Sobre la Expresividad de las Recompensas de Markov
Sobre recompensas de Markov
La recompensa es la fuerza impulsora para los agentes de aprendizaje por refuerzo (RL). Dado su papel central en RL, se asume que la recompensa es adecuadamente general en su expresividad, como se resume en la hipótesis de recompensa de Sutton y Littman:
“…todo lo que queremos decir con metas y propósitos puede considerarse como la maximización del valor esperado de la suma acumulativa de una señal escalar recibida (recompensa).” – SUTTON (2004), LITTMAN (2017)
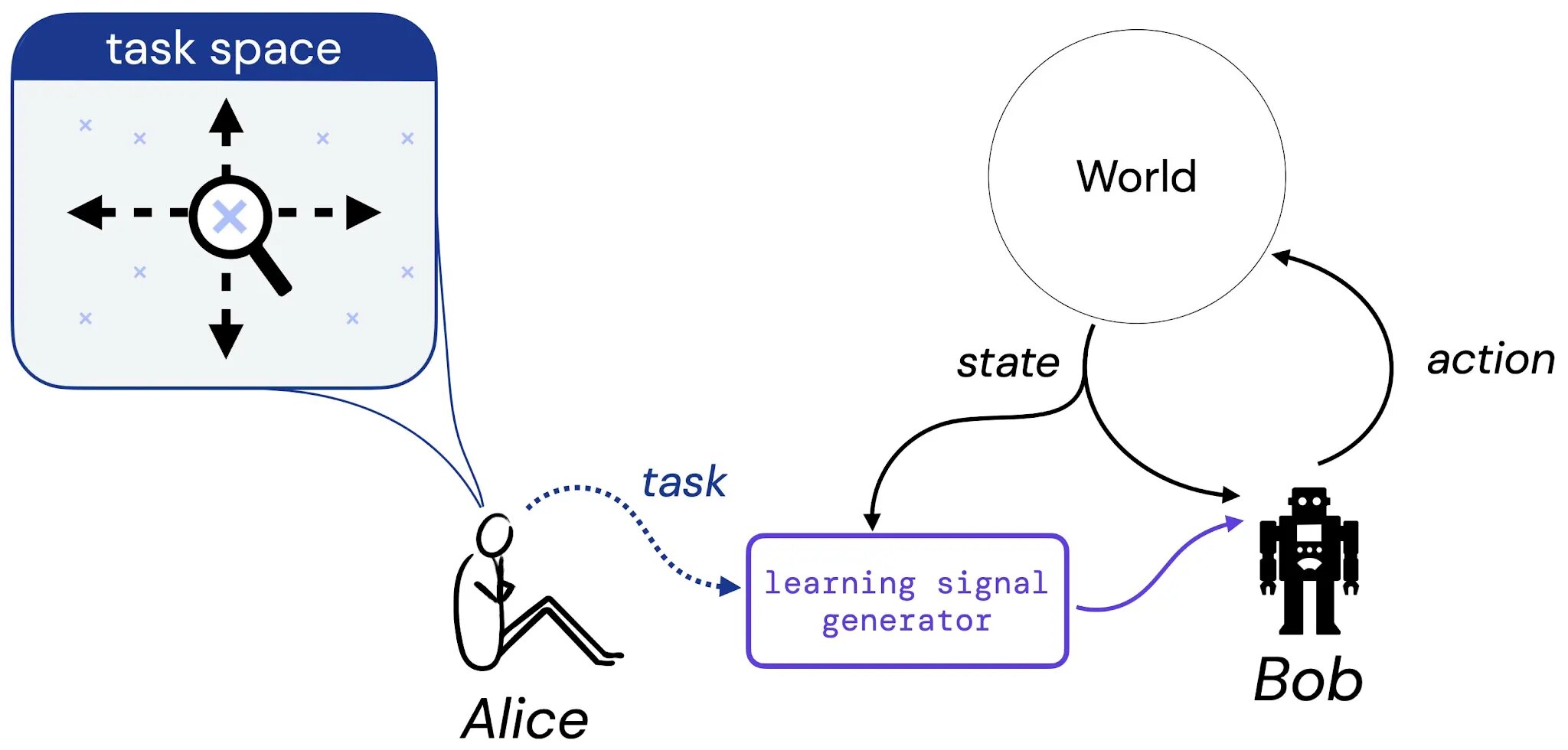
En nuestro trabajo, damos los primeros pasos hacia un estudio sistemático de esta hipótesis. Para hacerlo, consideramos el siguiente experimento mental que involucra a Alice, una diseñadora, y Bob, un agente de aprendizaje:
- Mejorando modelos de lenguaje mediante la recuperación de billones de tokens.
