Red Neuronal Recurrente con Puertas desde Cero en Julia
RNN con Puertas desde Cero en Julia
Vamos a explorar Julia para construir una RNN con celdas GRU desde cero
1. Introducción
Hace algún tiempo, comencé a aprender Julia para programación científica y ciencia de datos. La adopción continua de Julia resulta de combinar el poder estadístico de R, la sintaxis expresiva y clara de Python, y el alto rendimiento de los lenguajes compilados como C++.
La mejor manera de aprender algo es practicarlo constantemente. Esta “simple” receta es evidentemente efectiva en el campo de la tecnología. Solo a través de la codificación y la práctica un programador puede comprender y explorar la sintaxis, los tipos de datos, las funciones, los métodos, las variables, la gestión de memoria, el flujo de control, el manejo de errores y las bibliotecas, incluidas las mejores prácticas y convenciones.
Estrechamente ligado a esta creencia, comencé un proyecto personal para construir una Red Neuronal Recurrente (RNN) que utiliza la arquitectura de las Unidades Recurrentes con Puertas (GRUs) de última generación. Para agregar un poco más de sabor y aumentar mi comprensión de Julia, construí esta RNN desde cero. La idea era utilizar la RNN con GRUs para predecir series temporales relacionadas con el mercado de valores.
Algoritmo de Agrupamiento Basado en Densidad desde Cero en Julia
Programemos en Julia como una alternativa a Python en ciencia de datos
pub.towardsai.net
- 8 Razones por las que no renuncié a mi sueño de ser un científico de datos y por qué tú tampoco deberías hacerlo
- CarperAI presenta OpenELM una biblioteca de código abierto diseñada para permitir la búsqueda evolutiva con modelos de lenguaje tanto en código como en lenguaje natural.
- Productividad impulsada por IA la IA generativa abre una nueva era de eficiencia en todas las industrias
El esquema de este post será el siguiente:
- Comprender la arquitectura de las GRUs
- Configurar el proyecto
- Implementar la red GRU
- Resultados e ideas
- Conclusión
Comienza, bifurca, comparte y lo más importante, experimenta con el repositorio de GitHub creado para este proyecto 👇.
GitHub – jodhernandezbe/post-gru-julia: Este es un repositorio que contiene códigos en Julia para crear desde…
Este es un repositorio que contiene códigos en Julia para crear desde cero una Red Neuronal Recurrente con Puertas para acciones…
github.com
2. Comprendiendo la arquitectura GRU
La idea de esta sección no es dar una descripción exhaustiva de la arquitectura GRU, sino presentar los elementos necesarios para codificar una RNN con celdas GRU desde cero. Para los recién llegados, puedo decir que las RNN pertenecen a una familia de modelos que permiten manejar datos secuenciales como texto, precios de acciones y datos de sensores.
Descubriendo el Modelo de Markov Oculto: Conceptos, Matemáticas y Aplicaciones en la Vida Real
Vamos a explorar la Cadena de Markov Oculta
VoAGI.com
La idea detrás de las GRUs es superar el problema del gradiente desvaneciente de las RNN tradicionales. El artículo escrito por Chi-Feng Wang puede darte una explicación sencilla de este problema 👇. En caso de que desees profundizar en las GRUs, te animo a leer los siguientes papers de fácil lectura y de código abierto:
- Sobre las Propiedades de la Traducción Automática Neural: Enfoques Codificador-Decodificador
- Evaluación Empírica de Redes Neuronales Recurrentes con Puertas en Modelado de Secuencias
El Problema del Gradiente Desvaneciente
El Problema, Sus Causas, Su Importancia y Sus Soluciones
towardsdatascience.com
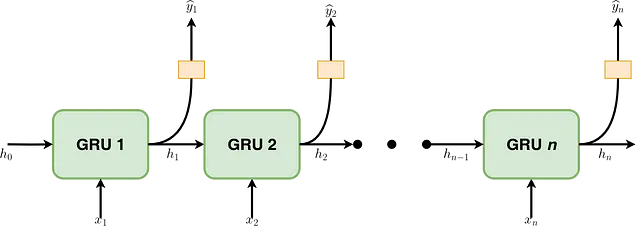
Este artículo implementa una RNN que no es ni profunda ni bidireccional. Las funciones integradas en Julia deben ser capaces de capturar este comportamiento. Como se ilustra en la Figura 1, una RNN con celdas GRU consta de una serie de fases secuenciales. En cada etapa t, proporciona un elemento correspondiente al estado oculto de la etapa inmediatamente anterior (hₜ₋₁). De manera similar, un elemento representa el elemento tᵗʰ de una secuencia de muestras (es decir, xₜ). La salida de cada celda GRU corresponde al estado oculto de ese paso de tiempo que se alimentará a la siguiente fase (es decir, hₜ). Además, hₜ puede pasar por una función como Softmax para obtener la salida deseada (por ejemplo, si una palabra en un texto es un adjetivo).
