Simplifica el acceso a la información interna utilizando la Generación Mejorada de Recuperación y los Agentes de LangChain
Simplifica acceso a información interna con Generación Mejorada de Recuperación y Agentes de LangChain
Esta publicación te lleva a través de los desafíos más comunes que enfrentan los clientes al buscar documentos internos, y te brinda orientación concreta sobre cómo los servicios de AWS se pueden utilizar para crear un bot conversacional de IA generativa que haga que la información interna sea más útil.
Los datos no estructurados representan el 80% de todos los datos que se encuentran dentro de las organizaciones, que consisten en repositorios de manuales, PDF, preguntas frecuentes, correos electrónicos y otros documentos que crecen diariamente. Las empresas de hoy dependen de repositorios de información interna en constante crecimiento, y surgen problemas cuando la cantidad de datos no estructurados se vuelve inmanejable. A menudo, los usuarios se encuentran leyendo y revisando muchas fuentes internas diferentes para encontrar las respuestas que necesitan.
Los foros internos de preguntas y respuestas pueden ayudar a los usuarios a obtener respuestas altamente específicas, pero también requieren tiempos de espera más largos. En el caso de las preguntas frecuentes internas específicas de la empresa, los tiempos de espera prolongados resultan en una menor productividad de los empleados. Los foros de preguntas y respuestas son difíciles de escalar, ya que dependen de respuestas escritas manualmente. Con la IA generativa, actualmente hay un cambio de paradigma en cómo los usuarios buscan y encuentran información. El siguiente paso lógico es utilizar la IA generativa para condensar documentos grandes en información más pequeña y fácil de consumir para el usuario. En lugar de pasar mucho tiempo leyendo texto o esperando respuestas, los usuarios pueden generar resúmenes en tiempo real basados en múltiples repositorios existentes de información interna.
Descripción general de la solución
La solución permite a los clientes obtener respuestas seleccionadas a preguntas sobre documentos internos mediante el uso de un modelo de transformador para generar respuestas a preguntas sobre datos en los que no se ha entrenado, una técnica conocida como “zero-shot prompting”. Al adoptar esta solución, los clientes pueden obtener los siguientes beneficios:
- Una revisión exhaustiva de la Blockchain en la Inteligencia Artificial
- Cómo construir un sistema Multi-GPU para Deep Learning en 2023
- Nuevo estudio sugiere la ecología como modelo para la innovación en IA
- Encontrar respuestas precisas a preguntas basadas en fuentes existentes de documentos internos
- Reducir el tiempo que los usuarios dedican a buscar respuestas mediante el uso de modelos de lenguaje grandes (LLMs) para proporcionar respuestas casi inmediatas a consultas complejas utilizando documentos con la información más actualizada
- Buscar preguntas previamente respondidas a través de un panel centralizado
- Reducir el estrés causado por pasar tiempo leyendo información manualmente para buscar respuestas
Generación aumentada por recuperación (RAG)
La generación aumentada por recuperación (RAG) reduce algunas de las limitaciones de las consultas basadas en LLM al encontrar las respuestas en tu base de conocimientos y utilizar el LLM para resumir los documentos en respuestas concisas. Por favor, lee esta publicación para aprender cómo implementar el enfoque RAG con Amazon Kendra. Los siguientes riesgos y limitaciones están asociados con las consultas basadas en LLM que un enfoque RAG con Amazon Kendra aborda:
- Alucinaciones y trazabilidad: los LLM se entrenan en grandes conjuntos de datos y generan respuestas en base a probabilidades. Esto puede llevar a respuestas inexactas, conocidas como alucinaciones.
- Múltiples silos de datos: para hacer referencia a datos de múltiples fuentes dentro de tu respuesta, es necesario configurar un ecosistema de conectores para agregar los datos. El acceso a múltiples repositorios es manual y consume tiempo.
- Seguridad: la seguridad y la privacidad son consideraciones críticas al implementar bots conversacionales impulsados por RAG y LLMs. A pesar de utilizar Amazon Comprehend para filtrar los datos personales que pueden ser proporcionados a través de las consultas de los usuarios, existe la posibilidad de mostrar información personal o sensible de manera no intencional, dependiendo de los datos ingresados. Esto significa que controlar el acceso al chatbot es crucial para evitar el acceso no deseado a información sensible.
- Relevancia de los datos: los LLM se entrenan en datos hasta cierta fecha, lo que significa que la información a menudo no está actualizada. El costo asociado con entrenar modelos con datos recientes es alto. Para garantizar respuestas precisas y actualizadas, las organizaciones tienen la responsabilidad de actualizar y enriquecer regularmente el contenido de los documentos indexados.
- Costo: el costo asociado con implementar esta solución debe ser considerado por las empresas. Las empresas deben evaluar cuidadosamente su presupuesto y requisitos de rendimiento al implementar esta solución. El funcionamiento de los LLM puede requerir recursos computacionales sustanciales, lo que puede aumentar los costos operativos. Estos costos pueden convertirse en una limitación para aplicaciones que necesitan operar a gran escala. Sin embargo, uno de los beneficios de la Nube de AWS es la flexibilidad de pagar solo por lo que se utiliza. AWS ofrece un modelo de precios simple, consistente y de pago por uso, por lo que solo se te cobrará por los recursos que consumes.
Uso de Amazon SageMaker JumpStart
Para modelos de lenguaje basados en transformadores, las organizaciones pueden beneficiarse del uso de Amazon SageMaker JumpStart, que ofrece una colección de modelos de aprendizaje automático preconstruidos. Amazon SageMaker JumpStart ofrece una amplia gama de modelos fundamentales de generación de texto y preguntas y respuestas (Q&A) que se pueden implementar y utilizar fácilmente. Esta solución integra un modelo FLAN T5-XL de Amazon SageMaker JumpStart, pero hay diferentes aspectos a tener en cuenta al elegir un modelo base.
