Superando barreras en la tecnología de voz multilingüe las 5 principales desafíos y soluciones innovadoras
Superando barreras en la tecnología de voz multilingüe desafíos y soluciones innovadoras
Introducción
¿Cuántas veces has tenido que hacer una pausa después de preguntarle algo a tu asistente de voz en español, tu idioma preferido, y luego reformular tu pregunta en el idioma que el asistente de voz entiende, probablemente inglés, porque el asistente de voz no entendió tu solicitud en español? ¿O cuántas veces has tenido que pronunciar deliberadamente mal el nombre de tu artista favorito A. R. Rahman al pedirle a tu asistente de voz que reproduzca su música porque sabes que si dices su nombre de la manera correcta, el asistente de voz simplemente no lo entenderá, pero si dices A. R. Ramen, el asistente de voz lo entenderá? Además, ¿cuántas veces has sentido repulsión cuando el asistente de voz, con su voz tranquilizadora y omnisciente, destroza el nombre de tu musical favorito Les Misérables y lo pronuncia claramente como “Les Miz-er-ables”?
A pesar de que los asistentes de voz se han vuelto populares hace aproximadamente una década, todavía siguen siendo simplistas, especialmente en su comprensión de las solicitudes de los usuarios en contextos multilingües. En un mundo donde los hogares multilingües están en aumento y la base de usuarios existente y potencial se está volviendo cada vez más global y diversa, es fundamental que los asistentes de voz se vuelvan fluidos cuando se trata de comprender las solicitudes de los usuarios, independientemente de su idioma, dialecto, acento, tono, modulación y otras características del habla. Sin embargo, los asistentes de voz siguen estando muy rezagados cuando se trata de poder tener conversaciones fluidas con los usuarios de la misma forma en que los humanos lo hacen entre sí. En este artículo, analizaremos cuáles son los principales desafíos para hacer que los asistentes de voz funcionen en múltiples idiomas y cuáles podrían ser algunas estrategias para mitigar estos desafíos. Utilizaremos un asistente de voz hipotético llamado Nova a lo largo de este artículo, con fines ilustrativos.
- Nvidia libera un chip de IA revolucionario para acelerar aplicaciones de IA generativa
- ¿La lluvia predice lluvia? Datos meteorológicos de Estados Unidos y la correlación entre la lluvia de hoy y mañana
- Tendencias en evolución en la ingeniería de indicaciones para modelos de lenguaje grandes (LLMs) con prácticas de IA responsable incorporadas
Cómo funcionan los asistentes de voz
Antes de adentrarnos en los desafíos y oportunidades con respecto a hacer que las experiencias de los usuarios de los asistentes de voz sean multilingües, veamos una descripción general de cómo funcionan los asistentes de voz. Utilizando a Nova como el asistente de voz hipotético, veremos cómo es el flujo de extremo a extremo para pedir una canción (referencia).
