Series de tiempo para el cambio climático Pronóstico de demanda origen-destino
Time series for climate change and origin-destination demand forecasting.
Minería de datos de vehículos flotantes para enfrentar el cambio climático
Este es el Parte 8 de la serie Series de tiempo para el cambio climático. Lista de artículos:
- Parte 1: Pronóstico de energía eólica
- Parte 2: Pronóstico de irradiación solar
- Parte 3: Pronóstico de grandes olas oceánicas
- Parte 4: Pronóstico de demanda de energía
- Parte 5: Pronóstico de eventos climáticos extremos
- Parte 6: Uso de aprendizaje profundo para agricultura de precisión
- Parte 7: Reducción del desperdicio de alimentos con clustering
Datos de vehículos flotantes para modelado de movilidad
La minería de datos de vehículos flotantes es una tarea clave en los sistemas de transporte inteligentes. Los datos de vehículos flotantes se refieren a los datos recopilados por vehículos equipados con dispositivos GPS. Estos proporcionan información sobre la ubicación y velocidad de los vehículos.
Comprender los patrones de movilidad dentro de las ciudades es una tarea importante en el transporte. Por ejemplo, ayuda a reducir la congestión y la actividad de transporte en general. Menos tiempo en el tráfico significa menos gases de efecto invernadero emitidos. Por lo tanto, los modelos precisos tienen un impacto positivo en el cambio climático.
La amplia difusión de los dispositivos GPS ha producido muchos conjuntos de datos relacionados con la movilidad. Pero, aprender de los datos GPS es un problema desafiante. Las dependencias espaciales son complicadas pero fundamentales para capturar. También hay dependencias temporales, por ejemplo, las horas pico. Los patrones de movilidad también difieren según si es un día hábil o no.
- El Desafío de Ver la Imagen Completa de la Inteligencia Artificial
- Conoce AnythingLLM Una Aplicación Full-Stack Que Transforma Tu Contenido en Datos Enriquecidos para Mejorar las Interacciones con Modelos de Lenguaje Amplio (LLMs)
- Teoría de Recursos Donde las Matemáticas se Encuentran con la Industria.
Estimación de flujo de origen-destino

Los datos de vehículos flotantes ofrecen muchas posibilidades para el modelado de movilidad. Una de estas posibilidades es el problema de conteo de flujo de origen-destino (OD).
El conteo de flujo OD se refiere a la estimación de cuántos vehículos atraviesan una subregión dada hacia otra en un período determinado. Esta tarea es relevante por varias razones. Las compañías de taxis pueden asignar su flota dinámicamente de acuerdo con la demanda esperada en una zona particular.
Práctica: Pronóstico de demanda OD en San Francisco
En el resto de este artículo, pronosticaremos la demanda de pasajeros en taxis en San Francisco, EE. UU. Abordaremos este problema como una tarea de conteo de flujo OD.
El código completo utilizado en este tutorial está disponible en Github:
- https://github.com/vcerqueira/tsa4climate
Conjunto de datos
Utilizaremos un conjunto de datos recopilado por una flota de taxis en San Francisco, California, EE. UU. El conjunto de datos contiene datos GPS de 536 taxis durante un período de 21 días. En total, hay 121 millones de trazas GPS divididas en 464045 viajes. Puede consultar la referencia [1] para obtener más detalles.
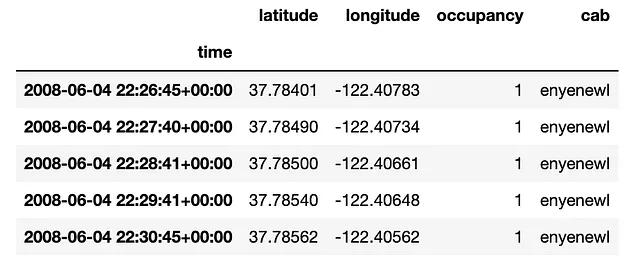
En cada paso de tiempo y para cada taxi, tenemos información sobre sus coordenadas y si un pasajero lo ocupa.
Definición del problema
Nuestro objetivo es modelar adónde se mueve la gente dada su origen. La estimación del flujo OD se puede dividir en cuatro sub-tareas:
- Descomposición de la cuadrícula espacial
- Selección de pares origen-destino
- Discretización temporal
- Modelado y pronóstico
Sumergámonos en cada problema en orden.
