Tres desafíos en la implementación de modelos generativos en producción
'Three challenges in implementing generative models in production'.
Cómo implementar modelos de lenguaje y difusión grandes para tu producto sin asustar a los usuarios.

OpenAI, Google, Microsoft, Midjourney, StabilityAI, CharacterAI y muchos más: todos compiten por ofrecer la mejor solución para modelos de texto a texto, texto a imagen, imagen a imagen e imagen a texto.
La razón es simple: el vasto campo de oportunidades que ofrece este espacio; después de todo, no solo se trata de entretenimiento, sino también de utilidad que antes era imposible desbloquear. Desde mejores motores de búsqueda hasta campañas publicitarias más impresionantes y personalizadas, y chatbots amigables, como el MyAI de Snap.
Y aunque este espacio es muy fluido, con muchos componentes en movimiento y puntos de control de modelos lanzados cada pocos días, hay desafíos a los que toda empresa que trabaja con IA generativa busca dar respuesta.
Aquí, hablaré sobre los principales desafíos y cómo abordarlos al implementar modelos generativos en producción. Si bien hay muchos tipos diferentes de modelos generativos, en este artículo me centraré en los avances recientes en modelos basados en difusión y GPT. Sin embargo, muchos de los temas discutidos aquí también se aplicarían a otros modelos.
- Construyendo PCA desde cero
- Cómo construir un pipeline de detección de cambios de datos completamente automatizado
- Fundamentos de Estadística para Científicos de Datos y Analistas
¿Qué es la IA generativa?
La IA generativa describe ampliamente un conjunto de modelos que pueden generar nuevo contenido. Los conocidos y ampliamente utilizados Generative Adversarial Networks (GAN) lo hacen aprendiendo la distribución de datos reales y generando variabilidad a partir del ruido agregado.
El reciente auge de la IA generativa proviene de que los modelos alcanzan calidad a nivel humano a gran escala. La razón por la que se logró esta transformación es simple: ahora tenemos suficiente capacidad informática (de ahí el aumento meteórico del precio de las acciones de NVIDIA) para entrenar y mantener modelos con la suficiente capacidad para lograr resultados de alta calidad. El avance actual se impulsa mediante dos arquitecturas base: los modelos transformadores y los modelos de difusión.
Tal vez el avance más significativo del último año fue el ChatGPT de OpenAI, un modelo generativo basado en texto, que cuenta con 175 mil millones de parámetros en una de las últimas versiones, el ChatGPT-3.5, que tiene una base de conocimientos suficiente para mantener conversaciones sobre diversos temas. Si bien ChatGPT es un modelo de una sola modalidad, ya que solo admite texto, los modelos multimodales pueden tomar varios tipos de entrada y generar varios tipos de salida, como texto e imágenes.
Las arquitecturas multimodales de imagen a texto y texto a imagen operan en un espacio latente compartido por los conceptos textuales e imágenes. El espacio latente se obtiene mediante el entrenamiento en una tarea que requiere ambos conceptos (por ejemplo, descripción de imágenes) penalizando la distancia en el espacio latente entre el mismo concepto en dos modalidades diferentes. Una vez obtenido este espacio latente, se puede reutilizar para otras tareas.
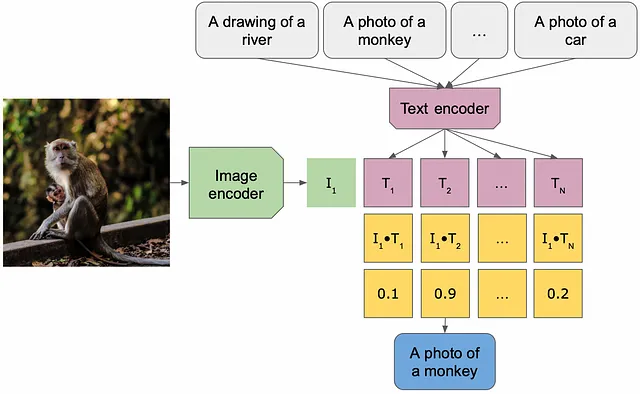
Algunos modelos generativos destacados lanzados este año son DALLE/Stable-Diffusion (implementación de texto a imagen / imagen a imagen) y BLIP (implementación de imagen a texto). Los modelos DALLE toman como entrada un texto o una imagen y generan una imagen como respuesta, mientras que los modelos basados en BLIP pueden responder preguntas sobre el contenido de la imagen.
