¿SEER ¿Un avance en los modelos de visión por computadora con autoaprendizaje?
¿SEER? ¿Un avance en los modelos de visión por computadora con autoaprendizaje?
En la última década, la Inteligencia Artificial (IA) y el Aprendizaje Automático (AA) han experimentado un tremendo progreso. Hoy en día, son más precisos, eficientes y capaces que nunca. Los modelos modernos de IA y AA pueden reconocer objetos en imágenes o archivos de video de manera precisa y sin problemas. Además, pueden generar texto y voz que se asemeja a la inteligencia humana.
Los modelos de IA y AA de hoy en día dependen en gran medida del entrenamiento en conjuntos de datos etiquetados que les enseñan cómo interpretar un bloque de texto, identificar objetos en una imagen o fotograma de video, y realizar varias otras tareas.
A pesar de sus capacidades, los modelos de IA y AA no son perfectos, y los científicos están trabajando para construir modelos que sean capaces de aprender de la información que se les proporciona, sin depender necesariamente de datos etiquetados o anotados. Este enfoque se conoce como aprendizaje auto-supervisado, y es uno de los métodos más eficientes para construir modelos de IA y AA que tengan el “sentido común” o conocimiento de fondo para resolver problemas que están más allá de las capacidades de los modelos de IA actuales.
El aprendizaje auto-supervisado ya ha demostrado sus resultados en el Procesamiento del Lenguaje Natural, ya que ha permitido a los desarrolladores entrenar modelos grandes que pueden trabajar con una enorme cantidad de datos, y ha llevado a varios avances en los campos de la inferencia del lenguaje natural, la traducción automática y la respuesta a preguntas.
- El mercado global de chips de inteligencia artificial experimentará una enorme tasa de crecimiento anual compuesta (CAGR) del 31.8% hasta el año 2031.
- 6 Razones por las cuales los eventos presenciales siguen siendo los reyes de la generación de leads
- Basura entra, basura sale El papel crucial de la calidad de los datos en la IA
El modelo SEER de Facebook AI tiene como objetivo maximizar las capacidades del aprendizaje auto-supervisado en el campo de la visión por computadora. SEER o SElf SupERvised es un modelo de aprendizaje auto-supervisado de visión por computadora que tiene más de mil millones de parámetros, y es capaz de encontrar patrones o aprender incluso de un grupo aleatorio de imágenes encontradas en Internet sin anotaciones o etiquetas adecuadas.
La Necesidad del Aprendizaje Auto-Supervisado en la Visión por Computadora
La anotación de datos es una etapa de preprocesamiento en el desarrollo de modelos de aprendizaje automático e inteligencia artificial. El proceso de anotación de datos identifica datos sin procesar como imágenes o fotogramas de video, y luego agrega etiquetas a los datos para especificar el contexto de los datos para el modelo. Estas etiquetas permiten que el modelo realice predicciones precisas sobre los datos.
Uno de los mayores desafíos a los que se enfrentan los desarrolladores al trabajar en modelos de visión por computadora es encontrar datos anotados de alta calidad. Los modelos de visión por computadora de hoy en día dependen de estos conjuntos de datos etiquetados o anotados para aprender los patrones que les permiten reconocer objetos en la imagen.
La anotación de datos y su uso en el modelo de visión por computadora plantean los siguientes desafíos:
Gestión de la Calidad Consistente del Conjunto de Datos
Probablemente el mayor desafío para los desarrolladores es acceder de manera consistente a conjuntos de datos de alta calidad, ya que los conjuntos de datos de alta calidad con etiquetas adecuadas e imágenes claras resultan en un aprendizaje mejor y modelos más precisos. Sin embargo, acceder consistentemente a conjuntos de datos de alta calidad tiene sus propios desafíos.
Gestión de la Fuerza Laboral
La anotación de datos a menudo conlleva problemas de gestión de la fuerza laboral principalmente porque se requiere un gran número de trabajadores para procesar y etiquetar grandes cantidades de datos no estructurados y sin etiquetar, al tiempo que se garantiza la calidad. Por lo tanto, es esencial que los desarrolladores encuentren un equilibrio entre calidad y cantidad cuando se trata de la anotación de datos.
Restricciones Financieras
Probablemente el mayor obstáculo sean las restricciones financieras que acompañan al proceso de anotación de datos, y la mayoría de las veces, el costo de la anotación de datos representa un porcentaje significativo del costo total del proyecto.
Como se puede ver, la anotación de datos es un gran obstáculo en el desarrollo de modelos avanzados de visión por computadora, especialmente cuando se trata de desarrollar modelos complejos que manejan una gran cantidad de datos de entrenamiento. Es la razón por la cual la industria de la visión por computadora necesita el aprendizaje auto-supervisado para desarrollar modelos de visión por computadora complejos y avanzados que sean capaces de abordar tareas que están más allá del alcance de los modelos actuales.
