Presentando RWKV – Una RNN con las ventajas de un transformador
RWKV es una RNN que combina las ventajas de un transformador.
ChatGPT y las aplicaciones impulsadas por chatbot han captado una atención significativa en el campo del Procesamiento del Lenguaje Natural (NLP, por sus siglas en inglés). La comunidad busca constantemente modelos sólidos, confiables y de código abierto para sus aplicaciones y casos de uso. El surgimiento de estos modelos poderosos se debe a la democratización y la adopción generalizada de modelos basados en transformadores, introducidos por primera vez por Vaswani et al. en 2017. Estos modelos superaron significativamente a los modelos anteriores de NLP basados en Redes Neuronales Recurrentes (RNN), que se consideraron obsoletos después de ese artículo. A través de esta publicación de blog, presentaremos la integración de una nueva arquitectura, RWKV, que combina las ventajas tanto de las RNN como de los transformadores, y que se ha integrado recientemente en la biblioteca de transformadores de Hugging Face.
Resumen del proyecto RWKV
El proyecto RWKV fue iniciado y es liderado por Bo Peng, quien contribuye activamente y mantiene el proyecto. La comunidad, organizada en el canal oficial de Discord, mejora constantemente los artefactos del proyecto en diversos temas como rendimiento (RWKV.cpp, cuantización, etc.), escalabilidad (procesamiento y extracción de conjuntos de datos) e investigación (ajuste fino de chat, ajuste fino multimodal, etc.). Las GPU para entrenar los modelos RWKV son donadas por Stability AI.
Puedes participar uniéndote al canal oficial de Discord y aprender más sobre las ideas generales detrás de RWKV en estos dos artículos de blog: https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html
Arquitectura de transformadores vs RNN
La arquitectura de RNN es una de las primeras arquitecturas de red neuronal ampliamente utilizadas para procesar una secuencia de datos, a diferencia de las arquitecturas clásicas que toman una entrada de tamaño fijo. Toma como entrada el “token” actual (es decir, el punto de datos actual de la secuencia de datos), el “estado” anterior y calcula el siguiente “token” predicho y el siguiente “estado” predicho. Luego se utiliza el nuevo estado para calcular la predicción del siguiente “token” y así sucesivamente. Una RNN también se puede utilizar en diferentes “modos”, lo que permite la posibilidad de aplicar RNN en diferentes escenarios, como se indica en el artículo de blog de Andrej Karpathy, tales como uno a uno (clasificación de imágenes), uno a muchos (subtitulado de imágenes), muchos a uno (clasificación de secuencias), muchos a muchos (generación de secuencias), etc.
- Más pequeño es mejor Q8-Chat, una experiencia eficiente de IA generativa en Xeon
- Deduplicación a gran escala detrás de BigCode
- 🐶Safetensors auditados como realmente seguros y convirtiéndose en la opción predeterminada
Debido a que las RNN utilizan los mismos pesos para calcular las predicciones en cada paso, tienen dificultades para memorizar información en secuencias de largo alcance debido al problema del gradiente que se desvanece. Se han realizado esfuerzos para abordar esta limitación mediante la introducción de nuevas arquitecturas como LSTMs o GRUs. Sin embargo, la arquitectura de transformador demostró ser la más efectiva hasta ahora para resolver este problema.
En la arquitectura de transformador, los tokens de entrada se procesan simultáneamente en el módulo de autoatención. Los tokens se proyectan linealmente en diferentes espacios utilizando los pesos de consulta, clave y valor. Las matrices resultantes se utilizan directamente para calcular los puntajes de atención (a través de softmax, como se muestra a continuación), luego se multiplican por los estados ocultos de valor para obtener los estados ocultos finales. Este diseño permite que la arquitectura mitigue de manera efectiva el problema de secuencias de largo alcance y también realice inferencias y entrenamientos más rápidos en comparación con los modelos RNN.
Durante el entrenamiento, la arquitectura de transformador tiene varias ventajas sobre las RNN tradicionales y las CNN. Una de las ventajas más significativas es su capacidad para aprender representaciones contextuales. A diferencia de las RNN y las CNN, que procesan secuencias de entrada palabra por palabra, la arquitectura de transformador procesa secuencias de entrada como un todo. Esto le permite capturar dependencias de largo alcance entre palabras en la secuencia, lo cual es especialmente útil para tareas como la traducción de idiomas y la respuesta a preguntas.