- Modelado del lenguaje a gran escala Gopher, consideraciones éticas y recuperación
- La normatividad espuria mejora el aprendizaje del comportamiento de cumplimiento y aplicación en agentes artificiales.
Suponemos que Alice piensa en una tarea que le gustaría que Bob aprendiera a resolver: esta tarea podría ser en forma de una descripción en lenguaje natural (“equilibra este poste”), una situación imaginada (“alcanza cualquiera de las configuraciones ganadoras de un tablero de ajedrez”) o algo más tradicional como una función de recompensa o valor. Luego, imaginamos que Alice traduce su elección de tarea en algún generador que proporcionará una señal de aprendizaje (como una recompensa) a Bob (un agente de aprendizaje), quien aprenderá de esta señal a lo largo de su vida. A continuación, fundamentamos nuestro estudio de la hipótesis de recompensa abordando la siguiente pregunta: dado la elección de tarea de Alice, ¿siempre hay una función de recompensa que pueda transmitir esta tarea a Bob?
¿Qué es una tarea?
Para hacer nuestro estudio de esta pregunta concreto, primero restringimos el enfoque a tres tipos de tarea. En particular, introducimos tres tipos de tarea que creemos capturan tipos sensibles de tareas: 1) Un conjunto de políticas aceptables (SOAP), 2) Un orden de políticas (PO) y 3) Un orden de trayectorias (TO). Estas tres formas de tareas representan instancias concretas de los tipos de tareas que podríamos querer que un agente aprenda a resolver.
.jpg)
Luego estudiamos si la recompensa es capaz de capturar cada uno de estos tipos de tareas en entornos finitos. Crucialmente, solo prestamos atención a las funciones de recompensa de Markov; por ejemplo, dado un espacio de estados que es suficiente para formar una tarea como pares (x,y) en un mundo de cuadrícula, ¿hay una función de recompensa que solo dependa de este mismo espacio de estados que pueda capturar la tarea?
Primer Resultado Principal
Nuestro primer resultado principal muestra que, para cada uno de los tres tipos de tareas, hay pares de entornos-tareas para los cuales no existe una función de recompensa de Markov que pueda capturar la tarea. Un ejemplo de tal par es la tarea “dar toda la vuelta a la cuadrícula en el sentido de las agujas del reloj o en sentido contrario” en un mundo de cuadrícula típico:
.jpg)
Esta tarea se captura naturalmente por un SOAP que consta de dos políticas aceptables: la política “en sentido de las agujas del reloj” (en azul) y la política “en sentido contrario a las agujas del reloj” (en morado). Para que una función de recompensa de Markov exprese esta tarea, tendría que hacer que estas dos políticas sean estrictamente de mayor valor que todas las demás políticas determinísticas. Sin embargo, no existe una función de recompensa de Markov que cumpla esta condición: la optimalidad de una única acción “mover en sentido de las agujas del reloj” dependerá de si el agente ya se estaba moviendo en esa dirección en el pasado. Dado que la función de recompensa debe ser de Markov, no puede transmitir este tipo de información. Ejemplos similares demuestran que la recompensa de Markov tampoco puede capturar cualquier orden de políticas y orden de trayectorias.
Segundo Resultado Principal
Dado que algunas tareas pueden ser capturadas y otras no, a continuación exploramos si existe un procedimiento eficiente para determinar si una tarea dada puede ser capturada por una recompensa en un entorno dado. Además, si existe una función de recompensa que captura la tarea dada, idealmente nos gustaría poder generar dicha función de recompensa. Nuestro segundo resultado es un resultado positivo que dice que, para cualquier par de entorno-tarea finito, existe un procedimiento que puede 1) decidir si la tarea puede ser capturada por una recompensa de Markov en el entorno dado, y 2) generar la función de recompensa deseada que transmita exactamente la tarea, cuando existe tal función.
Este trabajo establece vías iniciales para comprender el alcance de la hipótesis de recompensa, pero aún queda mucho por hacer para generalizar estos resultados más allá de los entornos finitos, las recompensas de Markov y las nociones simples de “tarea” y “expresividad”. Esperamos que este trabajo proporcione nuevas perspectivas conceptuales sobre la recompensa y su lugar en el aprendizaje por refuerzo.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Modelos de Lenguaje de Red Teaming con Modelos de Lenguaje
- El primer paso de MuZero de la investigación al mundo real.
- Acelerando la ciencia de la fusión a través del control de plasma aprendido
- Prediciendo el pasado con Ithaca
- GopherCite Enseñando a los modelos de lenguaje a respaldar respuestas con citas verificadas
- Un análisis empírico del entrenamiento de modelos de lenguaje grandes óptimos en cómputo
- La última investigación de DeepMind en ICLR 2022