Dicho esto, ya hay muchos modelos de aprendizaje auto-supervisado que han tenido un buen desempeño en un entorno controlado, y principalmente en el conjunto de datos ImageNet. Aunque estos modelos pueden estar haciendo un buen trabajo, no cumplen con la condición principal del aprendizaje auto-supervisado en la visión por computadora: aprender de cualquier conjunto de datos ilimitado o imagen aleatoria, y no solo de un conjunto de datos bien definido. Cuando se implementa de manera ideal, el aprendizaje auto-supervisado puede ayudar a desarrollar modelos de visión por computadora más precisos y capaces, que también sean rentables y viables.
SEER o el Modelo SElf-supERvised: Una Introducción
Las tendencias recientes en la industria de IA y ML han indicado que enfoques de pre-entrenamiento del modelo como el aprendizaje semi-supervisado, débilmente supervisado y auto-supervisado pueden mejorar significativamente el rendimiento de la mayoría de los modelos de aprendizaje profundo para tareas posteriores.
Hay dos factores clave que han contribuido masivamente al impulso en el rendimiento de estos modelos de aprendizaje profundo.
Pre-Entrenamiento en Conjuntos de Datos Masivos
El pre-entrenamiento en conjuntos de datos masivos generalmente resulta en una mejor precisión y rendimiento porque expone al modelo a una amplia variedad de datos. Un conjunto de datos grande permite que los modelos comprendan mejor los patrones en los datos, y en última instancia, esto se traduce en un mejor rendimiento del modelo en escenarios de la vida real.
Algunos de los modelos con mejor rendimiento, como el modelo GPT-3 y el modelo Wav2vec 2.0, están entrenados en conjuntos de datos masivos. El modelo de lenguaje GPT-3 utiliza un conjunto de datos de pre-entrenamiento con más de 300 mil millones de palabras, mientras que el modelo Wav2vec 2.0 para reconocimiento de voz utiliza un conjunto de datos con más de 53 mil horas de datos de audio.
Modelos con Capacidad Masiva
Los modelos con un mayor número de parámetros suelen producir resultados precisos porque un mayor número de parámetros permite que el modelo se centre solo en los objetos en los datos que son necesarios en lugar de centrarse en la interferencia o el ruido en los datos.
Los desarrolladores en el pasado han intentado entrenar modelos de aprendizaje auto-supervisado en datos no etiquetados o no curados, pero con conjuntos de datos más pequeños que contenían solo algunos millones de imágenes. ¿Pero pueden los modelos de aprendizaje auto-supervisado producir una alta precisión cuando se entrenan en una gran cantidad de datos no etiquetados y no curados? Es precisamente la pregunta que el modelo SEER pretende responder.
El modelo SEER es un marco de aprendizaje profundo que tiene como objetivo registrar imágenes disponibles en Internet de manera independiente a los conjuntos de datos curados o etiquetados. El marco SEER permite a los desarrolladores entrenar modelos de ML grandes y complejos en datos aleatorios sin supervisión, es decir, el modelo analiza los datos y aprende los patrones o información por sí mismo sin ninguna entrada manual agregada.
El objetivo final del modelo SEER es ayudar en el desarrollo de estrategias para el proceso de pre-entrenamiento que utilicen datos no curados para brindar un rendimiento de vanguardia en el aprendizaje por transferencia. Además, el modelo SEER también tiene como objetivo crear sistemas que puedan aprender continuamente de una corriente interminable de datos de manera auto-supervisada.
El marco SEER entrena modelos de alta capacidad en miles de millones de imágenes aleatorias y sin restricciones extraídas de Internet. Los modelos entrenados en estas imágenes no dependen de los metadatos o anotaciones de las imágenes para entrenar el modelo o filtrar los datos. En los últimos tiempos, el aprendizaje auto-supervisado ha mostrado un alto potencial, ya que entrenar modelos en datos no curados ha dado mejores resultados en comparación con modelos pre-entrenados supervisados para tareas posteriores.
Marco SEER y RegNet: ¿Cuál es la conexión?
Para analizar el modelo SEER, se centra en la arquitectura RegNet con más de 700 millones de parámetros que se alinean con el objetivo de SEER de aprendizaje auto-supervisado en datos no curados para dos razones principales:
- Ofrecen un equilibrio perfecto entre rendimiento y eficiencia.
- Son altamente flexibles y se pueden usar para escalar en cuanto al número de parámetros.
Marco SEER: Trabajo Previo de Diferentes Áreas
El marco SEER tiene como objetivo explorar los límites del entrenamiento de arquitecturas de modelos grandes en conjuntos de datos no curados o no etiquetados utilizando el aprendizaje auto-supervisado, y el modelo se inspira en trabajos previos en el campo.
Pre-Entrenamiento No Supervisado de Características Visuales
El aprendizaje auto-supervisado se ha implementado en la visión por computadora desde hace algún tiempo con métodos que utilizan autoencoders, discriminación a nivel de instancia o agrupamiento. En los últimos tiempos, los métodos que utilizan el aprendizaje por contraste han indicado que el pre-entrenamiento de modelos utilizando el aprendizaje no supervisado para tareas posteriores puede tener un mejor rendimiento que un enfoque de aprendizaje supervisado.
