Encuestas Simples con Streamlit
'Simple Surveys with Streamlit'
Los componentes de la interfaz de usuario de Streamlit facilitan la construcción de encuestas simples
- ¿Qué piensas sobre el futuro de la IA? ¿Debe ser regulada, creará nuevos trabajos o los destruirá?
- ¿Cómo crees que afectará el cambio climático a tu forma de vida?
- ¿Crees que hay vida alienígena en el universo?
- ¿Cuál es tu lenguaje de programación preferido para ciencia de datos?
A veces utilizamos los datos de otras personas para crear una historia, otras veces necesitamos crear nuestros propios datos y, por lo tanto, tenemos que recolectarlos. Esto puede ser una encuesta o un registro de resultados experimentales, pero necesitamos presentar preguntas y registrar los datos resultantes.
Por supuesto, hay servicios que lo harán por ti (a veces por una tarifa, pero a menudo también hay opciones gratuitas). O podrías quedarte con el método clásico de lápiz y papel.
Pero si eres usuario de Streamlit, crear una encuesta simple es bastante fácil.
Almacenando los datos
Sin embargo, hay un punto de bloqueo, aunque los componentes de la interfaz de usuario de Streamlit son excelentes y fáciles de usar, no hay métodos de almacenamiento de datos incorporados. Simplemente podrías almacenar los datos en un archivo de texto o una base de datos SQLite y eso funcionaría bien, pero solo para una aplicación local.
- Inteligencia Artificial Generativa vs NoCode en Desarrollo Web Un Nuevo Cambio de Paradigma.
- Mejores Herramientas de IA para Startups de E-commerce (2023)
- Presentamos OpenChat La plataforma gratuita y sencilla para construir chatbots personalizados en minutos.
Si intentas desplegar esa aplicación en Streamlit Cloud, descubrirás que cualquier dato que crees desaparece.
Es obvio cuando lo piensas.
Cuando inicias una aplicación de Streamlit Cloud, copia los archivos fuente de Github, incluidos los archivos de datos o las bases de datos, pero cuando sales de la aplicación, nada se escribe de vuelta. Así que cuando vuelves a iniciar la aplicación, estás comenzando desde cero. Cualquier dato que hayas recopilado y almacenado solo dura mientras la aplicación esté en ejecución. Cuando sales de la aplicación, esos datos se pierden.
No es un comportamiento genial para una aplicación de encuestas.
Los desarrolladores de Streamlit, por supuesto, han pensado en esto y han sugerido soluciones en su documentación (consulte la sección de tutoriales en la “Base de conocimientos”). En su mayoría, se refieren a la conexión con servidores de bases de datos que ejecutan varios sistemas de bases de datos como MySQL, Microsoft SQL Server, etc., pero también muestran cómo usar Streamlit con servicios basados en la nube como Amazon S3, MongoDB y Google Cloud Storage.
También existe Databutton, que es un entorno integral de desarrollo en línea para Streamlit que presenta, entre otras cosas, implementación con un clic, codificación con soporte de IA y, convenientemente, almacenamiento de datos como parte de los entornos de desarrollo e implementación.
Por ahora, nos concentraremos en la parte de la encuesta y trataremos el almacenamiento por separado. En esta aplicación, simplemente usaremos un archivo local para almacenar los datos, pero para hacer nuestras vidas futuras más fáciles, pondremos todas las operaciones de archivos en una biblioteca. De esa manera, si queremos migrar a otra plataforma, simplemente necesitamos volver a escribir la biblioteca. Así que, ten en cuenta que nuestra aplicación inicial no está diseñada para ser implementada, sino para funcionar en una máquina local.
Crear una encuesta en Streamlit
Streamlit proporciona una buena selección de componentes de interfaz de usuario que se pueden utilizar para crear, presentar y analizar datos de encuestas. En particular, haremos uso de grupos de botones de radio para implementar preguntas de opción múltiple y el dataframe editable para mostrar y editar el cuestionario en sí mismo.

Podemos pensar en presentaciones más sofisticadas o diferentes tipos de preguntas, más adelante, por el momento, lo mantendremos simple.
Hay tres componentes en la aplicación: el editor de cuestionarios; la presentación de la encuesta; y el analizador / visualizador de resultados. Los he implementado como páginas en una aplicación de varias páginas. (Todo lo que significa es que viven en una carpeta llamada “páginas”).
El editor
Utilizaremos principalmente diccionarios de Python para representar nuestros datos, tanto el cuestionario como los resultados, y en esta versión de la aplicación local, lo almacenaremos como archivos JSON.
