StackLLaMA Una guía práctica para entrenar LLaMA con RLHF
'StackLLaMA es una guía práctica para entrenar LLaMA con RLHF.'
Modelos como ChatGPT, GPT-4 y Claude son poderosos modelos de lenguaje que han sido afinados utilizando un método llamado Aprendizaje por Reforzamiento a partir de Retroalimentación Humana (RLHF) para estar mejor alineados con cómo esperamos que se comporten y cómo nos gustaría usarlos.
En esta publicación de blog, mostramos todos los pasos involucrados en el entrenamiento de un modelo LlaMa para responder preguntas en Stack Exchange con RLHF a través de una combinación de:
- Afinamiento Supervisado (SFT)
- Modelado de Recompensa/Preferencia (RM)
- Aprendizaje por Reforzamiento a partir de Retroalimentación Humana (RLHF)
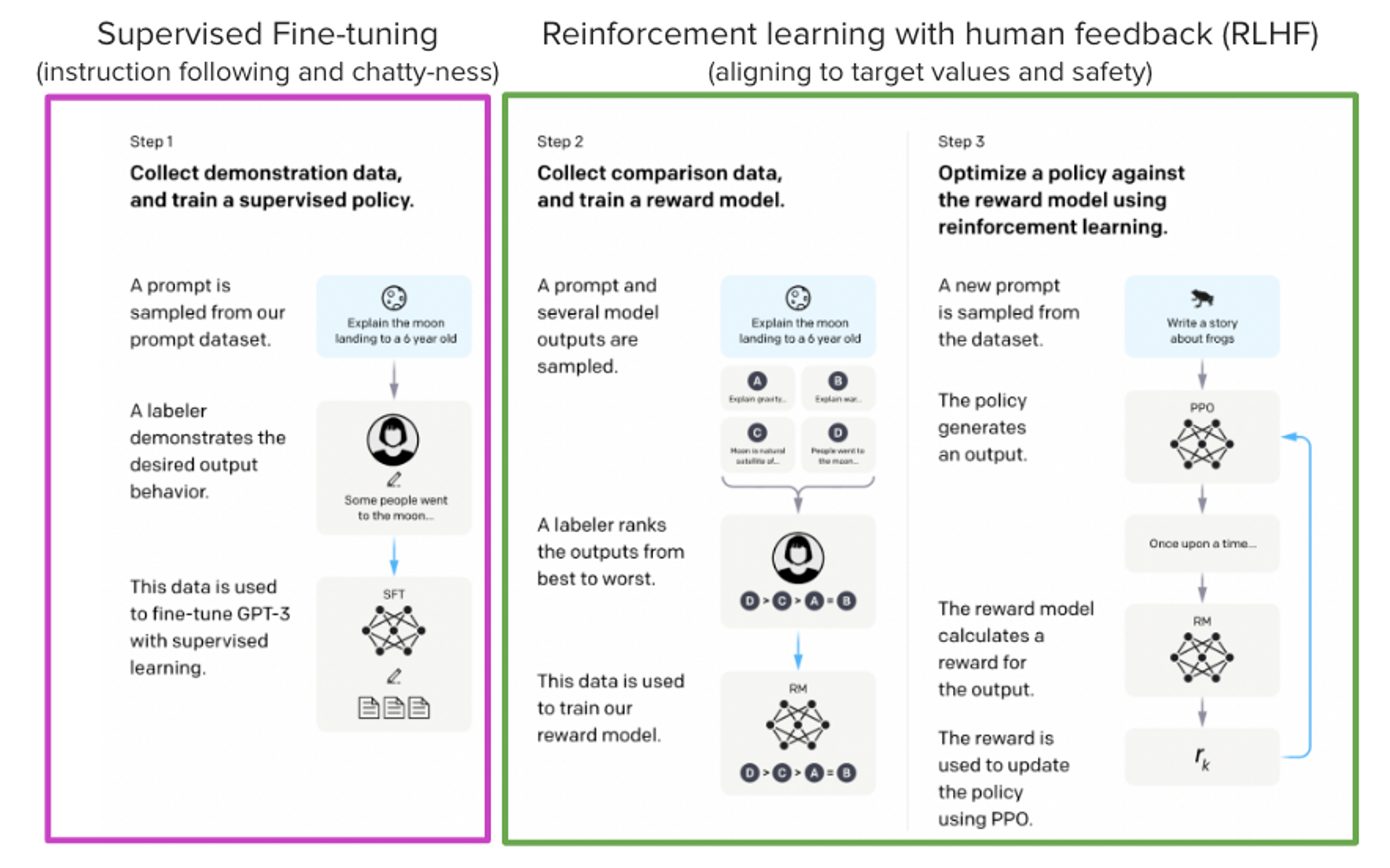 Del artículo InstructGPT: Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
Del artículo InstructGPT: Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
Al combinar estos enfoques, estamos lanzando el modelo StackLLaMA. Este modelo está disponible en el 🤗 Hub (consulte el lanzamiento de LLaMA de Meta para el modelo LLaMA original) y toda la canalización de entrenamiento está disponible como parte de la biblioteca Hugging Face TRL. ¡Para darte una idea de lo que el modelo puede hacer, prueba la demostración a continuación!
- Acelerando Hugging Face Transformers con AWS Inferentia2
- Ejecutando IF con difusores 🧨 en un Google Colab de nivel gratuito
- Cómo instalar y usar la API de Unity de Hugging Face
El modelo LLaMA
Cuando se realiza RLHF, es importante comenzar con un modelo capaz: el paso RLHF es solo un paso de afinamiento para alinear el modelo con cómo queremos interactuar con él y cómo esperamos que responda. Por lo tanto, elegimos utilizar los modelos LLaMA recientemente introducidos y de alto rendimiento. Los modelos LLaMA son los últimos modelos de lenguaje grandes desarrollados por Meta AI. Vienen en tamaños que van desde 7B hasta 65B parámetros y se entrenaron con entre 1T y 1.4T tokens, lo que los hace muy capaces. ¡Utilizamos el modelo de 7B como base para todos los siguientes pasos! Para acceder al modelo, utiliza el formulario de Meta AI.
Conjunto de datos de Stack Exchange
Recopilar retroalimentación humana es una tarea compleja y costosa. Para iniciar el proceso para este ejemplo y al mismo tiempo construir un modelo útil, utilizamos el conjunto de datos de StackExchange. El conjunto de datos incluye preguntas y sus respectivas respuestas de la plataforma StackExchange (incluido StackOverflow para código y muchos otros temas). Es atractivo para este caso de uso porque las respuestas vienen junto con el número de votos positivos y una etiqueta para la respuesta aceptada.
