¡Di una vez! Repetir palabras no ayuda a la IA.
Speak up! Repeating words doesn't help AI.
| INTELIGENCIA ARTIFICIAL | NLP | LLMs
¿Cómo y por qué repetir tokens daña a los LLMs? ¿Por qué es esto un problema?
Los Modelos de Lenguaje Grandes (LLMs) han demostrado sus capacidades y han causado sensación en el mundo. Cada gran empresa ahora tiene un modelo con un nombre elegante. Pero, bajo el capó, todos son transformadores. Todo el mundo sueña con los billones de parámetros, pero ¿no hay límite?
En este artículo, discutimos lo siguiente:
- ¿Está garantizado que un modelo más grande tenga un mejor rendimiento que un modelo pequeño?
- ¿Tenemos los datos para modelos enormes?
- ¿Qué sucede si en lugar de recopilar nuevos datos se utiliza de nuevo los datos?
Escalar sobre el cielo: ¿qué está dañando el ala?
OpenAI ha definido la ley de escala, afirmando que el rendimiento del modelo sigue una ley de potencia según la cantidad de parámetros utilizados y la cantidad de puntos de datos. Esto, junto con la búsqueda de propiedades emergentes, ha creado la carrera de parámetros: cuanto más grande sea el modelo, mejor.
¿Es eso cierto? ¿Los modelos más grandes dan un mejor rendimiento?
Recientemente, las propiedades emergentes han entrado en crisis. Como han demostrado investigadores de Stanford, el concepto de propiedad emergente puede no existir.
Habilidades emergentes en IA: ¿Estamos persiguiendo un mito?
Cambiando la perspectiva sobre las propiedades emergentes de los modelos de lenguaje grandes
towardsdatascience.com
La ley de escala probablemente asigna mucho menos valor al conjunto de datos de lo que se cree en realidad. DeepMind ha demostrado con Chinchilla que no solo se debe pensar en escalar los parámetros sino también los datos. De hecho, Chinchilla demuestra que es superior en capacidad a Gopher (70 B frente a 280 B de parámetros)
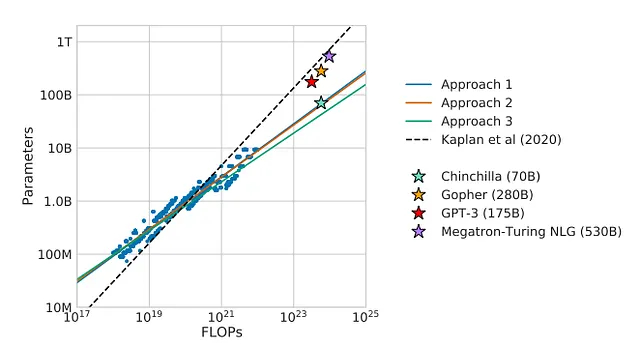
Recientemente, la comunidad de aprendizaje automático se emocionó con LLaMA no solo porque es de código abierto, sino porque la versión de 65 B de parámetros superó a OPT 175 B.
LLaMA de META: un modelo de lenguaje pequeño venciendo a gigantes
El modelo de código abierto de META nos ayudará a entender cómo surgen los sesgos de los LMs
Zepes.com
Como afirma DeepMind en el artículo de Chinchilla, se puede estimar cuántos tokens se requieren para entrenar completamente un LLM de última generación. Por otro lado, también se puede estimar cuántos tokens de alta calidad existen. La investigación reciente se ha preguntado sobre este tema. Concluyeron:
- Los conjuntos de datos de lenguaje han crecido exponencialmente, con un crecimiento anual del 50% en la publicación de conjuntos de datos de lenguaje (hasta 2e12 palabras a finales de 2022). Esto muestra que la investigación y publicación de nuevos conjuntos de datos de lenguaje es un campo muy activo.
- Por otro lado, el número de palabras en Internet (existencia de palabras) está creciendo (y los autores lo estiman entre 7e13 y 7e16 palabras, es decir, de 1,5 a 4,5 órdenes de magnitud).