Las preguntas se almacenarán en dos campos, text, una cadena que contiene el texto de la pregunta y responses, que es una cadena de respuestas de opción múltiple separadas por comas.
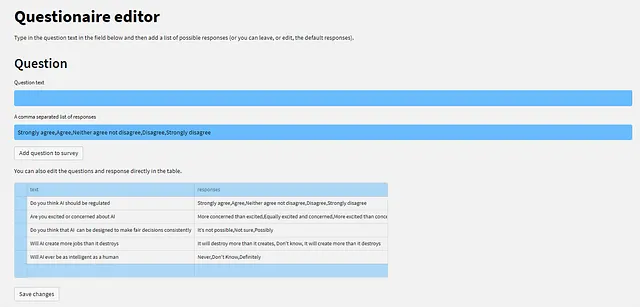
Puedes ver los datos de la pregunta mostrados como un componente data_editor de Streamlit en la captura de pantalla de abajo. Y usando este componente, puedes editar el cuestionario directamente, si lo deseas.
Encima del dataframe editable hay un par de campos: el primero es para la pregunta y el segundo es para la lista de posibles respuestas. Completa esto y presiona el botón Agregar pregunta al cuestionario y verás que aparece la nueva pregunta en el dataframe.
Como dije, también puedes editar el dataframe directamente: haz clic en el campo correspondiente para cambiar los datos existentes; haz clic a la izquierda de una fila para seleccionarla y usa la tecla de borrar para eliminarla; o haz clic a la izquierda debajo de la última fila para agregar una nueva fila.
En cualquier caso, debes presionar Guardar cambios para almacenar los datos.
Puedes ver la implementación a continuación.
Los programas de Streamlit se vuelven a ejecutar cada vez que hay una interacción del usuario, por lo que usamos la facilidad de sesión de Streamlit para almacenar el cuestionario para que su valor se mantenga correctamente. Aparte de eso, es un programa de Streamlit bastante sencillo; presenta dos componentes st.text_input() (agrega una cadena de respuesta predeterminada al segundo) seguidos de un st.data_editor() que muestra el cuestionario y permite modificarlo.
La última parte del programa es donde se almacenan los datos. Esto utiliza rutinas que he escrito en la librería DButils. Estos son esencialmente un envoltorio alrededor de las funciones básicas de almacenamiento de archivos, como dije anteriormente, he implementado el almacenamiento como estos para que los programas puedan usarse con opciones de almacenamiento alternativas en una plataforma diferente.
DButils.get_survey() recupera el cuestionario almacenado y DButils.save_survey() guarda todo el dataframe en el archivo.
import streamlit as stimport DButilsst.set_page_config(layout="wide")if 'survey' not in st.session_state: st.session_state['survey'] = DButils.get_survey()st.title("Editor de cuestionarios")st.write("""Escribe el texto de la pregunta en el campo de abajo y luego agrega una lista de posibles respuestas (o puedes dejar o editar las respuestas predeterminadas).""")# Establecer una respuesta predeterminadadefault_response = ( "Totalmente de acuerdo,De acuerdo,No estoy de acuerdo ni en desacuerdo,En desacuerdo,Totalmente en desacuerdo")st.header("Pregunta")q_text = st.text_input("Texto de la pregunta")q_responses = st.text_input( "Una lista separada por comas de respuestas", value=default_response)submitted = st.button("Agregar pregunta al cuestionario")if submitted: st.session_state['survey'].append( { "text": q_text, "responses": q_responses, } )st.write("También puedes editar las preguntas y respuestas directamente en la tabla.")edited_df = st.data_editor(st.session_state['survey'], num_rows="dynamic")save = st.button("Guardar cambios")if save: DButils.save_survey(edited_df) st.success(f"Cambios guardados")Presentar el cuestionario
Cada pregunta se presenta como un grupo de botones de radio.
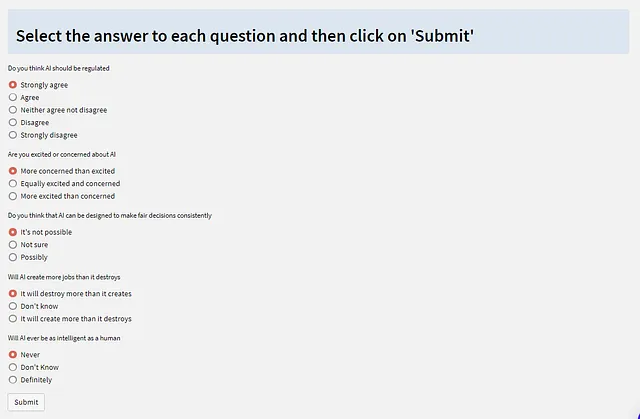
Como puedes ver a continuación, iteramos a través del cuestionario, extrayendo el campo text para la indicación y dividiendo el campo responses en sus respuestas separadas para mostrar el grupo de botones.
import pandas as pdimport streamlit as stimport DButilsst.info("## Selecciona la respuesta para cada pregunta y luego haz clic en 'Enviar'")questions = DButils.get_survey()responses = {}for q in questions: response = st.radio(label=q['text'], options=q['responses'].split(",")) responses[q['text']] = response.strip()if st.button("Enviar"): entry = responses DButils.append_results(entry) st.write("Actualizado")El conjunto completo de datos grabados se añade a las respuestas almacenadas con DButils.update().
