La importancia de la reproducibilidad en el aprendizaje automático
The importance of reproducibility in machine learning.
Y cómo los enfoques para una mejor gestión de datos, control de versiones y seguimiento de experimentos pueden ayudar a construir tuberías de aprendizaje automático reproducibles.

Cuando estaba aprendiendo machine learning, a menudo intentaba programar junto con los tutoriales de proyectos. Seguiría los pasos que había delineado el autor. Pero a veces, mi modelo rendía peor que el modelo del autor del tutorial. Tal vez te hayas encontrado en una situación similar, ¿no? O quizás simplemente has tomado el código de tu colega de GitHub. Y las métricas de rendimiento de tu modelo son diferentes de las que afirma el informe de tu colega. Entonces, ¿hacer lo mismo no garantiza los mismos resultados, cierto? Este es un problema prevalente en el machine learning: el desafío de la reproducibilidad.
No hace falta decir que los modelos de machine learning son útiles solo cuando otros pueden replicar los experimentos y reproducir los resultados. Desde el típico problema de “Funciona en mi máquina” hasta cambios sutiles en la forma en que se entrena el modelo de machine learning, hay varios desafíos para la reproducibilidad.
- SiMa.ai traerá el chip de inteligencia artificial más poderoso del mundo a la India.
- Toma esto y conviértelo en una marioneta digital GenMM es un modelo de IA que puede sintetizar movimiento usando un solo ejemplo.
- Batalla de los gigantes de LLM Google PaLM 2 vs OpenAI GPT-3.5.
En este artículo, examinaremos más de cerca los desafíos y la importancia de la reproducibilidad en el machine learning, junto con el papel de la gestión de datos, el control de versiones y el seguimiento de experimentos en abordar el desafío de la reproducibilidad del machine learning.
¿Qué es la reproducibilidad en el contexto del machine learning?
Veamos cómo podemos definir mejor la reproducibilidad en el contexto del machine learning.
Supongamos que hay un proyecto existente que utiliza un algoritmo de machine learning específico en un conjunto de datos determinado. Dado el conjunto de datos y el algoritmo, deberíamos poder ejecutar el algoritmo (tantas veces como deseemos) y reproducir (o replicar) el resultado en cada una de esas ejecuciones.
Pero la reproducibilidad en el machine learning no está exenta de desafíos. Ya hemos discutido un par de ellos, repasémoslos con más detalle en la siguiente sección.
Desafíos de la reproducibilidad en el machine learning
Para cualquier aplicación, existen desafíos como la fiabilidad y el mantenimiento. Sin embargo, en las aplicaciones de machine learning, hay desafíos adicionales.
Cuando hablamos de aplicaciones de machine learning, a menudo nos referimos a las canalizaciones de machine learning de principio a fin que suelen incluir los siguientes pasos:
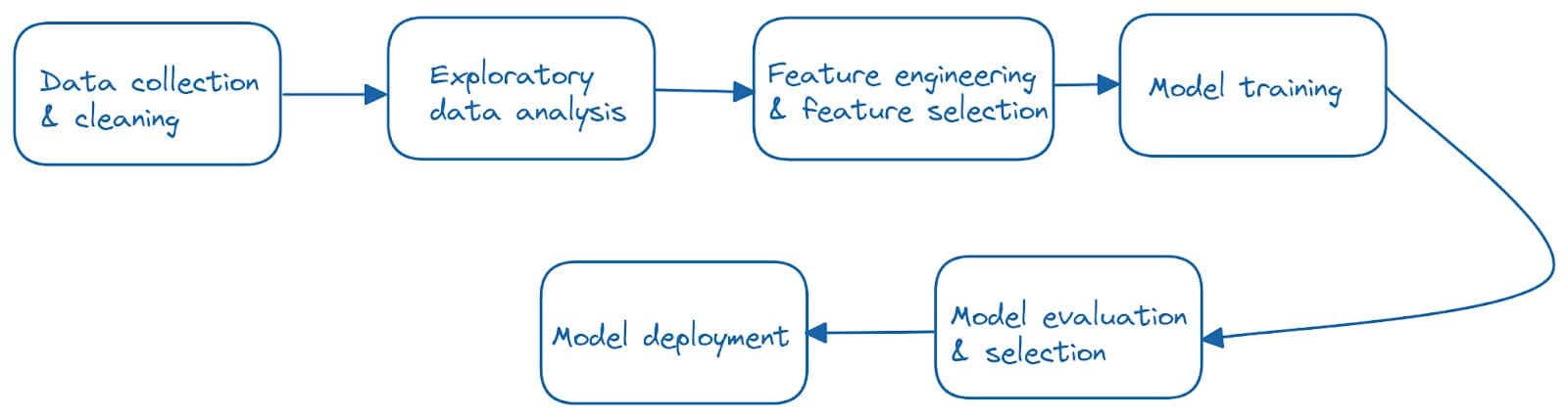
Por lo tanto, los desafíos de la reproducibilidad pueden surgir debido a cambios en uno o más de estos pasos. Y la mayoría de los cambios se pueden capturar en uno de los siguientes:
- Cambios en el entorno
- Cambios en el código
- Cambios en los datos
Veamos cómo cada uno de estos cambios obstaculiza la reproducibilidad.
Cambios en el entorno
Python y los marcos de machine learning basados en Python hacen que el desarrollo de aplicaciones de ML sea muy fácil. Sin embargo, la gestión de dependencias en Python -gestionar las diferentes bibliotecas y versiones requeridas para un proyecto determinado- es un desafío no trivial. Un pequeño cambio, como utilizar una versión diferente de la biblioteca y una llamada de función que utiliza un argumento obsoleto, es suficiente para romper el código.