- Dado que tratan de utilizar un conjunto de palabras de alta calidad, los autores estiman que el conjunto de calidad se encuentra entre 4,6e12 y 1,7e13 palabras. Los autores afirman que entre 2023 y 2027 se habrán agotado el número de palabras de calidad y entre 2030 y 2050 el conjunto completo.
- El conjunto de imágenes tampoco está mucho mejor (tres o cuatro órdenes de magnitud).
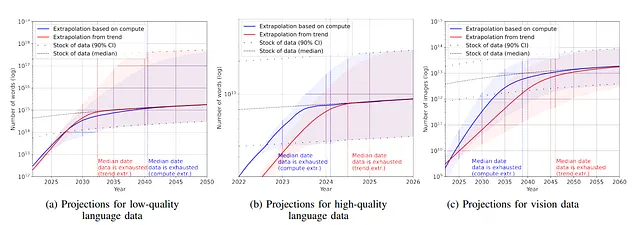
¿Por qué está sucediendo esto?
Bueno, porque nosotros, los humanos, no somos infinitos y no producimos tanto texto como ChatGPT. De hecho, las proyecciones del número de usuarios de Internet (reales y previstos) hablan por sí solas:
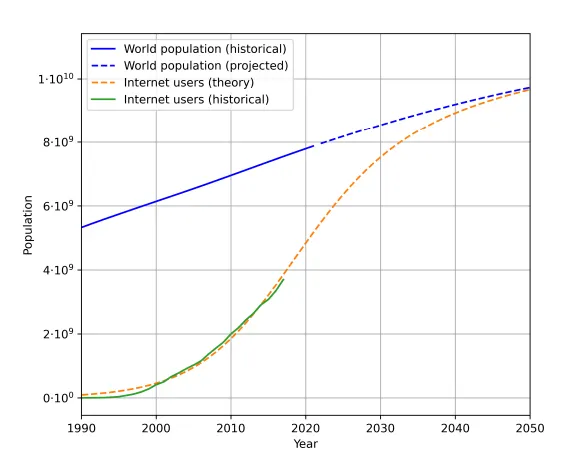
De hecho, no todos están contentos con que se utilicen textos, códigos y otras fuentes para entrenar modelos de inteligencia artificial. De hecho, Wikipedia, Reddit y otras fuentes históricamente utilizadas para entrenar modelos desean que las empresas paguen por utilizar sus datos. En cambio, las empresas están invocando el uso justo, y en la actualidad el panorama de regulación no está claro.
Combinando los datos juntos, se puede ver claramente una tendencia. El número de tokens necesarios para entrenar de manera óptima un LLM está creciendo más rápido que los tokens en stock.
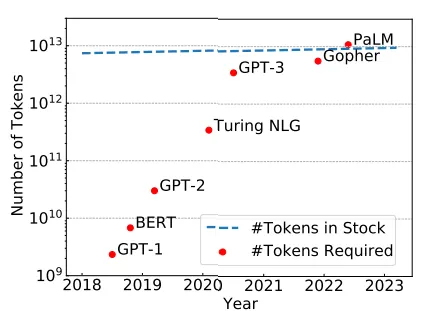
Según la ley de escala definida por Chinchilla (número de tokens necesarios para el entrenamiento óptimo de LLM), ya hemos superado el límite. A partir del gráfico, podemos ver que según estas estimaciones con PaLM-540 B, hemos alcanzado el límite (10,8 billones de tokens requeridos frente a 9 billones en stock).
Algunos autores han llamado a este problema la “crisis de tokens”. Además, hasta ahora solo hemos considerado tokens en inglés, pero existen otras siete mil lenguas. El cincuenta y seis por ciento de toda la web está en inglés, y el resto del cuarenta y cuatro por ciento pertenece a solo 100 otros idiomas. Y esto se refleja en el rendimiento de los modelos en otros idiomas.
