Tutorial de Docker para Científicos de Datos
Tutorial de Docker para Científicos de Datos

Python y el conjunto de bibliotecas de análisis de datos y aprendizaje automático de Python, como pandas y scikit-learn, te ayudan a desarrollar aplicaciones de ciencia de datos con facilidad. Sin embargo, la gestión de dependencias en Python es un desafío. Cuando trabajas en un proyecto de ciencia de datos, tendrás que pasar tiempo considerable instalando varias bibliotecas y controlando la versión de las bibliotecas que estás utilizando, entre otras cosas.
¿Y si otros desarrolladores quieren ejecutar tu código y contribuir al proyecto? Bueno, otros desarrolladores que deseen replicar tu aplicación de ciencia de datos deben configurar primero el entorno del proyecto en su máquina, antes de poder ejecutar el código. Incluso pequeñas diferencias, como versiones de bibliotecas diferentes, pueden introducir cambios que rompen el código. Docker al rescate. Docker simplifica el proceso de desarrollo y facilita la colaboración sin problemas.
Esta guía te presentará los conceptos básicos de Docker y te enseñará cómo contenerizar aplicaciones de ciencia de datos con Docker.
- Desbloquea el éxito de DataOps con DataOps.live – ¡Destacado en la Guía de Mercado de Gartner!
- La cirugía cerebral impulsada por IA se convierte en una realidad en Hong Kong
- Conoce FlexGen un motor de generación de alto rendimiento para ejecutar grandes modelos de lenguaje (LLM) con memoria limitada de GPU.
¿Qué es Docker?

Docker es una herramienta de contenerización que te permite construir y compartir aplicaciones como artefactos portátiles llamados imágenes.
Además del código fuente, tu aplicación tendrá un conjunto de dependencias, configuraciones requeridas, herramientas del sistema y más. Por ejemplo, en un proyecto de ciencia de datos, instalarás todas las bibliotecas requeridas en tu entorno de desarrollo (preferiblemente dentro de un entorno virtual). También te asegurarás de que estés utilizando una versión actualizada de Python que sea compatible con las bibliotecas.
Sin embargo, aún puedes encontrar problemas al intentar ejecutar tu aplicación en otra máquina. Estos problemas a menudo surgen debido a configuraciones incompatibles y versiones de bibliotecas diferentes en el entorno de desarrollo entre las dos máquinas.
Con Docker, puedes empaquetar tu aplicación junto con las dependencias y configuraciones. De esta manera, puedes definir un entorno aislado, reproducible y consistente para tus aplicaciones en una variedad de máquinas host.
Conceptos básicos de Docker: Imágenes, Contenedores y Registros
Vamos a repasar algunos conceptos/terminologías:
Imagen de Docker
Una imagen de Docker es el artefacto portátil de tu aplicación.
Contenedor de Docker
Cuando ejecutas una imagen, esencialmente estás ejecutando la aplicación dentro del entorno del contenedor. Por lo tanto, una instancia en ejecución de una imagen es un contenedor.
Registro de Docker
El registro de Docker es un sistema para almacenar y distribuir imágenes de Docker. Después de contenerizar una aplicación en una imagen de Docker, puedes ponerla a disposición de la comunidad de desarrolladores al enviarlas a un registro de imágenes. DockerHub es el registro público más grande y todas las imágenes se obtienen de DockerHub de forma predeterminada.
¿Cómo simplifica Docker el desarrollo?
Debido a que los contenedores proporcionan un entorno aislado para tus aplicaciones, otros desarrolladores solo necesitan tener Docker configurado en su máquina. Y pueden iniciar contenedores, pueden obtener la imagen de Docker y ejecutar contenedores usando un solo comando, sin tener que preocuparse por instalaciones complejas en un entorno remoto.
Cuando desarrollas una aplicación, también es común construir y probar múltiples versiones de la misma aplicación. Si usas Docker, puedes tener múltiples versiones de la misma aplicación ejecutándose en diferentes contenedores, sin conflictos, en el mismo entorno.