Durante la inferencia, las RNN tienen algunas ventajas en cuanto a velocidad y eficiencia de memoria. Estas ventajas incluyen simplicidad, debido a que solo se necesitan operaciones de matriz-vector, y eficiencia de memoria, ya que los requisitos de memoria no aumentan durante la inferencia. Además, la velocidad de cálculo permanece igual con la longitud de la ventana de contexto debido a cómo los cálculos solo actúan sobre el token actual y el estado.
La arquitectura RWKV
RWKV está inspirada en el Attention Free Transformer de Apple. La arquitectura se ha simplificado y optimizado cuidadosamente para que pueda transformarse en una RNN. Además, se han agregado una serie de trucos como TokenShift y SmallInitEmb (la lista de trucos se encuentra en el archivo README del repositorio oficial de GitHub) para mejorar su rendimiento y que sea comparable a GPT. Sin estos trucos, el modelo no sería tan eficiente. Para el entrenamiento, hay una infraestructura para escalar el entrenamiento hasta 14B de parámetros en la actualidad, y se han solucionado de forma iterativa algunos problemas en RWKV-4 (última versión hasta la fecha), como la inestabilidad numérica.
RWKV como una combinación de RNNs y transformers
¿Cómo combinar lo mejor de los transformers y las RNNs? La principal desventaja de los modelos basados en transformers es que puede resultar difícil ejecutar un modelo con una ventana de contexto que sea mayor que un cierto valor, ya que los puntajes de atención se calculan simultáneamente para toda la secuencia.
Las RNNs admiten de forma nativa longitudes de contexto muy largas, limitadas solo por la longitud de contexto vista durante el entrenamiento, pero esto se puede extender a millones de tokens con una codificación cuidadosa. Actualmente, existen modelos RWKV entrenados en una longitud de contexto de 8192 (ctx8192) y son tan rápidos como los modelos ctx1024 y requieren la misma cantidad de RAM.
Las principales desventajas de los modelos RNN tradicionales y cómo RWKV es diferente:
- Los modelos RNN tradicionales no pueden utilizar contextos muy largos (LSTM solo puede manejar ~100 tokens cuando se utiliza como LM). Sin embargo, RWKV puede utilizar miles de tokens y más, como se muestra a continuación:
- Los modelos RNN tradicionales no se pueden paralelizar durante el entrenamiento. RWKV es similar a un “GPT linealizado” y se entrena más rápido que GPT.
Al combinar ambas ventajas en una sola arquitectura, se espera que RWKV pueda crecer y convertirse en más que la suma de sus partes.
Formulación de atención en RWKV
La arquitectura del modelo es muy similar a la de los modelos basados en transformers clásicos (es decir, una capa de incrustación, múltiples capas idénticas, normalización de capas y una cabeza de modelado del lenguaje causal para predecir el siguiente token). La única diferencia está en la capa de atención, que es completamente diferente de los modelos tradicionales basados en transformers.
Para obtener una comprensión más completa de la capa de atención, recomendamos profundizar en la explicación detallada proporcionada en una publicación de blog de Johan Sokrates Wind.
Puntos de control existentes
Modelos de lenguaje puro: modelos RWKV-4
Los modelos RWKV adoptados varían desde ~170M de parámetros hasta 14B de parámetros. Según la publicación de blog de descripción general de RWKV, estos modelos se han entrenado en el conjunto de datos Pile y se han evaluado frente a otros modelos SoTA en diferentes pruebas, y parecen funcionar bastante bien, con resultados muy comparables.
Versión de instrucción afinada/chat: modelo RWKV-4 Raven
Bo también ha entrenado una versión “chat” de la arquitectura RWKV, el modelo RWKV-4 Raven. Es un modelo RWKV-4 Pile (modelo RWKV preentrenado en el conjunto de datos Pile) afinado en ALPACA, CodeAlpaca, Guanaco, GPT4All, ShareGPT y más. El modelo está disponible en múltiples versiones, con modelos entrenados en diferentes idiomas (solo inglés, inglés + chino + japonés, inglés + japonés, etc.) y diferentes tamaños (1.5B de parámetros, 7B de parámetros, 14B de parámetros).
