Learn more about Computer Vision - Section 6

Investigadores de ByteDance y UCSD proponen un modelo de difusión multi-vista que es capaz de generar un conjunto de imágenes multi-vista de un objeto/escena a partir de cualquier texto dado.
A pesar de ser una etapa crucial en la cadena de producción de la industria contemporánea de los videojuegos y los me...

Investigadores de NTU Singapur proponen PointHPS Un marco de IA para la estimación precisa de la postura humana y la forma a partir de nubes de puntos 3D.
Con varios avances en el campo de la Inteligencia Artificial, la estimación de la postura y forma humana (HPS, por su...

Conoce a AnomalyGPT Un nuevo enfoque de IAD basado en Modelos de Visión-Lenguaje de Gran Escala (LVLM) para detectar anomalías industriales
En varias tareas de Procesamiento del Lenguaje Natural (NLP), los Modelos de Lenguaje de Gran Tamaño (LLMs) como GPT-...

Investigadores de Microsoft proponen Síntesis Visual Responsable de Vocabulario Abierto (ORES) con el Marco de Intervención de Dos Etapas
Los modelos de síntesis visual pueden producir imágenes cada vez más realistas gracias al avance del entrenamiento de...
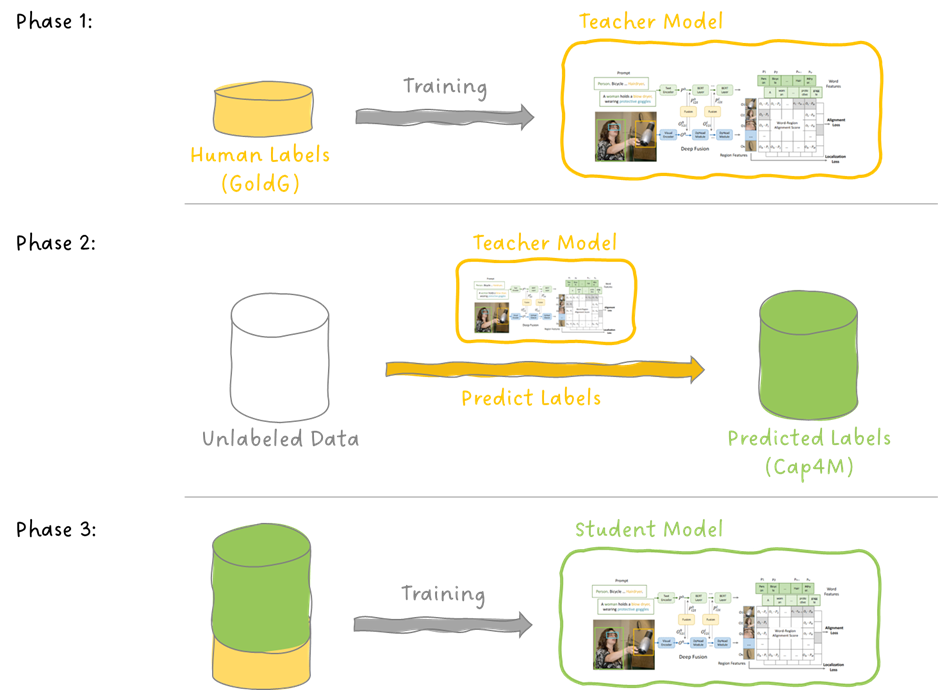
GLIP Introduciendo la Preparación Previa de Lenguaje-Imagen para la Detección de Objetos
Hoy nos sumergiremos en un artículo que se basa en el gran éxito de CLIP en el preentrenamiento de lenguaje-imagen y ...

Investigadores de NYU desarrollaron una nueva técnica de inteligencia artificial para cambiar la edad aparente de una persona en imágenes mientras se mantienen sus características únicas de identificación.
Los sistemas de IA se están utilizando cada vez más para estimar y modificar con precisión las edades de las personas...

Investigadores de la NTU de Singapur proponen IT3D un nuevo método de refinamiento de IA Plug-and-Play para la generación de texto a 3D.
Ha habido un notable progreso en el dominio de texto a imagen, lo que ha generado una oleada de entusiasmo dentro de ...