Integrando seguridad en nuestro flujo de trabajo
Siguiendo las mejores prácticas del Pilar de Seguridad del Marco de Arquitectura Bien Construida, se utiliza Amazon Cognito para la autenticación. Los grupos de usuarios de Amazon Cognito se pueden integrar con proveedores de identidades de terceros que admiten varios marcos utilizados para el control de acceso, incluyendo Autorización Abierta (OAuth), OpenID Connect (OIDC) o Lenguaje de Marcado de Declaración de Seguridad (SAML). Identificar a los usuarios y sus acciones permite que la solución mantenga la trazabilidad. La solución también utiliza la función de detección de información personalmente identificable (PII) de Amazon Comprehend para identificar y redactar automáticamente la PII. La PII redactada incluye direcciones, números de seguro social, direcciones de correo electrónico y otra información sensible. Este diseño garantiza que cualquier PII proporcionada por el usuario a través de la consulta de entrada sea redactada. La PII no se almacena, se utiliza por Amazon Kendra ni se alimenta a la LLM.
Recorrido de la solución
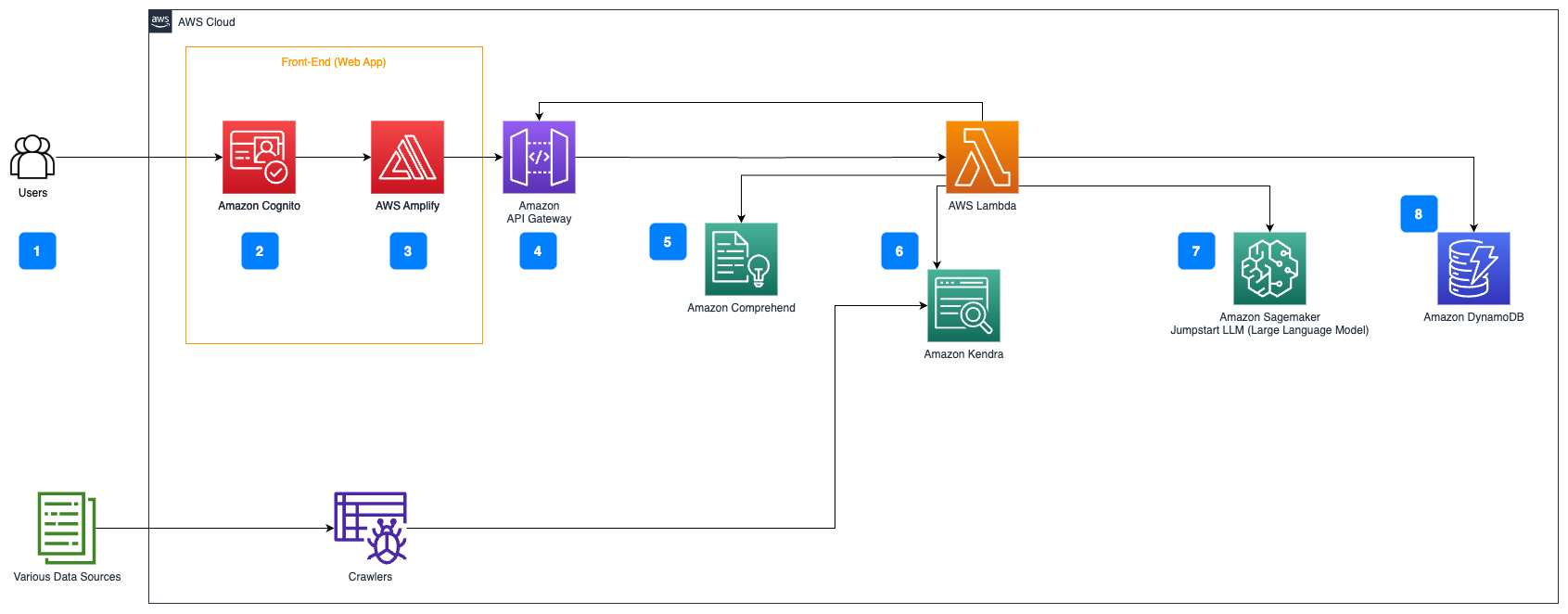
Los siguientes pasos describen el flujo del cuestionario de respuesta sobre documentos:
- Los usuarios envían una consulta a través de una interfaz web.
- Se utiliza Amazon Cognito para la autenticación, asegurando el acceso seguro a la aplicación web.
- La interfaz frontal de la aplicación web se aloja en AWS Amplify.
- Amazon API Gateway aloja una API REST con varios puntos finales para manejar las solicitudes de los usuarios que están autenticados utilizando Amazon Cognito.
- Redacción de PII con Amazon Comprehend:
- Procesamiento de consultas de usuario: Cuando un usuario envía una consulta o entrada, primero se pasa por Amazon Comprehend. El servicio analiza el texto e identifica cualquier entidad de PII presente dentro de la consulta.
- Extracción de PII: Amazon Comprehend extrae las entidades de PII detectadas de la consulta del usuario.
- Recuperación de información relevante con Amazon Kendra:
- Se utiliza Amazon Kendra para gestionar un índice de documentos que contiene la información utilizada para generar respuestas a las consultas de los usuarios.
- El módulo de recuperación de preguntas y respuestas de LangChain se utiliza para construir una cadena de conversación que tiene información relevante sobre las consultas de los usuarios.
- Integración con Amazon SageMaker JumpStart:
- La función de AWS Lambda utiliza la biblioteca LangChain y se conecta al punto final de Amazon SageMaker JumpStart con una consulta de contexto relleno. El punto final de Amazon SageMaker JumpStart sirve como la interfaz de la LLM utilizada para la inferencia.
- Almacenar respuestas y devolverlas al usuario:
- La respuesta de la LLM se almacena en Amazon DynamoDB junto con la consulta del usuario, la marca de tiempo, un identificador único y otros identificadores arbitrarios para el elemento, como la categoría de la pregunta. Almacenar la pregunta y la respuesta como elementos discretos permite que la función de AWS Lambda vuelva a crear fácilmente el historial de conversaciones de un usuario en función del momento en que se hicieron las preguntas.
- Finalmente, la respuesta se envía de vuelta al usuario a través de una solicitud HTTPs a través de la respuesta de integración de API REST de Amazon API Gateway.