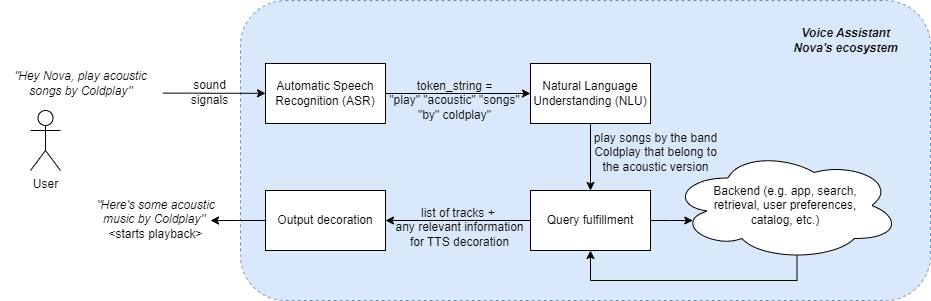
Como se muestra en la Fig. 1, cuando un usuario le pide a Nova que reproduzca música acústica de la popular banda Coldplay, esta señal de sonido del usuario se convierte primero en una cadena de tokens de texto, como primer paso en la interacción humano-asistente de voz. Esta etapa se llama Reconocimiento Automático del Habla (ASR, por sus siglas en inglés) o Conversión de Voz a Texto (STT, por sus siglas en inglés). Una vez que la cadena de tokens está disponible, se pasa al paso de Comprensión del Lenguaje Natural, donde el asistente de voz intenta entender el significado semántico y sintáctico de la intención del usuario. En este caso, la Comprensión del Lenguaje Natural del asistente de voz interpreta que el usuario está buscando canciones de la banda Coldplay (es decir, interpreta que Coldplay es una banda) que sean acústicas (es decir, busca metadatos de canciones en la discografía de esta banda y selecciona solo las canciones con versión = acústica). Esta comprensión de la intención del usuario se utiliza luego para hacer consultas en el backend y encontrar el contenido que el usuario está buscando. Finalmente, el contenido real que el usuario está buscando y cualquier otra información adicional necesaria para presentar esta salida al usuario se lleva al siguiente paso. En este paso, la respuesta y cualquier otra información disponible se utilizan para decorar la experiencia del usuario y responder satisfactoriamente a la consulta del usuario. En este caso, sería una salida de Texto a Voz (TTS, por sus siglas en inglés) (“aquí tienes algo de música acústica de Coldplay”), seguido de la reproducción de las canciones reales que se seleccionaron para esta consulta del usuario.
Desafíos en la construcción de asistentes de voz multilingües
Los asistentes de voz multilingües implican asistentes de voz que pueden entender y responder en varios idiomas, ya sea que sean hablados por la misma persona o personas, o si son hablados por la misma persona en la misma oración mezclados con otro idioma (por ejemplo, “Nova, arrêt! Reproduce algo más”). A continuación, se presentan los principales desafíos en los asistentes de voz cuando se trata de poder operar sin problemas en un entorno multilingüe.
- Cantidad y calidad de los recursos lingüísticos inadecuados
Para que un asistente de voz pueda analizar y comprender bien una consulta, necesita ser entrenado con una cantidad significativa de datos de entrenamiento en ese idioma. Estos datos incluyen datos de voz de seres humanos, anotaciones para la verdad del terreno, vastas cantidades de corpus de texto, recursos para una mejor pronunciación de TTS (por ejemplo, diccionarios de pronunciación) y modelos de lenguaje. Si bien estos recursos están fácilmente disponibles para idiomas populares como el inglés, español y alemán, su disponibilidad es limitada o incluso inexistente para idiomas como el suajili, pastún o checo. Aunque estos idiomas son hablados por suficiente gente, no existen recursos estructurados disponibles para ellos. Crear estos recursos para múltiples idiomas puede ser costoso, complejo y requerir mucho trabajo manual, lo que dificulta el progreso.
- Variaciones en el Lenguaje
Los idiomas tienen dialectos, acentos, variaciones y adaptaciones regionales diferentes. Lidiar con estas variaciones es un desafío para los asistentes de voz. A menos que un asistente de voz se adapte a estos matices lingüísticos, sería difícil entender correctamente las solicitudes de los usuarios o poder responder en el mismo tono lingüístico para ofrecer una experiencia natural y más parecida a la humana. Por ejemplo, solo en el Reino Unido hay más de 40 acentos en inglés. Otro ejemplo es cómo el español hablado en México es diferente del hablado en España.
- Identificación y Adaptación de Idiomas
Es común que los usuarios multilingües cambien de idioma durante sus interacciones con otras personas, y es posible que esperen las mismas interacciones naturales con los asistentes de voz. Por ejemplo, “Hinglish” es un término comúnmente utilizado para describir el lenguaje de una persona que utiliza palabras tanto del hindi como del inglés al hablar. Ser capaz de identificar el o los idiomas con los que el usuario interactúa con el asistente de voz y adaptar las respuestas en consecuencia es un desafío difícil que ningún asistente de voz convencional puede hacer hoy en día.