Investigadores de S-Lab y NTU proponen Scenimefy un nuevo marco de traducción de imagen a imagen semi-supervisado que cierra la brecha en la representación automática de escenas de anime de alta calidad a partir de imágenes del mundo real.
Los paisajes de anime requieren una gran cantidad de talento creativo y tiempo para crear. Por lo tanto, el desarroll...

Donde las rocas y la IA chocan La intersección de la mineralogía y la visión por computadora de cero disparos
Los minerales son sustancias inorgánicas de origen natural con una composición química y una estructura cristalina de...

Investigadores de la Universidad de Washington y AI2 presentan TIFA una métrica de evaluación automática que mide la fidelidad de una imagen generada por IA a través de VQA.
Los modelos de generación de texto a imagen son uno de los mejores ejemplos de avances en Inteligencia Artificial. Co...

Conoce DenseDiffusion una técnica de IA sin entrenamiento para abordar subtítulos densos y manipulación de diseño en la generación de texto a imagen
Los avances recientes en los modelos de texto a imagen han llevado a sistemas sofisticados capaces de generar imágene...

Investigadores de la Universidad de Wisconsin-Madison proponen Eventful Transformers un enfoque rentable para el reconocimiento de video con una pérdida mínima de precisión.
Los Transformers originalmente diseñados para el modelado del lenguaje han sido investigados recientemente como una p...

Investigadores de Alibaba presentan la serie Qwen-VL un conjunto de modelos de visión-lenguaje a gran escala diseñados para percibir y comprender tanto texto como imágenes
Los Modelos de Lenguaje Grande (LLMs) han generado mucho interés últimamente debido a sus poderosas habilidades de cr...

Desbloqueando la precisión en la edición de imágenes y escenas 3D guiadas por texto Conoce ‘Watch Your Steps
Los campos de radiación neuronal (NeRFs) están ganando popularidad gracias a su capacidad para crear visualizaciones ...

De las palabras a los mundos Explorando la narración de videos con la descripción de video fina y detallada multimodal de IA
El lenguaje es el modo predominante de interacción humana, ofreciendo más que solo detalles complementarios a otras f...

Este artículo de IA de NTU Singapur presenta MeVIS un banco de pruebas a gran escala para la segmentación de video con expresiones de movimiento
La segmentación de video guiada por lenguaje es un campo en desarrollo que se centra en segmentar y rastrear objetos ...

Investigadores del MIT desarrollaron una técnica de Inteligencia Artificial (IA) que permite a un robot desarrollar planes complejos para manipular un objeto utilizando toda su mano
La manipulación de cuerpo completo es una fortaleza de los humanos pero una debilidad de los robots. El robot interpr...

Decodificando emociones Revelando sentimientos y estados mentales con EmoTX, un novedoso marco de inteligencia artificial impulsado por Transformer
Las películas son una de las expresiones artísticas más importantes de historias y sentimientos. Por ejemplo, en R...

