Conoce Retroformer Un elegante marco de inteligencia artificial para mejorar iterativamente los agentes de lenguaje grandes mediante el aprendizaje de un modelo retrospectivo de conexión.
Retroformer es un marco AI elegante para mejorar agentes de lenguaje grandes mediante el aprendizaje de un modelo retrospectivo de conexión.


Ha surgido una nueva tendencia potente en la que los grandes modelos de lenguaje (LLMs, por sus siglas en inglés) se mejoran para convertirse en agentes de lenguaje autónomos capaces de llevar a cabo actividades de forma independiente, eventualmente al servicio de un objetivo, en lugar de simplemente responder a preguntas de los usuarios. React, Toolformer, HuggingGPT, agentes generativos, WebGPT, AutoGPT, BabyAGI y Langchain son algunas de las investigaciones conocidas que han demostrado de manera efectiva la viabilidad de desarrollar agentes autónomos de toma de decisiones utilizando LLMs. Estos métodos utilizan LLMs para producir salidas y acciones basadas en texto que luego se pueden utilizar para acceder a APIs y llevar a cabo actividades en un contexto específico.
La mayoría de los agentes de lenguaje actuales, sin embargo, no tienen comportamientos optimizados o alineados con las funciones de recompensa del entorno debido al enorme alcance de los LLMs con una alta cantidad de parámetros. Reflexion, una arquitectura de agente de lenguaje bastante reciente y muchas otras obras en la misma línea, incluyendo Self-Refine y Generative Agent, son una anomalía porque utilizan retroalimentación verbal, específicamente la autorreflexión, para ayudar a los agentes a aprender de fracasos pasados. Estos agentes reflexivos convierten las recompensas binarias o escalares del entorno en una entrada vocal como un resumen textual, proporcionando un contexto adicional a la solicitud del agente de lenguaje.
La retroalimentación de autorreflexión sirve como una señal semántica para el agente al proporcionarle un área específica en la que enfocarse para mejorar. Esto permite que el agente aprenda de fracasos pasados y evite repetir los mismos errores una y otra vez para que pueda mejorar en el próximo intento. Aunque la mejora iterativa es posible gracias a la operación de autorreflexión, puede ser difícil generar retroalimentación reflexiva útil a partir de un LLM pre-entrenado y congelado, como se muestra en la Fig. 1. Esto se debe a que el LLM debe ser capaz de identificar las áreas en las que el agente se equivocó en un entorno particular, como el problema de asignación de crédito, y producir un resumen con sugerencias para mejorar.
- Transición de carrera de Ingeniero de Sistemas a Analista de Datos
- Investigadores de NVIDIA y la Universidad de Tel Aviv presentan Perfusion una red neuronal compacta de 100 KB con un tiempo de entrenamiento eficiente.
- Revolucionando el Diseño de Proteínas Cómo esta investigación de IA aumentó las tasas de éxito diez veces con mejoras en el Aprendizaje Profundo
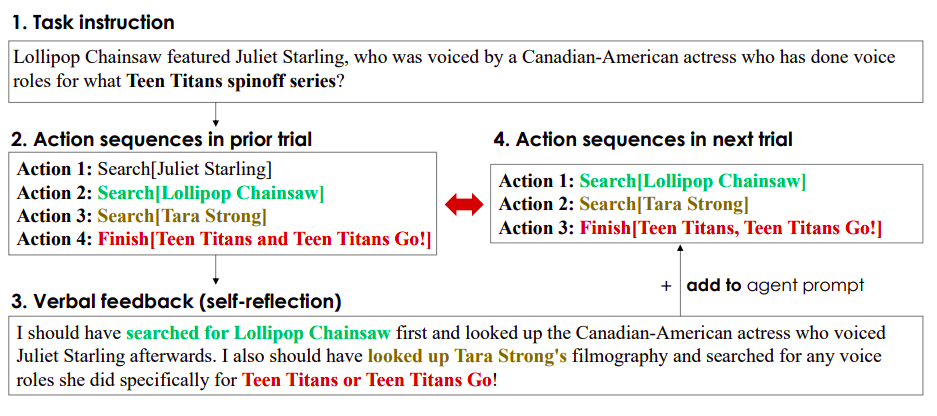
El modelo de lenguaje congelado debe ser ajustado de manera suficiente para especializarse en problemas de asignación de crédito para las tareas en circunstancias particulares a fin de optimizar la retroalimentación verbal. Además, los agentes de lenguaje actuales no razonan ni planifican de manera consistente con el aprendizaje diferenciable basado en gradientes utilizando los numerosos enfoques de aprendizaje por refuerzo que se utilizan actualmente. Investigadores de Salesforce Research presentan Retroformer, un marco moral para reforzar a los agentes de lenguaje mediante el aprendizaje de un modelo retrospectivo complementario para resolver restricciones. Retroformer mejora automáticamente las solicitudes del agente de lenguaje en función de la información del entorno a través de la optimización de políticas.
En particular, la arquitectura de agente propuesta puede refinar de manera iterativa un modelo de lenguaje pre-entrenado mediante la reflexión sobre intentos fallidos y asignando créditos a las acciones realizadas por el agente en función de recompensas futuras. Esto se logra aprendiendo a partir de información de recompensa arbitraria en múltiples entornos y tareas. Realizan experimentos en simulaciones de código abierto y entornos del mundo real, como HotPotQA, para evaluar las habilidades de uso de herramientas de un agente web que debe contactar repetidamente con las APIs de Wikipedia para responder preguntas. HotPotQA comprende tareas de búsqueda y respuesta basadas en preguntas. Los agentes Retroformer, a diferencia de la reflexión, que no utiliza gradientes para el pensamiento y la planificación, son aprendices más rápidos y mejores tomadores de decisiones. Específicamente, los agentes Retroformer aumentan la tasa de éxito de HotPotQA en tareas de búsqueda y respuesta basadas en preguntas en un 18% en solo cuatro intentos, lo que demuestra el valor de la planificación y el razonamiento basados en gradientes para el uso de herramientas en entornos con un gran espacio de estado-acción.
En conclusión, lo siguiente es lo que han contribuido:
• La investigación desarrolla Retroformer, que mejora la velocidad de aprendizaje y la finalización de tareas refinando repetidamente las indicaciones suministradas a los agentes de lenguaje basados en la entrada contextual. El método propuesto se centra en mejorar el modelo retrospectivo en la arquitectura del agente de lenguaje sin acceder a los parámetros del Actor LLM o necesitar propagar gradientes.
• El método propuesto permite el aprendizaje a partir de diversas señales de recompensa para tareas y entornos diversos. Retroformer es un módulo complementario adaptable para muchos tipos de LLM basados en la nube, como GPT o Bard, debido a su naturaleza agnóstica.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Descifrando el comportamiento colectivo Cómo la inferencia bayesiana activa impulsa los movimientos naturales de los grupos de animales
- Conoce Jupyter AI Desatando el poder de la inteligencia artificial en los cuadernos de Jupyter
- Tres desafíos en la implementación de modelos generativos en producción
- Construyendo PCA desde cero
- Cómo construir un pipeline de detección de cambios de datos completamente automatizado
- Fundamentos de Estadística para Científicos de Datos y Analistas
- Detectando Fraude en el Comercio Electrónico con Técnicas Avanzadas de Ciencia de Datos






