¿Se entienden Do Flamingo y DALL-E? Explorando la simbiosis entre los modelos de generación de subtítulos de imágenes y síntesis de texto a imagen
¿Se entienden Do Flamingo y DALL-E? Explorando simbiosis entre generación de subtítulos de imágenes y síntesis de texto a imagen


La investigación multimodal que mejora la comprensión de la computadora de texto e imágenes ha avanzado mucho recientemente. Descripciones verbales complejas de entornos del mundo real pueden traducirse en imágenes de alta fidelidad utilizando modelos de generación de texto a imagen como DALL-E y Stable Diffusion (SD). Por otro lado, modelos de generación de imagen a texto como Flamingo y BLIP demuestran la capacidad de comprender la semántica compleja que se encuentra en las imágenes y proporcionar descripciones coherentes. A pesar de la proximidad de las tareas de generación de texto a imagen y generación de subtítulos de imagen, a menudo se investigan de forma independiente, lo que significa que es necesario explorar la interacción entre estos modelos. El tema de si los modelos de generación de texto a imagen y los modelos de generación de imagen a texto pueden comprenderse mutuamente es intrigante.
Para abordar este problema, utilizan un modelo de generación de imagen a texto llamado BLIP para crear una descripción de texto para una imagen específica. Esta descripción de texto se introduce luego en un modelo de generación de texto a imagen llamado SD, que crea una nueva imagen. Sostienen que BLIP y SD pueden comunicarse si la imagen creada se parece a la imagen de origen. La capacidad de cada parte para comprender ideas subyacentes puede mejorar mediante su comprensión compartida, lo que lleva a una mejor creación de subtítulos y síntesis de imágenes. Este concepto se muestra en la Figura 1, donde el subtítulo superior conduce a una reconstrucción más precisa de la imagen original y representa mejor la imagen de entrada que el subtítulo inferior.
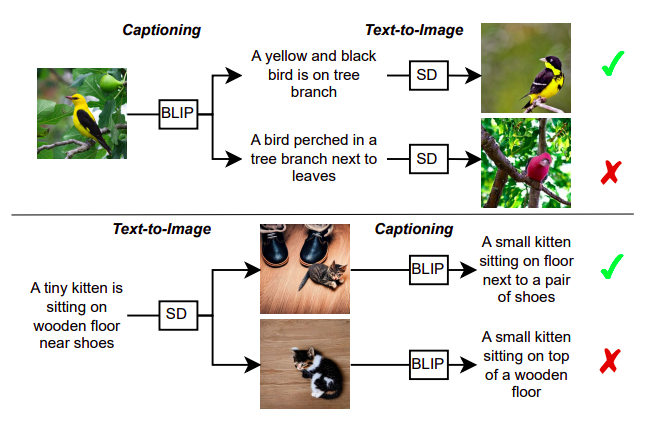
Investigadores de LMU Munich, Siemens AG y la Universidad de Oxford desarrollan una tarea de reconstrucción en la que DALL-E sintetiza una nueva imagen utilizando la descripción que Flamingo produce para una imagen determinada. Crean dos tareas de reconstrucción, texto-imagen-texto e imagen-texto-imagen, para probar esta suposición (ver Figura 1). Para la primera tarea de reconstrucción, calculan la distancia entre las características de la imagen extraídas con un codificador de imagen CLIP preentrenado para determinar cuán similares son la semántica de la imagen reconstruida y la imagen de entrada. Luego comparan la calidad del texto producido con los subtítulos anotados por humanos. Su investigación muestra que la calidad del texto creado afecta el rendimiento de la reconstrucción. Esto lleva a su primer descubrimiento: la descripción que permite al modelo generativo reconstruir la imagen original es la mejor descripción para una imagen.
- Investigadores de UCSC y TU Munich proponen RECAST un nuevo modelo basado en el aprendizaje profundo para predecir réplicas
- Preguntas, encogimientos de hombros y lo que viene después Un cuarto de siglo de cambio
- Una guía para la recolección de datos del mundo real para el Aprendizaje Automático
De manera similar, crean la tarea opuesta, donde SD crea una imagen a partir de una entrada de texto, y luego BLIP crea un texto a partir de la imagen creada. Descubren que la imagen que produjo el texto original es la mejor ilustración para el texto. Plantean la hipótesis de que la información de la imagen de entrada se retiene de manera precisa en la descripción textual durante el proceso de reconstrucción. Esta descripción significativa resulta en una recuperación fiel a la modalidad de imagen. Su investigación sugiere un marco único para el ajuste fino que facilita la comunicación entre modelos de generación de texto a imagen y generación de imagen a texto.
