Learn more about Computer Vision - Section 5

¿Cómo afecta la anonimización de imágenes al rendimiento de la visión por computadora? Explorando técnicas de anonimización tradicionales vs. realistas
La anonimización de imágenes implica modificar datos visuales para proteger la privacidad de las personas al obscenec...

Investigadores de UCSD liberan Graphologue de código abierto una técnica única de IA que transforma las respuestas de modelos de lenguaje grandes como GPT-4 en diagramas interactivos en tiempo real.
Los Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) han ganado recientemente una inmensa popularidad deb...

Desbloqueando la optimización de la batería Cómo el aprendizaje automático y la microscopía de rayos X a escala nanométrica podrían revolucionar las baterías de litio
Ha surgido una iniciativa innovadora de prestigiosas instituciones de investigación con el objetivo de desentrañar la...

RELU vs. Softmax en Vision Transformers ¿Importa la longitud de la secuencia? Ideas de un artículo de investigación de Google DeepMind
Hoy en día, una arquitectura común de aprendizaje automático es la arquitectura de transformer. Una de las partes pri...

¿Puede ser más rentable la segmentación de video? Conoce DEVA Un enfoque de segmentación de video desacoplado que ahorra en anotaciones y generaliza en múltiples tareas.
¿Alguna vez te has preguntado cómo funcionan los sistemas de vigilancia y cómo podemos identificar individuos o vehíc...

Introducción a la Reidentificación de Personas
La reidentificación de personas es un proceso que identifica a individuos que aparecen en diferentes vistas de cámara...

Esta investigación de IA de Corea presenta MagiCapture un método de personalización para integrar conceptos de sujeto y estilo para generar imágenes de retratos de alta resolución.
Las personas a menudo necesitan asistir a un estudio fotográfico, seguido de un costoso y lento procedimiento de edic...

La colaboración multi-AI ayuda al razonamiento y la precisión factual en modelos de lenguaje grandes.
Los investigadores utilizan múltiples modelos de IA para colaborar, debatir y mejorar sus habilidades de razonamiento...

Desbloqueando el poder del difuminado facial en los medios una exploración exhaustiva y comparación de modelos
En el mundo actual impulsado por datos, garantizar la privacidad y el anonimato de las personas es de vital importanc...

Desbloqueando la eficiencia en Transformers de Visión Cómo los MoEs de Visión Móvil Escasos superan a sus contrapartes densas en aplicaciones con recursos limitados
Una arquitectura de red neuronal llamada Mixture-of-Experts (MoE) combina las predicciones de varias redes neuronales...

Cómo construir un sistema Multi-GPU para Deep Learning en 2023
Esta es una guía sobre cómo construir un sistema multi-GPU para el aprendizaje profundo con un presupuesto limitado, ...

Conoce a BLIVA un modelo de lenguaje multimodal grande para manejar mejor preguntas visuales ricas en texto
Recientemente, los Modelos de Lenguaje Grande (LLMs) han desempeñado un papel crucial en el campo de la comprensión d...

Una nueva investigación de IA de Tel Aviv y la Universidad de Copenhague introduce un enfoque de conectar y usar para ajustar rápidamente modelos de difusión de texto a imagen utilizando una señal discriminativa.
Los modelos de difusión de texto a imagen han demostrado un impresionante éxito en la generación de imágenes diversas...
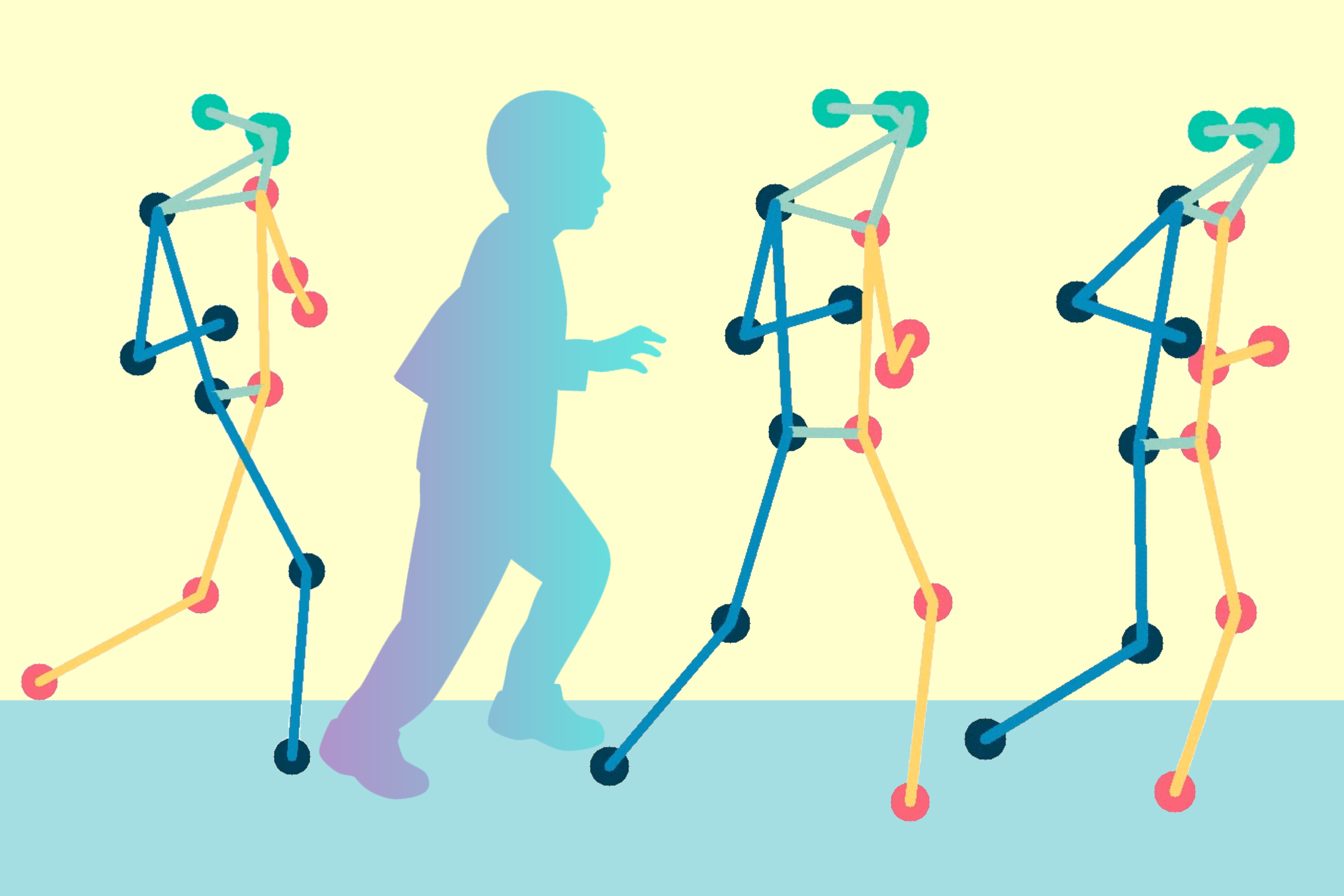
Una técnica de mapeo de posturas podría evaluar de forma remota a pacientes con parálisis cerebral
El método de aprendizaje automático funciona en la mayoría de los dispositivos móviles y podría ampliarse para evalua...

