Tus datos (finalmente) están en la nube. Ahora, deja de actuar como si estuvieran en las instalaciones físicas.
Tus datos están en la nube, no en instalaciones físicas.
Las pilas de datos modernas te permiten hacer las cosas de manera diferente, no solo a una escala mayor. Aprovecha esto.

Imagina que has estado construyendo casas con un martillo y clavos durante la mayor parte de tu carrera, y yo te doy una pistola de clavos. Pero en lugar de presionarla contra la madera y apretar el gatillo, la giras hacia un lado y golpeas el clavo como si estuvieras usando un martillo.
Probablemente pensarías que es costoso y no muy efectivo, mientras que el inspector del sitio lo consideraría un riesgo para la seguridad.
Bueno, eso es porque estás utilizando herramientas modernas, pero con pensamiento y procesos heredados. Y aunque esta analogía no es una encapsulación perfecta de cómo algunos equipos de datos operan después de pasar de las instalaciones locales a una pila de datos moderna, se acerca.
Los equipos comprenden rápidamente cómo los servicios de cómputo y almacenamiento hiperelásticos pueden permitirles manejar más tipos de datos diversos a un volumen y velocidad previamente desconocidos, pero no siempre comprenden el impacto de la nube en sus flujos de trabajo.
- Creando animación para mostrar 4 algoritmos de agrupamiento basados en centroides usando Python y Sklearn
- Kris Nagel, CEO de Sift – Serie de Entrevistas
- Esta investigación de IA propone Strip-Cutmix un método de aumento de datos más adecuado para la reidentificación de personas
Entonces, tal vez una mejor analogía para estos equipos de datos migrados recientemente sería si te diera 1,000 pistolas de clavos… y luego te viera girarlas todas hacia un lado para golpear 1,000 clavos al mismo tiempo.
De todos modos, lo importante es entender que la pila de datos moderna no solo te permite almacenar y procesar datos de manera más grande y rápida, sino que te permite manejar los datos de manera fundamentalmente diferente para lograr nuevos objetivos y extraer diferentes tipos de valor.
Esto se debe en parte al aumento de escala y velocidad, pero también como resultado de metadatos más ricos e integraciones más fluidas en todo el ecosistema.
En esta publicación, resalto tres de las formas más comunes en las que veo que los equipos de datos cambian su comportamiento en la nube, y cinco formas en las que no lo hacen (pero deberían). Vamos a sumergirnos.
3 Formas en que los Equipos de Datos Cambiaron con la Nube
Existen razones por las cuales los equipos de datos se mudan a una pila de datos moderna (más allá de que el director financiero finalmente libere presupuesto). Estos casos de uso suelen ser el primer y más fácil cambio de comportamiento para los equipos de datos una vez que ingresan a la nube. Son los siguientes:
Pasar de ETL a ELT para acelerar el tiempo de insight
No puedes simplemente cargar cualquier cosa en tu base de datos local, especialmente si quieres que una consulta se devuelva antes de que llegue el fin de semana. Como resultado, estos equipos de datos deben considerar cuidadosamente qué datos extraer y cómo transformarlos en su estado final, a menudo a través de un pipeline codificado en Python.
Es como hacer comidas específicas a pedido para cada consumidor de datos en lugar de ofrecer un buffet, y como cualquiera que haya estado en un crucero sabe, cuando necesitas satisfacer una demanda insaciable de datos en toda la organización, un buffet es el camino a seguir.
Ese fue el caso de Edward Kent, líder técnico de AutoTrader UK, quien habló con mi equipo el año pasado sobre la confianza en los datos y la demanda de análisis de autoservicio.
“Queremos empoderar a AutoTrader y a sus clientes para que tomen decisiones informadas por datos y democratizar el acceso a los datos a través de una plataforma de autoservicio…. A medida que estamos migrando sistemas confiables locales a la nube, los usuarios de esos sistemas antiguos necesitan confiar en que las nuevas tecnologías basadas en la nube son tan confiables como los sistemas antiguos que han utilizado en el pasado”, dijo.
Cuando los equipos de datos migran a la pila de datos moderna, adoptan con entusiasmo herramientas de ingestión automatizadas como Fivetran o herramientas de transformación como dbt y Spark, junto con estrategias de curación de datos más sofisticadas. El autoservicio analítico abre una nueva lata de gusanos, y no siempre está claro quién debería ser el responsable de la modelización de datos, pero en general es una forma mucho más eficiente de abordar casos de uso analíticos (¡y otros!).