Además de simplificar el desarrollo, Docker también simplifica la implementación y ayuda a los equipos de desarrollo y operaciones a colaborar de manera efectiva. En el lado del servidor, el equipo de operaciones no tiene que perder tiempo resolviendo conflictos de versiones y dependencias. Solo necesitan tener un entorno de ejecución de Docker configurado.
Comandos esenciales de Docker
Vamos a repasar rápidamente algunos comandos básicos de Docker que usaremos en este tutorial. Para obtener una descripción más detallada, lee: 12 Comandos de Docker que Todo Científico de Datos Debe Conocer.
| Comando | Función |
docker ps |
Muestra todos los contenedores en ejecución |
docker pull nombre-imagen |
Descarga la imagen-nombre de DockerHub de forma predeterminada |
docker images |
Muestra todas las imágenes disponibles |
docker run nombre-imagen |
Inicia un contenedor desde una imagen |
docker start id-contenedor |
Reinicia un contenedor detenido |
docker stop id-contenedor |
Detiene un contenedor en ejecución |
docker build ruta |
Construye una imagen en la ruta utilizando las instrucciones en el archivo Dockerfile |
Nota: Ejecute todos los comandos prefijando sudo si no ha creado el grupo docker con el usuario.
Cómo Contenerizar una Aplicación de Ciencia de Datos Usando Docker
Hemos aprendido los conceptos básicos de Docker, y es hora de aplicar lo que hemos aprendido. En esta sección, contenerizaremos una aplicación simple de ciencia de datos utilizando Docker.
Modelo de Predicción de Precios de Casas
Tomemos el siguiente modelo de regresión lineal que predice el valor objetivo: el precio medio de una casa basado en las características de entrada. El modelo se construye utilizando el conjunto de datos de viviendas de California:
# house_price_prediction.py
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Cargar el conjunto de datos de viviendas de California
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Estandarizar las características
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Entrenar el modelo
model = LinearRegression()
model.fit(X_train, y_train)
# Hacer predicciones en el conjunto de prueba
y_pred = model.predict(X_test)
# Evaluar el modelo
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Error Cuadrático Medio: {mse:.2f}")
print(f"Puntaje R-cuadrado: {r2:.2f}")
