Grandes Modelos de Lenguaje SBERT
SBERT Grand Language Models
Aprenda cómo las redes BERT siamesas transforman con precisión las oraciones en incrustaciones
Introducción
No es ningún secreto que los transformers han logrado un progreso evolutivo en el procesamiento del lenguaje natural. Basado en los transformers, muchos otros modelos de aprendizaje automático han evolucionado. Uno de ellos es BERT, que consiste principalmente en varios codificadores de transformers apilados. Aparte de ser utilizado para diferentes problemas como el análisis de sentimientos o la respuesta a preguntas, BERT se ha vuelto cada vez más popular para construir incrustaciones de palabras, es decir, vectores de números que representan los significados semánticos de las palabras.
La representación de palabras en forma de incrustaciones ha dado una gran ventaja, ya que los algoritmos de aprendizaje automático no pueden trabajar con texto sin procesar, pero pueden operar con vectores de vectores. Esto permite comparar diferentes palabras por su similitud utilizando una métrica estándar como la distancia euclidiana o la distancia coseno.
El problema es que, en la práctica, a menudo necesitamos construir incrustaciones no solo para palabras individuales, sino para frases enteras. Sin embargo, la versión básica de BERT solo construye incrustaciones a nivel de palabra. Debido a esto, se desarrollaron posteriormente enfoques similares a BERT para resolver este problema, que se discutirán en este artículo. Al discutirlos de manera progresiva, llegaremos al modelo de última generación llamado SBERT.
- LLMs y Análisis de Datos Cómo la IA está dando sentido a los grandes datos para obtener información empresarial
- Ingeniería de Aprendizaje Automático en el Mundo Real
- Conoce a PhysObjects Un conjunto de datos centrado en objetos con 36.9K anotaciones físicas obtenidas de la colaboración de la multitud y 417K anotaciones físicas automáticas de objetos comunes del hogar.
Para comprender cómo funciona SBERT en detalle, se recomienda que ya esté familiarizado con BERT. Si no es así, la parte anterior de esta serie de artículos lo explica en detalle.
Modelos de lenguaje grandes: BERT
Comprenda cómo BERT construye incrustaciones de última generación
towardsdatascience.com
BERT
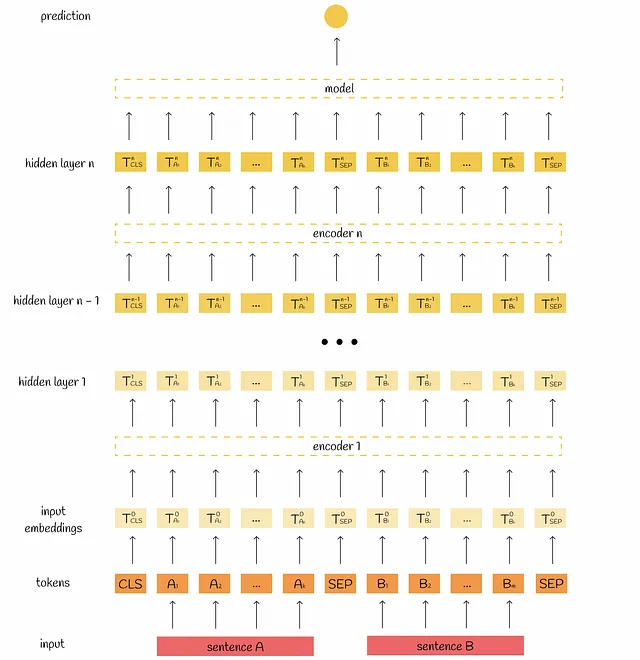
En primer lugar, recordemos cómo BERT procesa la información. Como entrada, toma un token [CLS] y dos oraciones separadas por un token especial [SEP]. Dependiendo de la configuración del modelo, esta información se procesa 12 o 24 veces mediante bloques de atención multi-cabeza. La salida se agrega y se pasa a un modelo de regresión simple para obtener la etiqueta final.
Para obtener más información sobre el funcionamiento interno de BERT, puede consultar la parte anterior de esta serie de artículos:
Arquitectura de codificador cruzado
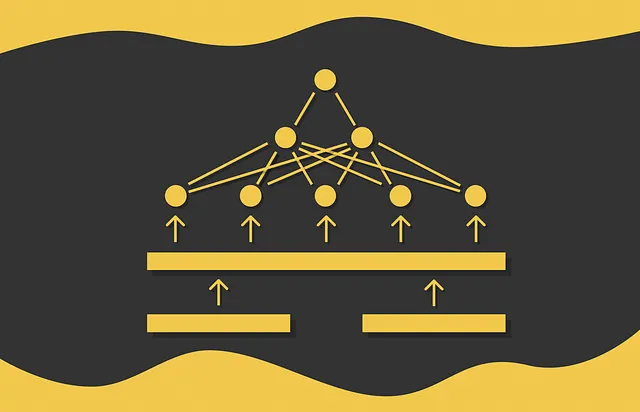
Es posible utilizar BERT para calcular la similitud entre un par de documentos. Considere el objetivo de encontrar el par de frases más similares en una gran colección. Para resolver este problema, cada par posible se introduce en el modelo BERT. Esto conduce a una complejidad cuadrática durante la inferencia. Por ejemplo, tratar con n = 10 000 frases requiere n * (n — 1) / 2 = 49 995 000 cálculos de inferencia BERT, lo cual no es realmente escalable.