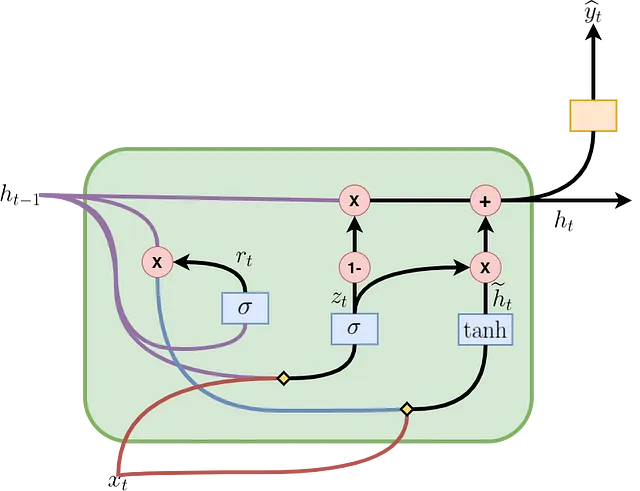
La Figura 2 muestra cómo se forma una celda GRU y cómo fluye la información y las operaciones matemáticas que ocurren en su interior. La celda en el paso de tiempo t contiene una puerta de actualización (zₜ) para determinar qué parte de la información anterior se pasará al siguiente paso y una puerta de reinicio (rₜ) para determinar qué parte de la información anterior se debe olvidar. Con rₜ, hₜ₋₁ y xₜ, se calcula un estado oculto candidato (ĥₜ) para el paso actual. Posteriormente, utilizando zₜ, hₜ₋₁ y ĥₜ, se calcula el estado oculto actual (hₜ₋₁). Todas estas operaciones componen el pase hacia adelante en una celda GRU y se resumen en las ecuaciones presentadas en la Figura 3, donde Wᵣₕ, Wᵣₓ, Wₕₕ, Wₕₓ, W₂ₓ, W₂ₕ, bᵣ, bₕ y b₂ son los parámetros aprendibles. El ” * ” indica multiplicación de matrices, mientras que “・” indica multiplicación de elementos.
En la literatura, es común encontrar las ecuaciones de pase hacia adelante como se muestra en la Figura 4. En esta figura, se utiliza la concatenación de matrices para acortar las expresiones presentadas en la Figura 3. Wᵣ, Wₕ y W₂ son las concatenaciones verticales entre Wᵣₕ y Wᵣₓ, Wₕₕ y Wₕₓ, y W₂ₓ y W₂ₕ, respectivamente. Los corchetes indican que los elementos contenidos dentro de ellos se concatenan horizontalmente. Ambas representaciones son útiles, siendo la de la Figura 4 buena para acortar las fórmulas y la de la Figura 3 útil para comprender las ecuaciones de retropropagación.
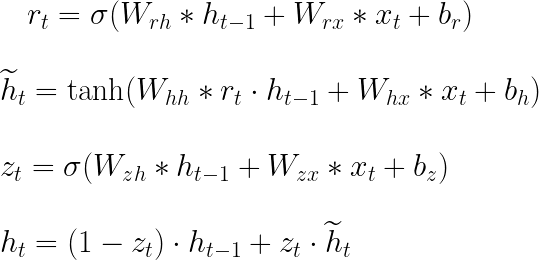
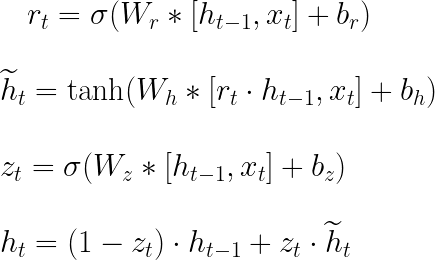
La Figura 4 muestra las ecuaciones de retropropagación que deben incluirse en el programa Julia para el entrenamiento del modelo. En las ecuaciones, ” T ” indica que se transponen las matrices. Estas ecuaciones se pueden obtener utilizando la definición de la derivada total para una función multivariable y la regla de la cadena. Además, puedes guiarte utilizando un enfoque gráfico 👇:
Pase hacia adelante y retropropagación en GRUs – Derivado | Aprendizaje Profundo
Una explicación de las unidades recurrentes con compuertas (GRUs) con las matemáticas detrás de cómo la pérdida se retropropaga a través del tiempo.