¿Podemos obtener más datos?
Como hemos visto, más parámetros no equivale a un mejor rendimiento. Para un mejor rendimiento, necesitamos tokens de calidad (textos), pero estos son escasos. ¿Cómo podemos obtenerlos? ¿Podemos ayudarnos con la inteligencia artificial?
¿Por qué no estamos utilizando Chat-GPT para producir texto?
Si los humanos no estamos produciendo suficiente texto, ¿por qué no automatizar este proceso? Un estudio reciente muestra cómo este proceso no es óptimo. Stanford Alpaca fue entrenado utilizando 52.000 ejemplos derivados de GPT-3, pero aparentemente solo logró un rendimiento similar. En realidad, el modelo aprende el estilo del modelo objetivo pero no su conocimiento.
¿Por qué no entrenar por más tiempo?
Tanto para PaLM, Gopher y LLaMA (también para otros LLM) está claramente escrito que los modelos fueron entrenados durante unos pocos epochs (uno o pocos). Esto no es una limitación del Transformador porque, por ejemplo, los Transformadores de Visión (ViT) han sido entrenados durante 300 epochs en ImageNet (1 millón de imágenes), como se muestra en la tabla:
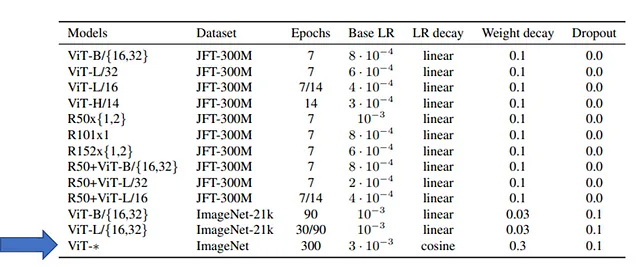
Porque es muy caro. En el artículo de LLaMA, los autores entrenaron solo durante un epoch (y dos epochs solo para parte del conjunto de datos). Sin embargo, los autores informan:
Cuando se entrena un modelo de 65B parámetros, nuestro código procesa alrededor de 380 tokens/seg/GPU en 2048 GPU A100 con 80GB de RAM. Esto significa que el entrenamiento sobre nuestro conjunto de datos que contiene 1,4T de tokens tarda aproximadamente 21 días. ( fuente )
Entrenar un LLM aunque sea por unos pocos epochs es extremadamente costoso. Como lo calculó Dmytro Nikolaiev (Dimid), esto significa 4.0 millones de dólares si entrenas un modelo similar al LLaMA de META en la plataforma Google Cloud.
Por lo tanto, entrenar durante más epochs llevaría a un aumento exponencial en los costos. Además, no sabemos si este entrenamiento adicional es realmente útil: aún no lo hemos probado.
Recientemente, un grupo de investigadores de la Universidad de Singapur estudió qué sucede si entrenamos un LLM durante múltiples epochs:
¿Repetir o no repetir? Ideas de la escalabilidad de LLM bajo crisis de tokens
Investigaciones recientes han destacado la importancia del tamaño del conjunto de datos en la escalabilidad de los modelos de lenguaje. Sin embargo, el lenguaje…
arxiv.org
Repetita iuvant aut continuata secant
Hasta ahora sabemos que el rendimiento de un modelo se deriva no solo por el número de parámetros sino también por la cantidad de tokens de calidad utilizados para entrenar. Por otro lado, estos tokens de calidad no son infinitos y nos estamos acercando al límite. Si no podemos encontrar suficientes tokens de calidad y es una opción generarlos con IA, ¿qué podríamos hacer?
¿Podemos usar el mismo conjunto de entrenamiento y entrenar por más tiempo?
Hay una locución en latín que dice que repetir las cosas beneficia (repetita iuvant), pero con el tiempo alguien agregó “pero lo continuo aburre” (continuata secant).