Desafíos y soluciones
Desafortunadamente, no existe almuerzo gratis cuando se trata de aprendizaje automático, y los modelos generativos a gran escala se encuentran con algunos desafíos cuando se trata de su implementación en producción, como el tamaño y la latencia del modelo, el sesgo y la imparcialidad, y la calidad de los resultados generados.
Tamaño del modelo y latencia
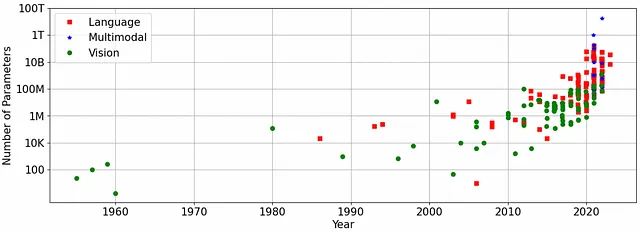
Los modelos GenAI de última generación son enormes. Por ejemplo, los modelos LLaMA de Meta para texto a texto tienen entre 7 y 65 mil millones de parámetros, y ChatGPT-3.5 tiene 175 mil millones de parámetros. Estos números están justificados: en un mundo simplificado, la regla general es que cuanto más grande es el modelo, más datos se utilizan para el entrenamiento y mejor es la calidad.
Los modelos de texto a imagen, aunque más pequeños, siguen siendo significativamente más grandes que sus predecesores de Redes Generativas Adversarias: las checkpoints de Stable Diffusion 1.5 tienen casi 1 mil millones de parámetros (ocupando más de tres gigabytes de espacio), y DALLE 2.0 tiene 3.5 mil millones de parámetros. Pocas GPUs tendrían suficiente memoria para mantener estos modelos y normalmente se necesitaría una flota para mantener un solo modelo grande, lo cual puede volverse muy costoso muy pronto, sin mencionar la implementación de estos modelos en dispositivos móviles.
Los modelos generativos tardan tiempo en producir la salida. Para algunos, la latencia se debe a su tamaño: propagar la señal a través de varios miles de millones de parámetros, incluso en una flota de GPUs, lleva tiempo, mientras que para otros, se debe a la naturaleza iterativa de producir resultados de alta calidad. Los modelos de difusión, en su configuración predeterminada, tardan 50 pasos en generar una imagen, reducir el número de pasos deteriora la calidad de la imagen resultante.
Soluciones: Reducir el tamaño del modelo a menudo ayuda a que sea más rápido: la destilación, compresión y cuantificación del modelo también reducirían la latencia. Qualcomm ha allanado el camino comprimiendo el modelo de difusión estable lo suficiente como para ser implementado en dispositivos móviles. Recientemente se han lanzado versiones más pequeñas, destiladas y mucho más rápidas de Stable Diffusion (tiny y small).
La optimización específica del modelo también puede ayudar a acelerar la inferencia: para los modelos de difusión, se podría generar una salida de baja resolución y luego ampliarla o utilizar un número menor de pasos y un calendario diferente, ya que algunos funcionan mejor con un número menor de pasos, mientras que otros generan una calidad superior con un mayor número de iteraciones. Por ejemplo, Snap mostró recientemente que ocho pasos serían suficientes para crear resultados de alta calidad con Stable Diffusion 1.5, utilizando diversas optimizaciones durante el entrenamiento.
Compilar el modelo con herramientas como tensorrt de NVIDIA y torch.compile podría reducir sustancialmente la latencia con un esfuerzo de ingeniería mínimo.
En el límite: implementando aplicaciones de aprendizaje profundo en dispositivos móviles
Técnicas para encontrar el equilibrio entre eficiencia y precisión en redes neuronales profundas en dispositivos con restricciones
towardsdatascience.com
Sesgo, equidad y seguridad
¿Alguna vez has intentado romper ChatGPT? Muchos han tenido éxito al descubrir sesgos y problemas de equidad, y felicitaciones a OpenAI por hacer un gran trabajo en abordar estos problemas. Sin correcciones a gran escala, los chatbots pueden crear problemas del mundo real al propagar ideas y comportamientos perjudiciales y peligrosos.