VoAGI.com
Unidades GRU
Para realizar la BPTT con una unidad GRU, tenemos el error proveniente de la capa superior (\(\delta 1\)), el oculto futuro…
cran.r-project.org

3. Configuración del proyecto
Para ejecutar el proyecto, instala Julia en tu computadora siguiendo las instrucciones de la documentación:
Instrucciones específicas de la plataforma para binarios oficiales
El sitio web oficial del lenguaje Julia. Julia es un lenguaje rápido, dinámico, fácil de usar y de código abierto…
julialang.org
Al igual que Python, puedes usar Jupyter Notebooks con kernels de Julia. Si deseas hacerlo, consulta el siguiente artículo escrito por el Dr. Martin McGovern, PhD FIA:
Cómo usar mejor Julia con Jupyter
Cómo agregar código de Julia a tus cuadernos de Jupyter y también permitirte usar Python y Julia simultáneamente en el mismo…
towardsdatascience.com
3.1. Estructura del proyecto
El proyecto dentro del repositorio de GitHub tiene la siguiente estructura de árbol:
.├── data│ ├── AAPL.csv│ ├── GOOG.csv│ └── IBM.csv├── plots│ ├── residual_plot.png│ └── sequence_plot.png├── Project.toml├── .pre-commit-config.yaml├── src│ ├── data_preprocessing.jl│ ├── main.jl│ ├── prediction_plots.jl│ └── scratch_gru.jl└── tests (unit testing) ├── test_data_preprocessing.jl ├── test_main.jl └── test_scratch_gru.jlCarpetas:
data: En esta carpeta encontrarás archivos.csvque contienen los datos para entrenar el modelo. Aquí se almacenan los archivos con los precios de las acciones.plots: Carpeta utilizada para almacenar las gráficas que se obtienen después del entrenamiento del modelo.src: Esta carpeta es el núcleo del proyecto y contiene los archivos.jlnecesarios para preprocesar los datos, entrenar el modelo, construir la arquitectura de la RNN, crear las celdas GRU y realizar las gráficas.tests: Esta carpeta contiene las pruebas unitarias construidas con Julia para asegurar la corrección del código y detectar errores. La explicación del contenido de esta carpeta está fuera del alcance de este artículo. Puedes utilizarla como referencia y avísame si te gustaría un artículo que explore el paqueteTest.
Pruebas unitarias
Base.runtests(tests=[“all”]; ncores=ceil(Int, Sys.CPU_THREADS / 2), exit_on_error=false, revise=false, [seed]) Ejecuta las…
docs.julialang.org
3.2. Paquetes necesarios
Aunque comenzaremos desde cero, se requieren los siguientes paquetes:
CSV(0.10.11):CSVes un paquete en Julia para trabajar con archivos de valores separados por comas (CSV).DataFrames(1.5.0):DataFrameses un paquete en Julia para trabajar con datos tabulares.LinearAlgebra(standard):LinearAlgebraes un paquete estándar en Julia que proporciona una colección de rutinas de álgebra lineal.Base(standard):Basees el módulo estándar en Julia que proporciona funcionalidad fundamental y tipos de datos básicos.Statistics(standard):Statisticses un módulo estándar en Julia que proporciona funciones y algoritmos estadísticos para el análisis de datos.ArgParse(1.1.4):ArgParsees un paquete en Julia para analizar argumentos de línea de comandos. Proporciona una forma fácil y flexible de definir interfaces de línea de comandos para scripts y aplicaciones de Julia.Plots(1.38.16):Plotses un paquete popular de trazado en Julia que proporciona una interfaz de alto nivel para crear visualizaciones de datos.Random(standard):Randomes un módulo estándar en Julia que proporciona funciones para generar números aleatorios y trabajar con procesos aleatorios.Test(standard, solo pruebas unitarias):Testes un módulo estándar en Julia que proporciona utilidades para escribir pruebas unitarias (fuera del alcance de este artículo).
