Train y despliega modelos de ML en un entorno multicloud utilizando Amazon SageMaker
Train y despliega modelos de ML en multicloud con Amazon SageMaker
A medida que los clientes aceleran sus migraciones a la nube y transforman sus negocios, algunos se encuentran en situaciones en las que tienen que gestionar operaciones de TI en un entorno multicloud. Por ejemplo, es posible que haya adquirido una empresa que ya estaba utilizando otro proveedor de servicios en la nube, o puede tener una carga de trabajo que genera valor a partir de capacidades únicas proporcionadas por AWS. Otro ejemplo son los proveedores de software independientes (ISV) que ponen a disposición sus productos y servicios en diferentes plataformas en la nube para beneficiar a sus clientes finales. O una organización puede estar operando en una región donde no está disponible un proveedor de servicios en la nube principal, y para cumplir con los requisitos de soberanía de datos o residencia de datos, pueden utilizar un proveedor de servicios en la nube secundario.
En estos escenarios, a medida que comienza a adoptar la inteligencia artificial generativa, los modelos de lenguaje grandes (LLMs) y las tecnologías de aprendizaje automático (ML) como parte fundamental de su negocio, es posible que esté buscando opciones para aprovechar las capacidades de IA y ML de AWS fuera de AWS en un entorno multicloud. Por ejemplo, es posible que desee utilizar Amazon SageMaker para construir y entrenar modelos de ML, o utilizar Amazon SageMaker Jumpstart para implementar modelos de ML preconstruidos de fundación o de terceros, que se pueden implementar con solo hacer clic en unos pocos botones. O puede que desee aprovechar Amazon Bedrock para construir y escalar aplicaciones de IA generativa, o puede aprovechar los servicios de IA preentrenados de AWS, que no requieren que aprenda habilidades de aprendizaje automático. AWS brinda soporte para escenarios en los que las organizaciones desean llevar su propio modelo a Amazon SageMaker o a Amazon SageMaker Canvas para predicciones.
En esta publicación, demostramos una de las muchas opciones que tiene para aprovechar el conjunto más amplio y profundo de capacidades de IA/ML de AWS en un entorno multicloud. Mostramos cómo puede construir y entrenar un modelo de ML en AWS e implementar el modelo en otra plataforma. Entrenamos el modelo utilizando Amazon SageMaker, almacenamos los artefactos del modelo en Amazon Simple Storage Service (Amazon S3) e implementamos y ejecutamos el modelo en Azure. Este enfoque es beneficioso si utiliza los servicios de AWS para ML por su conjunto más completo de funciones, pero necesita ejecutar su modelo en otro proveedor de servicios en la nube en una de las situaciones que hemos discutido.
Conceptos clave
Amazon SageMaker Studio es un entorno de desarrollo integrado (IDE) basado en web para el aprendizaje automático. SageMaker Studio permite a los científicos de datos, ingenieros de ML e ingenieros de datos preparar datos, construir, entrenar e implementar modelos de ML en una interfaz web. Con SageMaker Studio, puede acceder a herramientas específicas para cada etapa del ciclo de vida del desarrollo de ML, desde la preparación de datos hasta la construcción, el entrenamiento y la implementación de sus modelos de ML, mejorando la productividad del equipo de ciencia de datos hasta diez veces. Los cuadernos de SageMaker Studio son cuadernos de inicio rápido y colaborativos que se integran con herramientas de ML específicas en SageMaker y otros servicios de AWS.
- Guía completa para principiantes de las herramientas de Hugging Face LLM
- 10 Mejores Generadores de Retratos AI (Septiembre 2023)
- 20 ideas principales de proyectos de ingeniería de datos [con código fuente]
SageMaker es un servicio integral de ML que permite a los analistas de negocios, científicos de datos e ingenieros de MLOps construir, entrenar e implementar modelos de ML para cualquier caso de uso, independientemente de la experiencia en ML.