¿Pueden los robots cuadrúpedos de bajo costo dominar el parkour? Revelando un revolucionario sistema de aprendizaje para el movimiento ágil de robots
La búsqueda de hacer que los robots realicen tareas físicas complejas, como navegar por entornos desafiantes, ha sido...

¿Ha terminado la espera por Jurassic Park? Este modelo de IA utiliza la traducción de imagen a imagen para dar vida a los antiguos fósiles
La traducción de imagen a imagen (I2I) es un campo interesante dentro de la visión por computadora y el aprendizaje a...

¿Cómo podemos mitigar el sesgo inducido por el fondo en la clasificación de imágenes de granularidad fina? Un estudio comparativo de estrategias de enmascaramiento y arquitecturas de modelos
La categorización de imágenes de granularidad fina se adentra en distinguir subclases estrechamente relacionadas dent...

Conoce a PhysObjects Un conjunto de datos centrado en objetos con 36.9K anotaciones físicas obtenidas de la colaboración de la multitud y 417K anotaciones físicas automáticas de objetos comunes del hogar.
En el mundo real, la información se transmite a menudo a través de una combinación de imágenes, texto o videos. Para ...

Conoce ResFields Un enfoque novedoso de IA para superar las limitaciones de los campos neurales espaciotemporales en la modelización efectiva de señales temporales largas y complejas.
La arquitectura de red neuronal más popular para representar campos neuronales continuos espacio-temporales, también ...

Esta investigación de IA presenta Point-Bind un modelo de multimodalidad 3D que alinea nubes de puntos con imágenes 2D, lenguaje, audio y video
En el actual panorama tecnológico, la visión 3D ha emergido como una estrella en ascenso, capturando el foco de atenc...

Conoce a CityDreamer Un modelo generativo compositivo para ciudades 3D ilimitadas
La creación de entornos naturales en 3D ha sido objeto de mucha investigación en los últimos años. Se han realizado a...

Conoce LLaSM Un modelo de habla y lenguaje multimodal grande y entrenado de principio a fin con habilidades conversacionales cruzadas capaz de seguir instrucciones de habla y lenguaje.
El habla lleva más información que la escritura, ya que incluye información semántica y paralingüística como el tono....

Fusión de imágenes de IA y DGX GH200
En el ámbito de la Visión por Computadora (CV), la capacidad de unir imágenes parciales y medir dimensiones no es sol...

¿Puede la IA realmente restaurar detalles faciales de imágenes de baja calidad? Conozca DAEFR un marco de doble rama para mejorar la calidad
En el campo del procesamiento de imágenes, recuperar información de alta definición de fotografías faciales de mala c...

¿Se entienden Do Flamingo y DALL-E? Explorando la simbiosis entre los modelos de generación de subtítulos de imágenes y síntesis de texto a imagen
La investigación multimodal que mejora la comprensión de la computadora de texto e imágenes ha avanzado mucho recient...

- You may be interested
- Inteligencia Artificial (IA) y Web3 ¿Có...
- Aprendamos IA juntos – Boletín de...
- Conoce a BLIVA un modelo de lenguaje mu...
- Alper Tekin, Director de Productos en F...
- Los mejores artículos importantes de Vi...
- Esta investigación de IA presenta un nu...
- Amazon Transcribe anuncia un nuevo sist...
- Investigadores del MIT introducen la té...
- Manejando el procesamiento de datos por...
- La pantalla 3D podría llevar el tacto a...
- Cómo un socio académico puede ayudarte ...
- Todas tus publicaciones en línea ahora ...
- ¿Cuántos datos necesitamos? Equilibrand...
- PyrOSM trabajando con datos de Open Str...
- IA y sus Posibilidades/Destrucciones en...
Find your business way
Globalization of Business, We can all achieve our own Success.