Destacar el texto mientras se está hablando utilizando Amazon Polly
Texto destacado con Amazon Polly mientras se habla.
Amazon Polly es un servicio que convierte texto en voz realista. Permite el desarrollo de una amplia gama de aplicaciones que pueden convertir texto en voz en múltiples idiomas.
Este servicio puede ser utilizado por chatbots, audiolibros y otras aplicaciones de texto a voz en conjunto con otros servicios de inteligencia artificial o aprendizaje automático (ML) de AWS. Por ejemplo, Amazon Lex y Amazon Polly pueden combinarse para crear un chatbot que interactúe en una conversación bidireccional con un usuario y realice ciertas tareas basadas en los comandos del usuario. Amazon Transcribe, Amazon Translate y Amazon Polly pueden combinarse para transcribir el habla a texto en el idioma de origen, traducirlo a un idioma diferente y pronunciarlo.
En esta publicación, presentamos un enfoque interesante para resaltar el texto a medida que se habla utilizando Amazon Polly. Esta solución se puede utilizar en muchas aplicaciones de texto a voz para hacer lo siguiente:
- Agregar capacidades visuales al audio en libros, sitios web y blogs
- Aumentar la comprensión cuando los clientes intentan entender rápidamente el texto a medida que se habla
Nuestra solución le brinda al cliente (el navegador, en este ejemplo) la capacidad de saber qué texto (palabra o frase) está siendo hablado por Amazon Polly en cualquier momento. Esto permite al cliente resaltar dinámicamente el texto a medida que se habla. Esta capacidad es útil para proporcionar ayuda visual al habla para los casos de uso mencionados anteriormente.
- XPENG lanza el G6 Coupe SUV para el mercado general
- NVIDIA CEO, ejecutivos europeos de IA generativa discuten claves para el éxito.
- Robot se posiciona en el podio como director de orquesta en Seúl.
Nuestra solución se puede ampliar para realizar tareas adicionales además de resaltar texto. Por ejemplo, el navegador puede mostrar imágenes, reproducir música o realizar otras animaciones en el front-end a medida que se habla el texto. Esta capacidad es útil para crear audiolibros dinámicos, contenido educativo y aplicaciones de texto a voz más ricas.
Descripción general de la solución
En su núcleo, la solución utiliza Amazon Polly para convertir una cadena de texto en voz. El texto puede ser ingresado desde el navegador o a través de una llamada de API al punto de conexión expuesto por nuestra solución. El habla generada por Amazon Polly se almacena como un archivo de audio (formato MP3) en un bucket de Amazon Simple Storage Service (Amazon S3).
Sin embargo, utilizando solo el archivo de audio, el navegador no puede encontrar qué partes del texto se están hablando en un momento dado porque no tenemos información detallada sobre cuándo se habla cada palabra.
Amazon Polly proporciona una forma de obtener esto mediante marcas de habla. Las marcas de habla se almacenan en un archivo de texto que muestra el tiempo (medido en milisegundos desde el inicio del audio) en el que se habla cada palabra o frase.
Amazon Polly devuelve objetos de marcas de habla en un flujo JSON delimitado por líneas. Un objeto de marca de habla contiene los siguientes campos:
- Tiempo – La marca de tiempo en milisegundos desde el inicio del flujo de audio correspondiente
- Tipo – El tipo de marca de habla (frase, palabra, visema o SSML)
- Inicio – El desplazamiento en bytes (no caracteres) del inicio del objeto en el texto de entrada (sin incluir marcas de visema)
- Fin – El desplazamiento en bytes (no caracteres) del final del objeto en el texto de entrada (sin incluir marcas de visema)
- Valor – Esto varía dependiendo del tipo de marca de habla:
- SSML – Etiqueta SSML <mark>
- Visema – El nombre del visema
- Palabra o frase – Una subcadena del texto de entrada delimitada por los campos de inicio y fin
Por ejemplo, la frase “Mary tenía un corderito” puede dar lugar al siguiente archivo de marcas de habla si se utiliza SpeechMarkTypes = [“palabra”, “frase”] en la llamada de API para obtener las marcas de habla:
{"time":0,"type":"frase","start":0,"end":23,"value":"Mary tenía un corderito."}
{"time":6,"type":"palabra","start":0,"end":4,"value":"Mary"}
{"time":373,"type":"palabra","start":5,"end":8,"value":"tenía"}
{"time":604,"type":"palabra","start":9,"end":10,"value":"un"}
{"time":643,"type":"palabra","start":11,"end":17,"value":"corderito"}
{"time":882,"type":"palabra","start":18, "end":22,"value":"."}La palabra “tenía” (al final de la línea 3) comienza 373 milisegundos después de que comienza el flujo de audio, comienza en el byte 5 y termina en el byte 8 del texto de entrada.