AWS proporciona Contenedores de Aprendizaje Profundo (DLCs) para marcos de ML populares como PyTorch, TensorFlow y Apache MXNet, que puede utilizar con SageMaker para entrenamiento e inferencia. Los DLC están disponibles como imágenes de Docker en Amazon Elastic Container Registry (Amazon ECR). Las imágenes de Docker están preinstaladas y probadas con las últimas versiones de los marcos de aprendizaje profundo populares, así como con otras dependencias necesarias para el entrenamiento y la inferencia. Para obtener una lista completa de las imágenes de Docker preconstruidas gestionadas por SageMaker, consulte Rutas del Registro de Docker y Código de Ejemplo. Amazon ECR admite el escaneo de seguridad y está integrado con el servicio de administración de vulnerabilidades de Amazon Inspector para cumplir con los requisitos de seguridad de cumplimiento de imágenes de su organización y para automatizar el escaneo de evaluación de vulnerabilidades. Las organizaciones también pueden utilizar AWS Trainium y AWS Inferentia para obtener un mejor rendimiento de precio para ejecutar trabajos de entrenamiento o inferencia de ML.
Descripción general de la solución
En esta sección, describimos cómo construir y entrenar un modelo utilizando SageMaker e implementar el modelo en Azure Functions. Utilizamos un cuaderno de SageMaker Studio para construir, entrenar e implementar el modelo. Entrenamos el modelo en SageMaker utilizando una imagen de Docker preconstruida para PyTorch. Aunque estamos implementando el modelo entrenado en Azure en este caso, podría utilizar el mismo enfoque para implementar el modelo en otras plataformas como locales u otras plataformas en la nube.
Cuando creamos un trabajo de entrenamiento, SageMaker inicia las instancias de cómputo de ML y utiliza nuestro código de entrenamiento y el conjunto de datos de entrenamiento para entrenar el modelo. Guarda los artefactos del modelo resultante y otros resultados en un bucket de S3 que especificamos como entrada para el trabajo de entrenamiento. Cuando el entrenamiento del modelo está completo, utilizamos la biblioteca de tiempo de ejecución de Open Neural Network Exchange (ONNX) para exportar el modelo de PyTorch como un modelo ONNX.
Finalmente, implementamos el modelo ONNX junto con un código de inferencia personalizado escrito en Python en Azure Functions utilizando la CLI de Azure. ONNX admite la mayoría de los marcos y herramientas de ML comúnmente utilizados. Una cosa a tener en cuenta es que convertir un modelo de ML a ONNX es útil si desea utilizar un marco de implementación de destino diferente, como de PyTorch a TensorFlow. Si está utilizando el mismo marco tanto en la fuente como en el destino, no es necesario convertir el modelo al formato ONNX.
El siguiente diagrama ilustra la arquitectura para este enfoque.
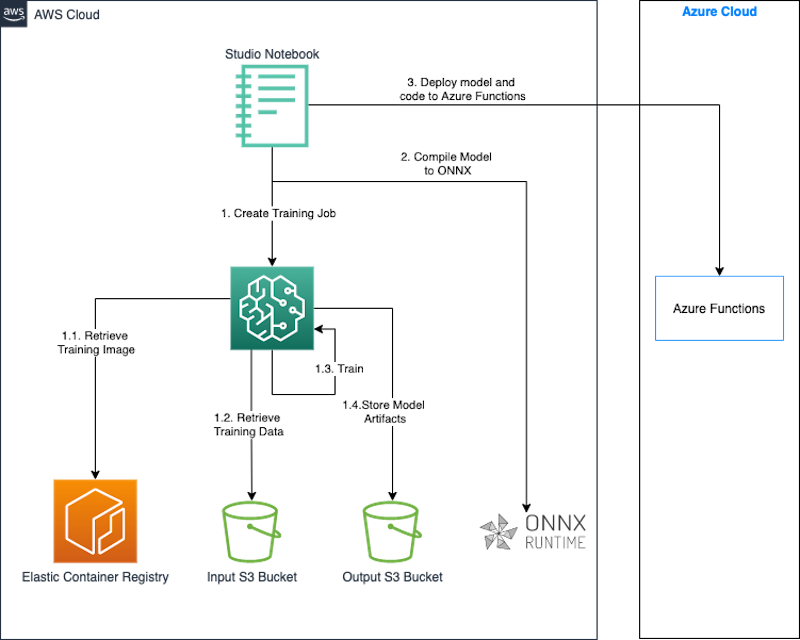
Utilizamos un cuaderno de SageMaker Studio junto con el SageMaker Python SDK para construir y entrenar nuestro modelo. El SageMaker Python SDK es una biblioteca de código abierto para entrenar e implementar modelos de ML en SageMaker. Para obtener más detalles, consulte Crear o abrir un cuaderno de SageMaker Studio de Amazon.