Datos en tiempo real para la toma de decisiones operativas
En la pila de datos moderna, los datos pueden moverse lo suficientemente rápido como para no tener que reservarse únicamente para las verificaciones diarias de métricas. Los equipos de datos pueden aprovechar las tablas en vivo de Delta, Snowpark, Kafka, Kinesis, micro-batching y más.
No todos los equipos tienen un caso de uso de datos en tiempo real, pero aquellos que lo tienen suelen estar bien informados. Estas suelen ser empresas con logística significativa que necesitan soporte operativo o empresas tecnológicas con informes sólidos integrados en sus productos (aunque una buena parte de estas últimas nacieron en la nube).
Por supuesto, todavía existen desafíos. Estos a veces pueden implicar la ejecución de arquitecturas paralelas (lotes analíticos y flujos en tiempo real) y tratar de alcanzar un nivel de control de calidad que no es posible en el grado que la mayoría desearía. Pero la mayoría de los líderes de datos comprenden rápidamente el desbloqueo de valor que se produce al poder apoyar de manera más directa la toma de decisiones operativas en tiempo real.
IA generativa y aprendizaje automático
Los equipos de datos son conscientes de la ola de GenAI y muchos observadores de la industria sospechan que esta tecnología emergente está impulsando una gran ola de modernización y utilización de infraestructuras.
Pero antes de que ChatGPT generara su primer ensayo, las aplicaciones de aprendizaje automático habían pasado lentamente de ser vanguardia a ser las mejores prácticas estándar en varias industrias intensivas en datos, incluyendo medios de comunicación, comercio electrónico y publicidad.
Hoy en día, muchos equipos de datos comienzan inmediatamente a examinar estos casos de uso en cuanto tienen almacenamiento y potencia de cálculo escalables (aunque algunos se beneficiarían de construir una mejor base).
Si recientemente te mudaste a la nube y no has preguntado al negocio cómo estos casos de uso podrían respaldar mejor al negocio, agéndalo. Para esta semana. O para hoy. Me lo agradecerás más tarde.
5 formas en que los equipos de datos aún actúan como si estuvieran en local
Ahora, veamos algunas de las oportunidades no realizadas que los equipos de datos anteriormente en local pueden tardar más en aprovechar.
Nota: Quiero dejar claro que, si bien mi analogía anterior fue un poco humorística, no me estoy burlando de los equipos que aún operan en local o que operan en la nube utilizando los procesos mencionados a continuación. El cambio es difícil. Es aún más difícil cuando te enfrentas a una lista de pendientes constante y una demanda cada vez mayor.
Pruebas de datos
Los equipos de datos que están en local no tienen la escala ni los metadatos ricos de los registros de consultas centrales o los formatos modernos de tablas para ejecutar fácilmente la detección de anomalías impulsada por el aprendizaje automático (es decir, la observabilidad de datos).
En cambio, trabajan con equipos de dominio para comprender los requisitos de calidad de los datos y traducirlos en reglas SQL o pruebas de datos. Por ejemplo, el customer_id nunca debe ser NULL o currency_conversion nunca debe tener un valor negativo. Existen herramientas basadas en local diseñadas para ayudar a acelerar y gestionar este proceso.
Cuando estos equipos de datos llegan a la nube, su primer pensamiento no es abordar la calidad de los datos de manera diferente, sino ejecutar pruebas de datos a escala en la nube. Es lo que conocen.
He visto estudios de casos que parecen historias de terror (y no, no diré nombres) donde un equipo de ingeniería de datos ejecuta millones de tareas en miles de DAG para monitorear la calidad de los datos en cientos de canalizaciones. ¡Vaya!
¿Qué sucede cuando se ejecutan medio millón de pruebas de datos? Te lo diré. Incluso si la gran mayoría pasa, todavía hay decenas de miles que fallarán. Y volverán a fallar mañana, porque no hay contexto para acelerar el análisis de la causa raíz o incluso comenzar a triage y averiguar por dónde empezar.
De alguna manera, has fatigado a tu equipo con alertas Y aún no has alcanzado el nivel de cobertura que necesitas. Sin mencionar que las pruebas de datos a gran escala son costosas en tiempo y dinero.