Más específicamente, en su paradigma, un modelo generativo recibe señales de entrenamiento de una pérdida de reconstrucción y de información de etiquetas humanas. Un modelo primero crea una representación de la entrada para una imagen o texto específico en la otra modalidad, y el modelo diferente traduce esta representación de regreso a la modalidad de entrada. El componente de reconstrucción crea una pérdida de regularización para guiar el ajuste fino del modelo inicial. De esta manera, obtienen supervisión propia y humana, aumentando la probabilidad de que la generación resulte en una reconstrucción más precisa. El modelo de subtítulos de imagen, por ejemplo, debe favorecer los subtítulos que no solo correspondan a las combinaciones de imagen y texto etiquetadas, sino también aquellos que puedan resultar en reconstrucciones confiables.
La comunicación entre agentes está íntimamente ligada a su trabajo. El principal modo de intercambio de información entre los agentes es el lenguaje. Pero, ¿cómo pueden estar seguros de que el primer y segundo agente tienen la misma definición de un gato o un perro? En este estudio, le piden al primer agente que examine una imagen y genere una oración que la describa. Después de obtener el texto, el segundo agente simula una imagen basada en él. La última fase es un proceso de encarnación. Según su hipótesis, la comunicación es efectiva si la simulación de la segunda agente de la imagen de entrada está cerca de la imagen de entrada recibida por el primer agente. En esencia, evalúan la utilidad del lenguaje, que sirve como el principal medio de comunicación de los humanos. En particular, utilizan modelos de generación de subtítulos de imagen preentrenados a gran escala y modelos de generación de imágenes en su investigación. Varios estudios han demostrado los beneficios de su marco propuesto para diversos modelos generativos tanto en situaciones sin entrenamiento como en situaciones de ajuste fino. En particular, su enfoque mejoró considerablemente la creación de subtítulos e imágenes en el paradigma sin entrenamiento, mientras que para el ajuste fino, obtuvieron mejores resultados para ambos modelos generativos.
Lo siguiente es un resumen de sus principales contribuciones:
• Framework: Hasta donde se sabe, son los primeros en investigar cómo los modelos generativos de imagen a texto y de texto a imagen pueden comunicarse a través de representaciones de texto e imagen fácilmente comprensibles. En contraste, trabajos similares integran implícitamente la creación de texto e imagen a través de un espacio de incrustación.
• Hallazgos: Descubrieron que evaluar la reconstrucción de la imagen creada por un modelo de texto a imagen puede ayudar a determinar la calidad de una leyenda escrita. La leyenda que permite la reconstrucción más precisa de la imagen original es la que se debe usar para esa imagen. De manera similar, la mejor imagen de leyenda es aquella que permite la reconstrucción más precisa del texto original.
• Mejoras: A raíz de su investigación, propusieron un marco integral para mejorar tanto los modelos de texto a imagen como los de imagen a texto. Se utilizará una pérdida de reconstrucción calculada por un modelo de texto a imagen como regularización para ajustar el modelo de imagen a texto, y una pérdida de reconstrucción calculada por un modelo de imagen a texto se utilizará para ajustar el modelo de texto a imagen. Investigaron y confirmaron la viabilidad de su enfoque.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Dos formas de descargar y acceder a Llama 2 localmente
- Creando habilidades personalizadas para chatbots con plugins
- Construyendo un Motor de Recomendación de Productos con Apache Cassandra y Apache Pulsar
- CassIO La mejor biblioteca para IA generativa inspirada por OpenAI
- Optimiza el costo de implementación de los modelos base de Amazon SageMaker JumpStart con los puntos finales asincrónicos de Amazon SageMaker
- Data Morph Avanzando más allá de la docena de Datasaurus
- Aprendizaje de representación en grafos y redes