Seguimos el enfoque descrito en Askell et al. 2021 y asignamos a cada respuesta una puntuación:
puntuación = log2 (1 + votos positivos) redondeado al entero más cercano, más 1 si el preguntante aceptó la respuesta (asignamos una puntuación de -1 si el número de votos positivos es negativo).
Para el modelo de recompensa, siempre necesitaremos dos respuestas por pregunta para comparar, como veremos más adelante. Algunas preguntas tienen docenas de respuestas, lo que lleva a muchas posibles parejas. Muestreamos como máximo diez pares de respuestas por pregunta para limitar el número de puntos de datos por pregunta. Por último, limpiamos el formato convirtiendo HTML a Markdown para que las salidas del modelo sean más legibles. Puedes encontrar el conjunto de datos y el cuaderno de procesamiento aquí.
Estrategias de entrenamiento eficientes
Incluso el entrenamiento del modelo LLaMA más pequeño requiere una enorme cantidad de memoria. Algunos cálculos rápidos: en bf16, cada parámetro usa 2 bytes (en fp32 4 bytes) además de los 8 bytes utilizados, por ejemplo, en el optimizador Adam (consulte la documentación de rendimiento en Transformers para obtener más información). Por lo tanto, un modelo de 7B parámetros usaría (2+8)*7B=70GB solo para caber en la memoria y probablemente necesitaría más cuando calcules valores intermedios como puntuaciones de atención. Por lo tanto, no podrías entrenar el modelo incluso en un solo A100 de 80GB. Puedes usar algunos trucos, como optimizadores más eficientes o entrenamiento de precisión reducida, para exprimir un poco más de memoria, pero tarde o temprano te quedarás sin ella.
Otra opción es utilizar técnicas de Afinamiento Eficiente de Parámetros (PEFT), como la biblioteca peft, que puede realizar Adaptación de Rango Bajo (LoRA) en un modelo cargado en 8 bits.
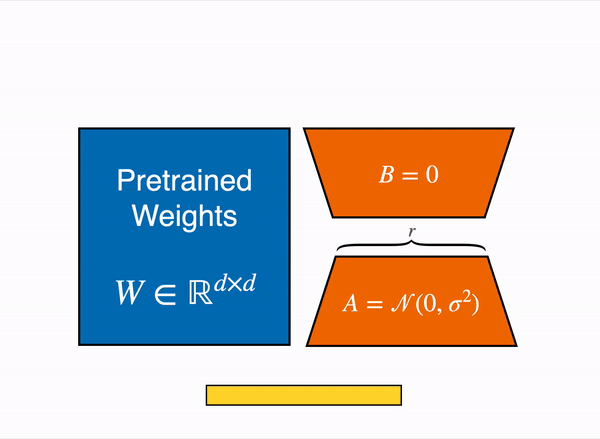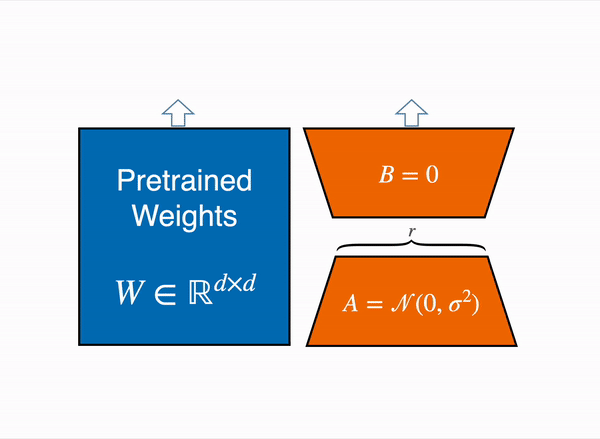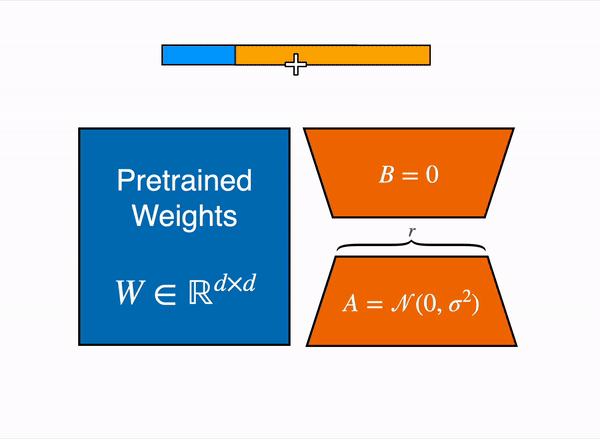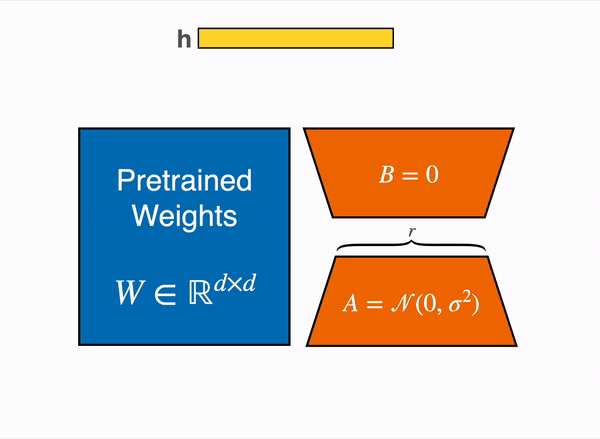 Adaptación de Rango Bajo de capas lineales: se agregan parámetros adicionales (en naranja) junto a la capa congelada (en azul), y se suman los estados ocultos codificados resultantes junto con los estados ocultos de la capa congelada.
Adaptación de Rango Bajo de capas lineales: se agregan parámetros adicionales (en naranja) junto a la capa congelada (en azul), y se suman los estados ocultos codificados resultantes junto con los estados ocultos de la capa congelada.
Cargar el modelo en 8 bits reduce drásticamente el uso de memoria, ya que solo se necesita un byte por parámetro para los pesos (por ejemplo, 7B LlaMa ocupa 7GB en memoria). En lugar de entrenar directamente los pesos originales, LoRA agrega capas adaptadoras pequeñas encima de algunas capas específicas (generalmente las capas de atención); de esta manera, se reduce drásticamente el número de parámetros entrenables.
En este escenario, una regla práctica es asignar aproximadamente 1.2-1.4GB por mil millones de parámetros (dependiendo del tamaño del lote y la longitud de la secuencia) para ajustar toda la configuración de ajuste fino. Como se detalla en la publicación de blog adjunta anteriormente, esto permite el ajuste fino de modelos más grandes (hasta modelos de escala de 50-60B en una NVIDIA A100 80GB) a bajo costo.