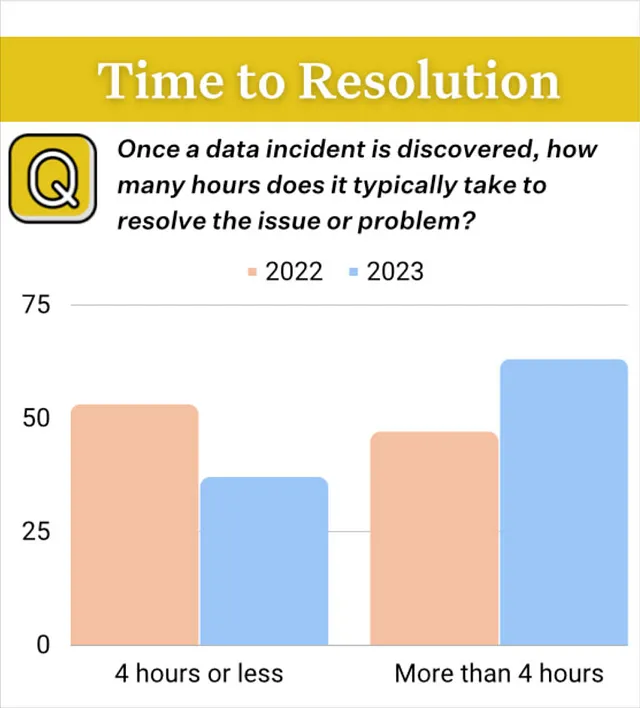
En cambio, los equipos de datos deberían aprovechar tecnologías que puedan detectar, triage y ayudar en el análisis de la causa raíz de posibles problemas, al mismo tiempo que reservan las pruebas de datos (o monitores personalizados) para los umbrales más claros en los valores más importantes dentro de las tablas más utilizadas.
Modelado de datos para el linaje de datos
Existen muchas razones legítimas para respaldar un modelo de datos central, y probablemente ya hayas leído todas ellas en un excelente artículo de Chad Sanderson.
Pero, de vez en cuando me encuentro con equipos de datos en la nube que están invirtiendo tiempo y recursos considerables en mantener modelos de datos únicamente con el propósito de mantener y comprender la línea de datos. Cuando estás en las instalaciones, esa es básicamente tu mejor opción a menos que quieras leer largos bloques de código SQL y crear un tablero lleno de fichas y hilos tan lleno que tu pareja comienza a preguntarse si estás bien.

(“¡No Lior! ¡No estoy bien, estoy tratando de entender cómo esta cláusula WHERE cambia qué columnas están en este JOIN!”)
Varias herramientas dentro del conjunto de datos moderno -incluyendo catálogos de datos, plataformas de observabilidad de datos y repositorios de datos- pueden aprovechar los metadatos para crear una línea de datos automatizada. Solo es cuestión de elegir un sabor.
Segmentación de clientes
En el mundo antiguo, la vista del cliente es plana, mientras que sabemos que realmente debería ser una vista global de 360 grados.
Esta vista limitada del cliente es el resultado de datos premodelados (ETL), restricciones de experimentación y el tiempo que se requiere para que las bases de datos en las instalaciones calculen consultas más sofisticadas (recuentos únicos, valores distintos) en conjuntos de datos más grandes.
Desafortunadamente, los equipos de datos no siempre eliminan las limitaciones de su enfoque en el cliente una vez que esas restricciones se han eliminado en la nube. A menudo existen varias razones para esto, pero los mayores culpables en gran medida son los buenos y viejos silos de datos.
La plataforma de datos del cliente que opera el equipo de marketing todavía está activa y en funcionamiento. Ese equipo podría beneficiarse de enriquecer su vista de prospectos y clientes con datos de otros dominios que se almacenan en el almacén/deposito de datos, pero los hábitos y el sentido de propiedad construidos a partir de años de gestión de campañas son difíciles de romper.
Entonces, en lugar de dirigirse a prospectos basados en el valor de vida estimado más alto, se trata de coste por cliente potencial o coste por clic. Esto es una oportunidad perdida para que los equipos de datos contribuyan con valor de manera directa y altamente visible para la organización.
Exportación y compartición de datos externos
Copiar y exportar datos es lo peor. Toma tiempo, agrega costos, crea problemas de versionado y hace que el control de acceso sea prácticamente imposible.
En lugar de aprovechar su conjunto de datos moderno para crear una canalización para exportar datos a sus socios habituales a velocidades extremadamente rápidas, más equipos de datos en la nube deberían aprovechar la compartición de datos sin copia. Al igual que administrar los permisos de un archivo en la nube ha reemplazado en gran medida el adjunto de correo electrónico, la compartición de datos sin copia permite acceder a los datos sin tener que moverlos del entorno de origen.
Tanto Snowflake como Databricks han anunciado y destacado ampliamente sus tecnologías de compartición de datos en sus cumbres anuales en los últimos dos años, y más equipos de datos deben comenzar a aprovecharlas.