- Traducción de Idiomas
Una forma de ampliar la capacidad del asistente de voz a múltiples idiomas podría ser traducir la salida del ASR de un idioma no tan común como el luxemburgués a un idioma que pueda ser interpretado de manera más precisa por la capa de NLU, como el inglés. Las tecnologías de traducción comúnmente utilizadas incluyen el uso de una o más técnicas como la traducción automática neuronal (NMT), la traducción automática estadística (SMT), la traducción automática basada en reglas (RBMT) y otras. Sin embargo, estos algoritmos pueden no escalar bien para conjuntos de idiomas diversos y también pueden requerir un extenso conjunto de datos de entrenamiento. Además, a menudo se pierden matices específicos del idioma y las versiones traducidas suelen parecer extrañas e artificiales. La calidad de las traducciones sigue siendo un desafío persistente en términos de poder ampliar los asistentes de voz multilingües. Otro desafío en el paso de la traducción es la latencia que introduce, degradando la experiencia de interacción entre humano y asistente de voz.
- Verdadero Entendimiento del Lenguaje
Los idiomas a menudo tienen estructuras gramaticales únicas. Por ejemplo, mientras que el inglés tiene el concepto de singular y plural, el sánscrito tiene 3 (singular, dual, plural). También puede haber diferentes modismos que no se traducen bien a otros idiomas. Finalmente, también puede haber matices culturales y referencias culturales que pueden ser mal traducidas, a menos que la técnica de traducción tenga una alta calidad de comprensión semántica. Desarrollar modelos de NLU específicos del idioma es costoso.
Superando los Desafíos en la Construcción de Asistentes de Voz Multilingües
Los desafíos mencionados anteriormente son problemas difíciles de resolver. Sin embargo, hay formas en las que estos desafíos se pueden mitigar parcialmente, si no totalmente, de inmediato. A continuación se presentan algunas técnicas que pueden resolver uno o más de los desafíos mencionados anteriormente.
- Aprovechar el Aprendizaje Profundo para Detectar el Idioma
El primer paso para interpretar el significado de una oración es saber a qué idioma pertenece la oración. Aquí es donde entra en juego el aprendizaje profundo. El aprendizaje profundo utiliza redes neuronales artificiales y grandes volúmenes de datos para crear una salida que parece similar a la humana. Las arquitecturas basadas en transformadores (por ejemplo, BERT) han demostrado éxito en la detección de idiomas, incluso en casos de idiomas con pocos recursos. Una alternativa al modelo de detección de idioma basado en transformadores es una red neuronal recurrente (RNN). Un ejemplo de la aplicación de estos modelos es que si un usuario que normalmente habla en inglés de repente habla con el asistente de voz en español un día, el asistente de voz puede detectar e identificar correctamente el español.
- Utilizar la Traducción Automática Contextual para ‘Entender’ la Solicitud
Una vez que se ha detectado el idioma, el siguiente paso para interpretar la oración es tomar la salida de la etapa de ASR, es decir, la cadena de tokens, y traducir esta cadena, no solo literalmente sino también semánticamente, a un idioma que pueda procesarse para generar una respuesta. En lugar de utilizar APIs de traducción que no siempre son conscientes del contexto y las peculiaridades de la interfaz de voz y que también introducen retrasos subóptimos en las respuestas debido a la alta latencia, degradando la experiencia del usuario. Sin embargo, si se integran modelos de traducción automática contextual en los asistentes de voz, las traducciones pueden tener una mayor calidad y precisión debido a ser específicas de un dominio o del contexto de la sesión. Por ejemplo, si un asistente de voz se utiliza principalmente para entretenimiento, puede aprovechar la traducción automática contextual para entender y responder correctamente a preguntas sobre géneros y subgéneros de música, instrumentos musicales y notas, relevancia cultural de ciertas pistas y más.