Los fragmentos de código en las siguientes secciones se han probado en el entorno del cuaderno de SageMaker Studio utilizando la imagen Data Science 3.0 y el kernel de Python 3.0.
En esta solución, demostramos los siguientes pasos:
- Entrenar un modelo PyTorch.
- Exportar el modelo PyTorch como un modelo ONNX.
- Empaquetar el modelo y el código de inferencia.
- Implementar el modelo en Azure Functions.
Prerrequisitos
Debe tener los siguientes prerrequisitos:
- Una cuenta de AWS.
- Un dominio de SageMaker y un usuario de SageMaker Studio. Para obtener instrucciones sobre cómo crearlos, consulte Incorporarse a un dominio de Amazon SageMaker mediante la configuración rápida.
- La interfaz de línea de comandos de Azure (Azure CLI).
- Acceso a Azure y credenciales para un principal de servicio que tenga permisos para crear y administrar Azure Functions.
Entrenar un modelo con PyTorch
En esta sección, detallamos los pasos para entrenar un modelo PyTorch.
Instalar dependencias
Instale las bibliotecas necesarias para llevar a cabo los pasos requeridos para el entrenamiento y la implementación del modelo:
pip install torchvision onnx onnxruntimeCompletar la configuración inicial
Comenzamos importando el SDK de AWS para Python (Boto3) y el SDK de Python de SageMaker. Como parte de la configuración, definimos lo siguiente:
- Un objeto de sesión que proporciona métodos de conveniencia en el contexto de SageMaker y nuestra propia cuenta.
- Un ARN de rol de SageMaker utilizado para delegar permisos al servicio de entrenamiento y alojamiento. Necesitamos esto para que estos servicios puedan acceder a los buckets de S3 donde se almacenan nuestros datos y modelo. Para obtener instrucciones sobre cómo crear un rol que cumpla con sus necesidades comerciales, consulte Roles de SageMaker. Para esta publicación, utilizamos el mismo rol de ejecución que nuestra instancia del cuaderno de Studio. Obtenemos este rol llamando a
sagemaker.get_execution_role(). - La región predeterminada donde se ejecutará nuestro trabajo de entrenamiento.
- El bucket predeterminado y el prefijo que utilizamos para almacenar la salida del modelo.
Vea el siguiente código:
import sagemaker
import boto3
import os
execution_role = sagemaker.get_execution_role()
region = boto3.Session().region_name
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = "sagemaker/mnist-pytorch"Crear el conjunto de datos de entrenamiento
Utilizamos el conjunto de datos disponible en el bucket público sagemaker-example-files-prod-{region}. El conjunto de datos contiene los siguientes archivos:
- train-images-idx3-ubyte.gz: Contiene imágenes del conjunto de entrenamiento
- train-labels-idx1-ubyte.gz: Contiene etiquetas del conjunto de entrenamiento
- t10k-images-idx3-ubyte.gz: Contiene imágenes del conjunto de pruebas
- t10k-labels-idx1-ubyte.gz: Contiene etiquetas del conjunto de pruebas
Utilizamos el módulo torchvision.datasets para descargar los datos del bucket público localmente antes de cargarlo en nuestro bucket de datos de entrenamiento. Pasamos esta ubicación del bucket como entrada al trabajo de entrenamiento de SageMaker. Nuestro script de entrenamiento utiliza esta ubicación para descargar y preparar los datos de entrenamiento, y luego entrenar el modelo. Vea el siguiente código:
MNIST.mirrors = [
f"https://sagemaker-example-files-prod-{region}.s3.amazonaws.com/datasets/image/MNIST/"
]
MNIST(
"data",
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
)Crear el script de entrenamiento
Con SageMaker, puedes traer tu propio modelo utilizando el modo de script. Con el modo de script, puedes utilizar los contenedores preconstruidos de SageMaker y proporcionar tu propio script de entrenamiento, que incluye la definición del modelo, junto con cualquier biblioteca personalizada y dependencias. El SDK de Python de SageMaker pasa nuestro script como un entry_point al contenedor, que carga y ejecuta la función de entrenamiento del script proporcionado para entrenar nuestro modelo.
Cuando el entrenamiento esté completo, SageMaker guarda la salida del modelo en el bucket de S3 que proporcionamos como parámetro al trabajo de entrenamiento.