Optimización de costes y rendimiento
En muchos sistemas en las instalaciones, el administrador de la base de datos es responsable de supervisar todas las variables que podrían afectar el rendimiento general y regularlas según sea necesario.
En cambio, dentro del conjunto de datos moderno, a menudo se observa uno de dos extremos.
En algunos casos, el rol de DBA permanece o se externaliza a un equipo central de plataforma de datos, lo que puede crear cuellos de botella si no se gestiona adecuadamente. Sin embargo, lo más común es que la optimización de costes o rendimiento se convierta en el salvaje oeste hasta que una factura particularmente impactante llega al escritorio del CFO.
Esto ocurre a menudo cuando los equipos de datos no tienen los monitores de costes adecuados en su lugar, y hay un evento atípico particularmente agresivo (quizás un código incorrecto o JOINs explosivos).
Además, algunos equipos de datos no aprovechan al máximo el modelo “paga por lo que usas” y optan por comprometerse con una cantidad predeterminada de créditos (normalmente con descuento)… y luego lo superan. Si bien no hay nada inherentemente incorrecto en los contratos de compromiso de créditos, tener esa libertad puede generar malos hábitos que pueden acumularse con el tiempo si no tienes cuidado.
La nube permite y fomenta un enfoque más continuo, colaborativo e integrado para DevOps/DataOps, y lo mismo ocurre cuando se trata de FinOps. Los equipos que veo que tienen más éxito en la optimización de costes dentro del conjunto de datos moderno son aquellos que lo integran en sus flujos de trabajo diarios e incentivan a aquellos que están más cerca del costo.
“El aumento de los precios basados en el consumo hace que esto sea aún más crítico, ya que el lanzamiento de una nueva función podría causar un aumento exponencial de los costos”, dijo Tom Milner en Tenable. “Como gerente de mi equipo, verifico nuestros costos diarios de Snowflake y convierto cualquier aumento en una prioridad en nuestra lista de tareas pendientes”.
Esto crea bucles de retroalimentación, aprendizajes compartidos y miles de pequeñas correcciones rápidas que generan grandes resultados.
“Tenemos alertas configuradas cuando alguien realiza consultas que nos costarían más de $1. Este es un umbral bastante bajo, pero hemos descubierto que no es necesario que cueste más que eso. Hemos encontrado que esto es un buen bucle de retroalimentación. [Cuando ocurre esta alerta] a menudo es porque alguien olvidó aplicar un filtro en una columna particionada o clusterizada y pueden aprender rápidamente”, dijo Stijn Zanders en Aiven.
Finalmente, implementar modelos de reembolso entre equipos, algo impensable en los días previos a la nube, es un esfuerzo complicado pero finalmente valioso que me gustaría ver que más equipos de datos evalúen.
Sé un aprendiz constante
El CEO de Microsoft, Satya Nadella, ha hablado sobre cómo deliberadamente cambió la cultura organizativa de la empresa de “sabelotodos” a “aprendices constantes”. Este sería mi mejor consejo para los líderes de datos, ya sea que acaben de migrar o hayan estado a la vanguardia de la modernización de los datos durante años.
Entiendo lo abrumador que puede ser. Las nuevas tecnologías están llegando rápidamente, al igual que las llamadas de los proveedores que las promocionan. En última instancia, no se trata de tener la pila de datos “más moderna” de su industria, sino de crear una alineación entre las herramientas modernas, el mejor talento y las mejores prácticas.
Para lograr eso, siempre esté listo para aprender cómo sus colegas están abordando muchos de los desafíos a los que se enfrenta. Participe en las redes sociales, lea VoAGI, siga a los analistas y asista a conferencias. ¡Nos vemos allí!
¿Qué otras actividades de ingeniería de datos en las instalaciones ya no tienen sentido en la nube? Comuníquese con Barr en LinkedIn con cualquier comentario o pregunta.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- El Proceso de IA
- 5 Formas en las que puedes utilizar el intérprete de código de ChatGPT para Ciencia de Datos
- Por qué la API de OpenAI es más cara para los idiomas que no son inglés
- Desenmascarando Deepfakes Aprovechando los patrones de estimación de la posición de la cabeza para mejorar la precisión de detección
- Este boletín de inteligencia artificial es todo lo que necesitas #60
- Qué saber sobre StableCode el generador de código de IA de Stability AI
- Los modelos de IA son poderosos, pero ¿son biológicamente plausibles?