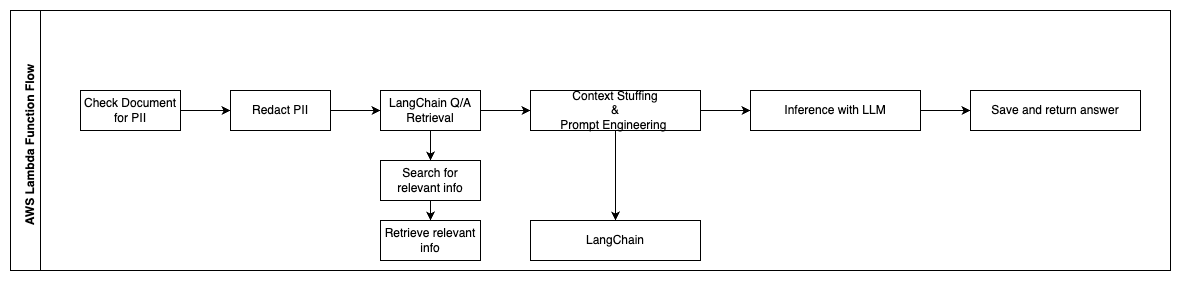
Los siguientes pasos describen las funciones de AWS Lambda y su flujo a través del proceso:
- Verificar y redactar cualquier información de PII / sensible
- Cadena de recuperación de preguntas y respuestas de LangChain
- Buscar y recuperar información relevante
- Relleno de contexto e ingeniería de indicaciones
- LangChain
- Inferencia con LLM
- Devolver respuesta y guardarla
Casos de uso
Hay muchos casos de uso empresariales donde los clientes pueden utilizar este flujo de trabajo. La siguiente sección explica cómo se puede utilizar el flujo de trabajo en diferentes industrias y verticales.
Asistencia al empleado
La capacitación corporativa bien diseñada puede mejorar la satisfacción de los empleados y reducir el tiempo requerido para la incorporación de nuevos empleados. A medida que las organizaciones crecen y aumenta la complejidad, los empleados encuentran difícil entender las muchas fuentes de documentos internos. Los documentos internos en este contexto incluyen pautas de la empresa, políticas y Procedimientos Operativos Estándar. Para este escenario, un empleado tiene una pregunta sobre cómo proceder y editar un ticket interno de emisión de problemas. El empleado puede acceder y utilizar el bot conversacional de inteligencia artificial generativa (IA) para hacer y ejecutar los siguientes pasos para un ticket específico.
Caso de uso específico: automatizar la resolución de problemas para empleados basándose en pautas corporativas.
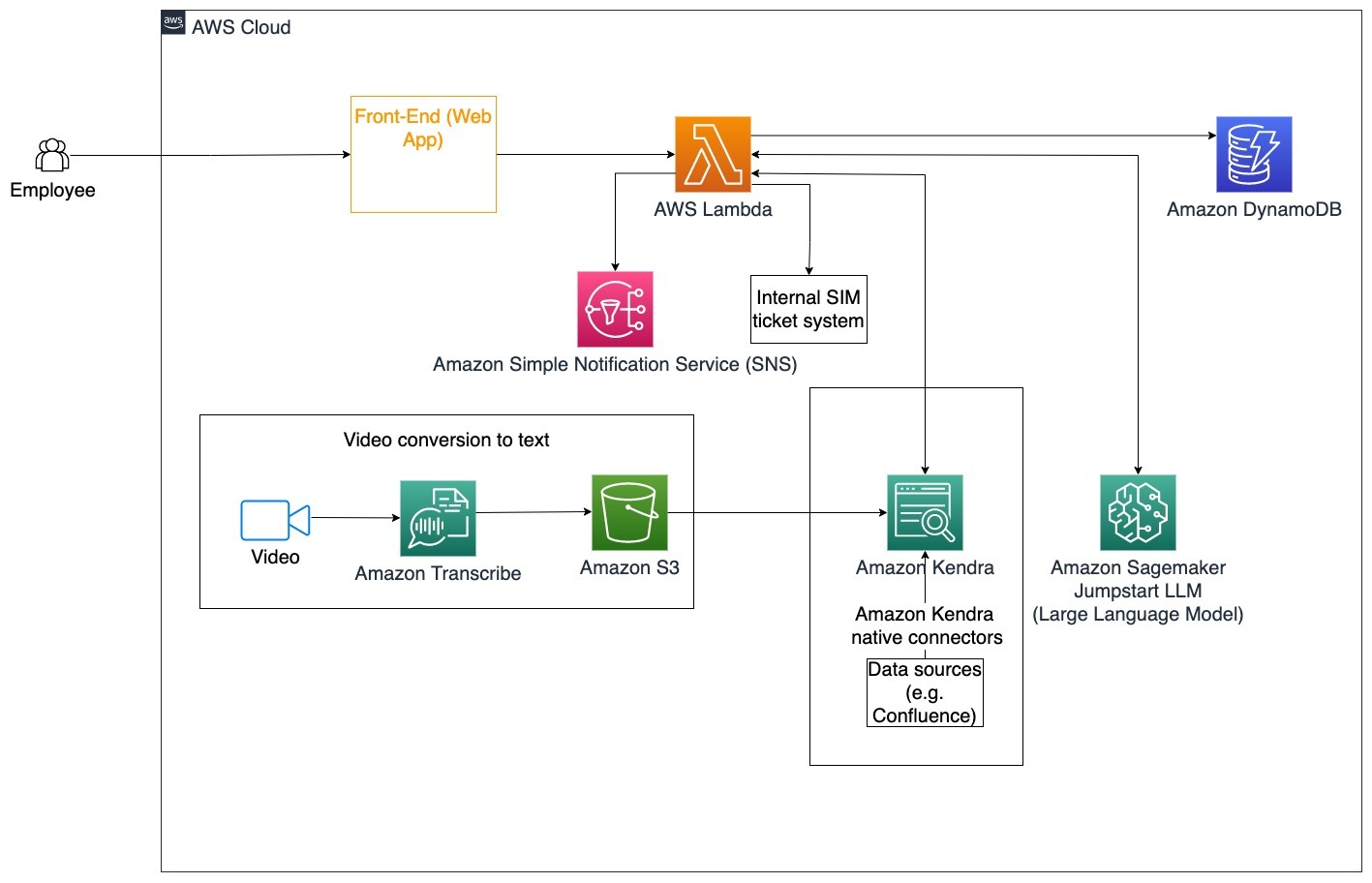
Los siguientes pasos describen las funciones de AWS Lambda y su flujo a través del proceso:
- El agente LangChain identifica la intención.
