Desbloqueando el potencial de la IA con MINILM Una inmersión profunda en la destilación del conocimiento de modelos de lenguaje más grandes a contrapartes más pequeñas.
Unlocking AI potential with MINILM Deep dive into knowledge distillation from larger language models to smaller counterparts.


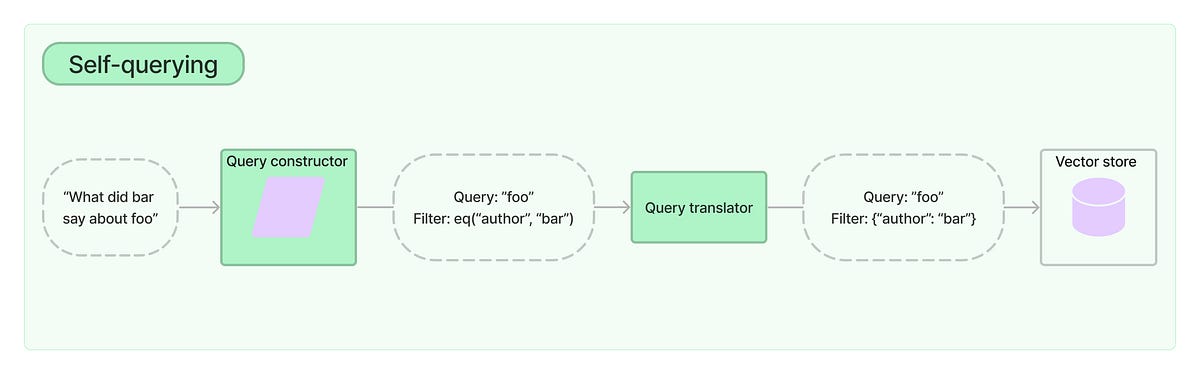
La destilación de conocimiento, que implica entrenar a un modelo estudiantil pequeño bajo la supervisión de un modelo docente grande, es una estrategia típica para disminuir la demanda excesiva de recursos computacionales debido al rápido desarrollo de modelos de lenguaje grandes. El KD de caja negra, en el que solo se tienen acceso a las predicciones del docente, y el KD de caja blanca, en el que se utilizan los parámetros del docente, son los dos tipos de KD que se utilizan con frecuencia. El KD de caja negra ha demostrado recientemente resultados alentadores en la optimización de modelos pequeños en los pares de respuesta de la API de LLM. El KD de caja blanca se vuelve cada vez más útil para las comunidades de investigación y los sectores industriales cuando se desarrollan más LLM de código abierto, ya que los modelos estudiantiles obtienen mejores señales de los modelos docentes de caja blanca, lo que puede llevar a una mejora del rendimiento.
Aunque aún no se ha investigado el KD de caja blanca para LLM generativos, se examina principalmente para modelos de comprensión del lenguaje pequeños (1B de parámetros). En este artículo, se examina el KD de caja blanca de LLM. Afirman que el KD común podría ser mejor para LLM que realizan tareas generativas. Los objetivos de KD estándar (incluyendo varias variantes para modelos a nivel de secuencia) minimizan esencialmente la divergencia de Kullback-Leibler hacia adelante aproximada (KLD) entre la distribución del docente y la del estudiante, conocida como KL, obligando a p a cubrir todos los modos de q dada la distribución del docente p(y|x) y la distribución del estudiante q(y|x) parametrizada por. KL funciona bien para problemas de clasificación de texto porque el espacio de salida a menudo contiene un número finito de clases, lo que garantiza que tanto p(y|x) como q(y|x) tengan un número pequeño de modos.
Sin embargo, para problemas de generación de texto abierto, donde los espacios de salida son mucho más complicados, p(y|x) puede representar una gama sustancialmente más amplia de modos que q(y|x). Durante la generación de ejecución libre, minimizar KLD hacia adelante puede hacer que q dé a las regiones vacías de p una probabilidad excesivamente alta y produzca muestras altamente improbables bajo p. Sugieren minimizar la divergencia de Kullback-Leibler hacia atrás, KL, que se utiliza comúnmente en visión por computadora y aprendizaje por refuerzo, para resolver este problema. Un experimento piloto muestra cómo subestimar KL impulsa a q a buscar los modos principales de p y dar a sus áreas vacías una probabilidad baja.
- Construir un Sistema de Recomendación Utilizando Google Cloud.
- Rompiendo barreras en el diseño de proteínas con un nuevo modelo de IA que comprende interacciones con cualquier tipo de molécula.
- Cerrando la brecha entre la comprensión humana y el aprendizaje automático Inteligencia Artificial Explicable como solución.
Esto significa que en la generación de lenguaje de LLM, el modelo estudiantil evita aprender demasiadas versiones de cola larga de la distribución del instructor y se concentra en la precisión de la respuesta producida, lo que es crucial en situaciones del mundo real donde se requiere honestidad y confiabilidad. Generan el gradiente del objetivo con Policy Gradient para optimizar min KL. Estudios recientes han demostrado la eficacia de la optimización de políticas en la optimización de PLMs. Sin embargo, también descubrieron que el entrenamiento del modelo aún sufre de variación excesiva, pirateo de recompensas y sesgo de longitud de generación. Por lo tanto, incluyen:
- Regularización de un solo paso para disminuir la variación.
- Muestreo mezclado del docente para disminuir el pirateo de recompensas.
- Normalización de longitud para reducir el sesgo de longitud.
En el entorno de seguimiento de instrucciones, que abarca una amplia gama de tareas de PLN, los investigadores de The CoAI Group, Tsinghua University y Microsoft Research ofrecen una técnica novedosa llamada MINILLM, que luego aplican a varios modelos generativos de lenguaje con tamaños de parámetros que van desde 120M hasta 13B. Se utilizan cinco conjuntos de datos de seguimiento de instrucciones y se emplean Rouge-L y GPT-4 para la evaluación. Sus pruebas demuestran que MINILM se escala con éxito desde modelos de 120M hasta 13B y supera consistentemente a los modelos de KD estándar de línea de secuencia en todos los conjuntos de datos (ver Figura 1). Más investigación revela que MINILLM funciona mejor en la producción de respuestas más largas con más variedad y tiene un sesgo de exposición reducido y una mejor calibración. Los modelos están disponibles en GitHub.

We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce TRACE Un Nuevo Enfoque de IA para la Estimación Precisa de la Postura y la Forma Humana en 3D con Seguimiento de Coordenadas Globales.
- Haciendo Predicciones Una Guía para Principiantes sobre Regresión Lineal en Python.
- El Maestro Gamer de la IA de DeepMind Aprende 26 juegos en 2 horas.
- La amistad con la modalidad única ha terminado, ahora la multi-modalidad es mi mejor amiga CoDi es un modelo de IA que puede lograr la generación de cualquier tipo a cualquier tipo a través de la difusión componible.
- CEO de NVIDIA Los creadores serán potenciados por la IA generativa.
- ¿Está lista su solicitud de LLM para el público?
- Desafíos de la producción en masa de conducción autónoma en China.