Presentar los resultados
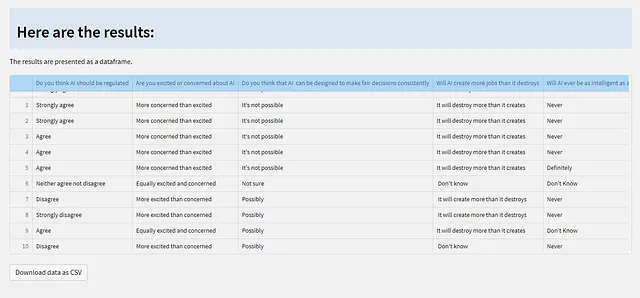
La página de resultados se divide en 3 secciones: la primera muestra los resultados como una tabla de datos que se puede descargar como un archivo CSV.
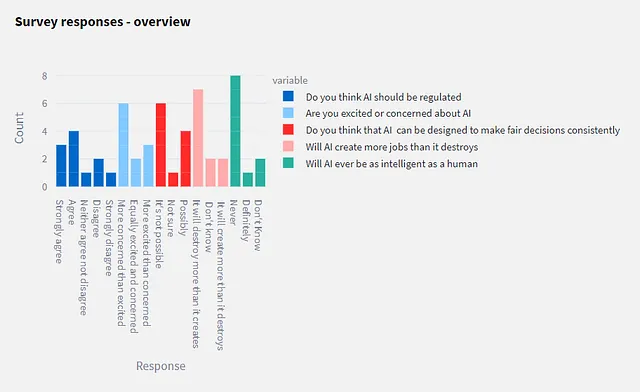
La segunda parte es una visión general gráfica de toda la encuesta. El gráfico de barras se crea con Plotly Express.
Y la parte final permite al usuario seleccionar los resultados para cada pregunta que se muestran como un gráfico de barras (también con Plotly).
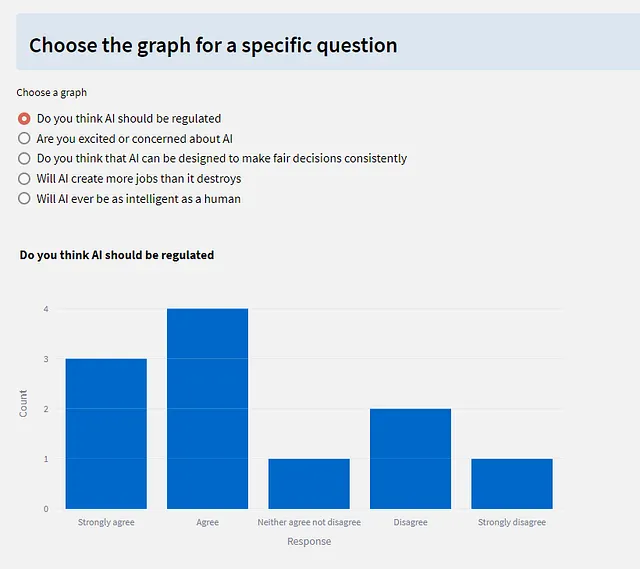
El código para esto se presenta a continuación. Usamos DButils.get_results() para cargar el dataframe de resultados y luego mostrarlo como un st.dataframe() (¡no editable, por supuesto!) y agregamos un botón de descarga que guardará los datos en tu máquina local como un archivo CSV.