Hay ejemplos en el ámbito político, por ejemplo, ChatGPT se negó a crear poemas sobre Trump pero creó uno sobre Biden, igualdad de género y empleos en particular, lo que implica que algunas profesiones son para hombres y otras para mujeres y razas específicas.
Al igual que los modelos de texto a texto, los modelos de texto a imagen e imagen a texto también contienen sesgos y problemas de equidad. El modelo Stable Diffusion 2.1, cuando se le pide generar imágenes de un médico y una enfermera, produce un hombre blanco para el primero y una mujer blanca para el segundo. Curiosamente, el sesgo depende del país especificado en la indicación, por ejemplo, un médico japonés o una enfermera brasileña.


Jugando con el modelo BLIP de imagen a texto y alimentando una imagen de una persona con sobrepeso y doctores de ambos géneros, obtuve descripciones de imágenes con prejuicios y juicios de valor: “un hombre gordo”, “un médico hombre”, “una mujer con bata de laboratorio y estetoscopio”.


![Imágenes generadas por el autor con Stable Diffusion 2.1 y leyendas generadas con el modelo BLIP de izquierda a derecha [1] un hombre gordo comiendo un helado; [2] un médico hombre con bata blanca y corbata; [3] una mujer con bata blanca y estetoscopio alrededor del cuello. Las imágenes son generadas por el autor con la interfaz SD 2.1 y pasadas a través de BLIP.](https://miro.medium.com/v2/resize:fit:640/format:webp/1*SU00ELFCZ4fNW8wTbKcDyw.png)
Cómo probar el problema: Es un problema bastante difícil de diagnosticar, en muchos casos necesitarías saber qué buscar. Tener un conjunto de datos de referencia separado con una amplia variedad de indicaciones, donde las cosas podrían o no salir mal, respuestas de plantilla y señales de advertencia para cada respuesta que detectaríamos, así como un conjunto de datos de humanos de diversos orígenes y en múltiples escenarios almacenando todos los atributos posibles sobre la persona en la imagen sería útil. Estos conjuntos de datos deben tener cientos de miles de entradas para obtener estadísticas confiables.
Solución: Casi todos los problemas de sesgo, equidad y seguridad provienen de los datos de entrenamiento. Me gusta la analogía de que los modelos de IA son un espejo de la humanidad que exacerba todos nuestros sesgos. Entrenar con datos limpios e imparciales mejoraría drásticamente los resultados. Sin embargo, incluso con estos datos, los modelos cometen errores.
La postprocesamiento y filtrado de los resultados es otra posible solución; por ejemplo, Stable Diffusion entrenado con datos que contienen imágenes explícitas tiene un detector de contenido NSFW para detectar posibles problemas. Filtros similares se pueden aplicar a la salida de modelos de texto a texto.
Calidad de salida, relevancia y corrección
Los modelos generativos pueden ser muy creativos al interpretar las solicitudes de los usuarios, y aunque los modelos de gran escala recientes alcanzan la calidad a nivel humano, para cada caso de uso no funcionarían directamente, requiriendo ajustes adicionales y diseño de indicaciones.
Evaluar la calidad en modelos tempranos y muy limitados de imagen a texto y de texto a texto era relativamente sencillo, después de todo, una mejora sobre la charlatanería es obvia. Los modelos generativos de alta calidad comienzan a exhibir comportamientos más difíciles de detectar; por ejemplo, los modelos de texto a texto pueden volverse evasivos, arrojando con confianza información incorrecta y desactualizada.
Los modelos de difusión presentan imperfecciones en la salida de otras formas. Los problemas típicos atribuidos a los modelos basados en imágenes son geometría incorrecta, anatomía mutada, falta de coherencia entre la indicación y el resultado de la imagen, así como discrepancia de color de piel y género en el caso de la transferencia de imágenes. La evaluación automatizada de la estética y el realismo está rezagada, y las métricas típicas, como FID, no son capaces de capturar estas variaciones.