- Enviar notificación basada en la solicitud del empleado.
- Modificar el estado del ticket.

En este diagrama de arquitectura, los videos de capacitación corporativa se pueden ingresar a través de Amazon Transcribe para recopilar un registro de los guiones de estos videos. Además, el contenido de capacitación corporativa almacenado en diversas fuentes (por ejemplo, Confluence, Microsoft SharePoint, Google Drive, Jira, etc.) se puede utilizar para crear índices a través de los conectores de Amazon Kendra. Lea este artículo para obtener más información sobre la recopilación de conectores nativos que puede utilizar en Amazon Kendra como punto de origen. Luego, el rastreador de Amazon Kendra puede utilizar tanto los guiones de video de capacitación corporativa como la documentación almacenada en estas otras fuentes para ayudar al bot conversacional a responder preguntas específicas sobre las pautas de capacitación corporativa de la empresa. El agente LangChain verifica los permisos, modifica el estado del ticket y notifica a las personas correctas utilizando Amazon Simple Notification Service (Amazon SNS).
Equipos de soporte al cliente
Resolver rápidamente las consultas de los clientes mejora la experiencia del cliente y fomenta la fidelidad a la marca. Una base de clientes leales ayuda a impulsar las ventas, lo que contribuye al resultado final y aumenta el compromiso del cliente. Los equipos de soporte al cliente gastan mucha energía consultando muchos documentos internos y software de gestión de relaciones con los clientes para responder consultas de los clientes sobre productos y servicios. Los documentos internos en este contexto pueden incluir guiones genéricos de atención al cliente, libros de jugadas, pautas de escalada e información comercial. El bot conversacional generativo de IA ayuda con la optimización de costos porque responde a las consultas en nombre del equipo de soporte al cliente.
Caso de uso específico: manejo de una solicitud de cambio de aceite basada en el historial de servicio y el plan de servicio al cliente adquirido.
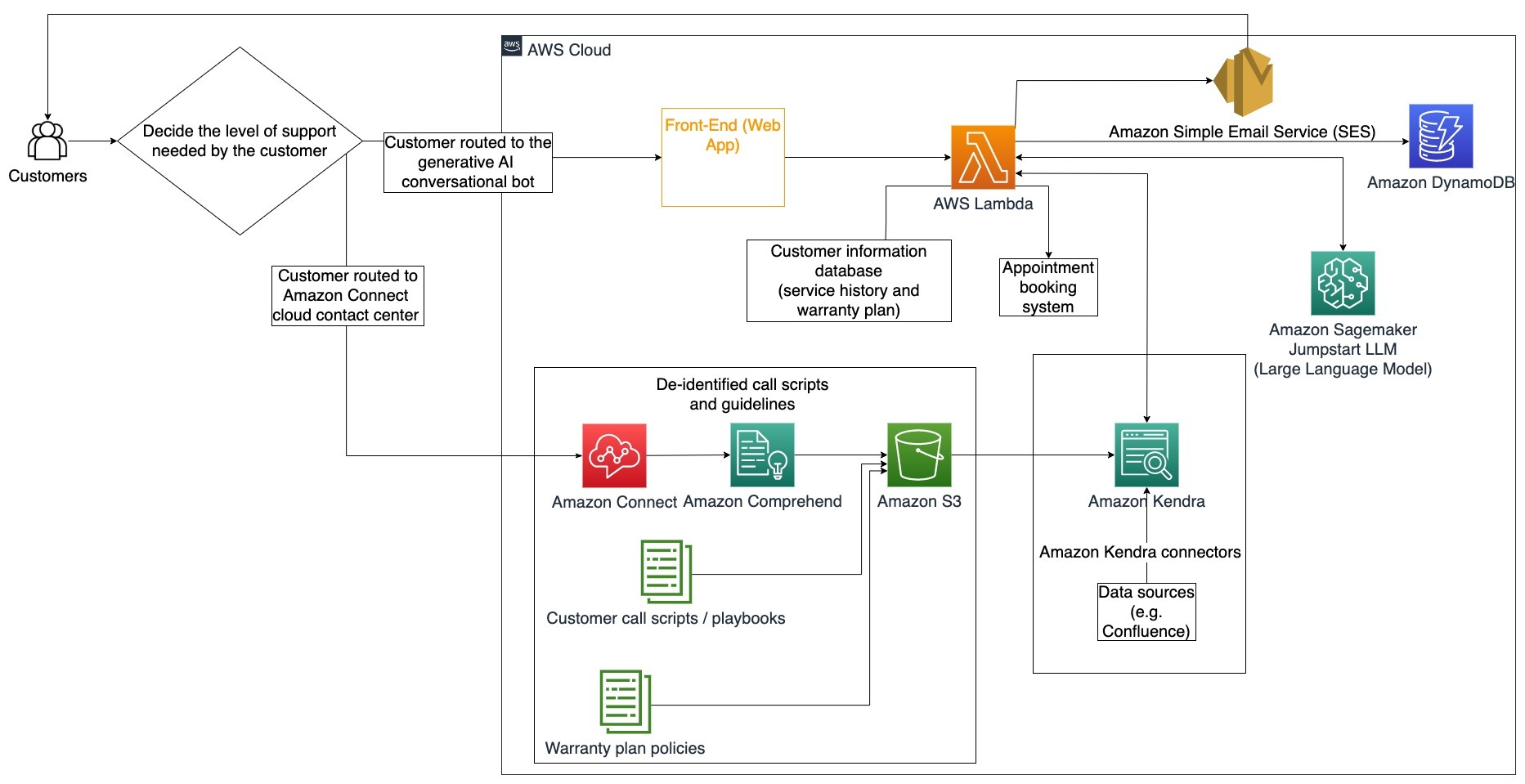
En este diagrama de arquitectura, el cliente es dirigido al bot conversacional generativo de IA o al centro de contacto de Amazon Connect. Esta decisión puede basarse en el nivel de soporte necesario o en la disponibilidad de agentes de soporte al cliente. El agente LangChain identifica la intención del cliente y verifica la identidad. El agente LangChain también verifica el historial de servicio y el plan de soporte adquirido.