Otros enfoques
Al analizar la ineficiencia de la arquitectura de codificador cruzado, parece lógico precalcular las incrustaciones de forma independiente para cada oración. Después de eso, podemos calcular directamente la métrica de distancia elegida en todos los pares de documentos, lo cual es mucho más rápido que alimentar una cantidad cuadrática de pares de oraciones a BERT.
Desafortunadamente, este enfoque no es posible con BERT: el problema principal de BERT es que cada vez se pasan y procesan simultáneamente dos oraciones, lo que dificulta obtener incrustaciones que representen de manera independiente solo una oración.
Los investigadores intentaron solucionar este problema utilizando la salida de la incrustación del token [CLS], con la esperanza de que contuviera suficiente información para representar una oración. Sin embargo, el [CLS] resultó no ser útil en absoluto para esta tarea, simplemente porque inicialmente se preentrenó en BERT para la predicción de la siguiente oración.
Otro enfoque fue pasar una sola oración a BERT y luego calcular el promedio de las incrustaciones de los tokens de salida. Sin embargo, los resultados obtenidos fueron incluso peores que simplemente promediar las incrustaciones GLoVe.
La obtención de incrustaciones de oraciones independientes es uno de los principales problemas de BERT. Para aliviar este aspecto, se desarrolló SBERT.
SBERT
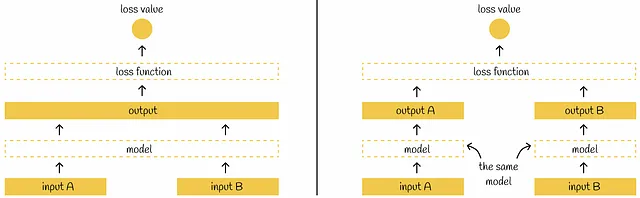
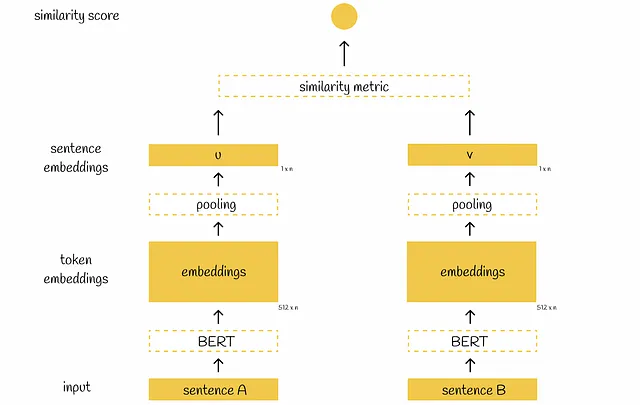
SBERT introduce el concepto de la red Siamesa, lo que significa que cada vez que se pasan dos oraciones de forma independiente a través del mismo modelo BERT. Antes de discutir la arquitectura de SBERT, hablemos de una nota sutil sobre las redes Siamesas:
La mayoría de las veces en artículos científicos, se representa la arquitectura de una red Siamesa con varios modelos que reciben tantas entradas. En realidad, se puede pensar en un solo modelo con la misma configuración y pesos compartidos en varias entradas paralelas. Cada vez que se actualizan los pesos del modelo para una entrada única, también se actualizan de manera equitativa para las demás entradas.