Nuestro código de entrenamiento se adapta del siguiente script de ejemplo de PyTorch. El siguiente fragmento de código muestra la definición del modelo y la función de entrenamiento:
# definir la red
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# entrenar
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
breakEntrenar el modelo
Ahora que hemos configurado nuestro entorno y creado nuestro conjunto de datos de entrada y nuestro script de entrenamiento personalizado, podemos comenzar el entrenamiento del modelo utilizando SageMaker. Utilizamos el estimador de PyTorch en el SDK de Python de SageMaker para iniciar un trabajo de entrenamiento en SageMaker. Pasamos los parámetros requeridos al estimador y llamamos al método fit. Cuando llamamos a fit en el estimador de PyTorch, SageMaker inicia un trabajo de entrenamiento utilizando nuestro script como código de entrenamiento:
from sagemaker.pytorch import PyTorch
output_location = f"s3://{bucket}/{prefix}/output"
print(f"los artefactos de entrenamiento se cargarán en: {output_location}")
hyperparameters={
"batch-size": 100,
"epochs": 1,
"lr": 0.1,
"gamma": 0.9,
"log-interval": 100
}
instance_type = "ml.c4.xlarge"
estimator = PyTorch(
entry_point="train.py",
source_dir="code", # directorio de tu script de entrenamiento
role=execution_role,
framework_version="1.13",
py_version="py39",
instance_type=instance_type,
instance_count=1,
volume_size=250,
output_path=output_location,
hyperparameters=hyperparameters
)
estimator.fit(inputs = {
'training': f"{inputs}",
'testing': f"{inputs}"
})Exportar el modelo entrenado como un modelo ONNX
Después de que el entrenamiento esté completo y nuestro modelo esté guardado en la ubicación predefinida en Amazon S3, exportamos el modelo a un modelo ONNX utilizando el tiempo de ejecución ONNX.
Incluimos el código para exportar nuestro modelo a ONNX en nuestro script de entrenamiento para ejecutarse después de que el entrenamiento esté completo.
PyTorch exporta el modelo a ONNX ejecutando el modelo utilizando nuestra entrada y registrando un seguimiento de los operadores utilizados para calcular la salida. Utilizamos una entrada aleatoria del tipo correcto con la función torch.onnx.export de PyTorch para exportar el modelo a ONNX. También especificamos la primera dimensión en nuestra entrada como dinámica para que nuestro modelo acepte un batch_size variable de entradas durante la inferencia.
def export_to_onnx(model, model_dir, device):
logger.info("Exportando el modelo a ONNX.")
dummy_input = torch.randn(1, 1, 28, 28).to(device)
input_names = [ "input_0" ]
output_names = [ "output_0" ]
path = os.path.join(model_dir, 'mnist-pytorch.onnx')
torch.onnx.export(model, dummy_input, path, verbose=True, input_names=input_names, output_names=output_names,
dynamic_axes={'input_0' : {0 : 'batch_size'}, # ejes de longitud variable
'output_0' : {0 : 'batch_size'}})ONNX es un formato estándar abierto para modelos de aprendizaje profundo que permite la interoperabilidad entre frameworks de aprendizaje profundo como PyTorch, Microsoft Cognitive Toolkit (CNTK), y más. Esto significa que puedes usar cualquiera de estos frameworks para entrenar el modelo y posteriormente exportar los modelos pre-entrenados en formato ONNX. Al exportar el modelo a ONNX, obtienes el beneficio de una selección más amplia de dispositivos y plataformas para implementar el modelo.
Descargar y extraer los artefactos del modelo
El modelo ONNX que nuestro script de entrenamiento ha guardado ha sido copiado por SageMaker a Amazon S3 en la ubicación de salida que especificamos al iniciar el trabajo de entrenamiento. Los artefactos del modelo se almacenan como un archivo de compresión llamado model.tar.gz. Descargamos este archivo de compresión a un directorio local en nuestra instancia de Studio notebook y extraemos los artefactos del modelo, es decir, el modelo ONNX.
import tarfile
archivo_modelo_local = 'model.tar.gz'
bucket_modelo, clave_modelo = estimator.model_data.split('/',2)[-1].split('/',1)
s3 = boto3.client("s3")
s3.download_file(bucket_modelo, clave_modelo, archivo_modelo_local)
modelo_tar = tarfile.open(archivo_modelo_local)
nombre_archivo_modelo = modelo_tar.next().name
modelo_tar.extractall('.')