Los siguientes pasos describen las funciones de AWS Lambda y su flujo a través del proceso:
- El agente LangChain identifica la intención.
- Recuperar información del cliente.
- Verificar el historial de servicio y la información de la garantía del cliente.
- Agendar una cita, proporcionar más información o dirigir al centro de contacto.
- Enviar confirmación por correo electrónico.

Se utiliza Amazon Connect para recopilar los registros de voz y chat, y se utiliza Amazon Comprehend para eliminar información de identificación personal (PII) de estos registros. Luego, el rastreador de Amazon Kendra puede utilizar los registros de voz y chat redactados, los guiones de llamadas de clientes y las políticas de plan de soporte al cliente para crear el índice. Una vez tomada una decisión, el bot conversacional generativo de IA decide si reservar una cita, proporcionar más información o dirigir al cliente al centro de contacto para obtener ayuda adicional. Para la optimización de costos, el agente LangChain también puede generar respuestas utilizando menos tokens y un modelo de lenguaje grande menos costoso para consultas de menor prioridad de los clientes.
Servicios financieros
Las empresas de servicios financieros dependen del uso oportuno de la información para mantenerse competitivas y cumplir con las regulaciones financieras. Utilizando un bot conversacional generativo de IA, los analistas y asesores financieros pueden interactuar con la información textual de manera conversacional y reducir el tiempo y el esfuerzo necesarios para tomar decisiones más informadas. Además de la inversión y la investigación de mercado, un bot conversacional generativo de IA también puede aumentar las capacidades humanas al manejar tareas que tradicionalmente requerirían más esfuerzo y tiempo humano. Por ejemplo, una institución financiera especializada en préstamos personales puede aumentar la velocidad a la que se procesan los préstamos al tiempo que proporciona una mayor transparencia a los clientes.
Caso de uso específico: Utilizar el historial financiero del cliente y las solicitudes de préstamos anteriores para decidir y explicar la decisión del préstamo.
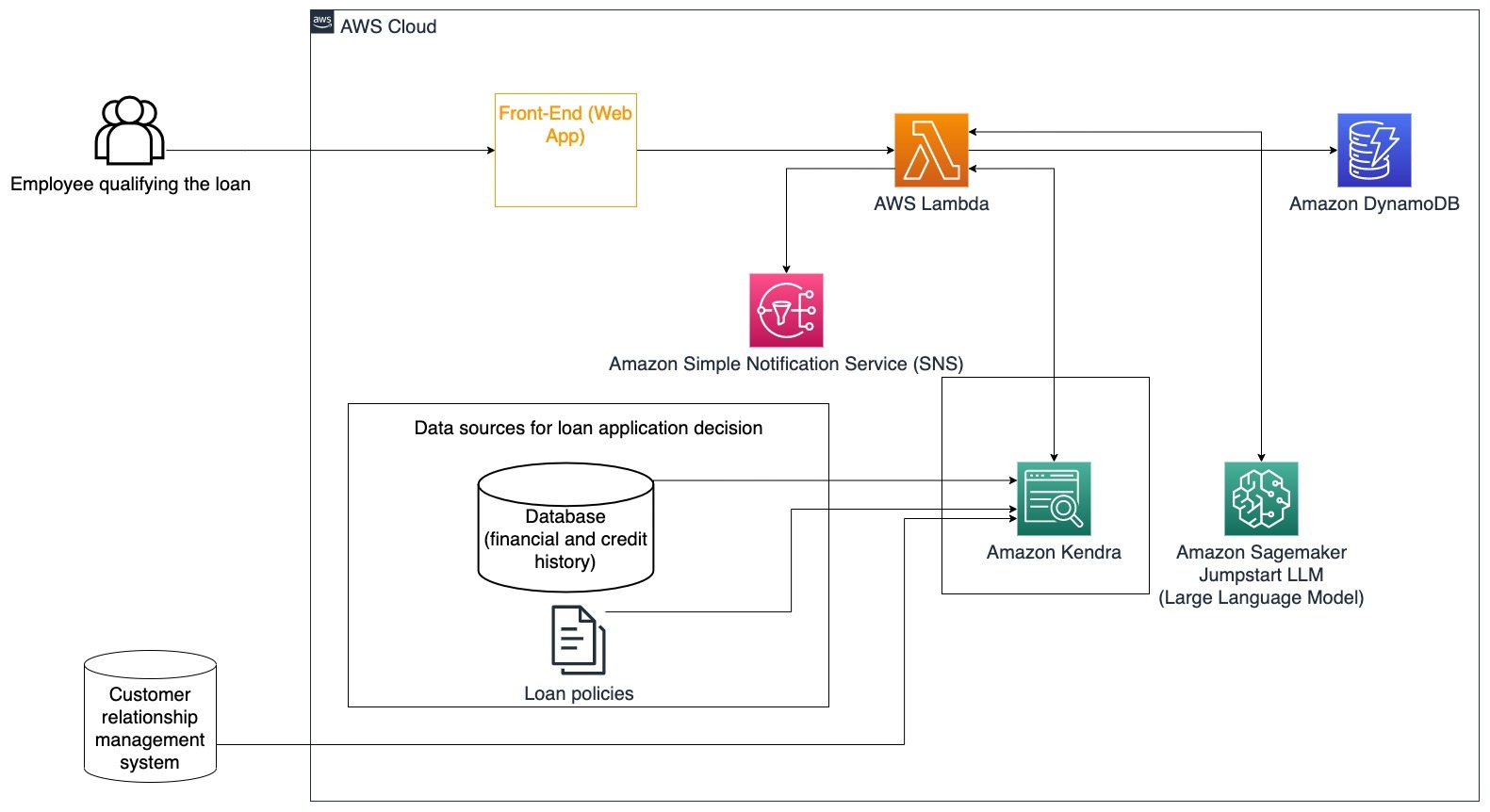
Los siguientes pasos describen las funciones de AWS Lambda y su flujo a través del proceso:
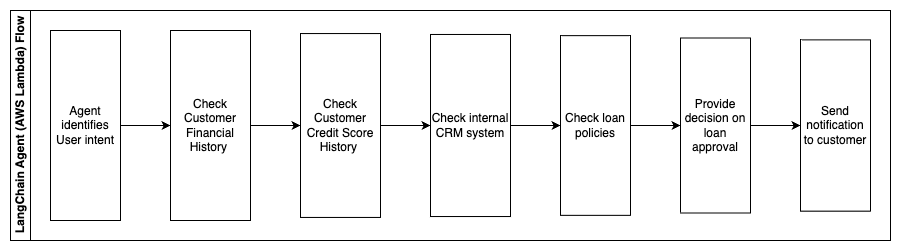
- Agente LangChain para identificar la intención