La lección principal del aprendizaje no supervisado de características visuales es que mientras se esté entrenando con datos filtrados, no son necesarias las etiquetas supervisadas. El modelo SEER tiene como objetivo explorar si el modelo puede aprender representaciones precisas cuando se entrenan grandes arquitecturas de modelo con una gran cantidad de imágenes no curadas, no etiquetadas y aleatorias.
Aprendizaje de características visuales a gran escala
Los modelos anteriores se han beneficiado del preentrenamiento de los modelos en grandes conjuntos de datos etiquetados con aprendizaje supervisado débil, aprendizaje supervisado y aprendizaje semi-supervisado en millones de imágenes filtradas. Además, el análisis del modelo también ha indicado que el preentrenamiento del modelo en miles de millones de imágenes a menudo produce una mayor precisión en comparación con el entrenamiento del modelo desde cero.
Además, el entrenamiento del modelo a gran escala generalmente se basa en pasos de filtrado de datos para hacer que las imágenes resuenen con los conceptos objetivo. Estos pasos de filtrado utilizan predicciones de un clasificador preentrenado o hashtags que a menudo son sinónimos de las clases de ImageNet. El modelo SEER funciona de manera diferente, ya que tiene como objetivo aprender características en cualquier imagen aleatoria, por lo que los datos de entrenamiento para el modelo SEER no están curados para coincidir con un conjunto predefinido de características o conceptos.
Escalar arquitecturas para reconocimiento de imágenes
Los modelos generalmente se benefician de entrenar arquitecturas grandes en características visuales resultantes de mejor calidad. Es esencial entrenar arquitecturas grandes cuando el preentrenamiento en un gran conjunto de datos es importante porque un modelo con capacidad limitada a menudo produce un ajuste insuficiente. Esto es aún más importante cuando el preentrenamiento se realiza junto con el aprendizaje contrastivo, ya que en esos casos, el modelo debe aprender a discriminar entre instancias del conjunto de datos para poder aprender mejores representaciones visuales.
Sin embargo, para el reconocimiento de imágenes, la escala de la arquitectura involucra mucho más que cambiar la profundidad y el ancho del modelo, y para construir un modelo eficiente a escala con mayor capacidad, se necesita dedicar mucha literatura. El modelo SEER muestra los beneficios de usar la familia de modelos RegNets para implementar el aprendizaje auto-supervisado a gran escala.
SEER: Métodos y componentes utilizados
El marco de SEER utiliza una variedad de métodos y componentes para preentrenar el modelo y aprender representaciones visuales. Algunos de los principales métodos y componentes utilizados por el marco de SEER son: RegNet y SwAV. Discutamos brevemente los métodos y componentes utilizados en el marco de SEER.
Preentrenamiento auto-supervisado con SwAV
El marco de SEER se preentrena con SwAV, un enfoque de aprendizaje auto-supervisado en línea. SwAV es un método de agrupación en línea que se utiliza para entrenar el marco de convnets sin anotaciones. El marco de SwAV funciona entrenando una incrustación que produce asignaciones de grupos consistentes entre diferentes vistas de la misma imagen. Luego, el sistema aprende representaciones semánticas mediante la búsqueda de grupos que son invariantes a las aumentaciones de datos.
En la práctica, el marco de SwAV compara las características de las diferentes vistas de una imagen utilizando sus asignaciones de grupo independientes. Si estas asignaciones capturan características similares, es posible predecir la asignación de una imagen utilizando la característica de otra vista.
El modelo SEER considera un conjunto de K grupos, y cada uno de estos grupos está asociado con un vector aprendible de dimensión d, vk. Para un lote de B imágenes, cada imagen i se transforma en dos vistas diferentes: xi1 y xi2. Luego, las vistas se representan con la ayuda de una convnet, lo que da como resultado dos conjuntos de características: (f11, …, fB2) y (f12, …, fB2). Cada conjunto de características se asigna independientemente a prototipos de grupos con la ayuda de un solucionador de Transporte Óptimo.
El solucionador de Transporte Óptimo garantiza que las características se distribuyan equitativamente entre los grupos y ayuda a evitar soluciones triviales en las que todas las representaciones se asignan a un solo prototipo. A continuación, se intercambia la asignación resultante entre los dos conjuntos: la asignación de grupo yi1 de la vista xi1 debe predecirse utilizando la representación de características fi2 de la vista xi2 y viceversa.
Los pesos de los prototipos y la convnet se entrenan para minimizar la pérdida para todos los ejemplos. La pérdida de predicción de grupo l es esencialmente la entropía cruzada entre un softmax del producto escalar de f y la asignación de grupo.