Esto también incluye la elección de sistemas operativos. Hay desafíos asociados con el hardware, como las diferencias en la precisión de punto flotante de la GPU, y cosas por el estilo.
Cambios en el código
Desde el barajado del conjunto de datos de entrada para determinar qué muestras van al conjunto de datos de entrenamiento hasta la inicialización aleatoria de pesos al entrenar redes neuronales: la aleatoriedad juega un papel importante en el machine learning.
Establecer una semilla aleatoria diferente puede llevar a resultados totalmente diferentes. Para cada modelo que entrenamos, hay un conjunto de hiperparámetros. Entonces, ajustar uno o más de los hiperparámetros también puede llevar a resultados diferentes.
Cambios en los datos

Incluso con el mismo conjunto de datos, hemos visto cómo las inconsistencias en los valores de los hiperparámetros y la aleatoriedad pueden dificultar la replicación de los resultados. Por lo tanto, es obvio que, cuando cambian los datos -un cambio en la distribución de los datos, modificaciones en un subconjunto de registros o eliminación de algunas muestras- dificultan la reproducción de los resultados.
En resumen: cuando intentamos replicar los resultados de un modelo de machine learning, incluso los cambios más pequeños en el código, el conjunto de datos utilizado y el entorno en el que se ejecuta el modelo de machine learning pueden impedirnos obtener los mismos resultados que el modelo original.
Cómo Abordar el Desafío de la Reproducibilidad
Ahora veremos cómo podemos abordar estos desafíos. 
Gestión de Datos
Vimos que uno de los desafíos más obvios en la reproducibilidad está en los datos. Existen ciertos enfoques de gestión de datos, como la versión de los conjuntos de datos, para que podamos rastrear los cambios en el conjunto de datos y almacenar metadatos útiles sobre el conjunto de datos.
Control de Versiones
Cualquier cambio en el código debe ser rastreado utilizando un sistema de control de versiones como Git.
En el desarrollo de software moderno, habrás encontrado pipelines de CI/CD que hacen que el seguimiento de los cambios, la prueba de nuevos cambios y su implementación en producción sean mucho más simples y eficientes.
En otras aplicaciones de software, el seguimiento de los cambios en el código es sencillo. Sin embargo, en el aprendizaje automático, los cambios en el código también pueden implicar cambios en el algoritmo utilizado y los valores de hiperparámetros. Incluso para modelos simples, el número de posibilidades que podemos probar es combinatoriamente grande. Aquí es donde se vuelve relevante el seguimiento de experimentos.
Seguimiento de Experimentos
La construcción de aplicaciones de aprendizaje automático es sinónimo de extensos experimentos. Desde algoritmos hasta hiperparámetros, experimentamos con diferentes algoritmos y valores de hiperparámetros. Por lo tanto, es importante hacer un seguimiento de estos experimentos.
El seguimiento de experimentos de aprendizaje automático incluye:
- registro de barridos de hiperparámetros
- registro de métricas de rendimiento del modelo, checkpoints del modelo
- almacenamiento de metadatos útiles sobre el conjunto de datos y el modelo
Herramientas para el Seguimiento de Experimentos de Aprendizaje Automático, Gestión de Datos y Más
Como se ha visto, la versión de conjuntos de datos, el seguimiento de cambios en el código y el seguimiento de experimentos de aprendizaje automático replican las aplicaciones de aprendizaje automático. Aquí hay algunas de las herramientas que pueden ayudarte a construir pipelines de aprendizaje automático reproducibles:
- Weights and Biases
- MLflow
- Neptune.ai
- Comet ML
- DVC
Conclusión
En resumen, hemos revisado la importancia y los desafíos de la reproducibilidad en el aprendizaje automático. Hemos repasado los enfoques como la versión de datos y modelos y el seguimiento de experimentos. Además, también hemos enumerado algunas de las herramientas que puedes usar para el seguimiento de experimentos y una mejor gestión de datos.
El MLOps Zoomcamp de DataTalks.Club es un excelente recurso para adquirir experiencia con algunas de estas herramientas. Si te gusta construir y mantener pipelines de aprendizaje automático de extremo a extremo, puede que te interese entender el papel de un ingeniero de MLOps. Bala Priya C es una desarrolladora y escritora técnica de India. Le gusta trabajar en la intersección de las matemáticas, la programación, la ciencia de datos y la creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento del lenguaje natural. Le gusta leer, escribir, programar y tomar café. Actualmente, está trabajando en aprender y compartir su conocimiento con la comunidad de desarrolladores escribiendo tutoriales, guías prácticas, artículos de opinión y más.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Conoce Video-ControlNet Un nuevo modelo de difusión de texto a video que cambiará el juego y dará forma al futuro de la generación de video controlable.
- Una comparación de algoritmos de aprendizaje automático en Python y R.
- Búsqueda de similitud, Parte 5 Hashing sensible a la localidad (LSH)
- Moldeando el Futuro de la IA Una Encuesta Exhaustiva sobre Modelos de Pre-Entrenamiento Visión-Lenguaje y su Papel en Tareas Uni-Modales y Multi-Modales.
- Implemente un punto final de inferencia de ML sin servidor para modelos de lenguaje grandes utilizando FastAPI, AWS Lambda y AWS CDK.
- GPT vs BERT ¿Cuál es mejor?
- Inmersión teórica profunda en la Regresión Lineal






