Learn more about Multimodal Learning
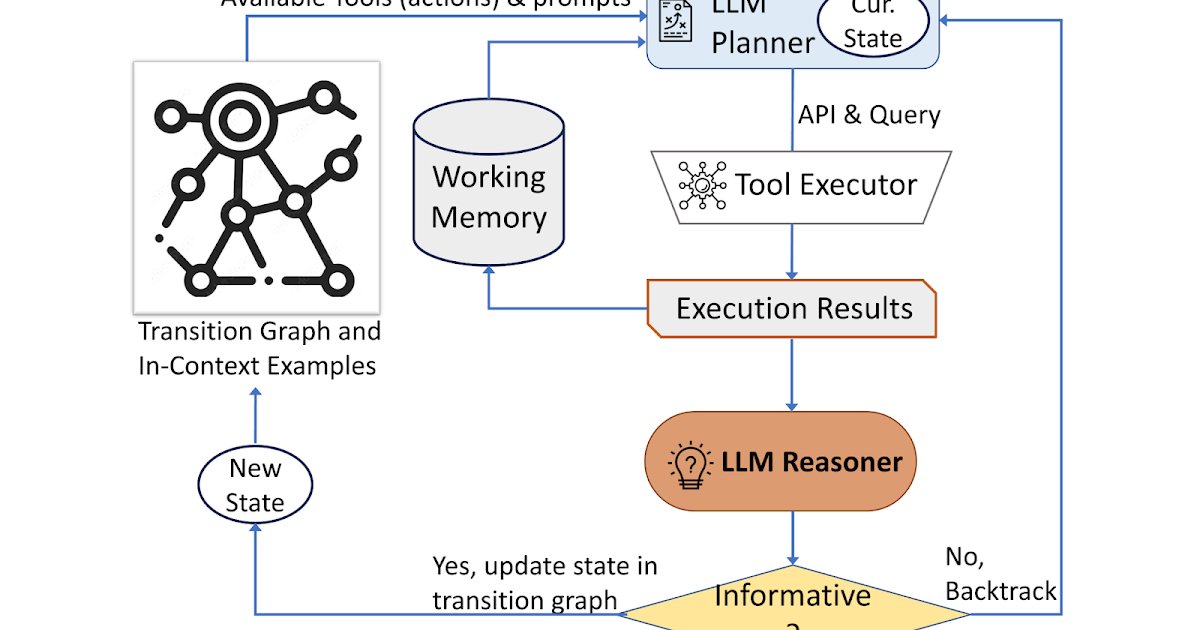
Búsqueda autónoma de información visual con modelos de lenguaje grandes
Publicado por Ziniu Hu, Investigador Estudiantil, y Alireza Fathi, Científico Investigador, Equipo de Percepción de G...

Pregunta y respuesta visual modular a través de generación de código
Publicado por Sanjay Subramanian, estudiante de doctorado en UC Berkeley, y Arsha Nagrani, científico investigador de...
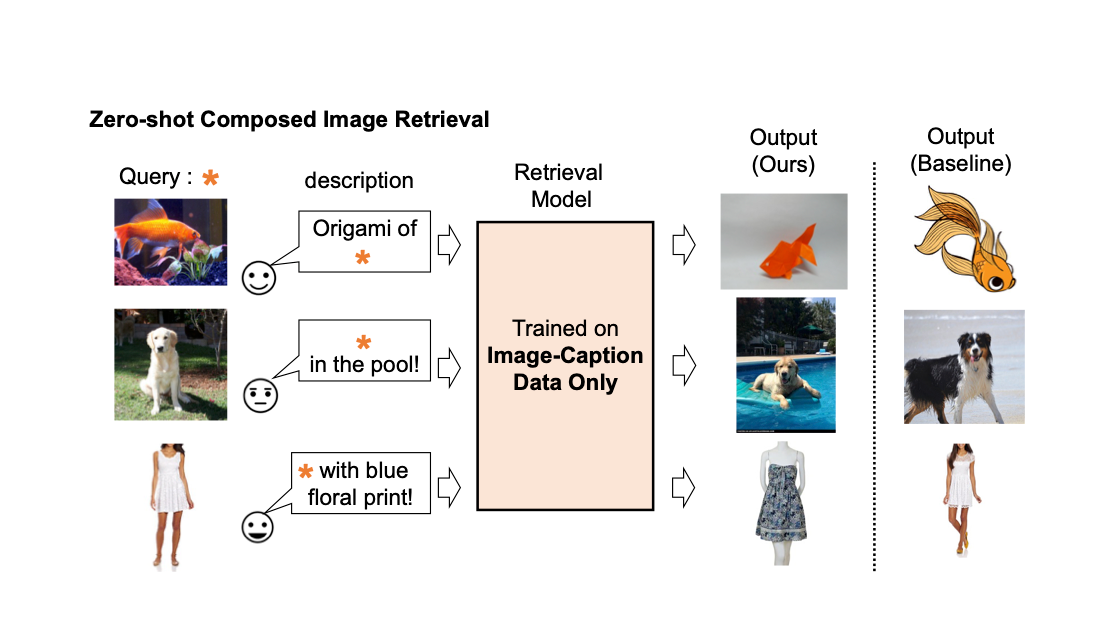
Pic2Word Mapeo de imágenes a palabras para la recuperación de imágenes compuestas sin entrenamiento previo.