- Verificar el historial financiero y la puntuación crediticia del cliente
- Verificar el sistema interno de gestión de relaciones con clientes
- Verificar las políticas de préstamos estándar y sugerir una decisión para el empleado que califica el préstamo
- Enviar una notificación al cliente
Esta arquitectura incorpora datos financieros del cliente almacenados en una base de datos y datos almacenados en una herramienta de gestión de relaciones con clientes (CRM). Estos puntos de datos se utilizan para tomar una decisión basada en las políticas internas de préstamos de la empresa. El cliente puede hacer preguntas para entender qué préstamos califica y los términos de los préstamos que puede aceptar. Si el bot conversacional de IA generativa no puede aprobar una solicitud de préstamo, el usuario aún puede hacer preguntas sobre cómo mejorar la puntuación crediticia o opciones de financiamiento alternativas.
Gobierno
Los bots conversacionales de IA generativa pueden beneficiar enormemente a las instituciones gubernamentales al acelerar la comunicación, la eficiencia y los procesos de toma de decisiones. También pueden proporcionar acceso instantáneo a bases de conocimiento internas para ayudar a los empleados del gobierno a recuperar rápidamente información, políticas y procedimientos (es decir, criterios de elegibilidad, procesos de solicitud y servicios y soporte al ciudadano). Una solución es un sistema interactivo que permite a los contribuyentes y profesionales de impuestos encontrar fácilmente detalles y beneficios relacionados con los impuestos. Se puede utilizar para comprender las preguntas del usuario, resumir documentos fiscales y proporcionar respuestas claras a través de conversaciones interactivas.
Los usuarios pueden hacer preguntas como:
- ¿Cómo funciona el impuesto de herencia y cuáles son los umbrales fiscales?
- ¿Puede explicar el concepto de impuesto sobre la renta?
- ¿Cuáles son las implicaciones fiscales al vender una segunda propiedad?
Además, los usuarios pueden tener la comodidad de enviar formularios fiscales a un sistema que puede ayudar a verificar la corrección de la información proporcionada.
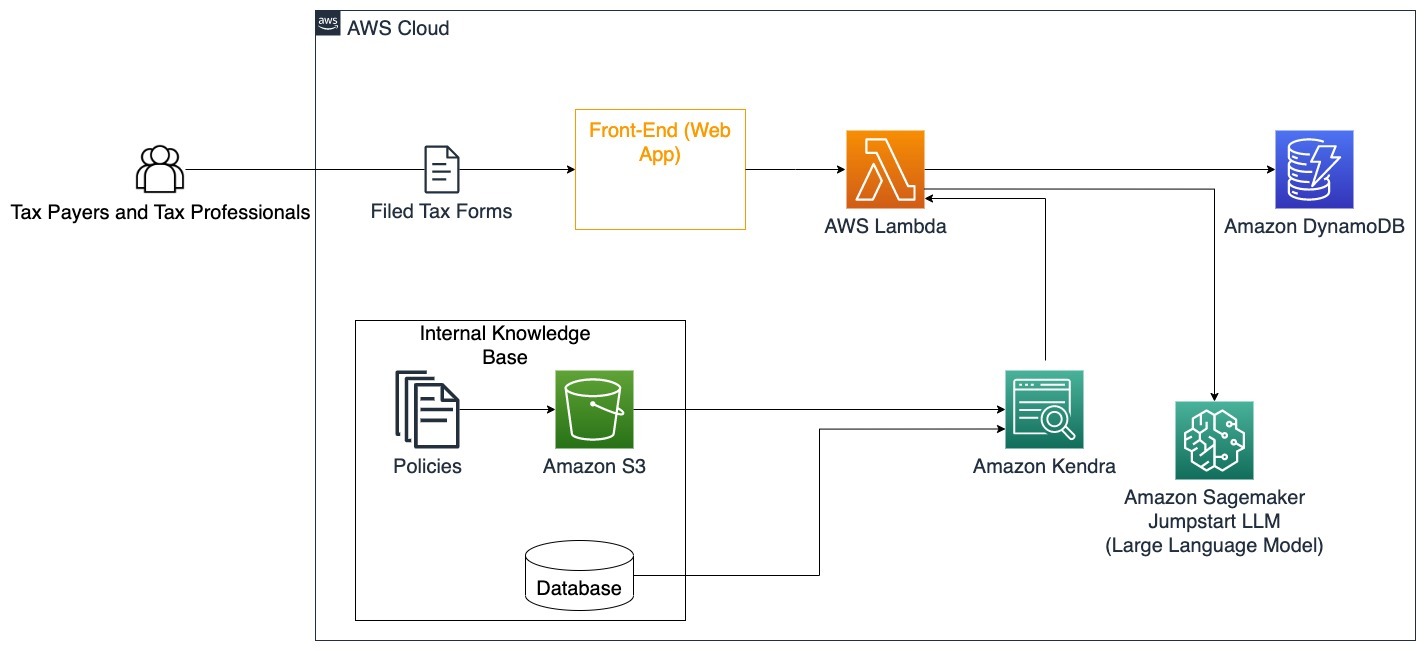
Esta arquitectura ilustra cómo los usuarios pueden cargar formularios fiscales completados en la solución y utilizarla para verificar e interactuar con orientación sobre cómo completar correctamente la información necesaria.