Sabemos que scikit-learn es una dependencia requerida. Si revisa el código, establecemos as_frame igual a True al cargar el conjunto de datos. Por lo tanto, también necesitamos pandas. Y el archivo requirements.txt se ve así:
pandas==2.0
scikit-learn==1.2.2
Crear el Dockerfile
Hasta ahora, tenemos el archivo de código fuente house_price_prediction.py y el archivo requirements.txt. Ahora debemos definir cómo construir una imagen a partir de nuestra aplicación. El Dockerfile se utiliza para crear esta definición de construcción de una imagen a partir de los archivos de código fuente de la aplicación.
Entonces, ¿qué es un Dockerfile? Es un documento de texto que contiene instrucciones paso a paso para construir la imagen de Docker.
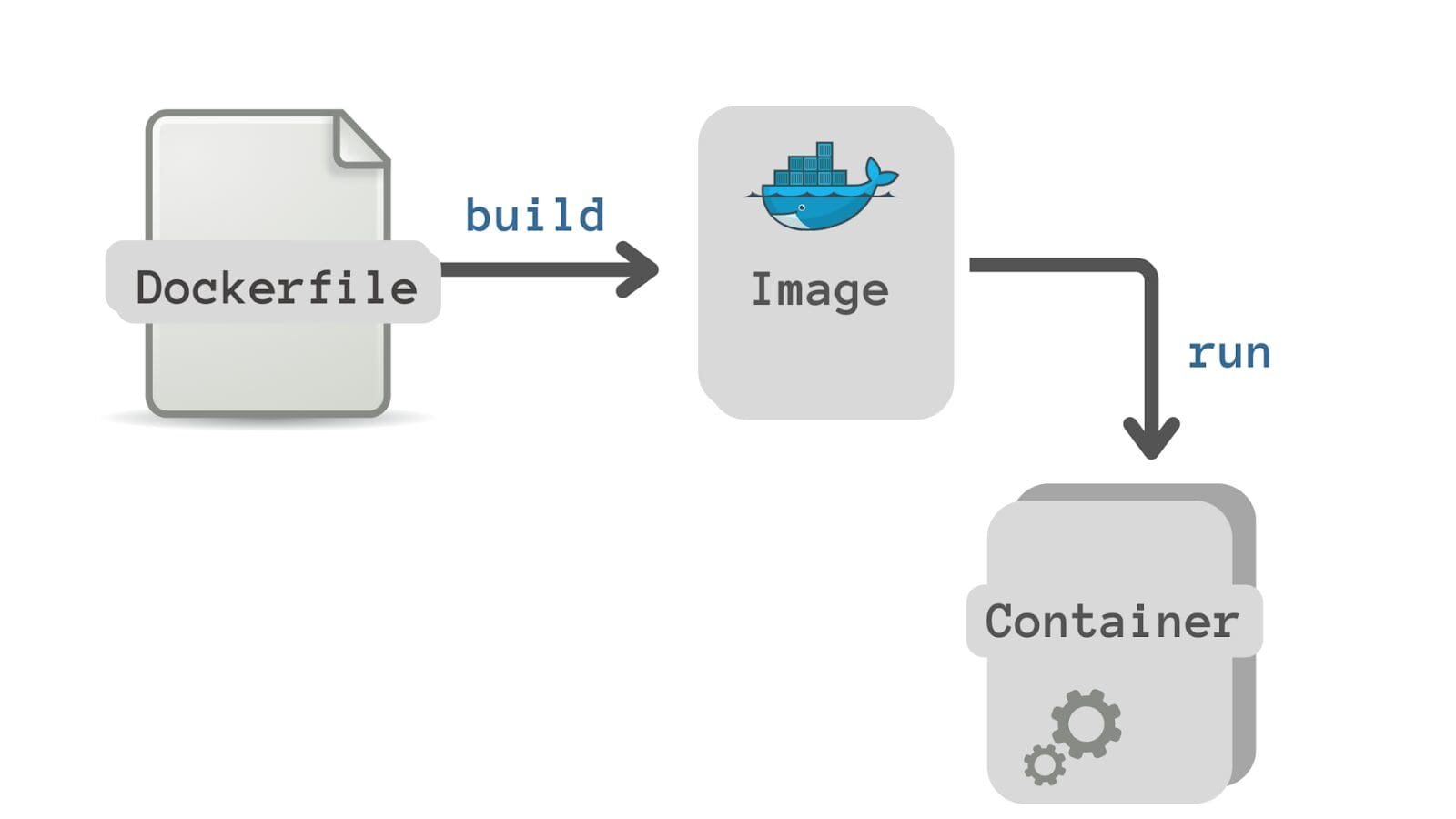
Aquí está el Dockerfile para nuestro ejemplo:
# Utilizar la imagen oficial de Python como imagen base
FROM python:3.9-slim
# Establecer el directorio de trabajo en el contenedor
WORKDIR /app
# Copiar el archivo requirements.txt al contenedor
COPY requirements.txt .
# Instalar las dependencias
RUN pip install --no-cache-dir -r requirements.txt
# Copiar el archivo de script al contenedor
COPY house_price_prediction.py .
# Establecer el comando para ejecutar el script de Python
CMD ["python", "house_price_prediction.py"]
Desglosemos el contenido del Dockerfile:
- Todos los Dockerfiles comienzan con una instrucción
FROMque especifica la imagen base. La imagen base es la imagen en la que se basa su imagen. Aquí utilizamos una imagen disponible para Python 3.9. La instrucciónFROMle indica a Docker que construya la imagen actual a partir de la imagen base especificada. - El comando
SETse utiliza para establecer el directorio de trabajo para todos los comandos siguientes (en este ejemplo, el directorio es “app”). - Luego copiamos el archivo
requirements.txtal sistema de archivos del contenedor. - La instrucción
RUNejecuta el comando especificado -en una shell- dentro del contenedor. Aquí instalamos todas las dependencias requeridas utilizandopip. - Luego copiamos el archivo de código fuente, el script de Python
house_price_prediction.py, al sistema de archivos del contenedor. - Finalmente,
CMDse refiere a la instrucción que se ejecutará cuando se inicie el contenedor. Aquí necesitamos ejecutar el scripthouse_price_prediction.py. El Dockerfile debe contener solo una instrucciónCMD.
