Learn more about Quantization

ExLlamaV2 La biblioteca más rápida para ejecutar LLMs
ExLlamaV2 es una biblioteca diseñada para exprimir aún más rendimiento de GPTQ. Gracias a nuevos kernels, está optimi...

QLoRA Entrenando un Modelo de Lenguaje Grande en una GPU de 16GB.
Vamos a combinar una técnica de reducción de peso para modelos, como la cuantización, con una técnica de ajuste fino ...
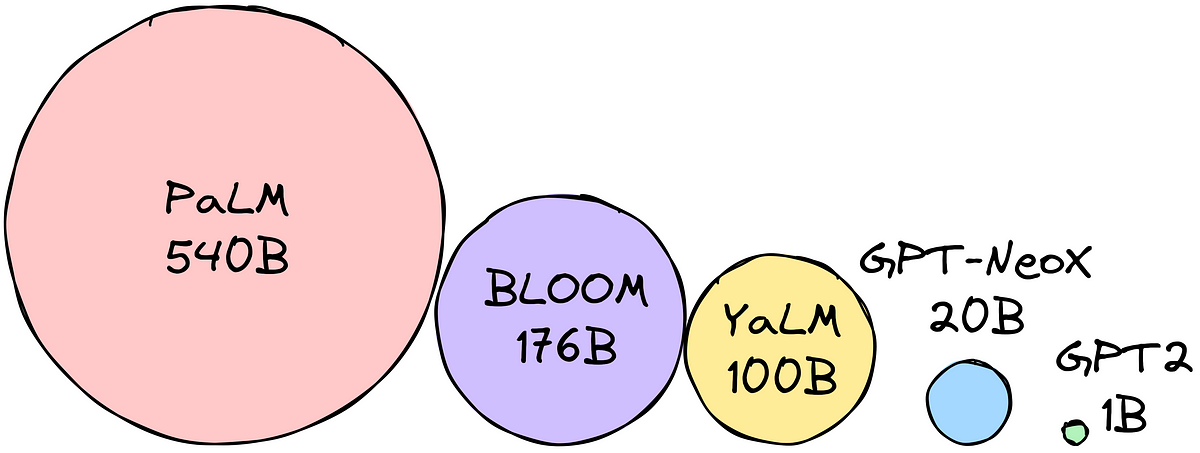
Cómo ajustar modelos de lenguaje grandes en memoria pequeña cuantización
Los Modelos de Lenguaje Grandes se pueden utilizar para la generación de texto, la traducción, las tareas de pregunta...
Quantización de Tensores La Historia No Contada
A lo largo del resto de este artículo, intentaremos responder a las siguientes preguntas con ejemplos concretos. Esca...
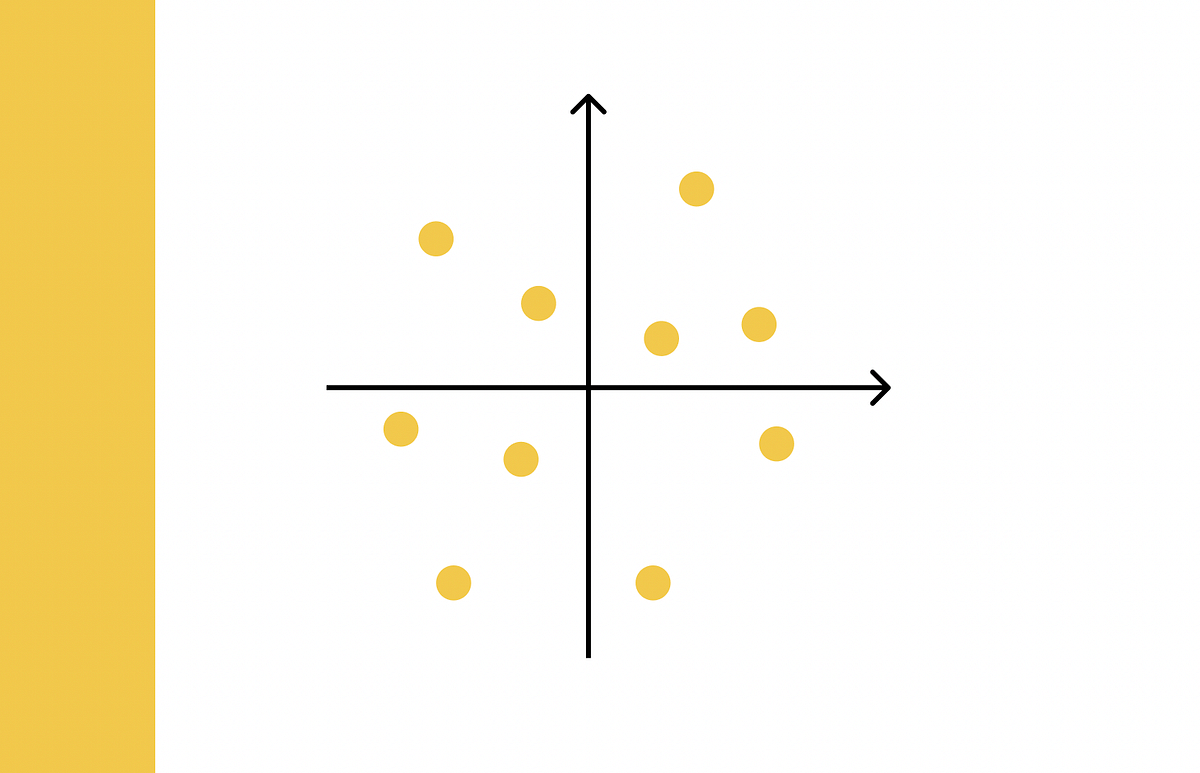
Búsqueda de similitud, Parte 3 Mezclando el índice de archivo invertido y la cuantificación de productos.
La búsqueda de similitud es un problema en el que, dada una consulta, el objetivo es encontrar los documentos más sim...

- You may be interested
- Spotify adopta la IA desde listas de re...
- Principales tendencias en pruebas de ap...
- El problema de percepción pública del A...
- Este artículo de IA revela DiffEnc Avan...
- Cómo convertir imágenes en indicaciones...
- Capturando Carbono
- Evaluando la síntesis del habla en vari...
- Los mejores cursos de IA de universidad...
- Investigadores de Stanford presentan Pa...
- LangChain 101 Parte 2c. Ajuste fino de ...
- Explora las relaciones semánticas en te...
- Conoce el nuevo modelo Zeroscope v2 un ...
- Principios efectivos de ingeniería de i...
- Más personas están quedando ciegas. La ...
- Investigadores de UCLA y CMU presentan ...
Find your business way
Globalization of Business, We can all achieve our own Success.