Después de esto, hay un gráfico de barras de todos los datos de respuesta (coloreado para cada pregunta). Y como esto no necesariamente es lo más fácil de leer, sigue un grupo de botones de radio que te permite elegir una pregunta específica en la que centrarte. Los gráficos de barras para cada pregunta se dibujan de antemano, en un bucle, y se muestra el apropiado para el botón de radio seleccionado.
import streamlit as stimport plotly.express as pximport pandas as pdimport DButilsst.set_page_config(layout="wide")st.info("## Aquí están los resultados:")st.write("Los resultados se presentan como un dataframe.")# Leer datos del botón de almacenamiento de datos de Databaseresults = DButils.get_results()st.dataframe(results, use_container_width=True)df = pd.DataFrame(results)st.download_button( label="Descargar datos como CSV", data=df.to_csv().encode("utf-8"), file_name="survey_results.csv", mime="text/csv",)# Graficar un resumen del gráfico de barrasfig = px.bar(results, title="Respuestas de la encuesta - resumen")fig.update_xaxes(title_text="Respuesta")fig.update_yaxes(title_text="Recuento")st.plotly_chart(fig)# Crear una matriz de figuras de gráficos de barras# una para cada pregunta figures = []for q in df.columns: fig = px.bar(df[q], title=q) fig.update_layout(showlegend=False) fig.update_xaxes(title_text="Respuesta") fig.update_yaxes(title_text="Recuento") figures.append(fig)# Elegir qué gráfico mostrar con un conjunto de botones de radiost.info("### Elija el gráfico para una pregunta específica")f = st.radio("Elegir un gráfico", options=df.columns)column_index = df.columns.get_loc(f)st.plotly_chart(figures[column_index])La biblioteca DButils
Como se puede ver a continuación, la biblioteca DButils tiene varias funciones para leer, escribir y actualizar archivos CSV. También define constantes para los dos archivos que usamos anteriormente.
La biblioteca está escrita específicamente para una aplicación local que utiliza archivos JSON para almacenar los datos, pero si quisieras portarla a otra plataforma, solo hay cuatro funciones simples para reescribir y dos constantes para definir.
import osimport jsonSURVEY_KEY = "survey.json"RESULTS_KEY = "results.json"# Guardar datosdef save_dict(value, key=SURVEY_KEY): print(f"Guardando: {value}") #return None out_file = open(key, "w") json.dump(value,out_file) out_file.close()def save_results(value): save_dict(value,RESULTS_KEY)def save_survey(value): save_dict(value, SURVEY_KEY)# Recuperar datosdef retrieve(key): # si el archivo existe, léalo y devuelva la matriz de diccionarios if os.path.isfile(key): in_file = open(key, "r") result = json.load(in_file) in_file.close() return result else: # si el archivo no existe, devuelva una matriz de diccionarios vacía return []def get_survey(key=SURVEY_KEY): return retrieve(key)def get_results(key=RESULTS_KEY): return retrieve(key)# Actualizar resultados# Esto puede no ser eficiente, pero es simpledef append_results(value): results = get_results() results.append(value) save_results(results)En el mundo real
Espero que estés de acuerdo en que estas rutinas simples crean una aplicación razonablemente atractiva y te muestran cómo se puede utilizar Streamlit para crear encuestas sencillas.
Pero hay algunas cosas en las que tendrías que pensar si quisieras implementar algo así en el mundo real.
Aquí hay algunas cosas que podrías considerar:
- Aunque las encuestas se hacen de forma anónima, es posible que desees identificar al encuestado para evitar entradas duplicadas.
- Es posible que desees incluir diferentes tipos de preguntas o presentarlas de diferentes maneras (por ejemplo, un
st.select_slider()). - La aleatorización de la forma en que se presentan las respuestas puede evitar que el encuestado sea llevado a una respuesta en particular.
- Casi con toda seguridad, querrías añadir preguntas demográficas a la encuesta. Estas también se pueden implementar como preguntas de opción múltiple, pero los resultados deben tratarse de manera diferente a los demás al realizar el análisis.
Pero esto no es un tutorial sobre cómo diseñar una encuesta, así que lo dejaré aquí.
Gracias por leer, espero que lo hayas encontrado una guía útil sobre cómo abordar el diseño de encuestas en Streamlit. Esta aplicación es deliberadamente muy simple y el almacenamiento de datos sólo funciona cuando la aplicación se implementa localmente; espero abordar estos temas en un artículo posterior.
Si quieres ver más de mi trabajo, por favor, echa un vistazo a mi página web.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Informe del Índice de Inteligencia Artificial 2023 Tendencias de la IA que podemos esperar en el futuro.
- Sugerencias de mitad de camino para personajes de dibujos animados.
- Pasar por la casilla de salida, recoger más juegos Xbox Game Pass llega a GeForce NOW.
- Las 5 mejores empresas de Desarrollo de IA para transformar su negocio.
- La cineasta Sara Dietschy habla sobre AI esta semana ‘En el Estudio NVIDIA’.
- Revelando el futuro 10 herramientas de IA de vanguardia que simplemente no puedes ignorar (junio de 2023)
- Imagen Editor y EditBench Avanzando y evaluando el relleno de imágenes guiado por texto.