RegNetY: Familia de Modelos Eficientes en Escala
Para escalar la capacidad del modelo y los datos se requieren arquitecturas eficientes no solo en términos de memoria, sino también en términos de tiempo de ejecución. El marco RegNets es una familia de modelos diseñados específicamente para este propósito.
La familia de arquitecturas RegNet está definida por un espacio de diseño de convnets con 4 etapas, donde cada etapa contiene una serie de bloques idénticos mientras se asegura que la estructura de su bloque permanezca fija, principalmente el bloque residual de cuello de botella.
El marco SEER se centra en la arquitectura RegNetY y agrega una Squeeze-and-Excitation a la arquitectura estándar de RegNets en un intento por mejorar su rendimiento. Además, el modelo RegNetY tiene 5 parámetros que ayudan en la búsqueda de buenas instancias con un número fijo de FLOPs que consumen recursos razonables. El modelo SEER tiene como objetivo mejorar sus resultados implementando directamente la arquitectura RegNetY en su tarea de pre-entrenamiento auto-supervisado.
La Arquitectura RegNetY 256GF: El modelo SEER se centra principalmente en la arquitectura RegNetY 256GF en la familia RegNetY, y sus parámetros utilizan la regla de escalado de la arquitectura RegNets. Los parámetros se describen de la siguiente manera.

La arquitectura RegNetY 256GF tiene 4 etapas con anchos de etapa (528, 1056, 2904, 7392) y profundidades de etapa (2, 7, 17, 1) que suman más de 696 millones de parámetros. Al entrenar en las GPUs NVIDIA 512 V100 32GB, cada iteración tarda aproximadamente 6125ms para un tamaño de lote de 8,704 imágenes. Entrenar el modelo en un conjunto de datos con más de mil millones de imágenes, con un tamaño de lote de 8,704 imágenes en más de 512 GPUs, requiere 114,890 iteraciones, y el entrenamiento dura aproximadamente 8 días.
Optimización y Entrenamiento a Gran Escala
El modelo SEER propone varios ajustes para entrenar métodos auto-supervisados y aplicar y adaptar estos métodos a gran escala. Estos métodos son:
- Programa de tasa de aprendizaje.
- Reducción del consumo de memoria por GPU.
- Optimización de la velocidad de entrenamiento.
- Pre-entrenamiento de datos a gran escala.
Vamos a discutirlos brevemente.
Programa de Tasa de Aprendizaje
El modelo SEER explora la posibilidad de utilizar dos programas de tasa de aprendizaje: el programa de tasa de aprendizaje de onda coseno y el programa de tasa de aprendizaje fija.
El programa de tasa de aprendizaje de onda coseno se utiliza para comparar diferentes modelos de manera justa, ya que se adapta al número de actualizaciones. Sin embargo, este programa de tasa de aprendizaje de onda coseno no se adapta a un entrenamiento a gran escala principalmente porque pondera las imágenes de manera diferente según cuándo se ven durante el entrenamiento, y también utiliza actualizaciones completas para su programación.
El programa de tasa de aprendizaje fija mantiene la tasa de aprendizaje fija hasta que la pérdida no disminuya, y luego la tasa de aprendizaje se divide por 2. El análisis muestra que el programa de tasa de aprendizaje fija funciona mejor, ya que tiene margen para hacer que el entrenamiento sea más flexible. Sin embargo, debido a que el modelo solo se entrena en mil millones de imágenes, utiliza el programa de tasa de aprendizaje de onda coseno para entrenar su modelo más grande, el RegNet 256GF.
Reducción del Consumo de Memoria por GPU
El modelo también tiene como objetivo reducir la cantidad de GPU necesaria durante el período de entrenamiento mediante el uso de precisión mixta y checkpointing graduado. El modelo utiliza el nivel de optimización O1 de la biblioteca Apex de NVIDIA para realizar operaciones como convoluciones y GEMMs en precisión de punto flotante de 16 bits. El modelo también utiliza la implementación de checkpointing de gradientes de PyTorch que intercambia cómputos por memoria.
Además, el modelo también descarta cualquier activación intermedia realizada durante el pase hacia adelante, y durante el pase hacia atrás, vuelve a calcular estas activaciones.
Optimización de la Velocidad de Entrenamiento
El uso de precisión mixta para optimizar el uso de memoria tiene beneficios adicionales, ya que los aceleradores aprovechan el tamaño reducido de FP16 al aumentar el rendimiento en comparación con el FP32. Ayuda a acelerar el período de entrenamiento mejorando el cuello de botella de ancho de banda de memoria.
El modelo SEER también sincroniza la capa de BatchNorm entre las GPU para crear grupos de procesos en lugar de usar una sincronización global que generalmente lleva más tiempo. Finalmente, el cargador de datos utilizado en el modelo SEER pre-carga más lotes de entrenamiento que conduce a una mayor cantidad de datos que se procesan cuando se compara con el cargador de datos de PyTorch.