Todos los modelos convertidos a HF están disponibles en Hugging Face Hub, en la organización RWKV.
Integración con 🤗 Transformers
La arquitectura se ha agregado a la biblioteca transformers gracias a esta solicitud de extracción. En el momento de escribir esto, puedes usarlo instalando transformers desde la fuente, o usando la rama main de la biblioteca. La arquitectura está estrechamente integrada con la biblioteca y puedes usarla como lo harías con cualquier otra arquitectura.
Veamos algunos ejemplos a continuación.
Ejemplo de generación de texto
Para generar texto a partir de una consulta de entrada, puedes usar pipeline para generar texto:
from transformers import pipeline
model_id = "RWKV/rwkv-4-169m-pile"
prompt = "\nEn un descubrimiento impactante, los científicos descubrieron una manada de dragones viviendo en un valle remoto, previamente inexplorado, en el Tíbet. Aún más sorprendente para los investigadores fue el hecho de que los dragones hablaban chino perfecto."
pipe = pipeline("text-generation", model=model_id)
print(pipe(prompt, max_new_tokens=20))
>>> [{'generated_text': '\nEn un descubrimiento impactante, los científicos descubrieron una manada de dragones viviendo en un valle remoto, previamente inexplorado, en el Tíbet. Aún más sorprendente para los investigadores fue el hecho de que los dragones hablaban chino perfecto.\n\nLos investigadores descubrieron que los dragones eran capaces de comunicarse entre sí y que eran'}]O puedes ejecutar y empezar desde el fragmento de código a continuación:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("RWKV/rwkv-4-169m-pile")
tokenizer = AutoTokenizer.from_pretrained("RWKV/rwkv-4-169m-pile")
prompt = "\nEn un hallazgo impactante, los científicos descubrieron una manada de dragones viviendo en un valle remoto, previamente inexplorado, en el Tíbet. Aún más sorprendente para los investigadores fue el hecho de que los dragones hablaban un chino perfecto."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(inputs["input_ids"], max_new_tokens=20)
print(tokenizer.decode(output[0].tolist()))
>>> En un hallazgo impactante, los científicos descubrieron una manada de dragones viviendo en un valle remoto, previamente inexplorado, en el Tíbet. Aún más sorprendente para los investigadores fue el hecho de que los dragones hablaban un chino perfecto.\n\nLos investigadores descubrieron que los dragones eran capaces de comunicarse entre sí y que eranUsar los modelos de raven (modelos de chat)
Puedes provocar al modelo de chat al estilo alpaca, aquí tienes un ejemplo:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "RWKV/rwkv-raven-1b5"
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
tokenizer = AutoTokenizer.from_pretrained(model_id)
question = "Cuéntame sobre los cuervos"
prompt = f"### Instrucción: {question}\n### Respuesta:"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0].tolist(), skip_special_tokens=True))
>>> ### Instrucción: Cuéntame sobre los cuervos
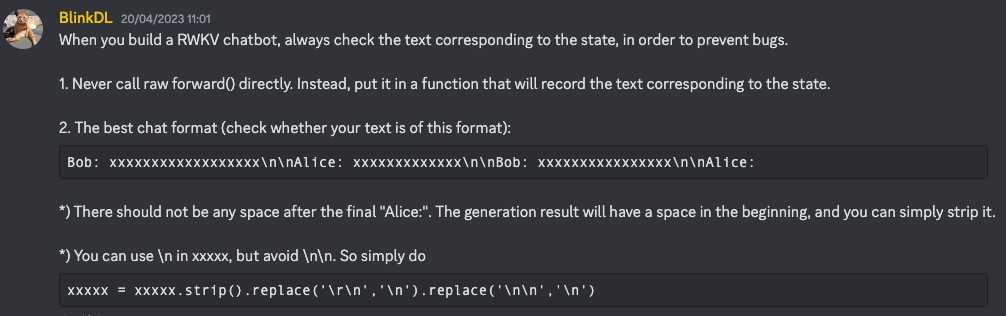
### Respuesta: LOS CUERVOS son un tipo de ave que es nativa de Oriente Medio y el norte de África. Son conocidos por su inteligencia, adaptabilidad y su capacidad para vivir en una variedad de entornos. LOS CUERVOS son conocidos por su inteligencia, adaptabilidad y su capacidad para vivir en una variedad de entornos. Son conocidos por su inteligencia, adaptabilidad y su capacidad para vivir en una variedad de entornos.Según Bo, las técnicas de instrucción mejoradas se detallan en este mensaje de Discord (asegúrate de unirte al canal antes de hacer clic)
|  |
