Detecta cualquier cosa que desees con UniDetector
UniDetector detecta cualquier cosa que desees


El aprendizaje profundo y la IA han avanzado notablemente en los últimos años, especialmente en los modelos de detección. A pesar de estos impresionantes avances, la efectividad de los modelos de detección de objetos depende en gran medida de conjuntos de datos de referencia a gran escala. Sin embargo, el desafío radica en la variación de las categorías y escenas de los objetos. En el mundo real, existen diferencias significativas con respecto a las imágenes existentes, y pueden surgir nuevas clases de objetos, lo que hace necesario reconstruir los conjuntos de datos para garantizar el éxito de los detectores de objetos. Desafortunadamente, esto afecta gravemente su capacidad de generalización en escenarios de mundo abierto. En contraste, los seres humanos, incluso los niños, pueden adaptarse rápidamente y generalizar bien en nuevos entornos. En consecuencia, la falta de universalidad en la IA sigue siendo una brecha notable entre los sistemas de IA y la inteligencia humana.
La clave para superar esta limitación es el desarrollo de un detector de objetos universal que logre capacidades de detección en todos los tipos de objetos en cualquier escena dada. Un modelo así poseería la notable capacidad de funcionar de manera efectiva en situaciones desconocidas sin necesidad de una nueva capacitación adicional. Este avance se acercaría significativamente al objetivo de hacer que los sistemas de detección de objetos sean tan inteligentes como los seres humanos.
Un detector de objetos universal debe poseer dos habilidades críticas. En primer lugar, debe ser entrenado utilizando imágenes de diversas fuentes y espacios de etiquetas diversos. El entrenamiento colaborativo a gran escala para la clasificación y localización es esencial para garantizar que el detector adquiera suficiente información para generalizar de manera efectiva. El conjunto de datos de aprendizaje a gran escala ideal debe incluir muchos tipos de imágenes, abarcando tantas categorías como sea posible, con anotaciones de cajas delimitadoras de alta calidad y vocabularios de categorías extensos. Desafortunadamente, lograr tal diversidad es un desafío debido a las limitaciones impuestas por los anotadores humanos. En la práctica, si bien los conjuntos de datos con vocabularios pequeños ofrecen anotaciones más limpias, los conjuntos de datos más grandes son más ruidosos y pueden sufrir inconsistencias. Además, los conjuntos de datos especializados se centran en categorías específicas. Para lograr la universalidad, el detector debe aprender de múltiples fuentes con espacios de etiquetas variables para adquirir conocimientos completos y exhaustivos.
- Investigadores de la Universidad Nacional de Singapur proponen Mind-Video una nueva herramienta de IA que utiliza datos de fMRI del cerebro para recrear imágenes de video
- Investigadores de UT Austin y UC Berkeley presentan Ambient Diffusion un marco de inteligencia artificial para entrenar/ajustar modelos de difusión dados solo datos corruptos como entrada.
- Conoce a QLORA Un enfoque de ajuste eficiente que reduce el uso de memoria lo suficiente como para ajustar un modelo de 65B parámetros en una sola GPU de 48GB, preservando al mismo tiempo el rendimiento completo de la tarea de ajuste fino de 16 bits.

En segundo lugar, el detector debe demostrar una generalización robusta al mundo abierto. Debe ser capaz de predecir con precisión etiquetas de categoría para clases nuevas que no se hayan visto durante el entrenamiento sin una caída significativa en el rendimiento. Sin embargo, confiar únicamente en la información visual no puede lograr este propósito, ya que el aprendizaje visual completo requiere anotaciones humanas para el aprendizaje completamente supervisado.
Para superar estas limitaciones, se ha propuesto un nuevo modelo de detección de objetos universal llamado “UniDetector”.
La descripción general de la arquitectura se muestra en la siguiente ilustración.