Lo mismo ocurre con las redes neuronales: aumentar el número de epochs mejora el rendimiento de la red (disminución en la pérdida); en algún momento, sin embargo, mientras que la pérdida en el conjunto de entrenamiento sigue disminuyendo, la pérdida en el conjunto de validación comienza a aumentar. La red neuronal entró en sobreajuste, comenzando a considerar patrones que solo están presentes en el conjunto de entrenamiento y perdiendo la capacidad de generalizar.
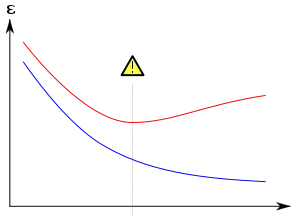
Bueno, esto se ha estudiado extensamente para pequeñas redes neuronales, pero ¿qué pasa con los enormes transformadores?
Los autores de este estudio utilizaron el modelo T5 (modelo codificador-decodificador) en el conjunto de datos C4. Los autores entrenaron varias versiones del modelo, aumentando el número de parámetros hasta que el modelo más grande superó al modelo más pequeño (lo que indica que el modelo más grande recibió un número suficiente de tokens, como la ley de Chinchilla). Los autores observaron que había una relación lineal entre el número de tokens requeridos y el tamaño del modelo (confirmando lo que DeepMind vio con Chinchilla).
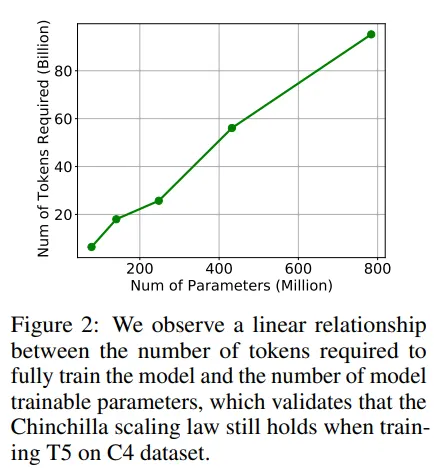
El conjunto de datos C4 es limitado (no tiene tokens infinitos) por lo que para aumentar el número de parámetros los autores se encontraron en una condición de escasez de tokens. Por lo tanto, decidieron simular lo que sucede si un LLM ve datos repetidos. Muestrearon un cierto número de tokens, por lo que el modelo se encontró viéndolos nuevamente en el entrenamiento de tokens. Esto mostró:
- Los tokens repetidos conducen a un rendimiento degradado.
- Los modelos más grandes son más susceptibles al sobreajuste en condiciones de crisis de tokens (por lo que incluso aunque teóricamente consume más recursos computacionales, esto lleva a un rendimiento degradado).
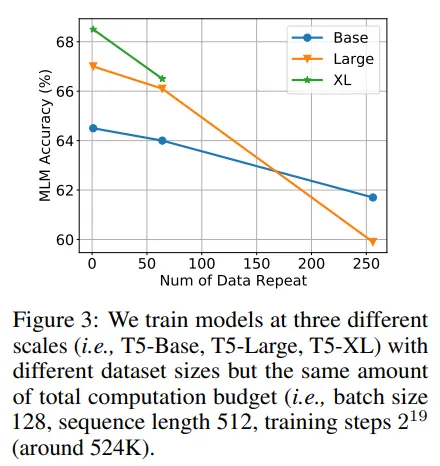
Además, estos modelos se utilizan para tareas secundarias. A menudo, un LLM se entrena sin supervisión con una gran cantidad de texto y luego se ajusta en un conjunto de datos más pequeño para una tarea secundaria. O puede pasar por un proceso llamado alineación (como en el caso de ChatGPT).
Cuando un LLM se entrena con datos repetidos, aunque luego se ajusta en otro conjunto de datos, el rendimiento se degrada. Por lo tanto, las tareas secundarias también se ven afectadas.
