¿Cuál es la conexión entre los Transformers y las Máquinas de Vectores de Soporte? Revelando el sesgo implícito y la geometría de optimización en las arquitecturas de los Transformers
Relación entre Transformers y Máquinas de Vectores de Soporte sesgo implícito y geometría de optimización en arquitecturas de Transformers


El procesamiento del lenguaje natural (NLP) ha revolucionado debido a la auto-atención, el elemento clave del diseño del transformer, que permite al modelo reconocer conexiones complejas dentro de las secuencias de entrada. La auto-atención asigna diferentes cantidades de prioridad a distintos aspectos de la secuencia de entrada al evaluar la relevancia de los tokens relevantes entre sí. Esta técnica ha demostrado ser muy efectiva para capturar relaciones a largo plazo, lo cual es importante para el aprendizaje por refuerzo, la visión por computadora y las aplicaciones de NLP. Los mecanismos de auto-atención y los transformers han logrado un éxito notable, allanando el camino para crear modelos de lenguaje complejos como GPT4, Bard, LLaMA y ChatGPT.
¿Pueden describir el sesgo implícito de los transformers y el panorama de optimización? ¿Cómo elige y combina los tokens la capa de atención cuando se entrena con descenso de gradientes? Investigadores de la Universidad de Pensilvania, la Universidad de California, la Universidad de Columbia Británica y la Universidad de Michigan responden a estos problemas vinculando cuidadosamente la geometría de optimización de la capa de atención con el problema SVM de máximo margen (Att-SVM), que separa y elige los mejores tokens de cada secuencia de entrada. Los experimentos demuestran que este formalismo, que se basa en trabajos anteriores, es prácticamente significativo e ilumina los matices de la auto-atención.
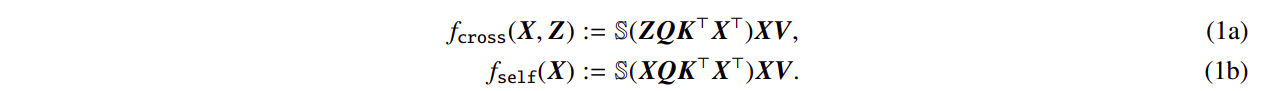
A lo largo del artículo, investigan los modelos de auto-atención cruzada y auto-atención fundamental utilizando secuencias de entrada X, Z ∈ RT×d con longitud T y dimensión de incrustación d: Aquí, las matrices clave, consulta y valor entrenables son K, Q ∈ Rd×m y V ∈ Rd×v respectivamente. S( . ) representa la no linealidad softmax, que se aplica fila por fila a XQK⊤X⊤. Al establecer Z ← X, se puede ver que la auto-atención (1b) es un caso único de la auto-atención cruzada (1a). Consideren el uso del token inicial de Z, representado por z, para predecir y revelar sus principales hallazgos.
- Conoce a CodiumAI El Asistente Definitivo para Pruebas Basado en Inteligencia Artificial para Desarrolladores
- Salesforce presenta la nueva plataforma Einstein 1 Elevando la productividad y la confianza del cliente a través de la IA impulsada por datos y el CRM.
- Desbloqueando la eficiencia en Transformers de Visión Cómo los MoEs de Visión Móvil Escasos superan a sus contrapartes densas en aplicaciones con recursos limitados
En concreto, abordan la minimización del riesgo empírico con una función de pérdida decreciente l(): R R, expresada de la siguiente manera: Dado un conjunto de datos de entrenamiento (Yi, Xi, zi)ni=1 con etiquetas Yi ∈ {−1, 1} e insumos Xi ∈ RT×d, zi ∈ Rd, evalúan lo siguiente: La cabeza de predicción en este caso, denotada por el símbolo h( . ), incluye los pesos de valor V. En esta formulación, un MLP sigue a la capa de atención en el modelo f( . ), que representa de manera precisa un transformer de una sola capa. La auto-atención se restaura en (2) al establecer zi ← xi1, donde xi1 designa el primer token de la secuencia Xi. Debido a su carácter no lineal, la operación softmax presenta un obstáculo considerable para optimizar (2).

El problema es no convexo y no lineal, incluso cuando la cabeza de predicción está fija y es lineal. Este trabajo optimiza los pesos de atención (K, Q o W) para superar estas dificultades y establecer una equivalencia básica con SVM.