Usando Project.toml, uno puede crear un entorno que contenga los paquetes mencionados anteriormente. Este archivo es similar a requirements.txt en Python o a environment.yml en Conda. Ejecute el siguiente comando para instalar las dependencias:
julia --project=. -e 'using Pkg; Pkg.instantiate()'3.3. Precios de las acciones
Como practicante de ciencia de datos, entiendes que los datos son el combustible que impulsa cada modelo de aprendizaje automático o estadístico. En nuestro ejemplo, los datos específicos del dominio provienen del mercado de valores. Yahoo Finance proporciona estadísticas del mercado de valores de acceso público. Específicamente, analizaremos estadísticas históricas para Google Inc. (GOOG). No obstante, también puedes buscar y descargar datos de otras empresas, como IBM y Apple.
Precios históricos de las acciones de Alphabet Inc. (GOOG) y datos – Yahoo Finance
Descubre los precios históricos de las acciones de GOOG en Yahoo Finance. Ver el formato diario, semanal o mensual desde que Alphabet…
finance.yahoo.com
4. Implementando la red GRU
Dentro de la carpeta src, puedes sumergirte en los archivos utilizados para generar las gráficas que se presentarán en la Sección 5 (prediction_plots.jl), procesar los precios de las acciones antes del entrenamiento del modelo (data_preprocessing.jl), entrenar y construir la red GRU (scratch_gru.jl), e integrar todos los archivos mencionados anteriormente en uno solo (main.jl). En esta sección, profundizaremos en las cuatro funciones que componen el corazón de la arquitectura de la red GRU y que se utilizan para implementar el pase hacia adelante y la retropropagación durante el entrenamiento.
4.1. Función gru_cell_forward
El fragmento de código presentado a continuación corresponde a la función gru_cell_forward. Esta función recibe la entrada actual (x), el estado oculto anterior (prev_h) y un diccionario de parámetros como entradas (parameters). Con los parámetros mencionados anteriormente, esta función permite un paso hacia adelante de la propagación hacia adelante de la celda GRU y calcula la compuerta de actualización (z), la compuerta de reinicio (r), el nuevo estado de memoria o estado oculto candidato (h_tilde) y el siguiente estado oculto (next_h), utilizando las funciones sigmoid y tanh. También calcula la predicción de la celda GRU (y_pred). Dentro de esta función, se implementan las ecuaciones presentadas en las Figuras 3 y 4.
4.2. Función gru_forward
A diferencia de gru_cell_forward, gru_forward realiza el pase hacia adelante de la red GRU, es decir, la propagación hacia adelante para una secuencia de pasos de tiempo. Esta función recibe el tensor de entrada (x), el estado oculto inicial (ho) y un diccionario como entrada (parameters).
Si eres nuevo en modelos secuenciales, no confundas un paso de tiempo con las iteraciones para minimizar el error del modelo.
No confundas el x que recibe gru_cell_forward con el que recibe gru_forward. En gru_forward, x tiene tres dimensiones en lugar de dos. La tercera dimensión corresponde al total de celdas GRU que tiene la capa RNN. En resumen, gru_cell_forward está relacionado con la Figura 2, mientras que gru_forward está relacionado con la Figura 1.
gru_forward itera sobre cada paso de tiempo en la secuencia, llamando a la función gru_cell_forward para calcular next_h y y_pred. Los resultados se almacenan en h y y, respectivamente.
4.3. Función gru_cell_backward
gru_cell_backward realiza el paso hacia atrás para una sola celda GRU. gru_cell_forward recibe el gradiente del estado oculto (dh) como entrada, acompañado de la cache que contiene los elementos necesarios para calcular las derivadas en la Figura 4 (es decir, next_h, prev_h, z, r, h_tilde, x y parameters). De esta manera, gru_cell_backward calcula los gradientes para las matrices de pesos (es decir, Wz, Wr y Wh) y los sesgos (es decir, bz, br y bh). Todos los gradientes se almacenan en un diccionario de Julia (gradients).
4.4. Función gru_backward
gru_backward realiza la retropropagación para la red GRU completa, es decir, para la secuencia completa de pasos de tiempo. Esta función recibe el gradiente del tensor de estado oculto (dh) y las caches. A diferencia del caso de gru_cell_backward, dh para gru_backward tiene una tercera dimensión correspondiente al número total de pasos de tiempo en la secuencia o celdas GRU en la capa de la red GRU. Esta función itera sobre los pasos de tiempo en orden inverso, llamando a gru_cell_backward para calcular los gradientes para cada paso de tiempo, acumulándolos en el bucle.