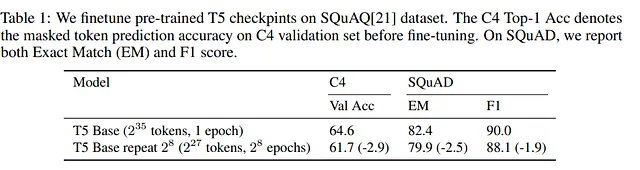
¿Por qué los tokens repetidos no son una buena idea?
Acabamos de ver que los tokens repetidos perjudican el entrenamiento. ¿Pero por qué sucede esto?
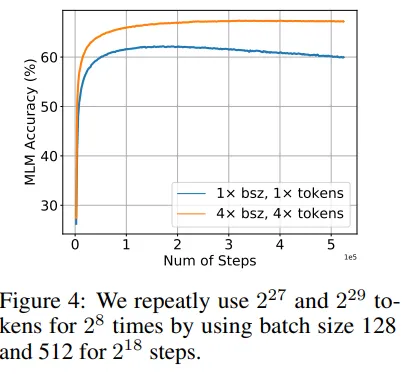
Los autores decidieron investigar manteniendo el número de tokens repetidos fijo y aumentando el número total de tokens en el conjunto de datos. Los resultados muestran que un conjunto de datos más grande alivia los problemas de degradación multi-época.
El año pasado se publicó Galactica (un modelo que se suponía que ayudaría a los científicos pero duró solo tres días). Aparte del espectacular fracaso, el artículo sugirió que parte de sus resultados se debían a la calidad de los datos. Según los autores, la calidad de los datos redujo el riesgo de sobreajuste:
Podemos entrenar con él durante múltiples épocas sin sobreajuste, donde el rendimiento aguas arriba y aguas abajo mejora con el uso de tokens repetidos. ( fuente )
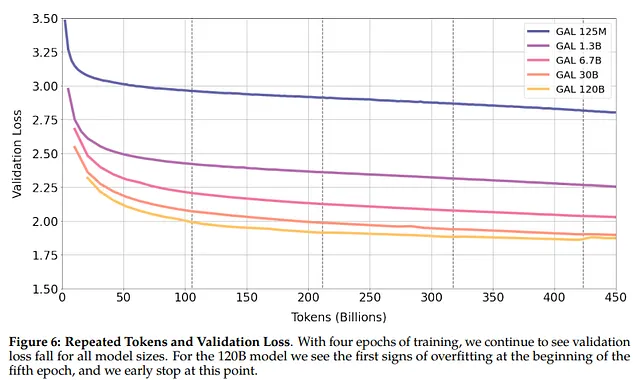
Para los autores, los tokens repetidos no solo no perjudican el entrenamiento del modelo sino que también mejoran el rendimiento aguas abajo.
En este nuevo estudio, los autores utilizan el conjunto de datos de Wikipedia, que se considera de mayor calidad que C4, y agregan tokens repetidos. Los resultados muestran que hay un nivel similar de degradación, lo que va en contra de lo que se afirma en el artículo de Galactica.

Los autores también intentaron investigar si también se debía a la escala del modelo. Durante la escala de un modelo, tanto el número de parámetros como el costo computacional aumentan. Los autores decidieron estudiar estos dos factores individualmente:
- Mixture-of-Experts (MoE) porque aunque aumenta el número de parámetros, mantiene un costo computacional similar.
- ParamShare, por otro lado, reduce el número de parámetros pero mantiene el mismo costo computacional.
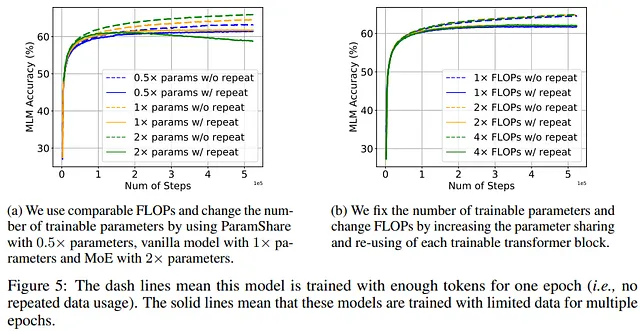
Los resultados muestran que el modelo con menos parámetros se ve menos afectado por los tokens repetidos. En contraste, el modelo MoE (mayor número de parámetros) es más propenso al sobreajuste. El resultado es interesante porque MoE se ha utilizado con éxito en muchos modelos de IA, por lo que los autores sugieren que aunque MoE es una técnica útil cuando hay suficientes datos, puede perjudicar el rendimiento cuando no hay suficientes tokens.
