Este documento de IA propone COLT5 un nuevo modelo para entradas de largo alcance que emplea la computación condicional para una mayor calidad y velocidad más rápida.
This AI document proposes COLT5, a new model for long-range inputs that uses conditional computation for higher quality and faster speed.


Se necesitan modelos de aprendizaje automático para codificar textos largos para diversas tareas de procesamiento de lenguaje natural, incluyendo resúmenes o respuestas a preguntas sobre documentos extensos. Dado que el costo de atención aumenta cuadráticamente con la longitud de entrada y las capas de proyección y de avance deben aplicarse a cada token de entrada, procesar textos largos utilizando un modelo Transformer es computacionalmente costoso. En los últimos años se han propuesto varias estrategias de “Transformer eficiente” que reducen el gasto del mecanismo de atención para entradas largas. Sin embargo, las capas de proyección y de avance, especialmente para modelos más grandes, llevan la mayor parte de la carga de cómputo y pueden hacer imposible el análisis de entradas largas. Este estudio presenta COLT5, una nueva familia de modelos que, al integrar mejoras arquitectónicas tanto para las capas de atención como para las capas de avance, se basa en LONGT5 para permitir un procesamiento rápido de entradas largas.
La base de COLT5 es la comprensión de que ciertos tokens son más significativos que otros y que asignando más cómputo a los tokens importantes se puede obtener una mayor calidad a un menor costo. Por ejemplo, COLT5 separa cada capa de avance y cada capa de atención en una rama ligera aplicada a todos los tokens y una rama pesada utilizada para seleccionar tokens significativos elegidos especialmente para esa entrada y componente. En comparación con LONGT5 regular, la dimensión oculta de la rama de avance ligera es menor que la de la rama de avance pesada. Además, el porcentaje de tokens significativos disminuirá con la longitud del documento, lo que permitirá el procesamiento manejable de textos largos.
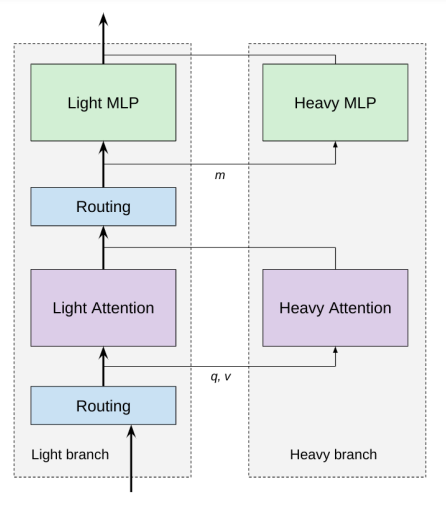
Se muestra una visión general del mecanismo condicional COLT5 en la Figura 1. La arquitectura LONGT5 ha experimentado dos cambios adicionales gracias a COLT5. La rama de atención pesada realiza una atención completa en un conjunto diferente de tokens significativos cuidadosamente seleccionados, mientras que la rama de atención ligera tiene menos cabezas y aplica una atención local. La multi-consulta de atención cruzada, que COLT5 introduce, acelera drásticamente la inferencia. Además, COLT5 utiliza el objetivo de preentrenamiento UL2, que demuestran que permite el aprendizaje contextual en entradas extensas.
- Una nueva investigación de Inteligencia Artificial de Stanford muestra cómo las explicaciones pueden reducir la dependencia excesiva en los sistemas de IA durante la toma de decisiones
- Descubre DERA Un marco de inteligencia artificial para mejorar las completaciones de modelos de lenguaje grandes con agentes de resolución habilitados para el diálogo
- El equipo de Red AI de Google los hackers éticos que hacen que la IA sea más segura
Investigadores de Google Research sugieren COLT5, un nuevo modelo para entradas distantes que utiliza el cálculo condicional para un mejor rendimiento y un procesamiento más rápido. Demuestran que COLT5 supera a LONGT5 en los conjuntos de datos de resumen de arXiv y de preguntas y respuestas de TriviaQA, mejorando LONGT5 y alcanzando SOTA en el benchmark de SCROLLS. Con una escala de “tokens de enfoque” menor que lineal, COLT5 mejora considerablemente la calidad y el rendimiento para tareas con entradas largas. COLT5 también realiza un ajuste fino y una inferencia sustancialmente más rápidos con la misma o mejor calidad de modelo. Las capas de avance y atención ligera en COLT5 se aplican a toda la entrada, mientras que las ramas pesadas solo afectan a una selección de tokens significativos elegidos por un enrutador aprendido. Demuestran que COLT5 supera a LONGT5 en varios conjuntos de datos de entrada larga a todas las velocidades y puede emplear entradas extremadamente largas de hasta 64k tokens de manera exitosa y eficiente.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Usando un Keras Tuner para la optimización de hiperparámetros de un modelo TensorFlow
- ¿Desvelando el poder de Meta’s Llama 2 ¿Un salto adelante en la IA generativa?
- GPT-Engineer Tu nuevo asistente de programación de IA
- OmniSpeech se convierte en socio de software de audio de Cadence Tensilica para los algoritmos de voz de IA de próxima generación para satisfacer mejor a los clientes de automoción, móviles, consumo y IoT.
- UNESCO Expresa Preocupaciones Sobre la Implantación de Chips de IA en Relación a la Privacidad
- Investigadores del MIT y UC Berkeley presentaron un marco de trabajo que permite a los humanos enseñar rápidamente a un robot lo que quieren que haga con un esfuerzo mínimo.
- Microsoft AI propone MM-REACT un paradigma del sistema que combina ChatGPT y expertos en visión para un razonamiento y acción multimodal avanzados.