Estas técnicas han permitido el ajuste fino de modelos grandes en dispositivos de consumo y en Google Colab. Algunas demostraciones destacadas son el ajuste fino de facebook/opt-6.7b (13GB en float16), y openai/whisper-large en Google Colab (15GB de RAM de la GPU). Para obtener más información sobre el uso de peft, consulte nuestro repositorio en GitHub o la publicación de blog anterior (https://huggingface.co/blog/trl-peft) sobre el entrenamiento de modelos de 20 mil millones de parámetros en hardware de consumo.
Ahora podemos ajustar modelos muy grandes en una sola GPU, pero el entrenamiento aún puede ser muy lento. La estrategia más simple en este escenario es el paralelismo de datos: replicamos la misma configuración de entrenamiento en GPUs separadas y pasamos lotes diferentes a cada GPU. Con esto, puede paralelizar los pases hacia adelante/atrás del modelo y escalar con el número de GPUs.
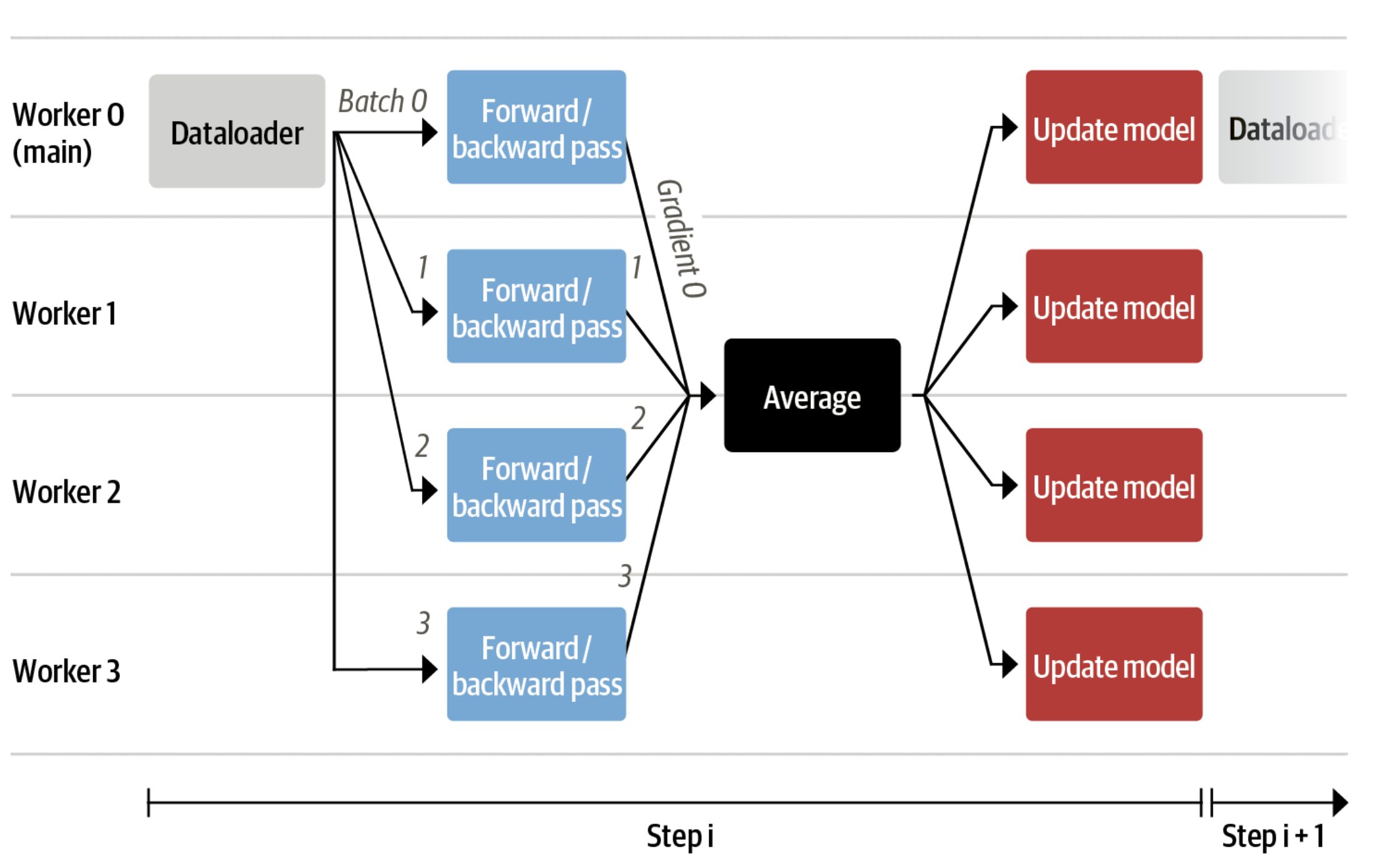
Utilizamos tanto transformers.Trainer como accelerate, que admiten el paralelismo de datos sin ningún cambio de código, simplemente pasando argumentos al llamar a los scripts con torchrun o accelerate launch. Lo siguiente ejecuta un script de entrenamiento con 8 GPUs en una sola máquina con accelerate y torchrun, respectivamente.
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.pyAjuste fino supervisado
Antes de comenzar a entrenar modelos de recompensa y ajustar nuestro modelo con RL, es útil que el modelo ya sea bueno en el dominio en el que estamos interesados. En nuestro caso, queremos que responda preguntas, mientras que para otros casos de uso, puede que queramos que siga instrucciones, en cuyo caso el ajuste de instrucciones es una gran idea. La forma más sencilla de lograr esto es continuar entrenando el modelo de lenguaje con el objetivo de modelado de lenguaje en textos del dominio o tarea. El conjunto de datos de StackExchange es enorme (más de 10 millones de instrucciones), por lo que podemos entrenar fácilmente el modelo de lenguaje en un subconjunto de él.
No hay nada especial en el ajuste fino del modelo antes de hacer RLHF, es simplemente el objetivo de modelado de lenguaje causal del preentrenamiento que aplicamos aquí. Para utilizar los datos de manera eficiente, utilizamos una técnica llamada empaquetado: en lugar de tener un texto por muestra en el lote y luego rellenar hasta el texto más largo o el contexto máximo del modelo, concatenamos muchos textos con un token EOS entre ellos y cortamos fragmentos del tamaño del contexto para llenar el lote sin ningún relleno.