Construir la Imagen
Ahora que hemos definido el Dockerfile, podemos construir la imagen de Docker ejecutando el comando docker build:
docker build -t ml-app .
La opción -t nos permite especificar un nombre y una etiqueta para la imagen en el formato nombre:etiqueta. La etiqueta por defecto es “latest”.
El proceso de construcción tarda un par de minutos:
Enviando contexto de construcción a Docker daemon 4.608kB
Paso 1/6 : FROM python:3.9-slim
3.9-slim: Pulling from library/python
5b5fe70539cd: Pull complete
f4b0e4004dc0: Pull complete
ec1650096fae: Pull complete
2ee3c5a347ae: Pull complete
d854e82593a7: Pull complete
Digest: sha256:0074c6241f2ff175532c72fb0fb37264e8a1ac68f9790f9ee6da7e9fdfb67a0e
Status: Descargado una imagen más reciente para python:3.9-slim
---> 326a3a036ed2
Paso 2/6 : WORKDIR /app
...
...
...
Paso 6/6 : CMD ["python", "house_price_prediction.py"]
---> Ejecutando en 7fcef6a2ab2c
Eliminando el contenedor intermedio 7fcef6a2ab2c
---> 2607aa43c61a
Construcción finalizada con éxito 2607aa43c61a
Etiquetado exitoso ml-app:latest
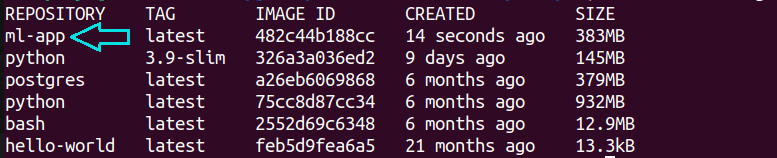
Después de haber construido la imagen de Docker, ejecuta el comando docker images. Deberías ver la imagen ml-app en la lista también.
docker images
 Puedes ejecutar la imagen de Docker
Puedes ejecutar la imagen de Docker ml-app utilizando el comando docker run:
docker run ml-app

¡Felicidades! Acabas de dockerizar tu primera aplicación de ciencia de datos. Al crear una cuenta en DockerHub, puedes subir la imagen a él (o a un repositorio privado dentro de la organización).
Conclusión
Espero que hayas encontrado útil este tutorial introductorio de Docker. Puedes encontrar el código utilizado en este tutorial en este repositorio de GitHub. Como siguiente paso, configura Docker en tu máquina y prueba este ejemplo. O dockeriza una aplicación de tu elección.
La forma más sencilla de instalar Docker en tu máquina es utilizando Docker Desktop: obtienes tanto el cliente de línea de comandos de Docker como una interfaz gráfica para gestionar tus contenedores fácilmente. ¡Así que configura Docker y comienza a programar de inmediato! Bala Priya C es una desarrolladora y escritora técnica de India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento del lenguaje natural. Le gusta leer, escribir, programar ¡y tomar café! Actualmente, está trabajando en aprender y compartir sus conocimientos con la comunidad de desarrolladores mediante la creación de tutoriales, guías prácticas, artículos de opinión y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Este artículo de IA presenta una novedosa clase de objetivos sin simulación para el aprendizaje de modelos generativos estocásticos en tiempo continuo entre distribuciones generales de origen y destino.
- Un Enfoque Práctico para la Ingeniería de Características en Aprendizaje Automático
- Construyendo una aplicación web completa en los servicios de AWS
- Listas de Python vs. Arrays de NumPy Un análisis detallado sobre la organización en memoria y los beneficios en rendimiento
- 3 Trucos Poderosos Para Trabajar Con Datos de Fecha y Hora en Python
- Una nueva investigación de IA presenta GPT4RoI un modelo de visión y lenguaje basado en la sintonización de instrucciones de un Gran Modelo de Lenguaje (LLM) en pares de región-texto.
- Los investigadores de la Universidad de Pennsylvania presentaron un enfoque alternativo de IA para diseñar y programar computadoras de depósito basadas en RNN.