Gran Escala de Datos de Pre-Entrenamiento
El modelo SEER utiliza más de mil millones de imágenes durante el pre-entrenamiento, y considera un cargador de datos que muestrea imágenes aleatorias directamente de Internet y de Instagram. Debido a que el modelo SEER entrena estas imágenes en entornos naturales y en línea, no aplica ningún preprocesamiento ni las cura utilizando procesos como la deduplicación o el filtrado de hashtags.
Cabe destacar que el conjunto de datos no es estático y las imágenes se actualizan cada tres meses. Sin embargo, la actualización del conjunto de datos no afecta el rendimiento del modelo.
Implementación del Modelo SEER
El modelo SEER preentrena un RegNetY 256GF con SwAV utilizando seis recortes por imagen, cada una con una resolución de 2×224 + 4×96. Durante la fase de pre-entrenamiento, el modelo utiliza un MLP o Perceptrón Multicapa de 3 capas con proyecciones de dimensiones 10444×8192, 8192×8192 y 8192×256.
En lugar de utilizar capas BatchNorm en la cabeza, el modelo SEER utiliza 16,000 prototipos con una temperatura t establecida en 0.1. El parámetro de regularización de Sinkhorn se establece en 0.05, y realiza 10 iteraciones del algoritmo. El modelo además sincroniza las estadísticas de BatchNorm entre las GPU y crea numerosos grupos de procesos con un tamaño de 64 para la sincronización.
Además, el modelo utiliza un optimizador LARS o Escalamiento de Tasa de Aprendizaje Adaptativo por Capa, una decaída de peso de 10-5, puntos de control de activación y optimización de precisión mixta O1. Luego, el modelo se entrena con descenso de gradiente estocástico utilizando un tamaño de lote con 8192 imágenes aleatorias distribuidas en 512 GPU NVIDIA, lo que resulta en 16 imágenes por GPU.
La tasa de aprendizaje se aumenta linealmente de 0.15 a 9.6 para las primeras 8 mil actualizaciones de entrenamiento. Después del calentamiento, el modelo sigue un programa de tasa de aprendizaje coseno que decae a un valor final de 0.0096. En general, el modelo SEER se entrena con más de mil millones de imágenes en 122 mil iteraciones.
Marco de Trabajo SEER: Resultados
La calidad de las características generadas por el enfoque de pre-entrenamiento auto-supervisado se estudia y analiza en una variedad de conjuntos de pruebas y tareas secundarias. El modelo también considera una configuración de baja disponibilidad que otorga acceso limitado a las imágenes y sus etiquetas para tareas secundarias.
Ajuste Fino de Modelos Pre-Entrenados a Gran Escala
Mide la calidad de los modelos preentrenados en datos aleatorios transfiriéndolos al conjunto de pruebas de ImageNet para la clasificación de objetos. Los resultados del ajuste fino de modelos preentrenados a gran escala se determinan en los siguientes parámetros.
Configuraciones Experimentales
El modelo preentrena 6 arquitecturas RegNet con diferentes capacidades, a saber, RegNetY- {8,16,32,64,128,256}GF, en más de mil millones de imágenes aleatorias y públicas de Instagram con SwAV. Luego, los modelos se ajustan finamente con el propósito de clasificación de imágenes en ImageNet, que utiliza más de 1.28 millones de imágenes de entrenamiento estándar con etiquetas adecuadas, y tiene un conjunto de validación estándar con más de 50 mil imágenes para la evaluación.
Luego, el modelo aplica las mismas técnicas de aumento de datos que en SwAV, y se ajusta finamente durante 35 épocas con el optimizador SGD o Descenso de Gradiente Estocástico con un tamaño de lote de 256, y una tasa de aprendizaje de 0.0125 que se reduce en un factor de 10 después de 30 épocas, con un momento de 0.9 y una decaída de peso de 10-4. El modelo informa la precisión top-1 en el conjunto de datos de validación utilizando el recorte central de 224×224.
Comparación con otros enfoques de Pre-entrenamiento Auto Supervisado
En la siguiente tabla, se compara el modelo pre-entrenado más grande en RegNetY-256GF con modelos pre-entrenados existentes que utilizan el enfoque de aprendizaje auto supervisado.
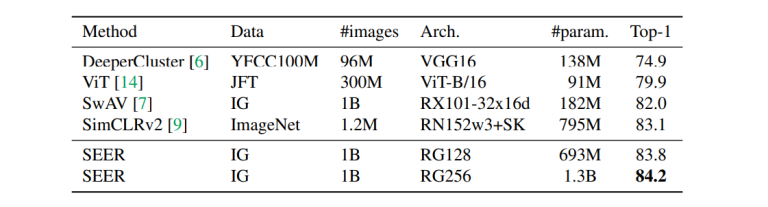
Como se puede ver, el modelo SEER tiene una precisión top-1 de 84.2% en ImageNet, y supera a SimCLRv2, el mejor modelo pre-entrenado existente en un 1%.