Los autores también exploraron si el entrenamiento objetivo afecta la degradación del rendimiento. En general, hay dos objetivos de entrenamiento:
- Predicción del siguiente token (dado una secuencia de tokens, predecir el siguiente en la secuencia).
- Modelado de lenguaje enmascarado, donde uno o más tokens están enmascarados y se necesita predecirlos.
Recientemente, con PaLM2-2, Google presentó UL2, que es una mezcla entre estos dos objetivos de entrenamiento. UL2 ha demostrado acelerar el entrenamiento del modelo, sin embargo, curiosamente, UL2 es más propenso al sobreajuste y tiene una mayor degradación multi-época.
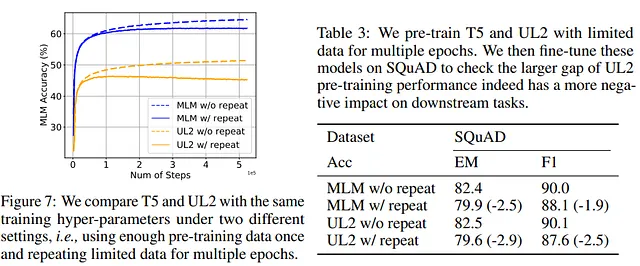
Los autores exploraron cómo podrían tratar de aliviar la degradación multi-época. Dado que las técnicas de regularización se utilizan precisamente para evitar el sobreajuste, los autores probaron si estas técnicas también tenían un efecto beneficioso aquí.
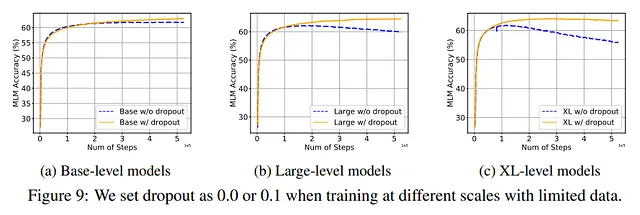
Dropout resulta ser una de las técnicas más eficientes para aliviar el problema. Esto no es sorprendente porque es una de las técnicas de regularización más eficientes, se puede paralelizar fácilmente y es utilizada por la mayoría de los modelos.

Además, los autores descubrieron que funciona mejor comenzar sin dropout y solo en un momento posterior del entrenamiento agregar dropout.

Por otro lado, los autores señalan que el uso de Dropout en algunos modelos, especialmente los más grandes, puede llevar a una ligera reducción en el rendimiento. Entonces, aunque puede tener efectos beneficiosos contra el sobreajuste, podría conducir a comportamientos inesperados en otros contextos. Tanto que los modelos GPT-3, PaLM, LLaMA, Chinchilla y Gopher no lo usan en su arquitectura.
