dinámica de varios patrones ondulatorios, como llamas, reacciones químicas y ondas superficiales. Se sabe que exhibe una gran cantidad de comportamientos caóticos espacio-temporales.

- Ecuación de Navier-Stokes: este conjunto de ecuaciones diferenciales parciales describe el movimiento de sustancias fluidas y constituye las ecuaciones fundamentales en la mecánica de fluidos. El artículo actual consideró un ejemplo clásico de turbulencia decreciente bidimensional en un dominio cuadrado con condiciones de frontera periódicas.

Los estudios de referencia arrojaron que:
- El algoritmo de entrenamiento causal propuesto pudo lograr mejoras de precisión de 10-100 veces en comparación con el esquema de entrenamiento PINN convencional.
- Demuestra que los PINN equipados con el algoritmo de entrenamiento causal pueden simular con éxito sistemas altamente no lineales, multi-escala y caóticos.
2.5 Fortalezas y Debilidades ⚡
Fortalezas 💪
- Respeta el principio de causalidad y hace que el entrenamiento de PINN sea más transparente.
- Introduce mejoras significativas de precisión, lo que le permite abordar problemas que han sido difíciles de abordar para los PINN.
- Proporciona un criterio cuantitativo práctico para evaluar la convergencia del entrenamiento de PINN.
- Costo computacional insignificante en comparación con la estrategia de entrenamiento PINN convencional. El único costo adicional es calcular los ωᵢ, que es insignificante en comparación con las operaciones de auto-diferenciación.
Debilidades 📉
- Introdujo un nuevo hiperparámetro ε, que controla la programación de los pesos para las pérdidas residuales temporales. Aunque los autores propusieron una estrategia de recocido como alternativa para evitar la tediosa sintonización de hiperparámetros.
- Complicó el flujo de trabajo de entrenamiento de PINN. Se debe prestar especial atención a los pesos temporales ωᵢ, ya que ahora son funciones de los parámetros entrenables de la red (por ejemplo, pesos y sesgos de capa), y el gradiente asociado con el cálculo de ωᵢ no debe retropropagarse.
2.6 Alternativas 🔀
Hay un par de métodos alternativos que intentan abordar el mismo problema que el actual “algoritmo de entrenamiento causal”:
- Estrategia de muestreo de tiempo adaptable (Wight et al.): en lugar de ponderar los puntos de colocación en diferentes instantes de tiempo, esta estrategia modifica la densidad de muestreo de los puntos de colocación. Esto tiene un efecto similar al de cambiar el enfoque del optimizador en la minimización de pérdidas temporales en diferentes instantes de tiempo.
- Estrategia de “avance de tiempo” / “entrenamiento basado en currículo” (por ejemplo, Krishnapriyan et al.): la causalidad temporal se respeta mediante el aprendizaje de la solución de manera secuencial dentro de ventanas de tiempo separadas.
Sin embargo, en comparación con esos enfoques alternativos, el “algoritmo de entrenamiento causal” pone la causalidad temporal en el centro, es más adaptable a una variedad de problemas y disfruta de un bajo costo computacional adicional.
3 Mejoras potenciales futuras 🌟
Existen varias posibilidades para mejorar aún más la estrategia propuesta:
- Incorporación de estrategias de muestreo de datos más sofisticadas, como métodos de muestreo basados en adaptación y residuos, para mejorar aún más la eficiencia y precisión del entrenamiento.
Para obtener más información sobre cómo optimizar la distribución de puntos residuales, consulte este blog de la serie de patrones de diseño de PINN.
- Extender a configuraciones de problemas inversos. Cómo garantizar la causalidad cuando hay fuentes puntuales de información disponibles (es decir, datos observacionales) requeriría una extensión de la estrategia de entrenamiento propuesta actualmente.
4 Conclusiones 📝
En este blog, vimos cómo llevar la causalidad al entrenamiento de PINN con una reformulación de los objetivos de entrenamiento. Aquí se presentan los aspectos más destacados del patrón de diseño propuesto en el artículo:
- [Problema]: ¿Cómo hacer que las PINN respeten el principio de causalidad que sustenta los sistemas físicos?
- [Solución]: Reformulando el objetivo de entrenamiento de PINN, donde se introduce un esquema de ponderación dinámico que gradualmente desplaza el enfoque de entrenamiento desde los pasos de tiempo anteriores hasta los pasos de tiempo posteriores.
- [Posibles beneficios]: 1. Precisión significativamente mejorada de las PINN. 2. Ampliación de la aplicabilidad de las PINN a problemas complejos.
Aquí está la tarjeta de diseño de PINN para resumir las conclusiones:

¡Espero que hayas encontrado útil este blog! Para obtener más información sobre los patrones de diseño de PINN, no dudes en consultar publicaciones anteriores:
- Patrón de diseño de PINN 01: Optimización de la distribución de puntos residuales
- Patrón de diseño de PINN 02: Expansión dinámica del intervalo de solución
- Patrón de diseño de PINN 03: Entrenamiento de PINN con impulso de gradiente
- Patrón de diseño de PINN 04: Aprendizaje de PINN mejorado con gradiente
- Patrón de diseño de PINN 05: Ajuste de hiperparámetros para PINN
¡Espero compartir más ideas contigo en los próximos blogs!
Referencia 📑
[1] Wang et al., Respecting causality is all you need for training physics-informed neural networks, arXiv, 2022.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Más allá de NeRFs (Parte Dos)
- Microsoft AI presenta Orca un modelo de 13 mil millones de parámetros que aprende a imitar el proceso de razonamiento de los LFM (modelos de fundación grandes).
- 10 Cursos Cortos Gratuitos Para Dominar la Inteligencia Artificial Generativa
- FastAPI y Streamlit El dúo de Python que debes conocer.
- AVFormer Inyectando visión en modelos de habla congelados para la conversión automática de voz a texto sin entrenamiento previo (AV-ASR).
- Rendimiento sobrehumano en la prueba Atari 100K El poder de BBF – Un nuevo agente de RL basado en valores de Google DeepMind, Mila y la Universidad de Montreal.
- Ejecutando Falcon en una CPU con Hugging Face Pipelines.