No es el Vader que piensas 3D VADER es un modelo de IA que difunde modelos 3D
La generación de imágenes nunca ha sido tan fácil. Con el surgimiento de los modelos de IA generativos, el proceso se...
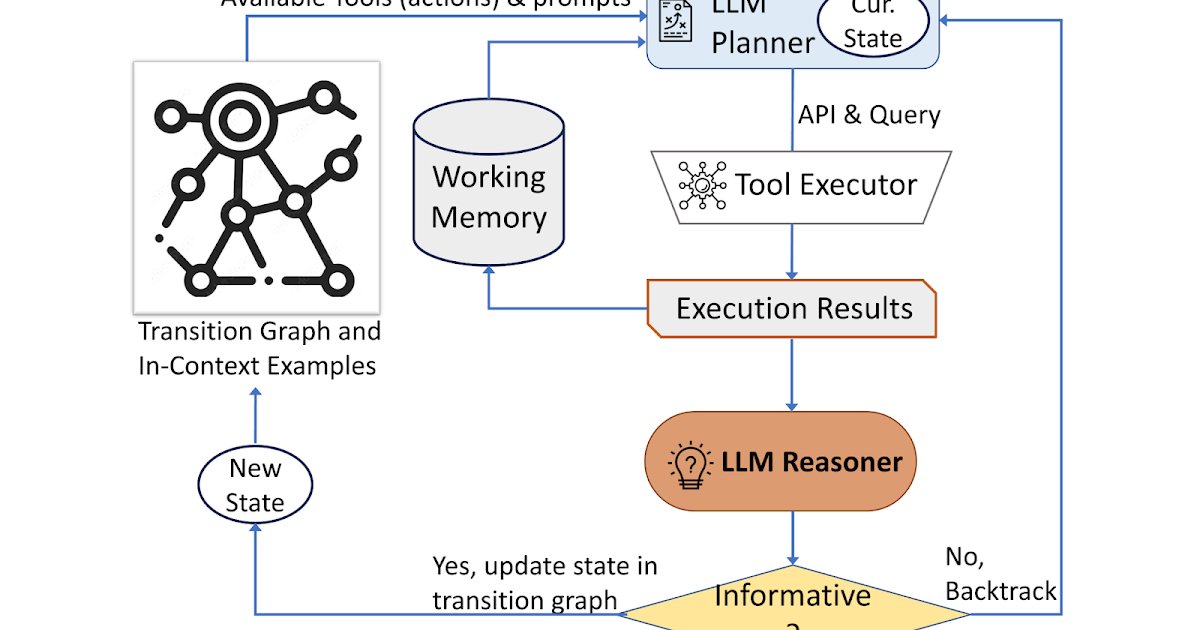
Búsqueda autónoma de información visual con modelos de lenguaje grandes
Publicado por Ziniu Hu, Investigador Estudiantil, y Alireza Fathi, Científico Investigador, Equipo de Percepción de G...

Investigadores de CMU desarrollaron un método simple de IA de aprendizaje a distancia para transferir conocimientos visuales a tareas de robótica mejorando el aprendizaje de políticas en un 20% sobre los resultados básicos
I had trouble accessing your link so I’m going to try to continue without it. Una barrera significativa para el...

