Trabajando con MS SQL Server en Julia
Trabajando con MS SQL Server en Julia' -> 'Trabajando con SQL Server en Julia
Es hora de potenciar tu flujo de trabajo de análisis de datos
Las bases de datos SQL son uno de los software más ampliamente desplegados en todo el mundo. Forman el núcleo de numerosas aplicaciones que van desde la analítica de datos empresariales hasta la predicción del clima. Actualmente existen varias implementaciones cliente-servidor, y el SQL Server de Microsoft es una de ellas. La edición para desarrolladores completamente funcional está disponible de forma gratuita. Se ejecuta en Windows, Linux y a través de Docker.
Los científicos de datos a menudo necesitan interactuar con datos almacenados en bases de datos SQL. Si bien es fácil encontrar guías sobre cómo hacer esto con lenguajes como Python, los tutoriales para Julia son bastante escasos. Por lo tanto, en este artículo, me enfocaré en cómo trabajar con SQL Server utilizando Julia. El código de ejemplo se genera utilizando un cuaderno Pluto con Julia 1.9.1 ejecutándose en Linux (Elementary OS).
Requisitos previos
- SQL Server 2022
Necesitas tener un servidor SQL ejecutándose localmente. La forma más sencilla de configurarlo es a través de Docker. Las instrucciones para SQL Server 2022 se proporcionan aquí. Para verificar si el contenedor de Docker está en ejecución, utiliza el siguiente comando:
watch -n 2 sudo docker ps -aEsto se actualizará cada 2 segundos, y la columna STATUS debería mostrar algo como ‘Up X minutos’, donde X es el tiempo transcurrido desde que se inició el contenedor.
- Optimiza eficazmente tu modelo de regresión con ajuste de hiperparámetros bayesianos
- Aprendizaje automático con efectos mixtos para datos longitudinales y de panel con GPBoost (Parte III)
- Explora el poder de las imágenes dinámicas con Text2Cinemagraph una nueva herramienta de IA para la generación de cinemagraphs a partir de indicaciones de texto
2. Controlador ODBC de Microsoft 17 para Linux
Las instrucciones se proporcionan aquí. No pude conectarme a la base de datos utilizando el controlador más nuevo 18, por lo tanto, no puedo recomendar su uso.
3. Utilidad sqlcmd (opcional)
La utilidad sqlcmd te permite ingresar declaraciones Transact-SQL, y es excelente para probar si todo funciona según lo esperado. Sigue las instrucciones aquí.
Carga de paquetes
Se necesitarán los siguientes paquetes de Julia. Al utilizar un cuaderno Pluto, su administrador de paquetes incorporado los descargará e instalará automáticamente por ti.
using ODBC, DBInterface, DataFramesVerificación de controladores
Los controladores de Conectividad Abierta de Bases de Datos (ODBC) nos permiten realizar conexiones con el servidor SQL. Usando el paquete ODBC.jl, podemos verificar los controladores actualmente disponibles en nuestro sistema:

También es posible instalar un controlador una vez que se conoce su ubicación.

Para eliminar un controlador, utiliza:

Agregar conexión
Usando una cadena de conexión completa, ahora podemos conectarnos al servidor SQL que se está ejecutando localmente, que se configuró anteriormente. Se necesitan la dirección IP, el puerto, el nombre de la base de datos existente, el ID de usuario y la contraseña. Ten en cuenta que en caso de que se desconozca el nombre de la base de datos, podemos conectarnos a ‘master’ ya que este nombre siempre existe de forma predeterminada.

Listar todas las bases de datos existentes
Usando el objeto conn_master, ahora podemos ejecutar consultas en el servidor. Veamos todas las bases de datos.
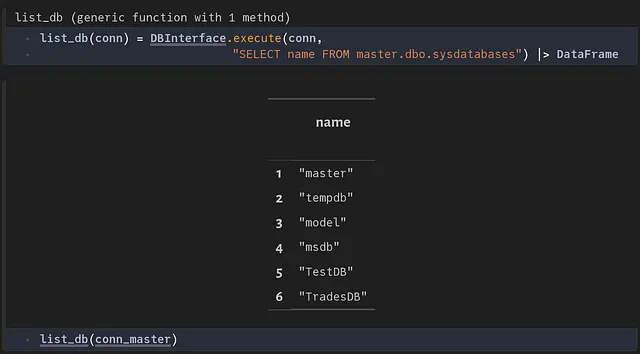
Crear una nueva base de datos
Para crear una nueva base de datos, primero debemos verificar si el nombre ya existe usando la función list_db. Si no existe, entonces la creamos como se muestra a continuación con ‘FruitsDB’ como ejemplo.