Atención médica
Las empresas de atención médica tienen la oportunidad de automatizar el uso de grandes cantidades de información interna de pacientes, al tiempo que responden preguntas comunes sobre casos de uso como opciones de tratamiento, reclamaciones de seguros, ensayos clínicos e investigación farmacéutica. El uso de un bot conversacional de IA generativa permite generar rápidamente respuestas precisas sobre información de salud a partir de la base de conocimientos proporcionada. Por ejemplo, algunos profesionales de la salud dedican mucho tiempo a completar formularios para presentar reclamaciones de seguros.
En entornos similares, los administradores de ensayos clínicos e investigadores necesitan encontrar información sobre opciones de tratamiento. Un bot conversacional de IA generativa puede utilizar los conectores preconstruidos en Amazon Kendra para recuperar la información más relevante de los millones de documentos publicados a través de investigaciones en curso realizadas por compañías farmacéuticas y universidades.
Caso de uso específico: Reducir los errores y el tiempo necesario para completar y enviar formularios de seguros.
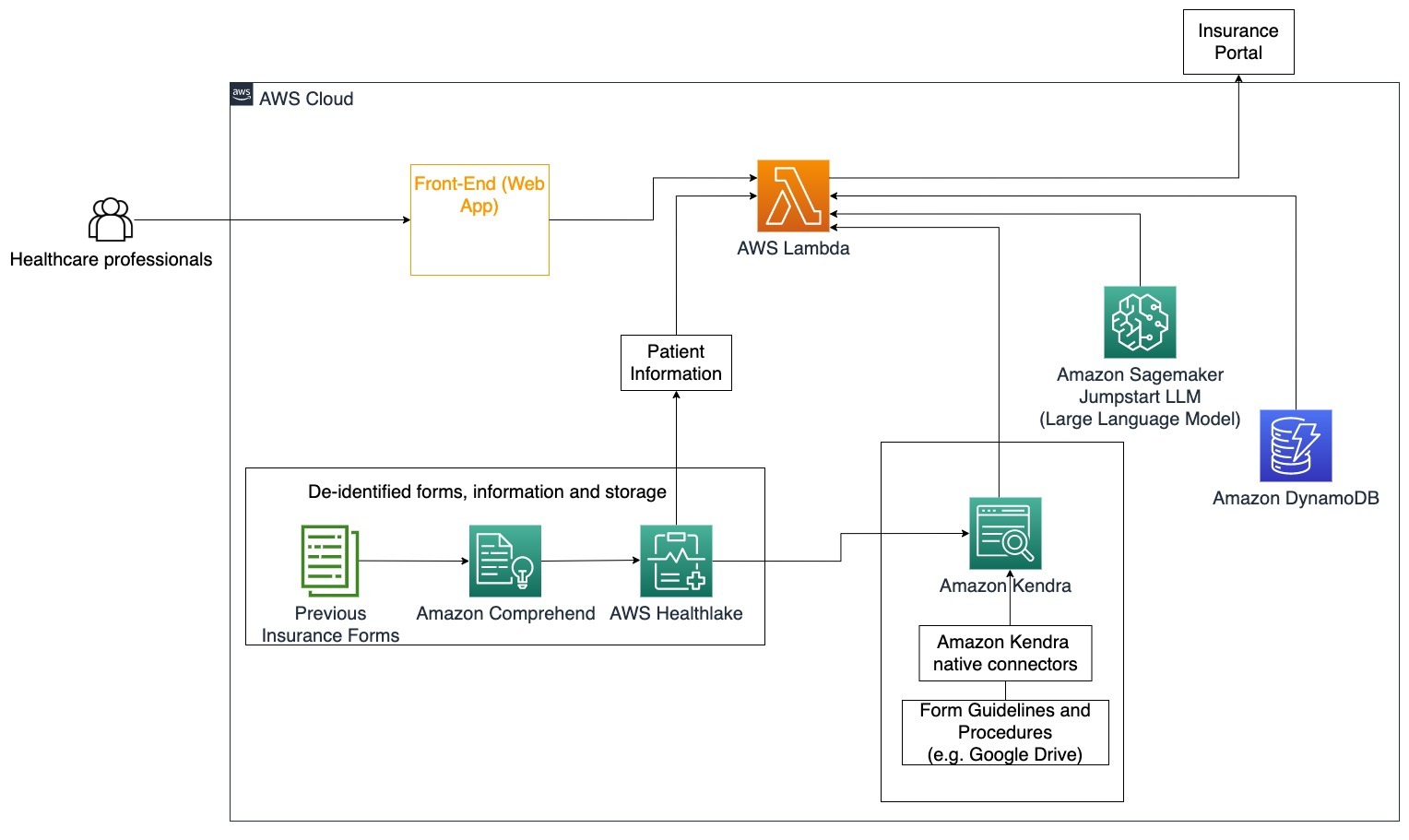
En este diagrama de arquitectura, un profesional de la salud puede utilizar el bot conversacional de IA generativa para determinar qué formularios deben completarse para el seguro. El agente LangChain luego puede recuperar los formularios correctos y agregar la información necesaria para un paciente, así como proporcionar respuestas para las partes descriptivas de los formularios basadas en las pólizas de seguro y los formularios anteriores. El profesional de la salud puede editar las respuestas dadas por el LLM antes de aprobar y enviar el formulario al portal de seguros.