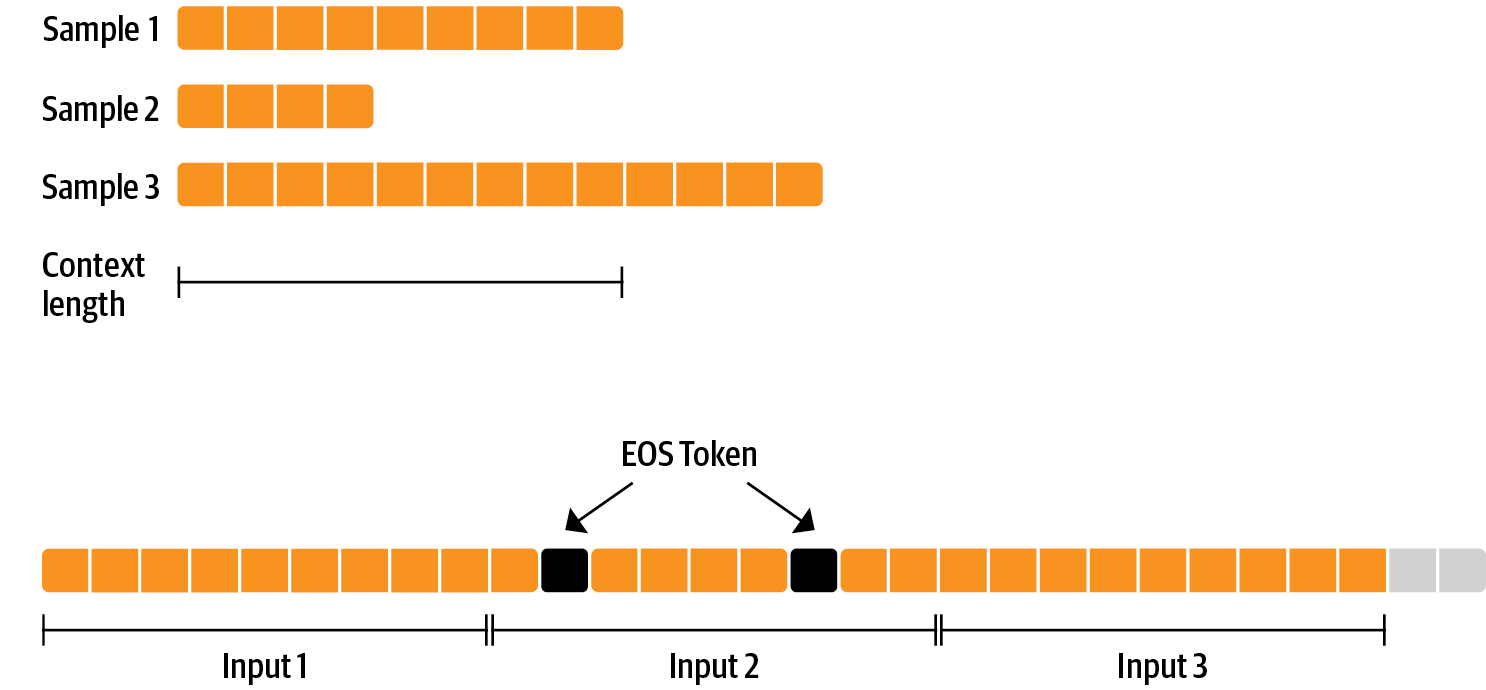
Con este enfoque, el entrenamiento es mucho más eficiente, ya que cada token que se pasa a través del modelo también se entrena en contraste con los tokens de relleno que generalmente se ocultan en la pérdida. Si no tienes muchos datos y te preocupa ocasionalmente cortar algunos tokens que desbordan el contexto, también puedes usar un cargador de datos clásico.
El empaquetado es manejado por ConstantLengthDataset y luego podemos usar el Trainer después de cargar el modelo con peft. Primero, cargamos el modelo en int8, lo preparamos para el entrenamiento y luego agregamos los adaptadores LoRA.
# cargar modelo en 8 bits
modelo = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
modelo = prepare_model_for_int8_training(model)
# agregar LoRA al modelo
config_lora = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
modelo = get_peft_model(model, config)Entrenamos el modelo durante varios miles de pasos con el objetivo de modelado de lenguaje causal y guardamos el modelo. Dado que ajustaremos el modelo nuevamente con diferentes objetivos, fusionamos los pesos del adaptador con los pesos originales del modelo.
Descargo de responsabilidad: debido a la licencia de LLaMA, solo publicamos los pesos del adaptador para esto y los puntos de control del modelo en las siguientes secciones. Puede solicitar acceso a los pesos del modelo base completando el formulario de Meta AI y luego convertirlos al formato de 🤗 Transformers ejecutando este script. Tenga en cuenta que también deberá instalar 🤗 Transformers desde la fuente hasta que se lance la versión v4.28.
Ahora que hemos ajustado el modelo para la tarea, estamos listos para entrenar un modelo de recompensa.
Modelado de recompensa y preferencias humanas
En principio, podríamos ajustar el modelo usando RLHF directamente con las anotaciones humanas. Sin embargo, esto requeriría enviar algunas muestras a los humanos para que las califiquen después de cada iteración de optimización. Esto es costoso y lento debido al número de muestras de entrenamiento necesarias para la convergencia y la latencia inherente de la lectura humana y la velocidad del anotador.
Un truco que funciona bien en lugar de la retroalimentación directa es entrenar un modelo de recompensa con las anotaciones humanas recopiladas antes del bucle RL. El objetivo del modelo de recompensa es imitar cómo un humano calificaría un texto. Hay varias estrategias posibles para construir un modelo de recompensa: la forma más directa sería predecir la anotación (por ejemplo, una puntuación o un valor binario para “bueno” / “malo”). En la práctica, lo que funciona mejor es predecir la clasificación de dos ejemplos, donde el modelo de recompensa se presenta con dos candidatos ( y k , y j ) (y_k, y_j) ( y k , y j ) para una determinada indicación x x x y debe predecir cuál sería calificado más alto por un anotador humano.
Esto se puede traducir en la siguiente función de pérdida:
loss ( θ ) = − E ( x , y j , y k ) ∼ D [ log ( σ ( r θ ( x , y j ) − r θ ( x , y k ) ) ) ] \operatorname{loss}(\theta)=- E_{\left(x, y_j, y_k\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_j\right)-r_\theta\left(x, y_k\right)\right)\right)\right] l o s s ( θ ) = − E ( x , y j , y k ) ∼ D [ lo g ( σ ( r θ ( x , y j ) − r θ ( x , y k ) ) ) ]
donde r r r es la puntuación del modelo y y j y_j y j es el candidato preferido.
Con el conjunto de datos de StackExchange, podemos inferir cuál de las dos respuestas fue preferida por los usuarios en función de la puntuación. Con esa información y la pérdida definida anteriormente, podemos modificar el transformers.Trainer agregando una función de pérdida personalizada.
