Proyecto RedPajama Una iniciativa de código abierto para democratizar los modelos de lenguaje de aprendizaje automático (LLM)
RedPajama Project An open-source initiative to democratize machine learning language models (LLM).
Liderando el proyecto para Empoderar a la Comunidad a través de Modelos de Lenguaje Amplios Accesibles.

En tiempos recientes, los Modelos de Lenguaje Grande o LLM han dominado el mundo. Con la introducción de ChatGPT, ahora todos podrían beneficiarse del modelo de generación de texto. Pero muchos modelos poderosos solo están disponibles comercialmente, dejando atrás una gran cantidad de investigación y personalización.
Hay, por supuesto, muchos proyectos que ahora intentan abrir muchos de los LLM completamente. Proyectos como Pythia, Dolly, DLite y muchos otros son algunos ejemplos. ¿Pero por qué intentar hacer que los LLM sean de código abierto? Es un sentimiento de la comunidad que movió a todos estos proyectos a superar las limitaciones que el modelo cerrado presenta. Sin embargo, ¿son los modelos de código abierto inferiores en comparación con los cerrados? Por supuesto que no. Muchos modelos podrían competir con los modelos comerciales y mostrar resultados prometedores en muchas áreas.
- Técnicas avanzadas de selección de características para modelos de aprendizaje automático
- AI Modelos de Lenguaje y Visión de Gran Escala
- Escala tus cargas de trabajo de aprendizaje automático en Amazon ECS impulsado por instancias AWS Trainium.
Para seguir esta tendencia, uno de los proyectos de código abierto para democratizar LLM es RedPajama. ¿Qué es este proyecto y cómo podría beneficiar a la comunidad? Explorémoslo más a fondo.
RedPajama
RedPajama es un proyecto de colaboración entre Ontocord.ai, ETH DS3Lab, Stanford CRFM y Hazy Research para desarrollar LLM de código abierto reproducibles. El proyecto RedPajama contiene tres hitos, que incluyen:
- Datos de pre-entrenamiento
- Modelos base
- Afinamiento de datos y modelos de instrucciones
Cuando se escribió este artículo, el proyecto RedPajama había desarrollado los datos y modelos de pre-entrenamiento, incluyendo las versiones base, instruidas y de chat.
Datos de pre-entrenamiento de RedPajama
En el primer paso, RedPajama intenta replicar el conjunto de datos LLaMa del modelo semi-abierto. Esto significa que RedPajama intenta construir datos de pre-entrenamiento con 1,2 billones de tokens y abrirlo completamente para la comunidad. Actualmente, los datos completos y los datos de muestra se pueden descargar en HuggingFace.
Las fuentes de datos para el conjunto de datos de RedPajama se resumen en la tabla a continuación. 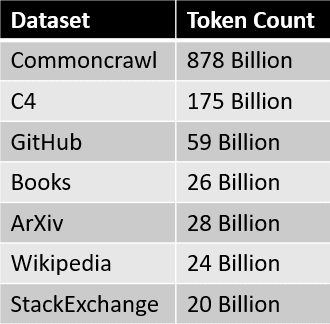 Donde cada segmento de datos se preprocesa y filtra cuidadosamente, la cantidad de tokens también coincide aproximadamente con el número informado en el documento LLaMa.
Donde cada segmento de datos se preprocesa y filtra cuidadosamente, la cantidad de tokens también coincide aproximadamente con el número informado en el documento LLaMa.
El siguiente paso después de la creación del conjunto de datos es el desarrollo de los modelos base.
Modelos de RedPajama
En las semanas siguientes a la creación del conjunto de datos de RedPajama, se lanzó el primer modelo entrenado en el conjunto de datos. Los modelos base tienen dos versiones: un modelo de 3 mil millones y un modelo de 7 mil millones de parámetros. El proyecto RedPajama también libera dos variaciones de cada modelo base: modelos afinados por instrucción y modelos de chat.
El resumen de cada modelo se puede ver en la tabla a continuación. 
Puede acceder a los modelos anteriores utilizando los siguientes enlaces:
- RedPajama-INCITE-Base-3B-v1
- RedPajama-INCITE-Chat-3B-v1
- RedPajama-INCITE-Instruct-3B-v1
- RedPajama-INCITE-Base-7B-v0.1
- RedPajama-INCITE-Chat-7B-v0.1
- RedPajama-INCITE-Instruct-7B-v0.1
Probemos el modelo base de RedPajama. Por ejemplo, probaremos el modelo base de RedPajama 3B con el código adaptado de HuggingFace.
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# init
tokenizer = AutoTokenizer.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1"
)
model = AutoModelForCausalLM.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1", torch_dtype=torch.bfloat16
)
# infer
prompt = "Madre Teresa es"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.7,
top_k=50,
return_dict_in_generate=True
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)
una santa católica y es conocida por su trabajo con los pobres y moribundos en Calcuta, India.
Nacida en Skopje, Macedonia, en 1910, fue la menor de trece hermanos. Sus padres murieron cuando ella tenía solo ocho años y fue criada por su hermano mayor, quien era sacerdote.
En 1928, ingresó en la Orden de las Hermanas de Loreto en Irlanda. Se convirtió en maestra y luego en monja, y se dedicó a cuidar a los pobres y enfermos.
Era conocida por su trabajo con los pobres y moribundos en Calcuta, India.El resultado del modelo base 3B es prometedor, pero podría ser mejor si usamos el modelo base 7B. Como el desarrollo todavía está en curso, es posible que el proyecto tenga un modelo aún mejor en el futuro.
Conclusión
La inteligencia artificial generativa está en aumento, pero lamentablemente muchos modelos excelentes aún están bloqueados en los archivos de la empresa. RedPajama es uno de los proyectos líderes que intenta replicar el modelo semiabierto LLaMA para democratizar los LLM. Al desarrollar un conjunto de datos similar al de LLama, RedPajama logra crear un conjunto de datos de 1,2 billones de tokens de código abierto que muchos proyectos de código abierto han utilizado.
RedPajama también lanza dos tipos de modelos; modelos base de parámetros 3B y 7B, donde cada modelo base contiene modelos de chat e instrucciones ajustadas. Cornellius Yudha Wijaya es un asistente de gestión de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos de Python y datos a través de las redes sociales y los medios de comunicación escritos.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