Los siguientes pasos describen las funciones de AWS Lambda y su flujo a través del proceso:
- Agente LangChain para identificar la intención
- Recuperar la información del paciente necesaria
- Rellenar el formulario de seguro basado en la información del paciente y la guía del formulario
- Enviar el formulario al portal de seguros después de la aprobación del usuario
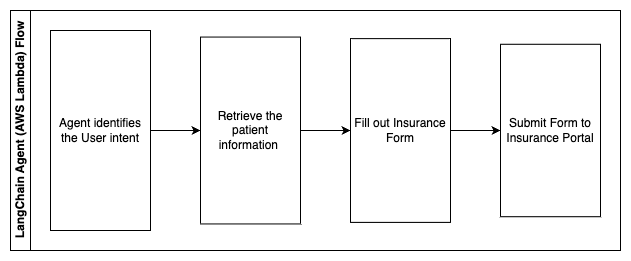
Se utiliza AWS HealthLake para almacenar de forma segura los datos de salud, incluidos los formularios de seguro anteriores y la información del paciente, y se utiliza Amazon Comprehend para eliminar la información de identificación personal (PII) de los formularios de seguro anteriores. Luego, el rastreador de Amazon Kendra puede utilizar el conjunto de formularios de seguro y pautas para crear el índice. Una vez que el/los formulario(s) son completados por la IA generativa, el/los formulario(s) revisados por el profesional médico se pueden enviar al portal de seguros.
Estimación de costos
El costo de implementar la solución base como prueba de concepto se muestra en la siguiente tabla. Dado que se considera que la solución base es una prueba de concepto, se utilizó Amazon Kendra Developer Edition como una opción de bajo costo, ya que la carga de trabajo no estaría en producción. Nuestra suposición para Amazon Kendra Developer Edition fue de 730 horas activas al mes.
Para Amazon SageMaker, asumimos que el cliente utilizaría la instancia ml.g4dn.2xlarge para inferencia en tiempo real, con un único punto de enlace de inferencia por instancia. Puede encontrar más información sobre los precios de Amazon SageMaker y los tipos de instancia de inferencia disponibles aquí.
| Servicio | Recursos Consumidos | Estimación de Costo Mensual en USD |
| AWS Amplify | 150 minutos de compilación 1 GB de datos servidos 500,000 solicitudes | 15.71 |
| Amazon API Gateway | 1 millón de llamadas a la API REST | 3.5 |
| AWS Lambda | 1 millón de solicitudes 5 segundos de duración por solicitud 2 GB de memoria asignada | 160.23 |
| Amazon DynamoDB | 1 millón de lecturas 1 millón de escrituras 100 GB de almacenamiento | 26.38 |
| Amazon Sagemaker | Inferencia en tiempo real con ml.g4dn.2xlarge | 676.8 |
| Amazon Kendra | Developer Edition con 730 horas/mes 10,000 documentos escaneados 5,000 consultas/día | 821.25 |
| . | . | Costo Total: 1703.87 |
* Amazon Cognito tiene una capa gratuita de 50,000 usuarios activos mensuales que utilizan Cognito User Pools o 50 usuarios activos mensuales que utilizan proveedores de identidad SAML 2.0
Limpieza
Para ahorrar costos, elimine todos los recursos implementados como parte del tutorial. Puede eliminar cualquier punto de enlace de SageMaker que haya creado a través de la consola de SageMaker. Recuerde que eliminar un índice de Amazon Kendra no elimina los documentos originales de su almacenamiento.
Conclusión
En esta publicación, le mostramos cómo simplificar el acceso a la información interna mediante la síntesis de múltiples repositorios en tiempo real. Después de los últimos desarrollos de LLM comerciales disponibles, las posibilidades de la IA generativa se han vuelto más evidentes. En esta publicación, presentamos formas de utilizar los servicios de AWS para crear un chatbot sin servidor que utiliza IA generativa para responder preguntas. Este enfoque incorpora una capa de autenticación y la detección de PII de Amazon Comprehend para filtrar cualquier información confidencial proporcionada en la consulta del usuario. Ya sea que se trate de individuos en el sector de la salud que comprendan los matices para presentar reclamos de seguro o de recursos humanos que comprendan regulaciones específicas de toda la empresa, hay múltiples industrias y sectores que pueden beneficiarse de este enfoque. Un modelo de base JumpStart de Amazon SageMaker es el motor detrás del chatbot, mientras que se utiliza un enfoque de relleno de contexto utilizando la técnica RAG para garantizar que las respuestas hagan referencia de manera más precisa a los documentos internos.
Para obtener más información sobre cómo trabajar con IA generativa en AWS, consulte el Anuncio de nuevas herramientas para la creación de IA generativa en AWS. Para obtener una guía más detallada sobre cómo utilizar la técnica RAG con los servicios de AWS, consulte Cómo construir rápidamente aplicaciones de IA generativa de alta precisión en datos empresariales utilizando Amazon Kendra, LangChain y modelos de lenguaje grandes. Dado que el enfoque en este blog es agnóstico en cuanto a LLM, se puede utilizar cualquier LLM para la inferencia. En nuestra próxima publicación, describiremos formas de implementar esta solución utilizando Amazon Bedrock y el LLM Amazon Titan.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Investigadores de China presentan ImageBind-LLM un método de ajuste de instrucciones de múltiples modalidades de modelos de lenguaje grandes (LLMs) a través de ImageBind.
- Comprendiendo el Aprendizaje Supervisado Teoría y Visión General
- Investigadores de Stanford introducen Protpardelle un modelo de difusión de todos los átomos revolucionario para el co-diseño de la estructura y secuencia de proteínas
- ¿Cómo deberíamos ver los datos clínicos sesgados en el aprendizaje automático médico? Un llamado a una perspectiva arqueológica
- Conoce vLLM una biblioteca de aprendizaje automático de código abierto para una inferencia y servicio LLM rápidos
- Investigadores de Stanford presentan Spellburst un entorno de codificación creativa impulsado por un modelo de lenguaje grande (LLM).
- IA para desarrolladores web Introducción y configuración del proyecto