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return lossUtilizamos un subconjunto de 100,000 pares de candidatos y evaluamos en un conjunto retenido de 50,000. Con un tamaño de lote de entrenamiento modesto de 4, entrenamos el modelo LLaMA utilizando el adaptador peft de LoRA durante una sola época utilizando el optimizador Adam con precisión BF16. Nuestra configuración de LoRA es:
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)El entrenamiento se registra a través de Weights & Biases y tarda algunas horas en 8-A100 GPUs utilizando el clúster de investigación de 🤗 y el modelo logra una precisión final del 67%. Aunque esto parece una puntuación baja, la tarea también es muy difícil, incluso para los anotadores humanos.
Tal como se detalla en la siguiente sección, el adaptador resultante se puede fusionar en el modelo congelado y guardar para su uso posterior.
Aprendizaje por Reforzamiento a partir de Retroalimentación Humana
Con el modelo de lenguaje afinado y el modelo de recompensa disponibles, ahora estamos listos para ejecutar el bucle de RL. Sigue aproximadamente tres pasos:
- Generar respuestas a partir de indicaciones
- Evaluar las respuestas con el modelo de recompensa
- Ejecutar un paso de optimización de la política de aprendizaje por reforzamiento con las evaluaciones
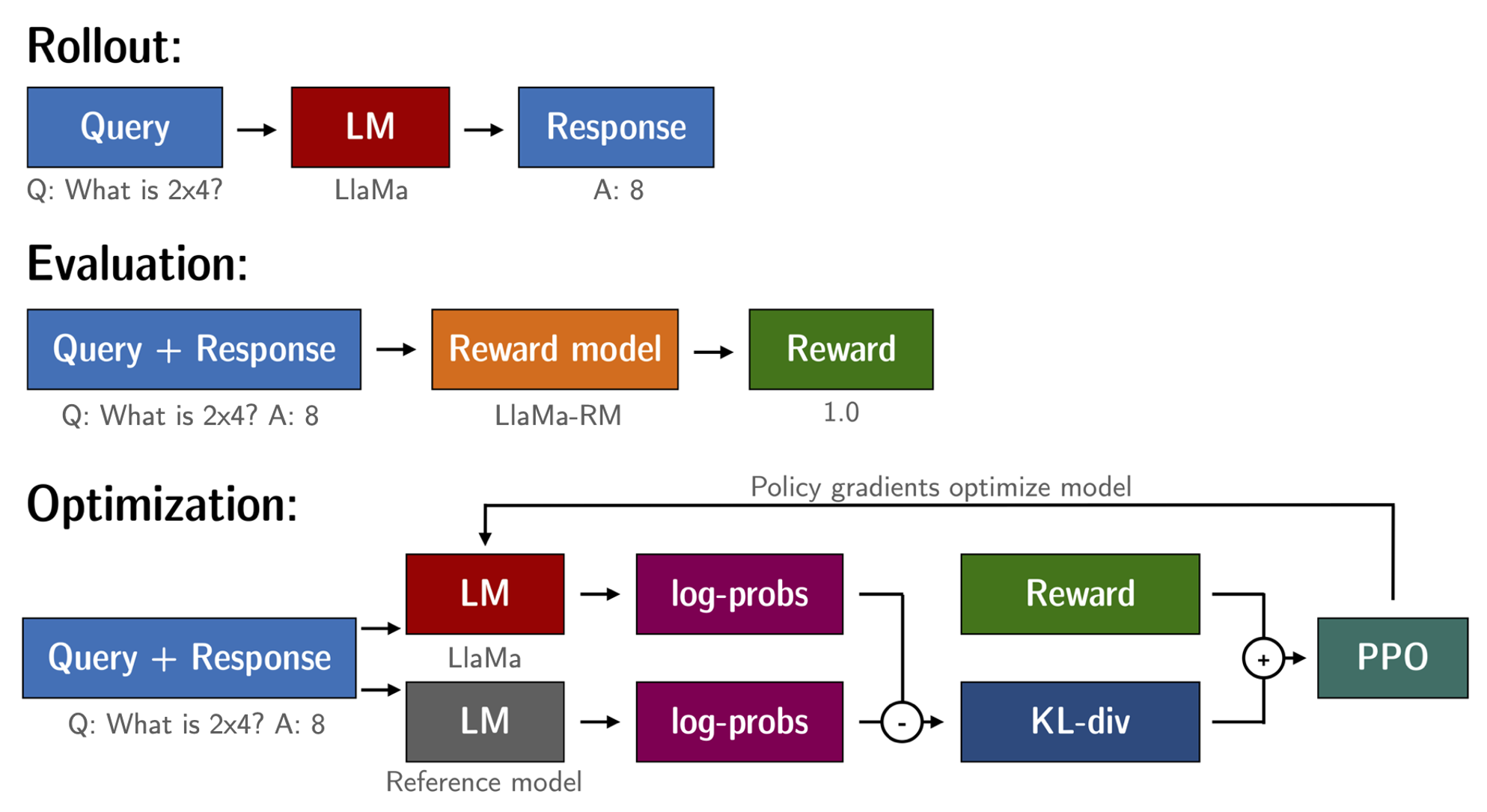
Las indicaciones de consulta y respuesta se plantilla de la siguiente manera antes de ser tokenizadas y pasadas al modelo:
Pregunta: <Consulta>
Respuesta: <Respuesta>La misma plantilla se utilizó para las etapas de SFT, RM y RLHF.
Un problema común al entrenar el modelo de lenguaje con RL es que el modelo puede aprender a explotar el modelo de recompensa generando basura completa, lo que provoca que el modelo de recompensa asigne altas recompensas. Para equilibrar esto, agregamos una penalización a la recompensa: mantenemos una referencia del modelo que no entrenamos y comparamos la generación del nuevo modelo con la referencia calculando la divergencia KL:
R ( x , y ) = r ( x , y ) − β KL ( x , y) \operatorname{R}(x, y)=\operatorname{r}(x, y)- \beta \operatorname{KL}(x, y) R ( x , y ) = r ( x , y ) − β K L ( x , y )
donde r es la recompensa del modelo de recompensa y KL ( x , y ) \operatorname{KL}(x,y) K L ( x , y ) es la divergencia KL entre la política actual y el modelo de referencia.
Una vez más, utilizamos peft para un entrenamiento eficiente en memoria, lo que ofrece una ventaja adicional en el contexto de RLHF. Aquí, el modelo de referencia y la política comparten la misma base, el modelo SFT, que cargamos en 8 bits y congelamos durante el entrenamiento. Optimizamos exclusivamente los pesos de LoRA de la política utilizando PPO mientras compartimos los pesos del modelo base.