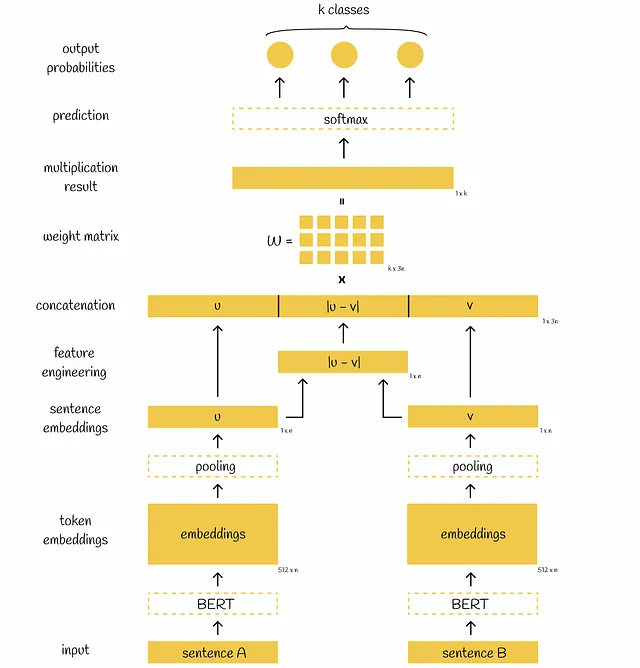
Volviendo a SBERT, después de pasar una oración por BERT, se aplica una capa de agrupación a las incrustaciones de BERT para obtener su representación de menor dimensionalidad: los vectores iniciales de 512 dimensiones 768 se transforman en un solo vector de 768 dimensiones. Para la capa de agrupación, los autores de SBERT proponen elegir una capa de agrupación promedio como la predeterminada, aunque también mencionan que es posible usar la estrategia de agrupación máxima o simplemente tomar la salida del token [CLS].
Cuando ambas oraciones se pasan por las capas de agrupación, tenemos dos vectores de 768 dimensiones u y v. Utilizando estos dos vectores, los autores proponen tres enfoques para optimizar diferentes objetivos que se discutirán a continuación.
Función objetivo de clasificación
El objetivo de este problema es clasificar correctamente un par de oraciones en una de varias clases.
Después de generar las incrustaciones u y v, los investigadores encontraron útil generar otro vector derivado de estos dos como la diferencia absoluta elemento a elemento |u-v|. También probaron otras técnicas de ingeniería de características, pero esta mostró los mejores resultados.
Finalmente, se concatenan tres vectores u, v y |u-v|, se multiplican por una matriz de pesos entrenable W y el resultado de la multiplicación se introduce en el clasificador softmax, que produce probabilidades normalizadas de oraciones correspondientes a diferentes clases. Se utiliza la función de pérdida de entropía cruzada para actualizar los pesos del modelo.
Uno de los problemas más populares que se solían resolver con este objetivo es el NLI (Inferencia de Lenguaje Natural), donde, para un par dado de oraciones A y B que definen una hipótesis y una premisa, es necesario predecir si la hipótesis es verdadera (entailment), falsa (contradicción) o indeterminada (neutral) dada la premisa. Para este problema, el proceso de inferencia es el mismo que para el entrenamiento.
Según se indica en el artículo, el modelo SBERT se entrena originalmente en dos conjuntos de datos, SNLI y MultiNLI, que contienen un millón de pares de oraciones con etiquetas correspondientes: entailment, contradiction o neutral. Después de eso, los investigadores mencionan detalles sobre los parámetros de ajuste de SBERT:
“Ajustamos finamente SBERT con una función objetivo de clasificador de softmax de 3 vías durante una época. Utilizamos un tamaño de lote de 16, el optimizador Adam con una tasa de aprendizaje de 2e−5 y un aumento lineal de la tasa de aprendizaje sobre el 10% de los datos de entrenamiento. Nuestra estrategia de agrupación predeterminada es la promedio.”
Función objetivo de regresión
En esta formulación, después de obtener los vectores u y v, la puntuación de similitud entre ellos se calcula directamente mediante una métrica de similitud elegida. La puntuación de similitud predicha se compara con el valor real y el modelo se actualiza utilizando la función de pérdida MSE. Por defecto, los autores eligen la similitud del coseno como la métrica de similitud.
En la inferencia, esta arquitectura se puede usar de dos formas:
- Dado un par de oraciones, es posible calcular la puntuación de similitud. El flujo de trabajo de inferencia es absolutamente el mismo que para el entrenamiento.
- Para una oración dada, es posible extraer su embedding de oración (justo después de aplicar la capa de pooling) para algún uso posterior. Esto es particularmente útil cuando se nos da una gran colección de oraciones con el objetivo de calcular puntuaciones de similitud entre ellas. Ejecutando cada oración a través de BERT solo una vez, extraemos todos los embeddings de oraciones necesarios. Después de eso, podemos calcular directamente la métrica de similitud elegida entre todos los vectores (sin duda, aún requiere un número cuadrático de comparaciones, pero al mismo tiempo evitamos cálculos de inferencia cuadráticos con BERT como antes).