Listando todas las bases de datos nuevamente, podemos verificar que ‘FruitsDB’ ha sido creada.

Crear una nueva tabla
Las bases de datos de SQL Server pueden contener varias tablas, que son simplemente una colección ordenada de datos. Una tabla en sí misma es una colección de filas, también conocidas como registros. Antes de poder comenzar a poblar una tabla, primero debemos crearla dentro de una base de datos existente. Como ejemplo, creemos una tabla llamada ‘Price_and_Origin’ dentro de ‘FruitsDB’. Esta tabla contendrá tres columnas: Nombre (String), Precio (Float) y Origen (String). Ten en cuenta que VARCHAR(50) se utiliza para denotar datos de cadena de tamaño variable. 50 es el tamaño en bytes y para una codificación de un solo byte también representa la longitud de la cadena.
Agregar a la nueva tabla
Una vez que una tabla existe, podemos agregar datos a ella. La forma más sencilla es utilizar DataFrame como origen. Recuerda que nuestra tabla ‘Price_and_Origin’ espera tres columnas con nombre, precio y origen. Por lo tanto, podemos usar algunos datos ficticios como se muestra a continuación:
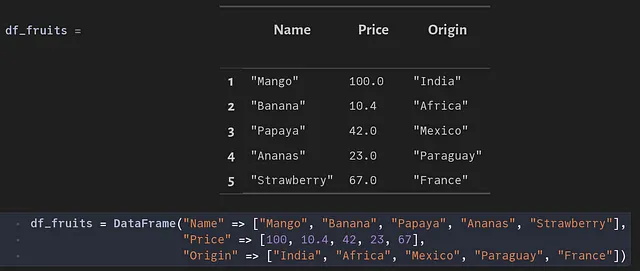
Para insertar valores, podemos utilizar la función DBInterface.executemany, que permite pasar múltiples valores en secuencia. Esto se puede hacer como se muestra en la función a continuación. La cláusula finally asegura que la conexión a la base de datos se cierre utilizando la función DBInterface.close!. Esta es generalmente una buena práctica, que ayuda a evitar reutilizar accidentalmente la misma conexión para otra cosa.

Verifiquemos si la base de datos se ha poblado como esperábamos. Primero establecemos una conexión ‘conn_fruit’ para conectarnos a ‘FruitsDB’ en el servidor SQL. Luego podemos seleccionar todas las entradas de la tabla ‘Price_and_Origin’ y pasarlas a un DataFrame.
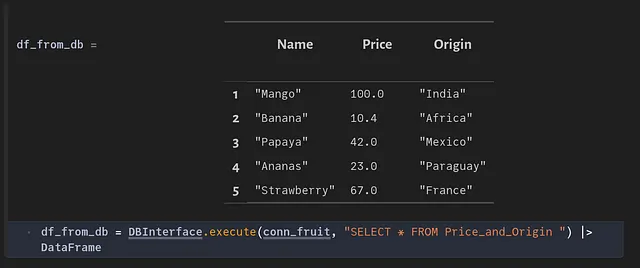
Actualizando una tabla
Siguiendo la misma secuencia que se muestra en la sección anterior, ahora se puede actualizar la base de datos con nuevos datos.

Verifiquemos si los nuevos datos están presentes en la base de datos.
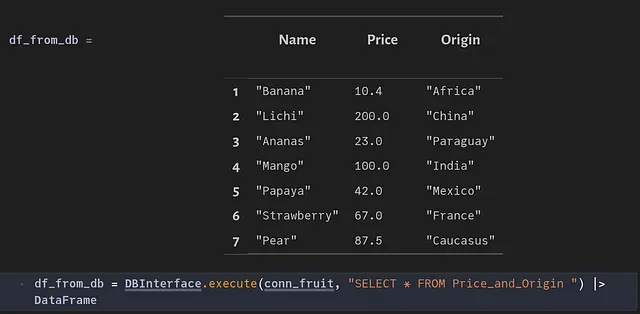
Eliminando duplicados
Volver a ejecutar la función add_to_fruit_table anterior agregaría filas duplicadas a la tabla.
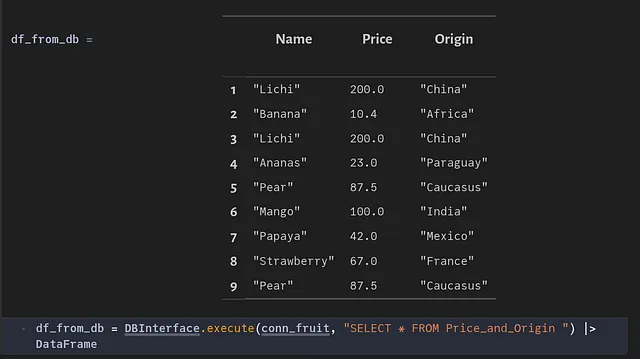
Usando una expresión de tabla común (CTE), podemos eliminar filas duplicadas de una tabla dada. La siguiente función nos ayuda a lograr esto:

Verificar si las filas son únicas.
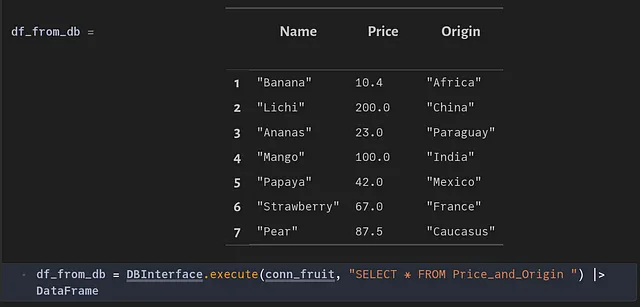
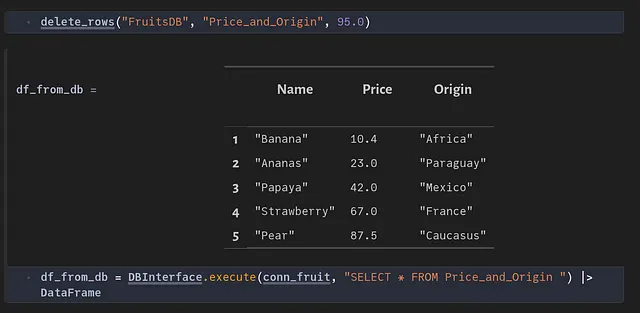
Eliminar registros
A menudo es necesario eliminar entradas (que coincidan con una determinada condición) de la tabla dentro de una base de datos. Por ejemplo, podemos eliminar todas las frutas cuyo precio sea > 95 como se muestra a continuación:
Eliminar tabla
Usando la instrucción DROP dentro de la función DBInterface.execute, se puede eliminar una tabla. El resto de la función permanecerá igual que delete_rows.
DBInterface.execute(conn_db, "DROP TABLE $table_name")Conclusión
La función DBInterface.execute acepta declaraciones SQL válidas como entrada. Por lo tanto, es posible ejecutar todo tipo de consultas según lo descrito aquí, además de lo que ya se ha presentado. Como se mostró anteriormente, los resultados de una consulta se pueden pasar fácilmente a un destino de DataFrame de Julia, que luego se puede usar para realizar operaciones adicionales.
Los paquetes ODBC.jl y DBInterface.jl se mantienen activamente y parecen integrarse bien con los flujos de trabajo existentes, especialmente si implican el uso de DataFrames. Esto abre emocionantes nuevas posibilidades para realizar análisis y visualización de datos usando Julia. Espero que haya encontrado útil este ejercicio. ¡Gracias por su tiempo! Conéctese conmigo en LinkedIn o visite mi sitio web impulsado por Web 3.0.
Referencias
- https://odbc.juliadatabases.org/stable/#Getting-Started
- https://juliadatabases.org/DBInterface.jl/dev/
- https://www.w3schools.com/sql/default.asp
- https://learn.microsoft.com/en-us/sql/?view=sql-server-linux-ver16
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Introducción práctica a los modelos de Transformer BERT
- Principios efectivos de ingeniería de indicaciones para la aplicación de IA generativa
- Esta es la razón por la que deberías leer esto antes de usar Pandas en la limpieza de datos
- ChatGPT destronado cómo Claude se convirtió en el nuevo líder de IA
- Justin McGill, Fundador y CEO de Content at Scale – Serie de entrevistas
- Conoce a Tongyi Qianwen, el competidor de ChatGPT de Alibaba un modelo de lenguaje grande que se integrará en sus altavoces inteligentes Tmall Genie y en la plataforma de mensajería laboral DingTalk.
- Sobre el aprendizaje en presencia de grupos subrepresentados