![De izquierda a derecha: [1] dos personas abrazándose; [2] un hombre con pulgar hacia arriba; [3] un perro corriendo en el parque. Una imagen de Stable Diffusion 1.5 generada por el autor](https://miro.medium.com/v2/resize:fit:640/format:webp/1*tyh1KGXnbEMtGszdyE6WKg.png)
Cómo probar el problema: Probar la calidad de los modelos generativos es un desafío; después de todo, no hay una verdad absoluta para estos modelos, ya que están diseñados para proporcionar salidas novedosas. Hasta ahora, ninguna métrica capturaría de manera confiable los aspectos de calidad. Y la métrica más confiable es la evaluación humana.
Al igual que en la evaluación de sesgo e imparcialidad, la mejor manera es tener un gran conjunto de datos de estímulos e imágenes para probar la calidad. Con los modelos de texto a texto volviéndose más personalizados y ajustados a cada usuario, además de la coherencia de los diálogos, la corrección y relevancia, también queremos evaluar qué tan bien pueden recordar información sobre la conversación.
Solución: Muchos de los problemas de calidad se pueden atribuir a los datos de entrenamiento y al tamaño de los modelos; aún podrían ser un poco demasiado pequeños para tener otro salto de calidad (piense en GPT-3.5 versus GPT-4) — el espacio latente actual es una abstracción y no está diseñado para almacenar información precisa. Muchos problemas se pueden resolver con una mejor ingeniería de estímulos — tanto la ampliación de estímulos para texto a texto como los estímulos negativos para modelos de texto a imagen.
Los modelos de texto a imagen e imagen a imagen pueden tener herramientas adicionales que podrían mejorar la calidad — mejora de imagen, ya sea a través de métodos convencionales de aprendizaje profundo o refinadores basados en difusión. Módulos adicionales como ControlNet y ortogonales a la arquitectura de difusión pueden ayudar con un control adicional sobre los resultados generados. Las técnicas Dreambooth para el ajuste fino del modelo para una aplicación específica también ayudarían a obtener esa ventaja en los resultados. Jugar con parámetros adicionales, como el programador, CFG y el número de pasos de difusión, puede afectar drásticamente la calidad.
Resumen
Los modelos generativos han abierto un nuevo campo de aplicaciones tanto divertidas, como las lentes de IA, como comerciales, como mejores motores de búsqueda, copilotos y anuncios. Al mismo tiempo, la prisa por lanzar el producto por parte de las empresas y la emoción de los consumidores por las nuevas funcionalidades a veces hacen que los fallos aparentes en la tecnología pasen desapercibidos.
Y aunque hay un impulso general para hacer que la evaluación de modelos sea más transparente mediante la publicación de conjuntos de datos de código abierto a gran escala, código de entrenamiento y resultados de evaluación, también hay un impulso para una regulación más estricta de los modelos de IA a gran escala. En un mundo ideal, ambos no llegarían a un extremo y se ayudarían mutuamente para que la IA sea más segura y divertida de usar.
¿Te gustó el autor? ¡Mantente conectado!
¿Me he perdido algo? No dudes en dejar una nota, comentario o enviarme un mensaje directamente en LinkedIn o Twitter.
Evaluación de calidad de imagen profunda
Inmersión profunda en la evaluación de calidad de imagen de referencia completa. Desde experimentos de calidad de imagen subjetiva hasta objetivos profundos…
towardsdatascience.com
Pérdidas perceptuales para la restauración de imagen profunda
Desde el error cuadrático medio hasta GANs: ¿qué hace una buena función de pérdida perceptual?
towardsdatascience.com
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Detectando Fraude en el Comercio Electrónico con Técnicas Avanzadas de Ciencia de Datos
- Inteligencia Artificial (IA) y Web3 ¿Cómo están conectados?
- Ami Hever, Co-Fundador y CEO de UVeye – Serie de Entrevistas
- Construyendo un Mapa Topográfico de Nepal Utilizando Python
- Expertos en tecnología comienzan a dudar de que las alucinaciones de ChatGPT, la IA, desaparezcan alguna vez
- El Cuadro de Búsqueda de Google Cambió el Significado de la Información
- 6 Diferentes formas en las que la IA podría ayudar a mejorar la experiencia del usuario