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# sample from the policy and generate responses
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# Compute sentiment score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# Run PPO step
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# Log stats to WandB
ppo_trainer.log_stats(stats, batch, rewards)Entrenamos durante 20 horas en 3×8 GPU A100-80GB, utilizando el clúster de investigación de 🤗, pero también se pueden obtener resultados decentes mucho más rápido (por ejemplo, después de ~20h en 8 GPU A100). Todas las estadísticas de entrenamiento de la ejecución de entrenamiento están disponibles en Weights & Biases.
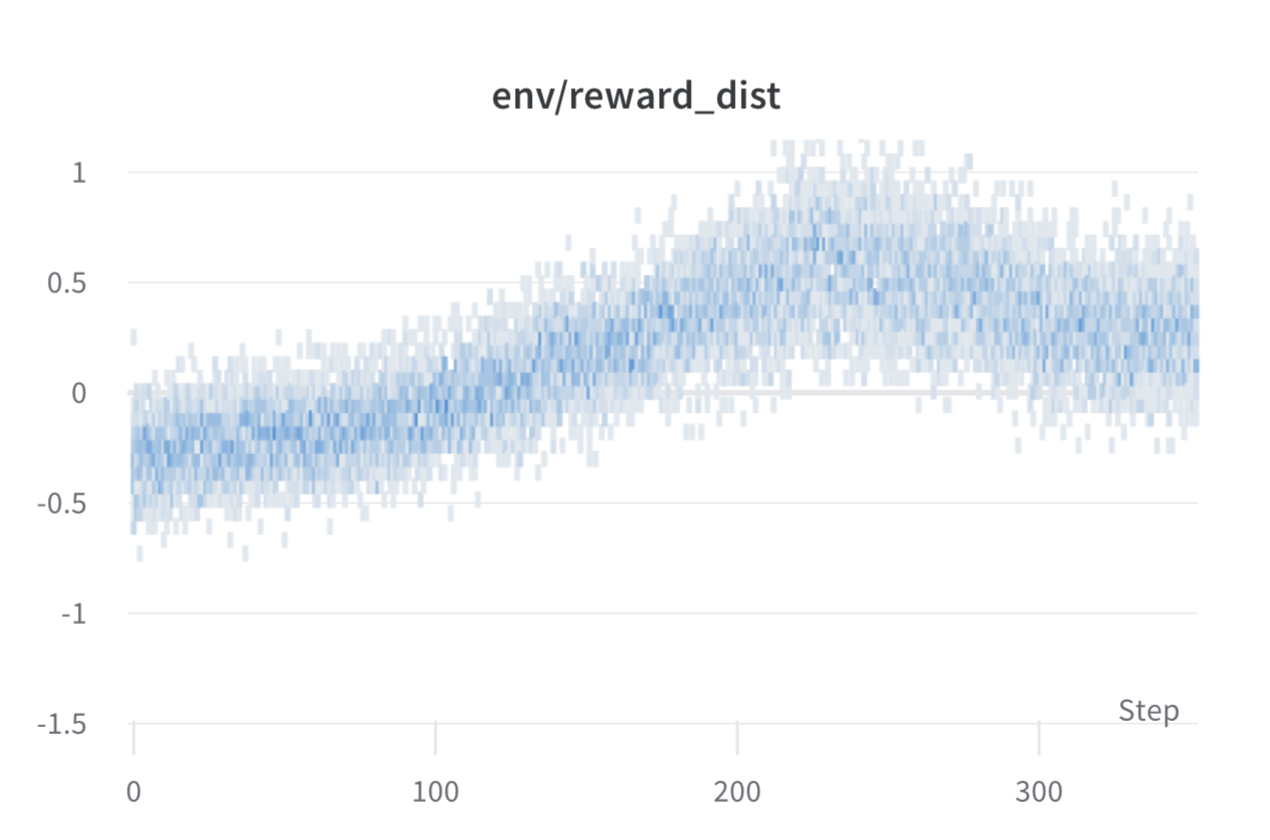 Recompensa por lote en cada paso durante el entrenamiento. El rendimiento del modelo se estabiliza después de alrededor de 1000 pasos.
Recompensa por lote en cada paso durante el entrenamiento. El rendimiento del modelo se estabiliza después de alrededor de 1000 pasos.
Entonces, ¿qué puede hacer el modelo después del entrenamiento? ¡Echemos un vistazo!
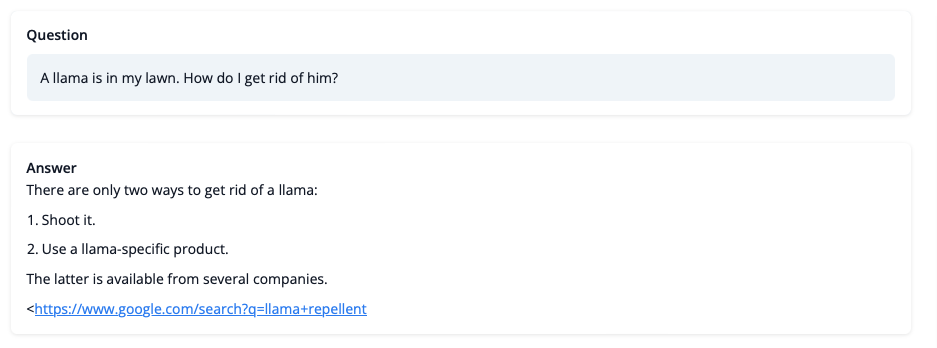
Aunque no debemos confiar en su consejo sobre asuntos de LLaMA por el momento, la respuesta parece coherente e incluso proporciona un enlace de Google. Echemos un vistazo a algunos de los desafíos de entrenamiento a continuación.
Desafíos, inestabilidades y soluciones alternativas
Entrenar LLMs con RL no siempre es un camino fácil. El modelo que demostramos hoy es el resultado de muchos experimentos, ejecuciones fallidas y barridos de hiperparámetros. Aún así, el modelo está lejos de ser perfecto. Aquí compartiremos algunas de las observaciones y dolores de cabeza que encontramos en el camino para crear este ejemplo.
¿Un mayor recompensa significa un mejor rendimiento, verdad?