Descomposición de la cuadrícula espacial
La descomposición espacial es un paso de preprocesamiento común para la estimación del flujo de recuento OD. La idea es dividir el mapa en celdas de cuadrícula, que representan una pequeña parte de la ciudad. Luego, podemos contar cuántas personas atraviesan cada posible par de celdas de cuadrícula.
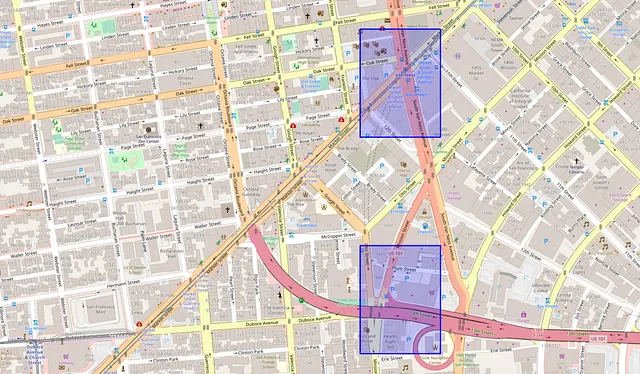
En este estudio de caso, dividimos el mapa de la ciudad en 10000 celdas de cuadrícula de la siguiente manera:
import pandas as pdfrom src.spatial import SpatialGridDecomposition, prune_coordinates# leyendo el conjunto de datos trips_df = pd.read_csv('trips.csv', parse_dates=['time'])# eliminando los valores atípicos de las coordenadastrips_df = prune_coordinates(trips_df=trips_df, lhs_thr=0.01, rhs_thr=0.99)# descomposición de la cuadrícula con 10000 celdasgrid = SpatialGridDecomposition(n_cells=10000)# estableciendo el cuadro delimitadorgrid.set_bounding_box(lat=trips_df.latitude, lon=trips_df.longitude)# descomposición de la cuadrículagrid.grid_decomposition()En el código anterior, eliminamos las ubicaciones atípicas. Estas pueden ocurrir debido a fallas del GPS.
Obtención de los viajes más populares
Después del proceso de descomposición espacial, obtenemos el origen y destino de cada viaje en taxi cuando están ocupados por un pasajero.
from src.spatial import ODFlowCounts# obteniendo las coordenadas de origen y destino para cada grupodf_group = trips_df.groupby(['cab', 'cab_trip_id'])trip_points = df_group.apply(lambda x: ODFlowCounts.get_od_coordinates(x))trip_points.reset_index(drop=True, inplace=True)La idea es reconstruir el conjunto de datos para que contenga la siguiente información: origen, destino y marca de tiempo de origen de cada viaje de pasajeros. Estos datos forman la base para nuestro modelo de recuento de flujo de origen-destino (OD).
Estos datos nos permiten contar cuántos viajes van de la celda A a la celda B:
# obteniendo el centroide de la celda de origen y destinood_pairs = trip_points.apply(lambda x: ODFlowCounts.get_od_centroids(x, grid.centroid_df), axis=1)Para simplificar, obtenemos los 50 pares de celdas de cuadrícula OD principales con más viajes. Tomar este subconjunto es opcional. Sin embargo, los pares OD con solo unos pocos viajes mostrarán una demanda dispersa a lo largo del tiempo, lo que es difícil de modelar. Además, los viajes con poca demanda pueden no ser útiles desde el punto de vista de la gestión de flotas.