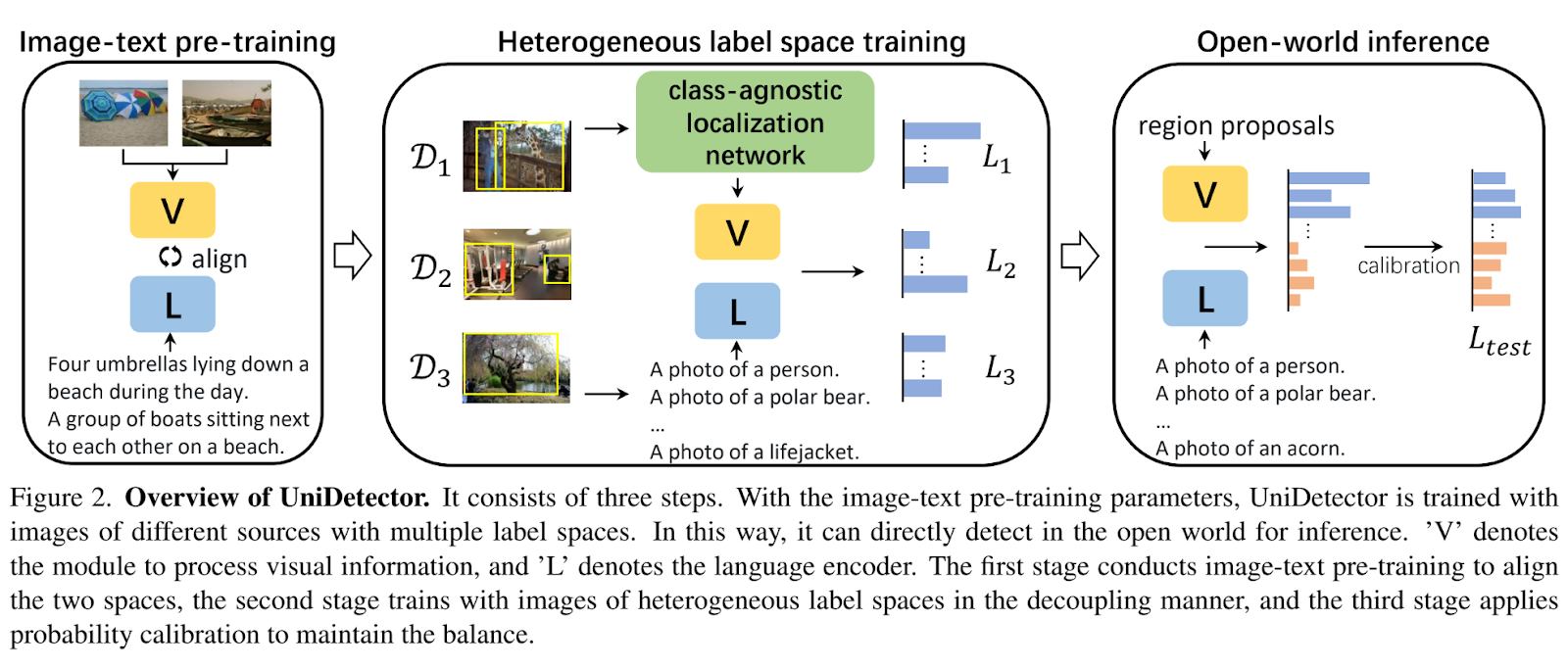
Se deben abordar dos desafíos correspondientes para lograr las dos habilidades esenciales de un detector de objetos universal. El primer desafío se refiere al entrenamiento con imágenes de múltiples fuentes, donde las imágenes provienen de diferentes fuentes y están asociadas con espacios de etiquetas diversos. Los detectores existentes se limitan a predecir clases de solo un espacio de etiquetas, y las diferencias en la taxonomía específica del conjunto de datos y la inconsistencia de anotación entre conjuntos de datos dificultan unificar múltiples espacios de etiquetas heterogéneos.
El segundo desafío involucra la discriminación de categorías nuevas. Inspirados por el éxito del preentrenamiento de imágenes y texto en la investigación reciente, los autores utilizan modelos preentrenados con incrustaciones de lenguaje para reconocer categorías no vistas. Sin embargo, el entrenamiento completamente supervisado tiende a sesgar el detector hacia las categorías presentes durante el entrenamiento. En consecuencia, el modelo podría inclinarse hacia las clases base en el momento de la inferencia y producir predicciones poco confiables para las clases nuevas. Aunque las incrustaciones de lenguaje ofrecen el potencial de predecir clases nuevas, su rendimiento aún está significativamente por debajo del de las categorías base.
UniDetector ha sido diseñado para abordar los desafíos mencionados anteriormente. Utilizando el espacio del lenguaje, los investigadores exploran varias estructuras para entrenar de manera efectiva el detector con espacios de etiquetas heterogéneos. Descubrieron que el empleo de una estructura particionada facilita el intercambio de características al evitar conflictos de etiquetas, lo cual es beneficioso para el rendimiento del detector.
Para mejorar la capacidad de generalización de la etapa de generación de propuestas de región hacia clases nuevas, los autores separan la etapa de generación de propuestas de la etapa de clasificación de RoI (Región de Interés), optando por un entrenamiento separado en lugar de un entrenamiento conjunto. Este enfoque aprovecha las características únicas de cada etapa, lo que contribuye a la universalidad general del detector. Además, introducen una red de localización sin clasificación (CLN) para lograr propuestas de región generalizadas.
Además, los autores proponen una técnica de calibración de probabilidades para corregir los sesgos en las predicciones. Estiman la probabilidad previa de todas las categorías y luego ajustan la distribución de categoría predicha en función de esta probabilidad previa. Esta calibración mejora significativamente el rendimiento de las clases nuevas dentro del sistema de detección de objetos. Según los autores, UniDetector puede superar a Dyhead, el detector de CNN de última generación, en un 6,3% de AP (Precisión Promedio).
Este fue el resumen de UniDetector, un nuevo marco de IA diseñado para la detección universal de objetos. Si estás interesado y quieres aprender más sobre este trabajo, puedes encontrar más información haciendo clic en los enlaces a continuación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- LLMs superan al aprendizaje por refuerzo Conozca SPRING un innovador marco de trabajo de sugerencias para LLMs diseñado para permitir la planificación y el razonamiento en cadena de pensamiento en contexto.
- Investigadores de UC Berkeley presentan Video Prediction Rewards (VIPER) un algoritmo que aprovecha los modelos de predicción de video preentrenados como señales de recompensa sin acción para el aprendizaje por refuerzo.
- Optimización del controlador PID Un enfoque de descenso de gradiente
- LLM (Modelos de Lenguaje Grandes) para un Mejor Aprendizaje del Desarrollador de tu Producto
- Conoce a WebAgent el nuevo LLM de DeepMind que sigue instrucciones y completa tareas en sitios web
- El modelo POE de sistemas de hardware inspirados en la biología
- Dominando las Expresiones Regulares con Python