Visión general de la arquitectura
La arquitectura de nuestra solución se presenta en el siguiente diagrama.
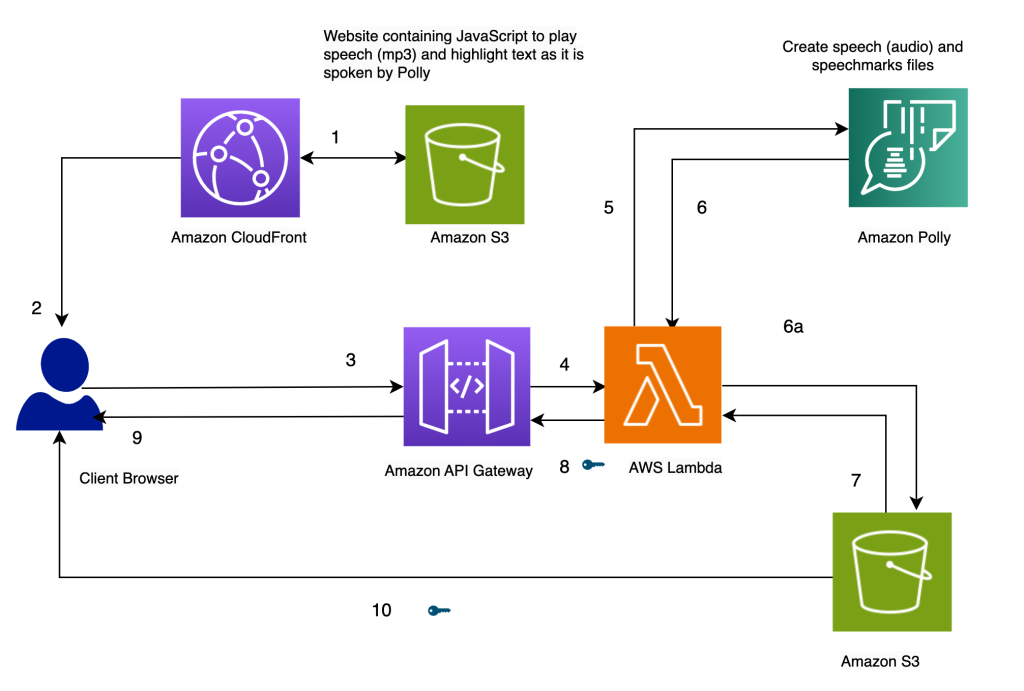
Destacar el texto a medida que se habla, utilizando Amazon Polly
Nuestro sitio web para la solución se almacena en Amazon S3 como archivos estáticos (JavaScript, HTML), que se alojan en Amazon CloudFront (1) y se sirven al navegador del usuario final (2).