Además, la siguiente figura compara el marco de trabajo SEER con modelos de diferentes capacidades. Como se puede observar, independientemente de la capacidad del modelo, combinar el marco de trabajo RegNet con SwAV produce resultados precisos durante el pre-entrenamiento.

El modelo SEER se pre-entrena en imágenes no curadas y aleatorias, y utiliza la arquitectura RegNet con el método de aprendizaje auto supervisado SwAV. El modelo SEER se compara con SimCLRv2 y los modelos ViT con diferentes arquitecturas de red. Finalmente, el modelo se ajusta finamente en el conjunto de datos ImageNet y se informa la precisión top-1.
Impacto de la Capacidad del Modelo
La capacidad del modelo tiene un impacto significativo en el rendimiento del pre-entrenamiento, y la siguiente figura lo compara con el impacto al entrenar desde cero.

Se puede ver claramente que la puntuación de precisión top-1 de los modelos pre-entrenados es mayor que la de los modelos entrenados desde cero, y la diferencia se hace cada vez mayor a medida que aumenta el número de parámetros. También es evidente que aunque la capacidad del modelo beneficia tanto a los modelos pre-entrenados como a los entrenados desde cero, el impacto es mayor en los modelos pre-entrenados cuando se trata de una gran cantidad de parámetros.
Una posible razón por la cual entrenar un modelo desde cero puede generar sobreajuste al entrenar en el conjunto de datos ImageNet es debido al tamaño pequeño del conjunto de datos.
Aprendizaje de Bajo Muestreo
El aprendizaje de bajo muestreo se refiere a evaluar el rendimiento del modelo SEER en un entorno de bajo muestreo, es decir, utilizando solo una fracción de los datos totales al realizar tareas posteriores.
Configuración Experimental
El marco de trabajo SEER utiliza dos conjuntos de datos para el aprendizaje de bajo muestreo, a saber, Places205 e ImageNet. Además, el modelo asume tener un acceso limitado al conjunto de datos durante el aprendizaje de transferencia tanto en términos de imágenes como de etiquetas. Esta configuración de acceso limitado es diferente de la configuración predeterminada utilizada para el aprendizaje auto supervisado, donde el modelo tiene acceso a todo el conjunto de datos y solo se limita el acceso a las etiquetas de imagen.
-
Resultados en el Conjunto de Datos Place205
La siguiente figura muestra el impacto de pre-entrenar el modelo en diferentes porciones del conjunto de datos Place205.

Se compara el enfoque utilizado con el pre-entrenamiento del modelo en el conjunto de datos ImageNet bajo supervisión con la misma arquitectura RegNetY-128 GF. Los resultados de la comparación son sorprendentes, ya que se puede observar que hay una ganancia estable de aproximadamente 2.5% en la precisión top-1 independientemente de la porción de datos de entrenamiento disponibles para el ajuste fino en el conjunto de datos Places205.
La diferencia observada entre los procesos de pre-entrenamiento supervisado y auto supervisado se puede explicar dada la diferencia en la naturaleza de los datos de entrenamiento, ya que las características aprendidas por el modelo a partir de imágenes aleatorias en la naturaleza pueden ser más adecuadas para clasificar la escena. Además, una distribución no uniforme del concepto subyacente puede resultar ventajosa para el pre-entrenamiento en un conjunto de datos desequilibrado como Places205.
Resultados en ImageNet
![]()
La tabla anterior compara el enfoque del modelo SEER con enfoques de pre-entrenamiento auto supervisado y semi-supervisado en el aprendizaje de bajo muestreo. Vale la pena destacar que todos estos métodos utilizan las 1.2 millones de imágenes en el conjunto de datos ImageNet para el pre-entrenamiento, y solo restringen el acceso a las etiquetas. Por otro lado, el enfoque utilizado en el modelo SEER solo permite ver del 1 al 10% de las imágenes en el conjunto de datos.
A medida que las redes han visto más imágenes de la misma distribución durante el pre-entrenamiento, esto beneficia enormemente a estos enfoques. Pero lo impresionante es que aunque el modelo SEER solo ve del 1 al 10% del conjunto de datos de ImageNet, aún logra una precisión de aproximadamente el 80% en el top 1, que se acerca al puntaje de precisión de los enfoques discutidos en la tabla anterior.
Impacto de la Capacidad del Modelo
La siguiente figura analiza el impacto de la capacidad del modelo en el aprendizaje de pocos ejemplos: al 1%, 10% y 100% del conjunto de datos de ImageNet.

Se puede observar que aumentar la capacidad del modelo puede mejorar el puntaje de precisión del modelo, ya que disminuye el acceso tanto a las imágenes como a las etiquetas en el conjunto de datos.
Transferencia a Otros Bancos de Pruebas
Para evaluar aún más el modelo SEER y analizar su rendimiento, se transfieren las características pre-entrenadas a otras tareas posteriores.