Es crucial señalar en esta etapa que este proyecto solo utiliza el descenso de gradiente para actualizar los parámetros de la red GRU y no incluye ninguna funcionalidad que afecte la tasa de aprendizaje o introduzca momento. Además, la implementación se creó teniendo en cuenta una preocupación de regresión. No obstante, debido a la modularización implementada, se requieren solo pequeños cambios para adquirir un comportamiento diferente.
5. Resultados e ideas
Ahora ejecutemos el código para entrenar la red GRU. Debido a la integración del paquete ArgParse, podemos usar argumentos de línea de comandos para ejecutar el código. El procedimiento es el mismo si estás familiarizado con Python. Realizaremos el experimento utilizando una división de entrenamiento del 0.7 (split_ratio), una longitud de secuencia de 10 (seq_length), un tamaño oculto de 70 (hidden_size), 1000 épocas (num_epochs) y una tasa de aprendizaje de 0.00001 (learning_rate) porque el propósito de este proyecto no es optimizar los hiperparámetros (lo cual implicaría el uso de módulos adicionales). Ejecuta el siguiente comando para comenzar el entrenamiento:
julia --project src/main.jl --data_file GOOG.csv --split_ratio 0.7 --seq_length 10 --hidden_size 70 --num_epochs 1000 --learning_rate 0.00001Aunque el modelo se entrena durante 1000 épocas, hay un control de flujo en la función
train_gruque almacena el mejor valor para los parámetros.
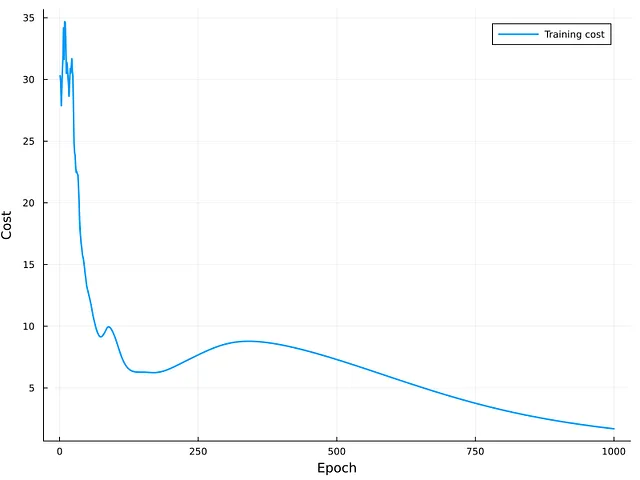
La Figura 5 muestra el costo de las iteraciones de entrenamiento. Como se puede observar, la curva tiene una tendencia descendente y el modelo parece converger alrededor de las últimas iteraciones. Debido a la curvatura de la curva, es posible que se pueda obtener una mejora adicional aumentando el número de épocas para entrenar la red GRU. La evaluación externa del conjunto de prueba produce un error cuadrático medio (MSE) de aproximadamente 6.57. Aunque este valor puede no ser cercano a cero, no se puede sacar una conclusión final debido a la falta de un valor de referencia para comparación.
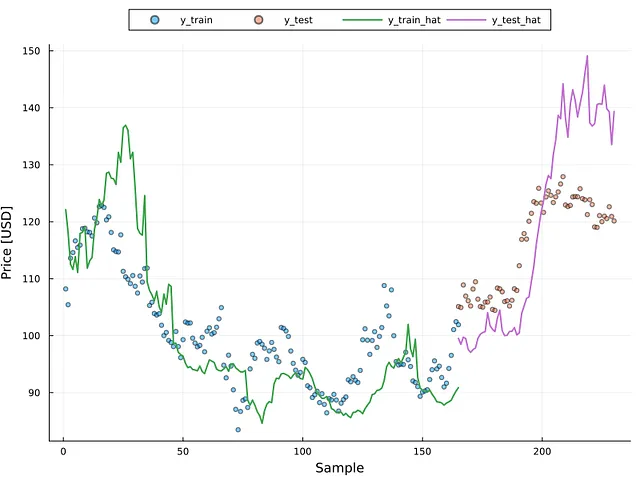
La Figura 6 muestra los valores reales para los conjuntos de datos de entrenamiento y prueba como puntos dispersos y los valores predichos como líneas continuas (ver la leyenda de la figura para más detalles). Es claro que el modelo coincide con la tendencia de los puntos reales; sin embargo, se requiere más entrenamiento para mejorar el rendimiento de la red GRU. Aun así, es posible observar que en algunas partes de la imagen, especialmente en el lado de entrenamiento, el modelo sobreajustó algunas muestras; dado que el MSE para el conjunto de entrenamiento fue alrededor de 1.70, es posible que el modelo presente algo de sobreajuste.