Cuando el usuario ingresa texto en el navegador a través de un formulario HTML simple, se procesa mediante JavaScript en el navegador. Esto llama a una API (3) a través de Amazon API Gateway para invocar una función de AWS Lambda (4). La función Lambda llama a Amazon Polly (5) para generar archivos de habla (audio) y marcas de habla (JSON). Se realizan dos llamadas a Amazon Polly para obtener los archivos de audio y marcas de habla. Las llamadas se realizan utilizando funciones asíncronas de JavaScript. La salida de estas llamadas son los archivos de audio y marcas de habla, que se almacenan en Amazon S3 (6a). Para evitar que varios usuarios sobrescriban los archivos de los demás en el bucket de S3, los archivos se almacenan en una carpeta con una marca de tiempo. Esto minimiza las posibilidades de que dos usuarios sobrescriban los archivos de los demás en Amazon S3. Para un lanzamiento en producción, podemos emplear enfoques más robustos para segregar los archivos de los usuarios en función del ID de usuario, la marca de tiempo y otras características únicas.
La función Lambda crea URL prefirmadas para los archivos de habla y marcas de habla y los devuelve al navegador en forma de un array (7, 8, 9).
Cuando el navegador envía el archivo de texto al punto de conexión de la API (3), recibe dos URL prefirmadas para el archivo de audio y el archivo de marcas de habla en una invocación síncrona (9). Esto se indica con el símbolo de clave junto a la flecha.
Una función de JavaScript en el navegador obtiene el archivo de marcas de habla y el audio desde sus URL (10). Configura el reproductor de audio para reproducir el audio (se utiliza la etiqueta de audio de HTML con este propósito).
Cuando el usuario hace clic en el botón de reproducción, analiza las marcas de habla recuperadas en el paso anterior para crear una serie de eventos temporizados utilizando timeouts. Los eventos invocan una función de devolución de llamada, que es otra función de JavaScript utilizada para resaltar el texto hablado en el navegador. Simultáneamente, la función de JavaScript transmite el archivo de audio desde su URL.
El resultado es que los eventos se ejecutan en los momentos adecuados para resaltar el texto a medida que se habla mientras se reproduce el audio. El uso de timeouts de JavaScript nos proporciona la sincronización del audio con el texto resaltado.
Prerrequisitos
Para ejecutar esta solución, necesita una cuenta de AWS con un usuario de AWS Identity and Access Management (IAM) que tenga permiso para usar Amazon CloudFront, Amazon API Gateway, Amazon Polly, Amazon S3, AWS Lambda y AWS Step Functions.
Usar Lambda para generar habla y marcas de habla
El siguiente código invoca la función synthesize_speech de Amazon Polly dos veces para obtener el archivo de audio y las marcas de habla. Se ejecutan como funciones asíncronas y se coordinan para devolver el resultado al mismo tiempo utilizando promesas.
const p1 = new Promise(doSynthesizeSpeech marks);
const p2 = new Promise(doSynthesizeSpeech);
var result;
await Promise.all([p1, p2])
.then((values) => {
//devolver array de URLs prefirmadas
console.log('Valores:', values);
result = { "output" : values };
})
.catch((err) => {
console.log("Error:" + err);
result = err;
});En el lado de JavaScript, el resaltado de texto se realiza mediante la función highlighter(start, finish, word) y los eventos temporizados se establecen mediante setTimers():
function highlighter(start, finish, word) {
let textarea = document.getElementById("postText");
//console.log(start + "," + finish + "," + word);
textarea.focus();
textarea.setSelectionRange(start, finish);
}
function setTimers() {
let speech marksStr = sessionStorage.getItem("speech marks");
//leer el archivo de marcas de habla y establecer temporizadores para cada palabra
console.log(speech marksStr);
let speech marks = speech marksStr.split("\n");
for (let i = 0; i < speech marks.length; i++) {
//console.log(i + ":" + speech marks[i]);
if (speech marks[i].length == 0) {
continue;
}
smjson = JSON.parse(speech marks[i]);
t = smjson["time"];
s = smjson["start"];
f = smjson["end"];
word = smjson["value"];
setTimeout(highlighter, t, s, f, word);
}
}Enfoques alternativos
En lugar del enfoque anterior, puedes considerar algunas alternativas:
- Crea tanto las comillas de discurso como los archivos de audio dentro de una máquina de estados de Step Functions. La máquina de estados puede invocar la condición de rama paralela para invocar dos funciones Lambda diferentes: una para generar el discurso y otra para generar las comillas de discurso. El código para esto se puede encontrar en la subcarpeta usando-step-functions en el repositorio de Github.