|
Conversión de pesos
Cualquier usuario puede convertir fácilmente los pesos originales de RWKV al formato HF simplemente ejecutando el script de conversión proporcionado en la biblioteca transformers. Primero, envía los pesos “raw” al Hugging Face Hub (denotemos ese repositorio como RAW_HUB_REPO, y el archivo raw como RAW_FILE), luego ejecuta el script de conversión:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIRSi deseas enviar el modelo convertido al Hub (digamos, bajo dummy_user/converted-rwkv), primero no olvides iniciar sesión con huggingface-cli login antes de enviar el modelo, luego ejecuta:
python convert_rwkv_checkpoint_to_hf.py --repo_id RAW_HUB_REPO --checkpoint_file RAW_FILE --output_dir OUTPUT_DIR --push_to_hub --model_name dummy_user/converted-rwkvTrabajo futuro
RWKV multilingüe
Bo está trabajando actualmente en un corpus multilingüe para entrenar modelos RWKV. Recientemente se ha lanzado un nuevo tokenizador multilingüe.
Proyectos orientados a la comunidad e investigación
La comunidad de RWKV es muy activa y está trabajando en varias direcciones de seguimiento, una lista de proyectos interesantes se puede encontrar en un canal dedicado en Discord (asegúrate de unirte al canal antes de hacer clic en el enlace). También hay un canal dedicado a la investigación en torno a esta arquitectura, ¡no dudes en unirte y contribuir!
Compresión y aceleración del modelo
Debido a que solo se necesitan operaciones de matriz-vector, RWKV es un candidato ideal para hardware informático no estándar y experimental, como procesadores/aceleradores fotónicos.
Por lo tanto, la arquitectura también puede beneficiarse naturalmente de técnicas clásicas de aceleración y compresión (como ONNX, cuantificación de 4 bits/8 bits, etc.), y esperamos que esto se democratice para desarrolladores y profesionales junto con la integración de los transformadores en la arquitectura.
RWKV también puede beneficiarse de las técnicas de aceleración propuestas por la biblioteca optimum en un futuro cercano. Algunas de estas técnicas se destacan en el repositorio rwkv.cpp o en el repositorio rwkv-cpp-cuda.
Agradecimientos
El equipo de Hugging Face desea agradecer a Bo y a la comunidad de RWKV por su tiempo y por responder nuestras preguntas sobre la arquitectura. También queremos agradecerles por su ayuda y apoyo, y esperamos ver una mayor adopción de los modelos RWKV en el ecosistema de HF. También queremos reconocer el trabajo de Johan Wind por su publicación en el blog sobre RWKV, que nos ayudó mucho a comprender la arquitectura y su potencial. Y finalmente, nos gustaría resaltar y agradecer el trabajo de ArEnSc por comenzar con la PR inicial de transformers. ¡También un gran reconocimiento a Merve Noyan, Maria Khalusova y Pedro Cuenca por revisar amablemente esta publicación en el blog y hacerla mucho mejor!
Cita
Si utilizas RWKV para tu trabajo, por favor utiliza la siguiente cff cita.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Hugging Face y IBM se unen en watsonx.ai, el estudio empresarial de próxima generación para desarrolladores de IA.
- Optimizando la Difusión Estable para CPUs de Intel con NNCF y 🤗 Optimum
- Anunciando la Jam de Juegos de Inteligencia Artificial de Código Abierto 🎮
- Reconocimiento de Voz de IA en Unity
- DuckDB analiza más de 50,000 conjuntos de datos almacenados en el Hugging Face Hub
- El Hub de Hugging Face para Galerías, Bibliotecas, Archivos y Museos
- ¿Qué está pasando con el Open LLM Leaderboard?