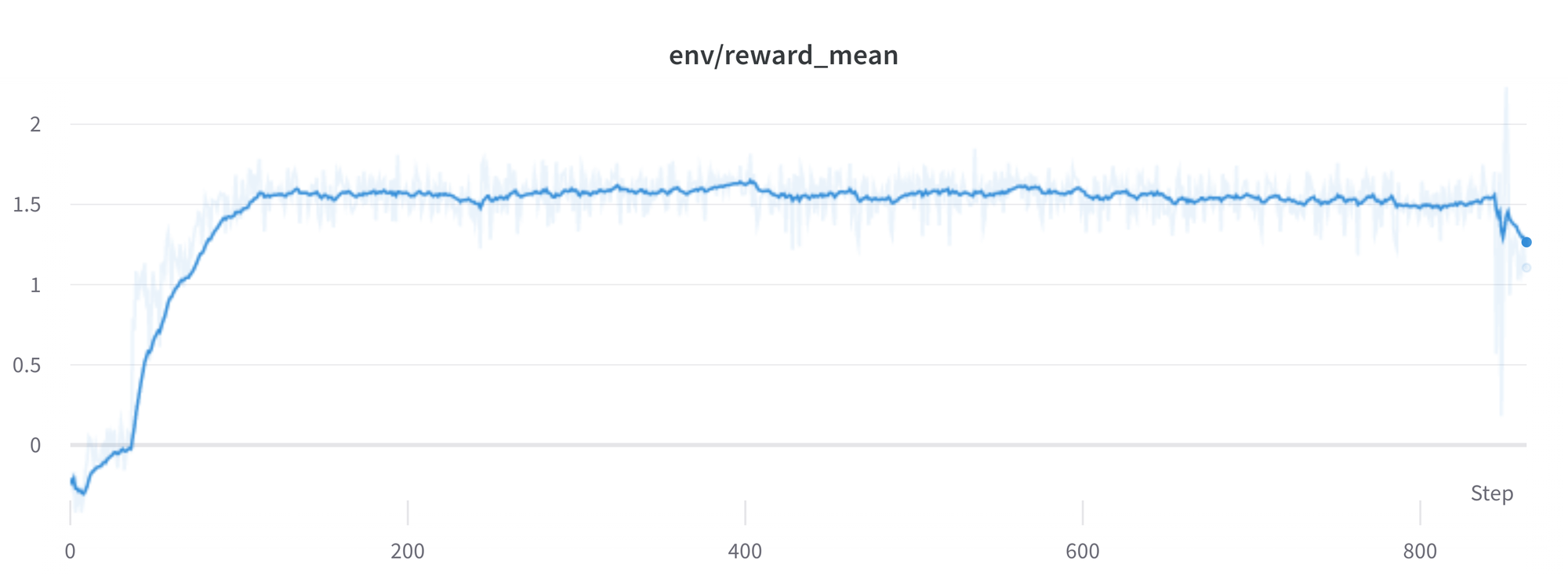 ¡Wow, esta ejecución debe ser genial, mira esa dulce, dulce recompensa!
¡Wow, esta ejecución debe ser genial, mira esa dulce, dulce recompensa!
En general, en RL, quieres alcanzar la recompensa más alta. En RLHF usamos un Modelo de Recompensa, el cual es imperfecto y, de tener la oportunidad, el algoritmo PPO explotará estas imperfecciones. Esto puede manifestarse como aumentos repentinos en la recompensa, sin embargo, cuando observamos las generaciones de texto de la política, en su mayoría contienen repeticiones de la cadena “`, ya que el modelo de recompensa encontró que las respuestas de Stack Exchange que contienen bloques de código suelen tener una clasificación más alta que las que no lo tienen. Afortunadamente, este problema se observó con bastante poca frecuencia y, en general, la penalización KL debería contrarrestar tales explotaciones.
¿La KL siempre es un valor positivo, verdad?
Como mencionamos anteriormente, se utiliza un término de penalización KL para asegurar que las salidas del modelo se mantengan cerca de la política base. En general, la divergencia KL mide las distancias entre dos distribuciones y siempre es una cantidad positiva. Sin embargo, en trl usamos una estimación de la KL que en promedio es igual a la verdadera divergencia KL.
K L p e n ( x , y ) = log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) )
Claramente, cuando se selecciona un token de la política que tiene una probabilidad menor que el modelo SFT, esto dará lugar a una penalización KL negativa, pero en promedio será positiva, de lo contrario no estarías muestreando correctamente de la política. Sin embargo, algunas estrategias de generación pueden forzar que algunos tokens sean generados o suprimir algunos tokens. Por ejemplo, al generar en lotes, las secuencias finalizadas se rellenan y al establecer una longitud mínima, el token EOS se suprime. El modelo puede asignar probabilidades muy altas o bajas a esos tokens, lo que da lugar a una KL negativa. Como el algoritmo PPO optimiza para la recompensa, perseguirá estas penalizaciones negativas, lo que conduce a inestabilidades.
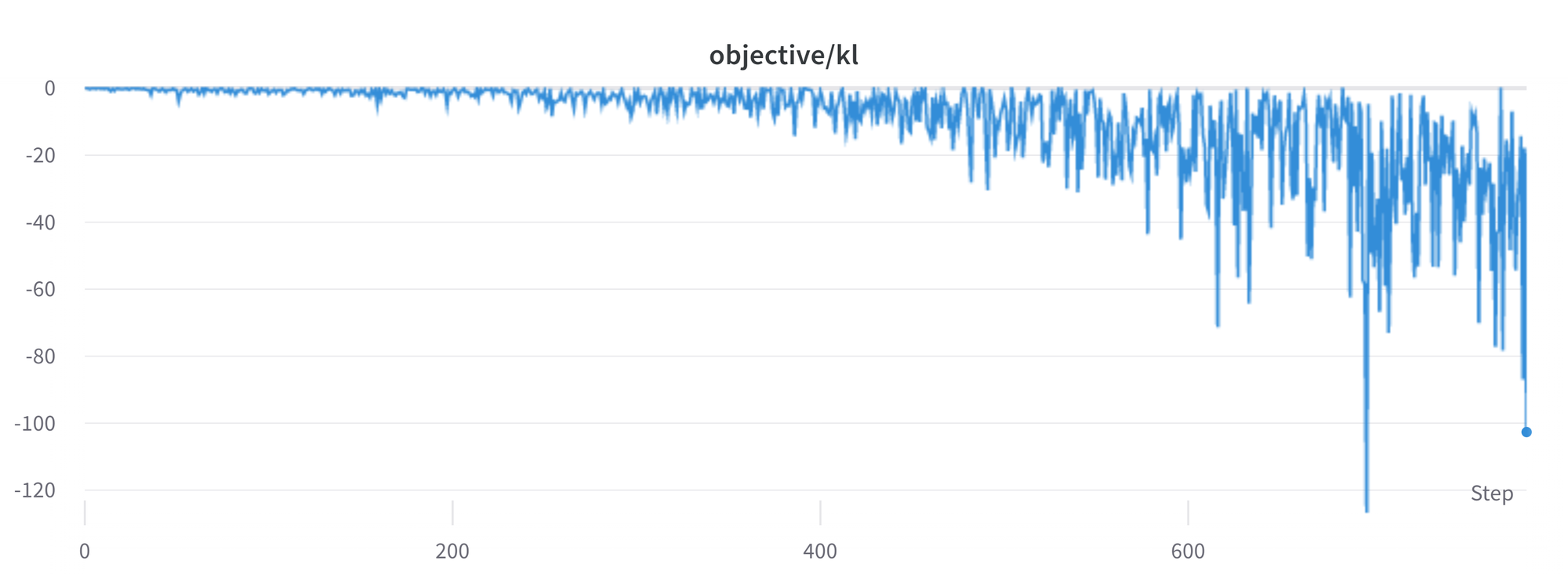
Es necesario tener cuidado al generar las respuestas y sugerimos siempre usar una estrategia de muestreo simple antes de recurrir a métodos de generación más sofisticados.