- Invoca a Amazon Polly de forma asíncrona para generar el audio y las comillas de discurso. Este enfoque se puede utilizar si el contenido de texto es grande o el usuario no necesita una respuesta en tiempo real. Para obtener más detalles sobre la creación de archivos de audio largos, consulta la creación de archivos de audio largos.
- Haz que Amazon Polly cree la URL prefirmada directamente utilizando la llamada
generate_presigned_urlen el cliente de Amazon Polly en Boto3. Si eliges este enfoque, Amazon Polly genera el audio y las comillas de discurso cada vez. En nuestro enfoque actual, almacenamos estos archivos en Amazon S3. Aunque estos archivos almacenados no son accesibles desde el navegador en nuestra versión del código, puedes modificar el código para reproducir archivos de audio previamente generados recuperándolos de Amazon S3 (en lugar de regenerar el audio para el texto nuevamente utilizando Amazon Polly). Tenemos más ejemplos de código para acceder a Amazon Polly con Python en la AWS Code Library.
Crear la solución
Toda la solución está disponible en nuestro repositorio de Github. Para crear esta solución en tu cuenta, sigue las instrucciones en el archivo README.md. La solución incluye una plantilla de AWS CloudFormation para aprovisionar tus recursos.
Limpieza
Para limpiar los recursos creados en esta demostración, realiza los siguientes pasos:
- Elimina los buckets de S3 creados para almacenar la plantilla de CloudFormation (Bucket A), el código fuente (Bucket B) y el sitio web (
pth-cf-text-highlighter-website-[Sufijo]). - Elimina la stack de CloudFormation
pth-cf. - Elimina el bucket de S3 que contiene los archivos de discurso (
pth-speech-[Sufijo]). Este bucket fue creado por la plantilla de CloudFormation para almacenar los archivos de audio y las comillas de discurso generados por Amazon Polly.
Resumen
En esta publicación, mostramos un ejemplo de una solución que puede resaltar texto a medida que se habla utilizando Amazon Polly. Se desarrolló utilizando la función de comillas de discurso de Amazon Polly, que nos proporciona marcadores para el lugar donde comienza cada palabra o oración en un archivo de audio.
La solución está disponible como una plantilla de CloudFormation. Se puede implementar tal cual en cualquier aplicación web que realice conversión de texto a voz. Esto sería útil para agregar capacidades visuales al audio en libros, avatares con capacidades de sincronización de labios (utilizando comillas de discurso de visemas), sitios web y blogs, y para ayudar a personas con discapacidades auditivas.
Se puede ampliar para realizar tareas adicionales además de resaltar texto. Por ejemplo, el navegador puede mostrar imágenes, reproducir música y realizar otras animaciones en el frontend mientras se habla el texto. Esta capacidad puede ser útil para crear audiolibros dinámicos, contenido educativo y aplicaciones de texto a voz más ricas.
Te invitamos a probar esta solución y aprender más sobre los servicios relevantes de AWS desde los siguientes enlaces. Puedes ampliar la funcionalidad para tus necesidades específicas.
- Amazon API Gateway
- Amazon CloudFront
- AWS Lambda
- Amazon Polly
- Amazon S3
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Tour de France incorpora ChatGPT y tecnología de gemelos digitales.
- Casas de cuidado en Japón utilizan Big Data para impulsar a los cuidadores y aligerar las cargas de trabajo.
- Comprensión del código en tu propio hardware
- Investigadores de Princeton presentan InterCode un revolucionario marco ligero que simplifica la interacción del modelo de lenguaje para generar código de manera similar a como lo haría un humano.
- Cómo automatizar la extracción de entidades de un PDF utilizando LLMs
- Evolucionando un Plan de Pruebas para una Canalización de Datos
- Cómo llamar a Hugging Face AI desde una base de datos Oracle usando JavaScript