modelo_tar.close()Validar el modelo ONNX
El modelo ONNX se exporta a un archivo llamado mnist-pytorch.onnx en nuestro script de entrenamiento. Después de haber descargado y extraído este archivo, opcionalmente podemos validar el modelo ONNX usando el módulo onnx.checker. La función check_model en este módulo verifica la consistencia de un modelo. Se lanza una excepción si la prueba falla.
import onnx
modelo_onnx = onnx.load("mnist-pytorch.onnx")
onnx.checker.check_model(modelo_onnx)Empaquetar el modelo y el código de inferencia
Para este post, utilizamos el despliegue .zip para Azure Functions. En este método, empaquetamos nuestro modelo, el código de acompañamiento y la configuración de Azure Functions en un archivo .zip y lo publicamos en Azure Functions. El siguiente código muestra la estructura de directorios de nuestro paquete de despliegue:
mnist-onnx ├── function_app.py ├── model │ └── mnist-pytorch.onnx └── requirements.txt
Listar las dependencias
Listamos las dependencias para nuestro código de inferencia en el archivo requirements.txt en la raíz de nuestro paquete. Este archivo se utiliza para construir el entorno de Azure Functions cuando publicamos el paquete.
azure-functions numpy onnxruntime
Escribir el código de inferencia
Utilizamos Python para escribir el siguiente código de inferencia, utilizando la biblioteca ONNX Runtime para cargar nuestro modelo y ejecutar la inferencia. Esto indica a la aplicación de Azure Functions que ponga el punto de conexión disponible en la ruta relativa /classify.
import logging
import azure.functions as func
import numpy as np
import os
import onnxruntime as ort
import json
app = func.FunctionApp()
def preprocess(input_data_json):
# convertir los datos JSON en la entrada de tensor
return np.array(input_data_json['data']).astype('float32')
def run_model(model_path, req_body):
session = ort.InferenceSession(model_path)
input_data = preprocess(req_body)
logging.info(f"La forma de los datos de entrada es {input_data.shape}.")
input_name = session.get_inputs()[0].name # obtener el id de la primera entrada del modelo
try:
result = session.run([], {input_name: input_data})
except (RuntimeError) as e:
print("Forma={0} y error={1}".format(input_data.shape, e))
return result[0]
def get_model_path():
d=os.path.dirname(os.path.abspath(__file__))
return os.path.join(d , './model/mnist-pytorch.onnx')
@app.function_name(name="mnist_classify")
@app.route(route="classify", auth_level=func.AuthLevel.ANONYMOUS)
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('La función de gatillo HTTP de Python ha procesado una solicitud.')
# Obtener el valor img del post.
try:
req_body = req.get_json()
except ValueError:
pass
if req_body:
# ejecutar el modelo
result = run_model(get_model_path(), req_body)
# mapear la salida a enteros y devolver una cadena de resultado.
digits = np.argmax(result, axis=1)
logging.info(type(digits))
return func.HttpResponse(json.dumps({"digits": np.array(digits).tolist()}))
else:
return func.HttpResponse(
"Esta función de gatillo HTTP se ha ejecutado correctamente.",
status_code=200
)Implementar el modelo en Azure Functions
Ahora que hemos empaquetado el código en el formato .zip requerido, estamos listos para publicarlo en Azure Functions. Hacemos esto utilizando Azure CLI, una utilidad de línea de comandos para crear y administrar recursos de Azure. Instala Azure CLI con el siguiente código:
!pip install -q azure-cliLuego, completa los siguientes pasos:
-
Inicia sesión en Azure:
!az login -
Configura los parámetros de creación de recursos:
import random random_suffix = str(random.randint(10000,99999)) resource_group_name = f"multicloud-{random_suffix}-rg" storage_account_name = f"multicloud{random_suffix}" location = "ukwest" sku_storage = "Standard_LRS" functions_version = "4" python_version = "3.9" function_app = f"multicloud-mnist-{random_suffix}" -
Usa los siguientes comandos para crear la aplicación de Azure Functions junto con los recursos previos necesarios:
!az group create --name {resource_group_name} --location {location} !az storage account create --name {storage_account_name} --resource-group {resource_group_name} --location {location} --sku {sku_storage} !az functionapp create --name {function_app} --resource-group {resource_group_name} --storage-account {storage_account_name} --consumption-plan-location "{location}" --os-type Linux --runtime python --runtime-version {python_version} --functions-version {functions_version} -
Configura las Azure Functions para que cuando implementemos el paquete de Functions, se use el archivo
requirements.txtpara construir nuestras dependencias de aplicación:!az functionapp config appsettings set --name {function_app} --resource-group {resource_group_name} --settings @./functionapp/settings.json -
Configura la aplicación de Functions para ejecutar el modelo de Python v2 y realizar una compilación en el código que recibe después de la implementación .zip:
{ "AzureWebJobsFeatureFlags": "EnableWorkerIndexing", "SCM_DO_BUILD_DURING_DEPLOYMENT": true } -
Después de tener el grupo de recursos, el contenedor de almacenamiento y la aplicación de Functions con la configuración correcta, publica el código en la aplicación de Functions:
!az functionapp deployment source config-zip -g {resource_group_name} -n {function_app} --src {function_archive} --build-remote true
Probar el modelo
Hemos implementado el modelo de ML en Azure Functions como un desencadenador HTTP, lo que significa que podemos usar la URL de la aplicación de Functions para enviar una solicitud HTTP a la función para invocarla y ejecutar el modelo.