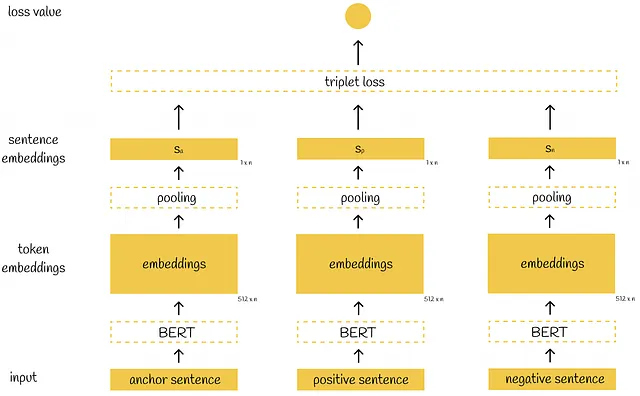
Función objetivo de tripletas
La función objetivo de tripletas introduce una pérdida de tripletas que se calcula en tres oraciones generalmente llamadas ancla, positiva y negativa. Se asume que las oraciones de ancla y positivas están muy cerca entre sí, mientras que el ancla y la negativa son muy diferentes. Durante el proceso de entrenamiento, el modelo evalúa qué tan cerca está el par (ancla, positiva) en comparación con el par (ancla, negativa). Matemáticamente, se minimiza la siguiente función de pérdida:
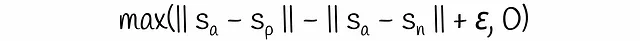
El margen ε asegura que una oración positiva esté más cerca del ancla al menos por ε que la oración negativa al ancla. De lo contrario, la pérdida se vuelve mayor que 0. Por defecto, en esta fórmula, los autores eligen la distancia euclidiana como la norma del vector y el parámetro ε se establece en 1.
La arquitectura de tripletas de SBERT difiere de las dos anteriores en que el modelo ahora acepta en paralelo tres oraciones de entrada (en lugar de dos).
Código
SentenceTransformers es una biblioteca de Python de última generación para construir embeddings de oraciones. Contiene varios modelos preentrenados para diferentes tareas. Construir embeddings con SentenceTransformers es simple y se muestra un ejemplo en el fragmento de código a continuación.
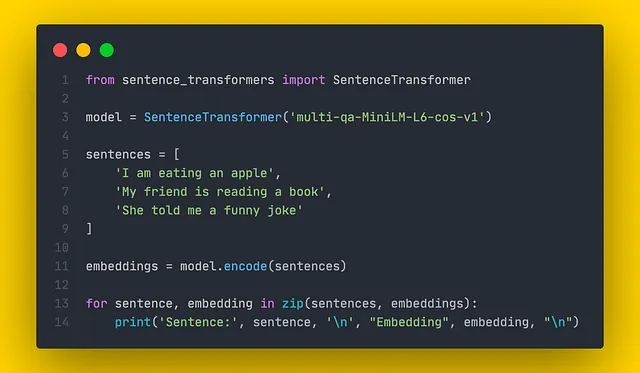
Los embeddings construidos luego se pueden usar para comparación de similitud. Cada modelo se entrena para una tarea específica, por lo que siempre es importante elegir una métrica de similitud adecuada para la comparación consultando la documentación.
Conclusión
Hemos recorrido uno de los modelos avanzados de PLN para obtener embeddings de oraciones. Al reducir un número cuadrático de ejecuciones de inferencia de BERT a lineal, SBERT logra un crecimiento masivo en velocidad al tiempo que mantiene una alta precisión.
Para comprender finalmente cuán significativa es esta diferencia, basta con referirse al ejemplo descrito en el artículo donde los investigadores intentaron encontrar el par más similar entre n = 10000 oraciones. ¡En una GPU V100 moderna, este procedimiento tomó aproximadamente 65 horas con BERT y solo 5 segundos con SBERT! Este ejemplo demuestra que SBERT es un gran avance en NLP.
Recursos
- Sentence-BERT: Sentence Embeddings utilizando redes Siamese BERT
- Documentación de SentenceTransformers | SBERT.net
- Inferencia de Lenguaje Natural | Papers with code
Todas las imágenes, a menos que se indique lo contrario, son del autor.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo construir una estrategia de Ciencia de Datos para cualquier tamaño de equipo
- Dominio de Amazon SageMaker en modo solo VPC para admitir SageMaker Studio con configuración de ciclo de vida de apagado automático y SageMaker Canvas con Terraform
- Matemáticos encuentran 12,000 soluciones para el problema de los tres cuerpos
- ¿Qué tienen en común las neuronas, las luciérnagas y bailar el Nutbush?
- Microsoft protegerá a los clientes de Copilot que hayan pagado de cualquier disputa por derechos de autor de IA que se inicie
- Generative AI Desatado Estrategias de implementación de MLOps y LLM para Ingenieros de Software
- Construye una aplicación de búsqueda de texto e imágenes con NodeJS y IA