Las siguientes son las principales contribuciones del artículo:
• El sesgo implícito de la capa de atención. Con la norma nuclear como objetivo del parámetro de combinación W := KQ (Thm 2), la optimización de los parámetros de atención (K, Q) con una regularización decreciente converge en dirección a una solución de margen máximo de (Att-SVM). El camino de regularización (RP) converge en dirección a la solución de (Att-SVM) con la norma de Frobenius como objetivo cuando la atención cruzada está explícitamente parametrizada por el parámetro de combinación W. Hasta donde saben, este es el primer estudio que compara formalmente la dinámica de optimización de las parametrizaciones (K, Q) con las parametrizaciones (W), destacando el sesgo de baja rango de estas últimas. El Teorema 11 y SAtt-SVM en el apéndice describen cómo su teoría se extiende fácilmente a contextos de secuencia a secuencia o categorización causal y definen claramente la optimalidad de los tokens elegidos.
• Convergencia del descenso de gradiente. Con la inicialización adecuada y una cabeza lineal h(), las iteraciones del descenso de gradiente para la variable combinada clave-consulta W convergen en la dirección de una solución Att-SVM que es localmente óptima. Los tokens seleccionados deben tener un mejor rendimiento que los tokens circundantes para la optimalidad local. Las reglas de optimalidad local se definen en la siguiente geometría del problema, aunque no siempre son únicas. Contribuyen significativamente al identificar los parámetros geométricos que aseguran la convergencia hacia la dirección globalmente óptima. Estos incluyen (i) la capacidad de diferenciar tokens ideales en función de sus puntajes o (ii) la alineación de la dirección de gradiente inicial con los tokens óptimos. Además de esto, demuestran cómo la sobreparametrización (es decir, la dimensión d siendo grande y condiciones equivalentes) promueve la convergencia global al garantizar la factibilidad de Att-SVM y un paisaje de optimización benigno, lo que significa que no hay puntos estacionarios ni direcciones localmente óptimas ficticias.
• Generalidad de la equivalencia del SVM. La capa de atención, a menudo conocida como atención dura al optimizar con h() lineal, tiene intrínsecamente sesgo hacia la elección de un token de cada secuencia. Como resultado de los tokens de salida siendo combinaciones convexas de los tokens de entrada, esto se refleja en el (Att-SVM).
Sin embargo, demuestran que las cabezas no lineales necesitan la creación de varios tokens, subrayando la importancia de estos componentes en la dinámica del transformador. Sugieren una equivalencia del SVM más amplia al concluir su teoría. Sorprendentemente, muestran que su hipótesis predice correctamente el sesgo implícito de la atención entrenada por descenso de gradiente bajo condiciones amplias que no aborda el enfoque (por ejemplo, h() siendo un MLP). Sus ecuaciones generales disocian específicamente los pesos de atención en dos componentes: un componente finito que determina la composición precisa de las palabras seleccionadas modificando las probabilidades de softmax y un componente direccional controlado por SVM que elige los tokens aplicando una máscara 0-1.
El hecho de que estos resultados se puedan verificar matemáticamente y aplicar a cualquier conjunto de datos (siempre que SVM sea práctico) es un aspecto clave de ellos. A través de experimentos perspicaces, confirman de manera exhaustiva la equivalencia de margen máximo y el sesgo implícito de los transformadores. Creen que estos resultados contribuyen a nuestro conocimiento de los transformadores como procesos jerárquicos de selección de tokens de margen máximo, y anticipan que sus hallazgos proporcionarán una base sólida para futuras investigaciones sobre la optimización y la dinámica de generalización de los transformadores.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- La inteligencia artificial de Alibaba, Tongyi Qianwen, está abierta al público.
- ¿ChatGPT tomará trabajos de ciencia de datos?
- Gestión de memoria en Apache Spark Derrame en disco
- Competencias culturales para la gestión de riesgos del aprendizaje automático
- Drones abordan la seguridad de los tiburones en las playas de Nueva York
- Mejorando la Ajuste de Hiperparámetros con el Estimador Parzen Estructurado en Árbol (Hyperopt)
- Snowflake vs. Data Bricks Compitiendo para crear la mejor plataforma de datos en la nube