flow_count = od_pairs.value_counts().reset_index()flow_count = flow_count.rename({0: 'count'}, axis=1)top_od_pairs = flow_count.head(50)Discretización temporal
Después de encontrar los pares OD principales en términos de demanda, los discretizamos en el tiempo. Esto se hace contando cuántos viajes ocurren en cada hora para cada par superior dado. Esto se puede hacer de la siguiente manera:
# preparando los datos trip_points = pd.concat([trip_points, od_pairs], axis=1)trip_points = trip_points.sort_values('time_start')trip_points.reset_index(drop=True, inplace=True)# obteniendo las celdas de origen-destino para cada viaje y tiempo de inicio del origentrip_starts = []for i, pair in top_od_pairs.iterrows(): origin_match = trip_points['origin'] == pair['origin'] dest_match = trip_points['destination'] == pair['destination'] od_trip_df = trip_points.loc[origin_match & dest_match, :] od_trip_df.loc[:, 'pair'] = i trip_starts.append(od_trip_df[['time_start', 'time_end', 'pair']])trip_starts_df = pd.concat(trip_starts, axis=0).reset_index(drop=True)# más procesamiento de datosod_count_series = {}for pair, data in trip_starts_df.groupby('pair'): new_index = pd.date_range( start=data.time_start.values[0], end=data.time_end.values[-1], freq='H', tz='UTC' ) od_trip_counts = pd.Series(0, index=new_index) for _, r in data.iterrows(): dt = r['time_start'] - new_index dt_secs = dt.total_seconds() valid_idx = np.where(dt_secs >= 0)[0] idx = valid_idx[dt_secs[valid_idx].argmin()] od_trip_counts[new_index[idx]] += 1 od_count_series[pair] = od_trip_counts.resample('H').mean()od_df = pd.DataFrame(od_count_series)Esto lleva a un conjunto de series temporales, una para cada par OD superior. Aquí está el gráfico de series de tiempo para cuatro pares de ejemplo:
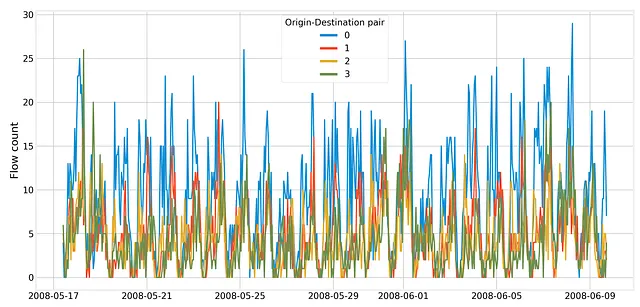
Las series de tiempo muestran una estacionalidad diaria, que es impulsada principalmente por las horas punta.
Pronóstico
El conjunto de series de tiempo que resulta de la discretización temporal se puede utilizar para el pronóstico. Podemos construir un modelo para pronosticar cuántos pasajeros desean hacer el viaje en relación con un par OD dado.
Así es como se puede hacer esto para un par OD de ejemplo:
from pmdarima.arima import auto_arima# obteniendo el primer par OD como ejemploseries = od_df[0].dropna()# ajustando un modelo ARIMAmodel = auto_arima(y=series, m=24)Arriba, construimos un modelo de pronóstico basado en ARIMA. El modelo pronostica la demanda de pasajeros en la próxima hora dada la demanda reciente pasada. Usamos un método ARIMA por simplicidad, pero se pueden usar otros enfoques como el aprendizaje profundo.
Avanzando con Redes Neuronales de Grafo
El enfoque mencionado anteriormente es una manera simple pero efectiva de resolver problemas de recuento de flujo OD. Pero, considera cada par OD como una serie temporal separada.
En realidad, cada par está correlacionado con los pares OD vecinos o las carreteras circundantes. Debido a esto, las redes neuronales de grafo se han utilizado cada vez más para pronosticar las condiciones del tráfico. La red de carreteras se modela como un grafo, y las redes neuronales pueden capturar interacciones complejas en ella. Puede consultar este ejemplo de Keras para aprender cómo implementar este tipo de método.
Conclusiones clave
- La modelización de la movilidad es una tarea importante en los sistemas de transporte inteligentes;
- Los modelos de recuento de flujo OD pueden ayudar a reducir el tráfico dentro de las ciudades, lo que disminuye la emisión de gases de efecto invernadero;
- Puede abordar problemas de recuento de flujo OD con un enfoque basado en la descomposición espacial y la discretización temporal. Esto da como resultado un conjunto de series de tiempo para cada par OD, que se puede utilizar para el pronóstico.
¡Gracias por leer y nos vemos en la próxima historia!
Referencias
[1] Conjunto de datos de rastros de movilidad de taxis en San Francisco, EE. UU. (Licencia CC BY 4.0)
[2] Moreira-Matias, Luís, et al. “Estimación de matriz OD en evolución temporal utilizando flujos de datos de GPS de alta velocidad”. Expert systems with Applications 44 (2016): 275–288.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Funciones de Ventana Un conocimiento imprescindible para ingenieros de datos y científicos de datos.
- Haz que tus gráficos sean excelentes con UTF-8.
- Haz que cada dólar de marketing cuente con la ciencia de datos.
- Cómo medir el desvío en las incrustaciones de ML
- Incorpore SageMaker Autopilot en sus procesos de MLOps usando un Proyecto personalizado de SageMaker.
- Habilidades Suaves Superan las Habilidades Técnicas en Análisis de Datos.
- Utilizando pykrige y matplotlib para la visualización espacial de variaciones geológicas.