Evaluación Lineal de la Clasificación de Imágenes

La tabla anterior compara las características de RegNetY-256GF pre-entrenadas de SEER y RegNetY128-GF pre-entrenadas en el conjunto de datos de ImageNet con la misma arquitectura con y sin supervisión. Para analizar la calidad de las características, el modelo congela los pesos y utiliza un clasificador lineal sobre las características utilizando el conjunto de entrenamiento para las tareas posteriores. Se consideran los siguientes bancos de pruebas para el proceso: Open-Images (OpIm), iNaturalist (iNat), Places205 (Places) y Pascal VOC (VOC).
Detección y Segmentación
La siguiente figura compara las características pre-entrenadas en detección y segmentación, y las evalúa.

El marco SEER entrena un modelo Mask-RCNN en el banco de pruebas COCO con RegNetY-64GF y RegNetY-128GF pre-entrenados como bloques de construcción. Tanto para la arquitectura como para las tareas posteriores, el enfoque de pre-entrenamiento auto-supervisado de SEER supera al entrenamiento supervisado en 1.5 a 2 puntos AP.
Comparación con el Preentrenamiento Débilmente Supervisado
La mayoría de las imágenes disponibles en Internet suelen tener una descripción meta o un texto alternativo, descripciones o geolocalizaciones que pueden proporcionar ventajas durante el preentrenamiento. Trabajos anteriores han indicado que predecir un conjunto curado o etiquetado de hashtags puede mejorar la calidad de las características visuales resultantes. Sin embargo, este enfoque necesita filtrar imágenes y funciona mejor solo cuando hay metadatos de texto presentes.
La siguiente figura compara el preentrenamiento de una arquitectura ResNetXt101-32dx8d entrenada en imágenes aleatorias con la misma arquitectura entrenada en imágenes etiquetadas con hashtags y metadatos, y muestra la precisión en el top 1 para ambas.

Se puede observar que aunque el marco SEER no utiliza metadatos durante el preentrenamiento, su precisión es comparable a los modelos que utilizan metadatos para el preentrenamiento.
Estudios de Ablación
Se realiza un estudio de ablación para analizar el impacto de un componente particular en el rendimiento general del modelo. Un estudio de ablación se realiza eliminando el componente por completo del modelo y comprendiendo cómo se desempeña el modelo. Esto brinda a los desarrolladores una descripción general del impacto de ese componente particular en el rendimiento del modelo.
Impacto de la Arquitectura del Modelo
La arquitectura del modelo tiene un impacto significativo en el rendimiento del modelo, especialmente cuando el modelo se escala o se modifican las especificaciones de los datos de preentrenamiento.
La siguiente figura analiza el impacto de cómo cambiar la arquitectura afecta la calidad de las características pre-entrenadas evaluando el conjunto de datos de ImageNet de manera lineal. Las características pre-entrenadas se pueden probar directamente en este caso porque la evaluación no favorece al modelo que devuelve una alta precisión cuando se entrena desde cero en el conjunto de datos de ImageNet.

Se puede observar que para las arquitecturas ResNeXts y ResNet, las características obtenidas de la capa penúltima funcionan mejor con la configuración actual. Por otro lado, la arquitectura RegNet supera a las otras arquitecturas.
En general, se puede concluir que aumentar la capacidad del modelo tiene un impacto positivo en la calidad de las características y hay una ganancia logarítmica en el rendimiento del modelo.
Escalar los datos de pre-entrenamiento
Hay dos razones principales por las que entrenar un modelo en un conjunto de datos más grande puede mejorar la calidad general de la característica visual que aprende el modelo: más imágenes únicas y más parámetros. Veamos brevemente cómo estas razones afectan el rendimiento del modelo.
Aumentar el número de imágenes únicas

La figura anterior compara dos arquitecturas diferentes, RegNet8 y RegNet16, que tienen la misma cantidad de parámetros, pero se entrenan en diferentes números de imágenes únicas. El marco SEER entrena los modelos para actualizaciones correspondientes a 1 época para mil millones de imágenes, o 32 épocas para 32 imágenes únicas, y con una tasa de aprendizaje de coseno de onda única.
Se puede observar que para que un modelo funcione bien, idealmente debería recibir imágenes únicas en mayor cantidad que las imágenes presentes en el conjunto de datos de ImageNet.
Más parámetros
La figura siguiente indica el rendimiento de un modelo a medida que se entrena con mil millones de imágenes utilizando la arquitectura RegNet-128GF. Se puede observar que el rendimiento del modelo aumenta de manera constante cuando se incrementa el número de parámetros.

Visión por computadora auto-supervisada en el mundo real
Hasta ahora, hemos discutido cómo funciona el aprendizaje auto-supervisado y el modelo SEER para la visión por computadora en teoría. Ahora, echemos un vistazo a cómo funciona la visión por computadora auto-supervisada en escenarios del mundo real y por qué SEER es el futuro de la visión por computadora auto-supervisada.