Como se describe en la tabla a continuación, los autores utilizaron para sus experimentos lo que ahora se consideran modelos casi pequeños. Por lo tanto, es costoso probar diferentes hiperparámetros al diseñar un LLM:
Por ejemplo, en nuestro escenario específico, entrenar T5-XL cinco veces requeriría aproximadamente $37,000 USD para alquilar Google Cloud TPUs. Considerando modelos aún más grandes como PaLM y GPT-4, entrenados en conjuntos de datos aún más grandes, este costo se vuelve inmanejable ( fuente )
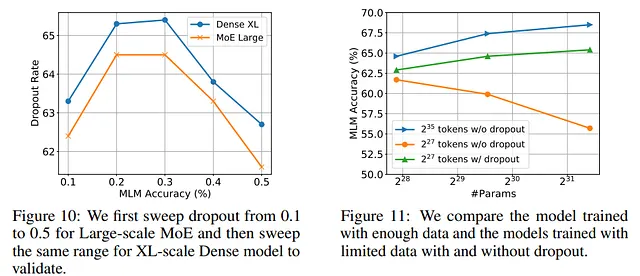
Dado que en sus experimentos, un modelo Sparse MoE aproxima el comportamiento de un modelo denso (que es más computacionalmente costoso), se puede usar para buscar los mejores hiperparámetros.
Por ejemplo, los autores muestran que se pueden probar diferentes tasas de aprendizaje para el modelo MoE y exhibe el mismo rendimiento que el modelo denso equivalente. Entonces, para los autores, se pueden probar diferentes hiperparámetros con el modelo MoE y luego entrenar con los parámetros elegidos el modelo denso, ahorrando costos:
El barrido del modelo MoE Large incurrió en un gasto de aproximadamente 10.6K USD en la plataforma Google Cloud. Por el contrario, el entrenamiento del modelo Dense XL solo requería 7.4K USD. En consecuencia, todo el proceso de desarrollo, incluido el barrido, ascendió a un costo total de 18K USD, que es solo 0.48 veces el gasto de ajustar directamente el modelo Dense XL ( fuente )
Pensamientos finales
En los últimos años ha habido una carrera por tener el modelo más grande. Por un lado, esta carrera ha sido motivada por el hecho de que a cierta escala, surgían propiedades que eran imposibles de predecir con modelos más pequeños. Por otro lado, la ley de escalamiento de OpenAI afirmó que el rendimiento es una función del número de parámetros del modelo.
En el último año este paradigma ha entrado en crisis.
Recientemente, LlaMA ha demostrado la importancia de la calidad de los datos. Además, Chinchilla ha mostrado una nueva regla para calcular el número de tokens necesarios para entrenar un modelo de manera óptima. De hecho, un modelo con cierto número de parámetros requiere una cantidad de datos para funcionar de manera óptima.
Estudios posteriores han demostrado que el número de tokens de calidad no es infinito. Por otro lado, el número de parámetros del modelo crece más que la cantidad de tokens que los seres humanos podemos generar.
Esto llevó a la pregunta de cómo podemos resolver la crisis de tokens. Estudios recientes muestran que usar LLM para generar tokens no es una forma viable. Este nuevo trabajo muestra cómo el uso de los mismos tokens para múltiples épocas puede deteriorar el rendimiento.
Trabajos como este son importantes porque aunque estamos entrenando y usando LLM cada vez más, hay muchos aspectos incluso básicos que no conocemos. Este trabajo responde una pregunta que parece básica pero que los autores responden con datos experimentales: ¿qué sucede cuando se entrena un LLM durante múltiples épocas?
Además, este artículo es parte de una creciente literatura que muestra cómo un aumento acrítico en el número de parámetros no es necesario. Por otro lado, modelos más grandes y grandes son cada vez más costosos y también consumen cada vez más electricidad. Teniendo en cuenta que necesitamos optimizar los recursos, este artículo sugiere que entrenar un modelo enorme sin suficientes datos es simplemente un desperdicio.
Este artículo también muestra cómo necesitamos nuevas arquitecturas que puedan reemplazar al transformador. Así que es hora de enfocar la investigación en nuevas ideas en lugar de seguir escalando modelos.
Si te ha parecido interesante:
Puedes buscar mis otros artículos, también puedes subscribirte para recibir notificaciones cuando publique artículos, puedes convertirte en miembro de Zepes para acceder a todas sus historias (enlaces de afiliados de la plataforma por la que obtengo pequeñas ganancias sin costo para ti) y también puedes conectarte o contactarme en LinkedIn .