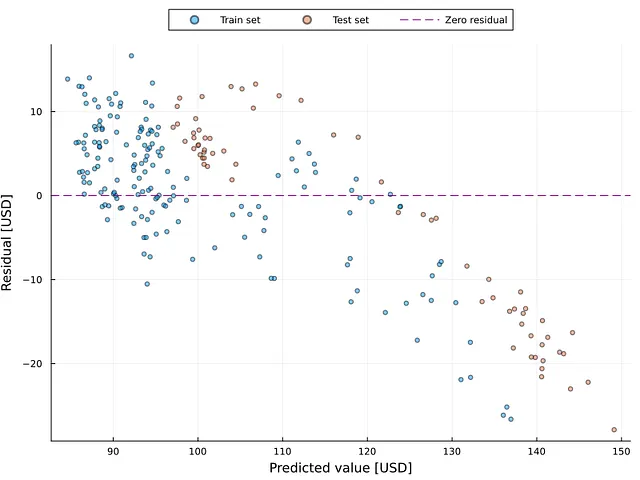
La fluctuación o inestabilidad del error puede ser un problema en el análisis de regresión, incluyendo la predicción de series de tiempo. En ciencia de datos y estadística, esto se conoce como heterocedasticidad (para más información, consulta el siguiente artículo 👇). El gráfico de residuos es un método para detectar la heterocedasticidad. La Figura 7 ilustra el gráfico de residuos, donde el eje x representa el valor predicho y el eje y representa el residuo.
Heterocedasticidad y Homocedasticidad en el Aprendizaje de Regresión
Variabilidad del residuo en el análisis de regresión
pub.towardsai.net
Los puntos espaciados uniformemente alrededor del valor cero indican la presencia de homocedasticidad (es decir, residuos estables). Esta figura muestra evidencia de heterocedasticidad en este escenario, lo que requeriría el uso de métodos para corregir el problema (por ejemplo, la transformación logarítmica) para crear un modelo de alto rendimiento. La Figura 7 muestra que la presencia de heterocedasticidad es evidente por encima de los 120 USD, independientemente de si la muestra proviene del conjunto de entrenamiento o de prueba. La Figura 6 ayuda a reforzar este punto. La Figura 6 indica que los valores mayores a 120 se desvían significativamente del número real.
Conclusión
En esta publicación, construimos una red GRU desde cero utilizando el lenguaje de programación Julia. Comenzamos investigando las ecuaciones matemáticas que el programa necesitaba considerar, así como los problemas teóricos más críticos para que la implementación de GRU sea exitosa. Repasamos cómo crear la configuración inicial para que los programas de Julia manejen los datos, establecer la arquitectura GRU, entrenar el modelo y evaluarlo. Repasamos los fragmentos de código más importantes utilizados en el diseño de la arquitectura del modelo. Ejecutamos los programas para analizar los resultados. Detectamos la presencia de heterocedasticidad en este proyecto en particular, recomendando la investigación de estrategias para superar este problema y crear una red GRU de alto rendimiento.
Te invito a examinar el código en GitHub y hacernos saber si deseas que analicemos algo más en Julia o en otro tema de ciencia de datos o programación. Tus ideas y comentarios son extremadamente útiles para mí 🚀…
Material adicional
- Unidad Recurrente con Compuertas (GRU)
- Curso Completo de Modelos de Secuencia
Si disfrutas de mis publicaciones, sígueme en VoAGI para estar al tanto de más contenido estimulante y comparte este material con tus colegas.

We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La evolución automatizada aborda tareas difíciles
- La IA está haciendo que la política sea más fácil, más barata y más peligrosa
- La FTC investiga si ChatGPT perjudica a los consumidores
- Investigadores cultivan matrices precisas de nanoLEDs
- Calculadora de números determina si las ballenas están actuando de manera extraña
- Los robots de IA podrían desempeñar un papel futuro como compañeros en hogares de cuidado
- El aumento de los costos de los centros de datos vinculados a las demandas de la inteligencia artificial