El modelo SEER rivaliza con el trabajo realizado en la industria del procesamiento del lenguaje natural, donde los modelos de vanguardia de alta gama utilizan billones de conjuntos de datos y parámetros junto con billones de palabras de texto durante el pre-entrenamiento del modelo. El rendimiento en tareas posteriores generalmente aumenta con un aumento en la cantidad de datos de entrada para entrenar el modelo, y lo mismo ocurre para las tareas de visión por computadora.
Pero usar técnicas de aprendizaje auto-supervisado para el procesamiento del lenguaje natural es diferente de usar aprendizaje auto-supervisado para la visión por computadora. Esto se debe a que al tratar con textos, los conceptos semánticos suelen descomponerse en palabras discretas, pero al tratar con imágenes, el modelo debe decidir qué píxel pertenece a qué concepto.
Además, diferentes imágenes tienen diferentes vistas y aunque varias imágenes pueden tener el mismo objeto, el concepto puede variar significativamente. Por ejemplo, consideremos un conjunto de datos con imágenes de un gato. Aunque el objeto principal, el gato, es común en todas las imágenes, el concepto puede variar significativamente, ya que el gato puede estar quieto en una imagen, mientras que puede estar jugando con una pelota en la siguiente, y así sucesivamente. Debido a que las imágenes a menudo tienen conceptos variables, es esencial que el modelo observe una cantidad significativa de imágenes para comprender las diferencias en torno al mismo concepto.
Escalar un modelo con éxito para que funcione eficientemente con datos de imágenes de alta dimensión y complejos requiere dos componentes:
- Una red neuronal convolucional o CNN lo suficientemente grande como para capturar y aprender los conceptos visuales de un conjunto de datos de imágenes muy grande.
- Un algoritmo que pueda aprender los patrones de una gran cantidad de imágenes sin etiquetas, anotaciones o metadatos.
El modelo SEER tiene como objetivo aplicar los componentes anteriores al campo de la visión por computadora. El modelo SEER tiene como objetivo aprovechar los avances realizados por SwAV, un marco de aprendizaje auto-supervisado que utiliza agrupación en línea para agrupar o emparejar imágenes con conceptos visuales paralelos y aprovechar estas similitudes para identificar mejor los patrones.

Con la arquitectura SwAV, el modelo SEER es capaz de hacer que el aprendizaje auto-supervisado en visión por computadora sea mucho más efectivo y reducir el tiempo de entrenamiento hasta en 6 veces.
Además, entrenar modelos a gran escala, en esta magnitud, más de 1 mil millones de imágenes requiere una arquitectura de modelo que sea eficiente no solo en términos de tiempo de ejecución y memoria, sino también en precisión. Aquí es donde entran en juego los modelos RegNet ya que estos modelos RegNets son modelos ConvNets que pueden escalar billones de parámetros y pueden optimizarse según las necesidades para cumplir con las limitaciones de memoria y las regulaciones de tiempo de ejecución.
Conclusión: Un Futuro Auto-Supervisado
El aprendizaje auto-supervisado ha sido un tema importante en la industria de IA y ML durante un tiempo porque permite que los modelos de IA aprendan información directamente de una gran cantidad de datos disponibles al azar en Internet en lugar de depender de conjuntos de datos cuidadosamente seleccionados y etiquetados que tienen el único propósito de entrenar modelos de IA.
El aprendizaje auto-supervisado es un concepto vital para el futuro de la IA y el ML porque tiene el potencial de permitir a los desarrolladores crear modelos de IA que se adapten bien a escenarios del mundo real y tengan múltiples casos de uso en lugar de tener un propósito específico, y SEER es un hito en la implementación del aprendizaje auto-supervisado en la industria de la visión por computadora.
El modelo SEER da el primer paso en la transformación de la industria de la visión por computadora y reduce nuestra dependencia de los conjuntos de datos etiquetados. El modelo SEER tiene como objetivo eliminar la necesidad de anotar el conjunto de datos, lo que permitirá a los desarrolladores trabajar con una gran cantidad y diversidad de datos. La implementación de SEER es especialmente útil para los desarrolladores que trabajan en modelos que tratan áreas que tienen imágenes o metadatos limitados, como la industria médica.
Además, eliminar las anotaciones humanas permitirá a los desarrolladores desarrollar e implementar el modelo más rápido, lo que les permitirá responder a situaciones en constante evolución de manera más rápida y precisa.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Parte 1 Crear paso a paso un entorno virtual para ejecutar tus tuberías de datos en sistemas basados en Windows
- EE.UU. busca malware chino que podría perturbar las operaciones militares estadounidenses
- Por qué Meta está regalando su modelo de IA extremadamente poderoso
- Mejorando el rendimiento de consulta de archivos CSV en ChatGPT
- Presentamos OpenLLM Biblioteca de código abierto para LLMs
- Construyendo un panel interactivo de ML en Panel
- Cómo construí una canalización de datos en cascada basada en AWS