- Aprovechar los modelos pre-entrenados multilingües
Dado que cada idioma tiene una estructura gramatical única, referencias culturales, frases, modismos y expresiones, y otros matices, resulta desafiante procesar diferentes idiomas. Dado que los modelos específicos de cada idioma son costosos, los modelos pre-entrenados multilingües pueden ayudar a capturar los matices específicos de cada idioma. Modelos como BERT y XLM-R son buenos ejemplos de modelos pre-entrenados que pueden capturar los matices específicos de cada idioma. Por último, estos modelos pueden ser afinados para un dominio específico para aumentar aún más su precisión. Por ejemplo, un modelo entrenado en el ámbito de la música podría no solo entender la consulta, sino también proporcionar una respuesta detallada a través de un asistente de voz. Si se le pregunta a este asistente de voz cuál es el significado de la letra de una canción, podrá responder de una manera mucho más completa que una simple interpretación de las palabras.
- Utilizar modelos de cambio de código
Implementar modelos de cambio de código para poder manejar entradas de lenguaje que mezclan diferentes idiomas puede ser útil en casos en los que un usuario utiliza más de un idioma al interactuar con el asistente de voz. Por ejemplo, si un asistente de voz está diseñado específicamente para una región en Canadá donde los usuarios a menudo mezclan francés e inglés, se puede utilizar un modelo de cambio de código para comprender oraciones dirigidas al asistente de voz que sean una mezcla de ambos idiomas y el asistente de voz podrá manejarlo.
- Aprovechar el aprendizaje por transferencia y el aprendizaje de cero ejemplos para idiomas con pocos recursos
El aprendizaje por transferencia es una técnica en aprendizaje automático en la que un modelo se entrena en una tarea y luego se utiliza como punto de partida para otro modelo en una segunda tarea. Utiliza el aprendizaje de la primera tarea para mejorar el rendimiento de la segunda tarea, superando así en cierta medida el problema del inicio en frío. El aprendizaje de cero ejemplos se produce cuando un modelo pre-entrenado se utiliza para procesar datos que nunca ha visto antes. Tanto el aprendizaje por transferencia como el aprendizaje de cero ejemplos pueden aprovecharse para transferir conocimientos de idiomas con muchos recursos a idiomas con pocos recursos. Por ejemplo, si un asistente de voz ya está entrenado en los 10 idiomas más comunes del mundo, podría utilizarse para entender consultas en idiomas con pocos recursos como el suajili.
Conclusión
En resumen, construir e implementar experiencias multilingües en asistentes de voz es un desafío, pero también existen formas de mitigar algunos de estos desafíos. Al abordar los desafíos mencionados anteriormente, los asistentes de voz podrán ofrecer una experiencia fluida a sus usuarios, independientemente de su idioma. Ashlesha Kadam lidera un equipo global de productos en Amazon Music que crea experiencias musicales en Alexa y en las aplicaciones de Amazon Music (web, iOS, Android) para millones de clientes en más de 45 países. También es una apasionada defensora de las mujeres en la tecnología, y se desempeña como copresidenta de la pista de Interacción Humano-Computadora (HCI, por sus siglas en inglés) para la Celebración Grace Hopper (la conferencia tecnológica más grande para mujeres en tecnología, con más de 30,000 participantes de 115 países). En su tiempo libre, a Ashlesha le encanta leer ficción, escuchar podcasts de negocios y tecnología (su favorito actual es “Acquired”), hacer senderismo en el hermoso Noroeste del Pacífico y pasar tiempo con su esposo, su hijo y su Golden Retriever de 5 años.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- De los Cristales de Tiempo a los Agujeros de Gusano ¿Cuándo es una Simulación Cuántica Real?
- Herramientas de codificación de IA han llegado cómo los equipos de Ingeniería de Productos las utilizarán
- Si los ingenieros comienzan a utilizar herramientas de codificación de IA, ¿qué sucede con nuestros equipos de producto?
- Revisión de Gizzmo AI ¿La mejor herramienta de IA para contenido de afiliados de Amazon?
- Comienza el trabajo en el proyecto para construir la ‘Vía más Sofisticada del Mundo
- Construye una solución centralizada de monitoreo e informes para Amazon SageMaker utilizando Amazon CloudWatch
- Plataforma de Hugging Face en el AWS Marketplace Paga con tu cuenta de AWS