Publicado por Kuniaki Saito, Investigador Estudiantil, Investigación de Google, Equipo de IA en la Nube, y Kihyuk Soh...
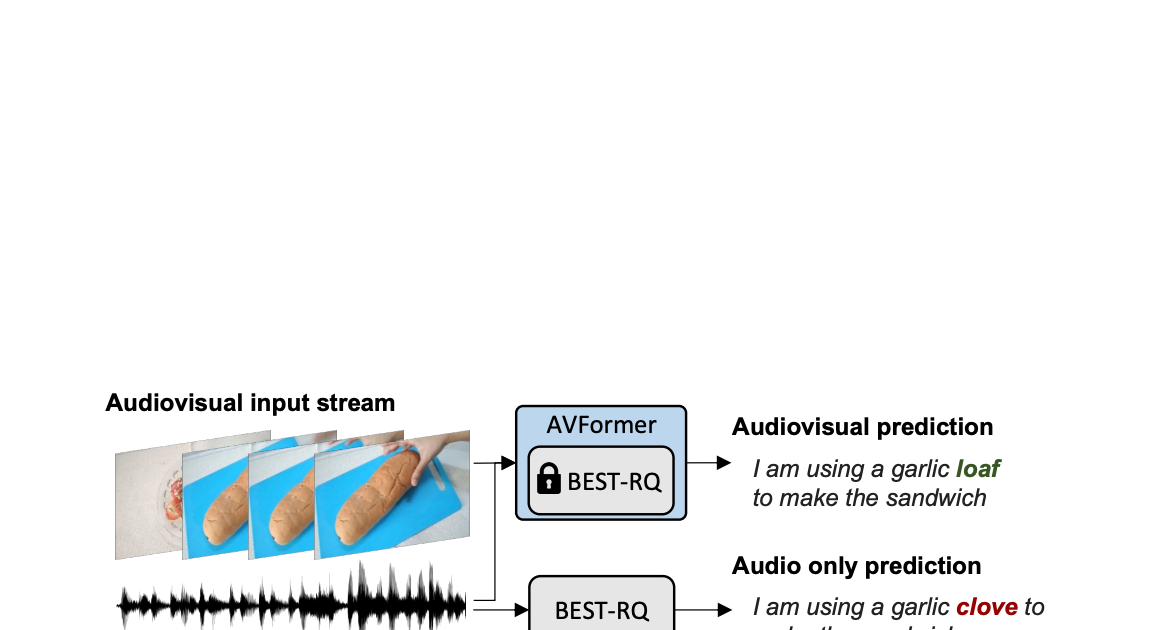
AVFormer Inyectando visión en modelos de habla congelados para la conversión automática de voz a texto sin entrenamiento previo (AV-ASR).
Publicado por Arsha Nagrani y Paul Hongsuck Seo, Científicos Investigadores de Google Research El reconocimiento auto...

- You may be interested
- ‘Búsqueda potenciada en el 🤗 Hub&...
- 20 Mejores Inicios de ChatGPT para Rede...
- Los adolescentes se esfuerzan por ampli...
- Herramientas y Agentes de HuggingFace T...
- La recuperación del conocimiento toma e...
- Un enfoque simple para crear transforma...
- Anthropic presenta una suscripción de p...
- Centros de datos en riesgo debido a fal...
- Creando un Agente LLAma 2 Empoderado co...
- Las 5 mejores plataformas y herramienta...
- Conozca al Omnivore SiBORG Lab mejora s...
- Acelere el ciclo de vida del desarrollo...
- Hoja de ruta de Aprendizaje Automático ...
- 2023 en revisión Recapitulando la era p...
- 5 libros gratuitos para dominar el apre...
Find your business way
Globalization of Business, We can all achieve our own Success.