Problemas en curso
Todavía hay una serie de problemas que debemos entender y resolver mejor. Por ejemplo, ocasionalmente hay picos en la pérdida, lo que puede llevar a más inestabilidades.
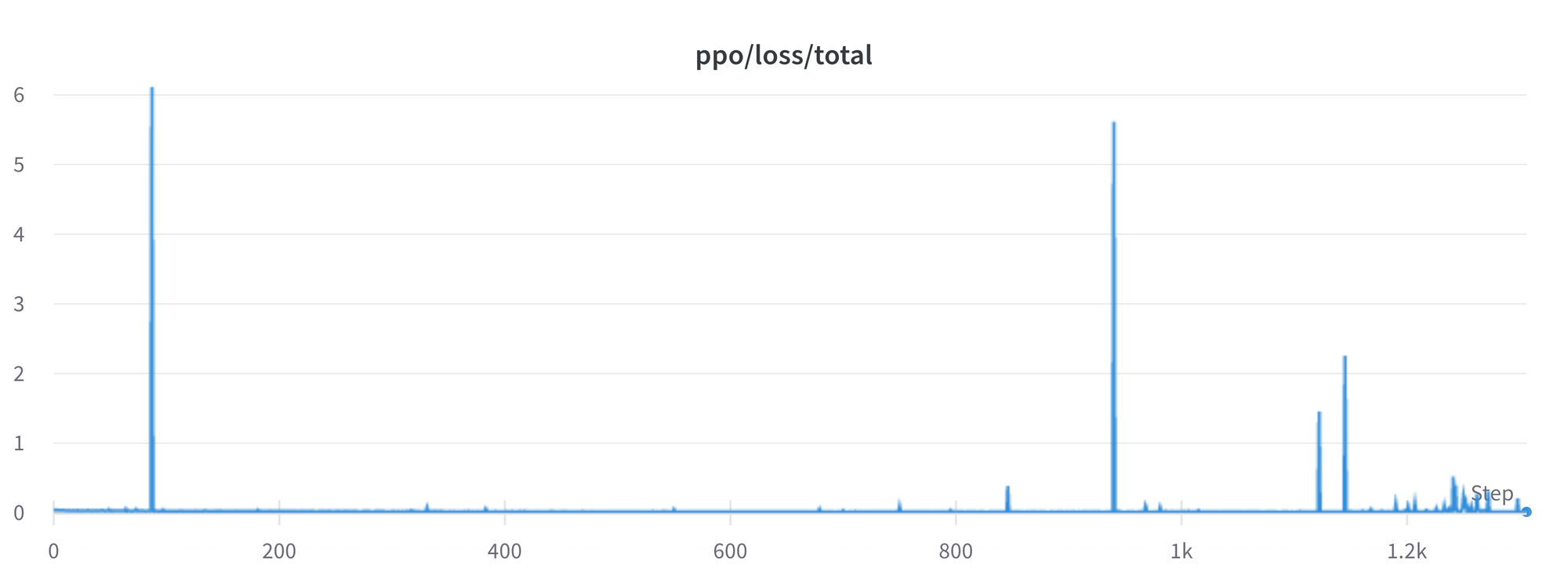
A medida que identificamos y resolvemos estos problemas, compartiremos los cambios con la comunidad en trl para que puedan beneficiarse.
Conclusión
En esta publicación, pasamos por todo el ciclo de entrenamiento para RLHF, comenzando con la preparación de un conjunto de datos con anotaciones humanas, adaptando el modelo de lenguaje al dominio, entrenando un modelo de recompensa y finalmente entrenando un modelo con RL.
¡Usando peft, cualquiera puede ejecutar nuestro ejemplo en una sola GPU! Si el entrenamiento es demasiado lento, puedes usar paralelismo de datos sin cambios en el código y escalar el entrenamiento agregando más GPUs.
¡Para un caso de uso real, este es solo el primer paso! Una vez que tienes un modelo entrenado, debes evaluarlo y compararlo con otros modelos para ver qué tan bueno es. Esto se puede hacer clasificando las generaciones de diferentes versiones del modelo, de manera similar a cómo construimos el conjunto de datos de recompensa.
Una vez que agregas el paso de evaluación, la diversión comienza: puedes comenzar a iterar en tu conjunto de datos y en la configuración de entrenamiento del modelo para ver si hay formas de mejorar el modelo. Podrías agregar otros conjuntos de datos a la mezcla o aplicar mejores filtros al existente. Por otro lado, podrías probar diferentes tamaños de modelo y arquitectura para el modelo de recompensa o entrenar durante más tiempo.
¡Estamos mejorando activamente TRL para que todos los pasos involucrados en RLHF sean más accesibles y estamos emocionados de ver las cosas que la gente construye con él! Echa un vistazo a los problemas en GitHub si estás interesado en contribuir.
Cita
@misc {beeching2023stackllama,
author = { Edward Beeching y
Younes Belkada y
Kashif Rasul y
Lewis Tunstall y
Leandro von Werra y
Nazneen Rajani y
Nathan Lambert
},
title = { StackLLaMA: Un modelo LLaMA afinado por RL para preguntas y respuestas en Stack Exchange },
year = 2023,
url = { https://huggingface.co/blog/stackllama },
doi = { 10.57967/hf/0513 },
publisher = { Hugging Face Blog }
}Agradecimientos
Agradecemos a Philipp Schmid por compartir su maravilloso demo de generación de texto en tiempo real, en el cual se basó nuestro demo. También agradecemos a Omar Sanseviero y Louis Castricato por brindar comentarios valiosos y detallados sobre el borrador de la publicación del blog.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- StarCoder Un LLM de última generación para el código
- Generación Asistida una nueva dirección hacia la generación de texto de baja latencia
- Presentando RWKV – Una RNN con las ventajas de un transformador
- Más pequeño es mejor Q8-Chat, una experiencia eficiente de IA generativa en Xeon
- Deduplicación a gran escala detrás de BigCode
- 🐶Safetensors auditados como realmente seguros y convirtiéndose en la opción predeterminada
- Hugging Face y IBM se unen en watsonx.ai, el estudio empresarial de próxima generación para desarrolladores de IA.