Para preparar la entrada, descarga los archivos de imágenes de prueba del bucket de archivos de ejemplo de SageMaker y prepara un conjunto de muestras en el formato requerido por el modelo:
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
test_dataset = datasets.MNIST(root='../data', download=True, train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=True)
test_features, test_labels = next(iter(test_loader))Usa la biblioteca requests para enviar una solicitud POST al punto de referencia de inferencia con las entradas de muestra. El punto de referencia de inferencia tiene el formato que se muestra en el siguiente código:
import requests, json
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
url = f"https://{function_app}.azurewebsites.net/api/classify"
response = requests.post(url,
json.dumps({"data":to_numpy(test_features).tolist()})
)
predictions = json.loads(response.text)['digits']Limpiar
Cuando hayas terminado de probar el modelo, elimina el grupo de recursos junto con los recursos contenidos, incluido el contenedor de almacenamiento y la aplicación de Functions:
!az group delete --name {resource_group_name} --yesAdemás, se recomienda apagar los recursos inactivos dentro de SageMaker Studio para reducir los costos. Para obtener más información, consulta Cómo ahorrar costos apagando automáticamente los recursos inactivos dentro de Amazon SageMaker Studio.
Conclusión
En esta publicación, mostramos cómo puedes construir y entrenar un modelo de aprendizaje automático con SageMaker y desplegarlo en otro proveedor de servicios en la nube. En la solución, utilizamos un cuaderno de SageMaker Studio, pero para cargas de trabajo de producción, recomendamos utilizar MLOps para crear flujos de trabajo de entrenamiento repetibles y acelerar el desarrollo y despliegue del modelo.
Esta publicación no mostró todas las formas posibles de desplegar y ejecutar un modelo en un entorno multicloud. Por ejemplo, también puedes empaquetar tu modelo en una imagen de contenedor junto con el código de inferencia y las bibliotecas de dependencia para ejecutar el modelo como una aplicación en contenedor en cualquier plataforma. Para obtener más información sobre este enfoque, consulta Cómo desplegar aplicaciones en contenedor en un entorno multicloud utilizando Amazon CodeCatalyst. El objetivo de esta publicación es mostrar cómo las organizaciones pueden utilizar las capacidades de inteligencia artificial/aprendizaje automático de AWS en un entorno multicloud.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Cómo convertirse en un científico de datos en Estados Unidos?
- El camino hacia una IA creíble y orientada al valor comienza haciendo las preguntas correctas.
- Crea una aplicación sin servidor rápidamente con Zipper Escribe TypeScript, Descarga todo lo demás
- Principales artículos importantes de Visión por Computadora de la semana del 11/9 al 17/9
- Cómo la IA está generando cambios en las salas de redacción de todo el mundo
- ¿Puede ser más rentable la segmentación de video? Conoce DEVA Un enfoque de segmentación de video desacoplado que ahorra en anotaciones y generaliza en múltiples tareas.
- Revolucionando la personalización de modelos 3D utilizando inteligencia artificial Investigadores del MIT desarrollaron una interfaz fácil de usar para ajustes estéticos sin afectar la funcionalidad