Swin Transformers | Tareas modernas de visión por computadora
Introducción El Swin Transformer es una innovación significativa en el campo de los transformadores de visión. El ren...
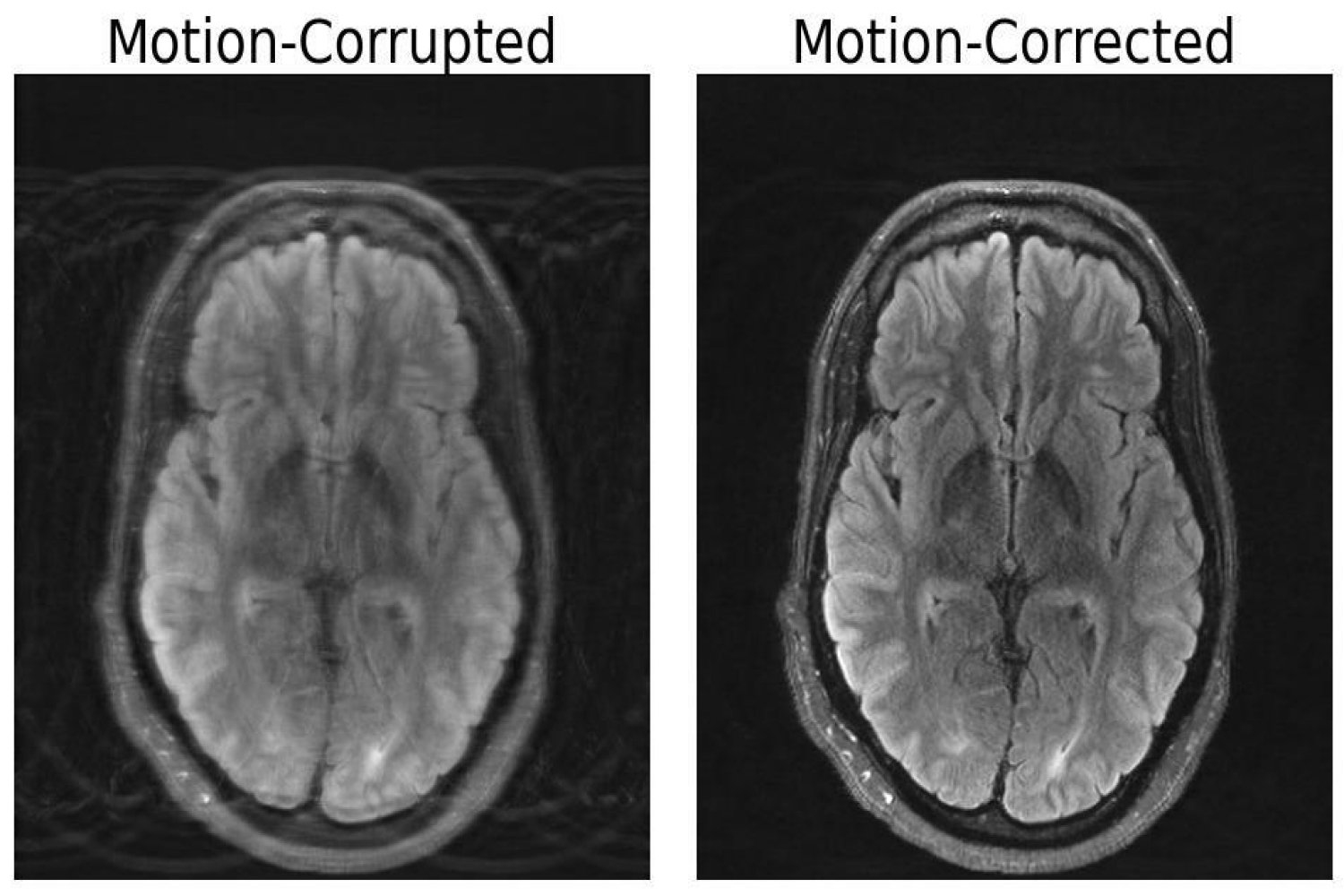
Investigadores del MIT combinan el aprendizaje profundo y la física para corregir las imágenes de resonancia magnética afectadas por el movimiento
El desafío implica más que simplemente una imagen JPEG borrosa. Arreglar los artefactos de movimiento en la imagen mé...
Conoce a Cheetor Un modelo de lenguaje multimodal basado en Transformer (MLLMs) que puede manejar eficazmente una amplia variedad de instrucciones de visión-lenguaje entrelazadas y logra un rendimiento de vanguardia sin necesidad de entrenamiento previo.
A través de la sintonización de instrucciones en grupos de tareas de lenguaje con un estilo instructivo, los modelos ...

Conoce 3D-VisTA Un Transformer pre-entrenado para alineación de visión 3D y texto que puede adaptarse fácilmente a diversas tareas posteriores.
En el dinámico panorama de la Inteligencia Artificial, los avances están remodelando los límites de lo posible. La fu...

- You may be interested
- Un enfoque de 3 pasos para evaluar un R...
- NVIDIA brinda apoyo a los esfuerzos de ...
- Conoce GPTCache una biblioteca para des...
- Principales documentos importantes de L...
- Comprendiendo el sesgo algorítmico Tipo...
- Hacia modelos de lenguaje grandes encri...
- Inmersión profunda en la API del Sentin...
- PyrOSM trabajando con datos de Open Str...
- Construyendo tu propio chatbot de IA co...
- 10 Sesiones imperdibles sobre modelos d...
- Presentación de datos espaciales de for...
- Investigadores de UBC Canadá presentan ...
- Crea una tubería de MLOps de principio ...
- 8 formas en que Google Lens puede ayuda...
- Este artículo de IA de Georgia Tech pro...
Find your business way
Globalization of Business, We can all achieve our own Success.