Aquí está el enlace a mi repositorio de GitHub, donde planeo recopilar código y muchos recursos relacionados con el aprendizaje automático, la inteligencia artificial y más.
GitHub – SalvatoreRa/tutorial: Tutoriales sobre aprendizaje automático, inteligencia artificial, ciencia de datos…
Tutoriales sobre aprendizaje automático, inteligencia artificial, ciencia de datos con explicaciones matemáticas y código reutilizable (en Python…
github.com
O tal vez te interese alguno de mis artículos recientes:
La escalabilidad no lo es todo: cómo los modelos más grandes fallan más duro
¿Los modelos de lenguaje grandes realmente entienden los lenguajes de programación?
salvatore-raieli.medium.com
META’S LIMA: el camino de Maria Kondo para el entrenamiento de LLMs
Datos más pequeños y ordenados para crear un modelo capaz de competir con ChatGPT
levelup.gitconnected.com
Google Med-PaLM 2: ¿Está la IA lista para la residencia médica?
El nuevo modelo de Google logra resultados impresionantes en el ámbito médico
levelup.gitconnected.com
¿IA o no IA: cómo sobrevivir?
Con la IA generativa amenazando a las empresas y los trabajos paralelos, ¿cómo puedes encontrar espacio?
levelup.gitconnected.com
Referencias
Una lista de las principales referencias consultadas para este artículo:
- Fuzhao Xue et al, 2023, To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis, link
- Hugo Touvron et all. 2023, LLaMA: Open and Efficient Foundation Language Models. link
- Arnav Gudibande et all, 2023, The False Promise of Imitating Proprietary LLMs. link
- PaLM 2, google blog, link
- Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance. Google Blog, link
- Buck Shlegeris et all, 2022, Language models are better than humans at next-token prediction, link
- Pablo Villalobos et. all, 2022, Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning. link
- Susan Zhang et al. 2022, OPT: Open Pre-trained Transformer Language Models. link
- Jordan Hoffmann et all, 2022, An empirical analysis of compute-optimal large language model training. link
- Ross Taylor et al, 2022, Galactica: A Large Language Model for Science, link
- Zixiang Chen et al, 2022, Towards Understanding Mixture of Experts in Deep Learning, link
- Jared Kaplan et all, 2020, Scaling Laws for Neural Language Models. link
- Cómo la IA podría alimentar el calentamiento global, TDS, link
- Modelado de lenguaje enmascarado, blog de HuggingFace, link
- Mixture-of-Experts con Expert Choice Routing, Blog de Google, link
- Por qué el último gran modelo de lenguaje de Meta sobrevivió solo tres días en línea, revisión del MIT, link
- Explorando la transferencia de aprendizaje con T5: el Text-To-Text Transfer Transformer, Google Blog, link
- Leyes de escalabilidad para la sobreoptimización de modelos de recompensa, blog de OpenAI, link
- Un análisis empírico del entrenamiento óptimo de modelos de lenguaje grandes, blog de DeepMind, link
- Xiaonan Nie et al, 2022, EvoMoE: Un marco de entrenamiento evolutivo de mezcla de expertos a través de una puerta densa a dispersa. link
- Tianyu Chen et al, 2022, Podado de expertos específicos de tareas para un modelo de mezcla de expertos disperso, link
- Bo Li et al, 2022, Los modelos de mezcla de expertos dispersos son aprendices de dominio general, link
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Regresión Lineal y Descenso del Gradiente
- Boto3 vs AWS Wrangler Simplificando Operaciones en S3 con Python
- Samsung adopta la IA y los grandes datos, revoluciona el proceso de fabricación de chips.
- Modelo SARIMA para la predicción de tasas de cambio de divisas.
- Consejos de Matplotlib para mejorar instantáneamente tus visualizaciones de datos – Según Storytelling with Data
- Usando RAPIDS cuDF para aprovechar la GPU en la ingeniería de características.
- Desarrollar y probar reglas RLS en Power BI.






