Redes convolucionales de grafos Introducción a las GNN
Redes convolucionales de grafos - GNN
Una guía paso a paso usando PyTorch Geometric

Las Redes Neuronales Gráficas (GNNs) representan una de las arquitecturas más cautivadoras y de evolución rápida en el campo del aprendizaje profundo. Como modelos de aprendizaje profundo diseñados para procesar datos estructurados como gráficos, las GNNs ofrecen una versatilidad notable y capacidades de aprendizaje potentes.
Entre los diferentes tipos de GNNs, las Redes Convolucionales Gráficas (GCNs) han surgido como el modelo más prevalente y ampliamente aplicado. Las GCNs son innovadoras debido a su capacidad para aprovechar tanto las características de un nodo como su localidad para hacer predicciones, proporcionando una forma efectiva de manejar datos estructurados en forma de gráficos.
En este artículo, profundizaremos en la mecánica de la capa GCN y explicaremos su funcionamiento interno. Además, exploraremos su aplicación práctica para tareas de clasificación de nodos, utilizando PyTorch Geometric como nuestra herramienta de elección.
PyTorch Geometric es una extensión especializada de PyTorch que ha sido creada específicamente para el desarrollo e implementación de GNNs. Es una biblioteca avanzada pero fácil de usar que ofrece un conjunto completo de herramientas para facilitar el aprendizaje automático basado en gráficos. Para comenzar nuestro viaje, se requerirá la instalación de PyTorch Geometric. Si estás utilizando Google Colab, PyTorch ya debería estar instalado, por lo que todo lo que necesitamos hacer es ejecutar algunos comandos adicionales.
- Los Conjuntos de Estímulos Hacen que los LLMs Sean Más Confiables
- Difusión Estable El AI de la Comunidad
- Cómo utilizar ChatGPT para convertir texto en una presentación de PowerPoint
Todo el código está disponible en Google Colab y GitHub.
!pip install torch_geometric
import torchimport numpy as npimport networkx as nximport matplotlib.pyplot as pltAhora que PyTorch Geometric está instalado, exploremos el conjunto de datos que utilizaremos en este tutorial.
🌐 I. Datos del gráfico
Los gráficos son una estructura esencial para representar las relaciones entre objetos. Puedes encontrar datos en forma de gráficos en una multitud de escenarios del mundo real, como redes sociales y de computadoras, estructuras químicas de moléculas, procesamiento de lenguaje natural y reconocimiento de imágenes, por nombrar algunos.
En este artículo, estudiaremos el infame y muy utilizado conjunto de datos del club de karate de Zachary.
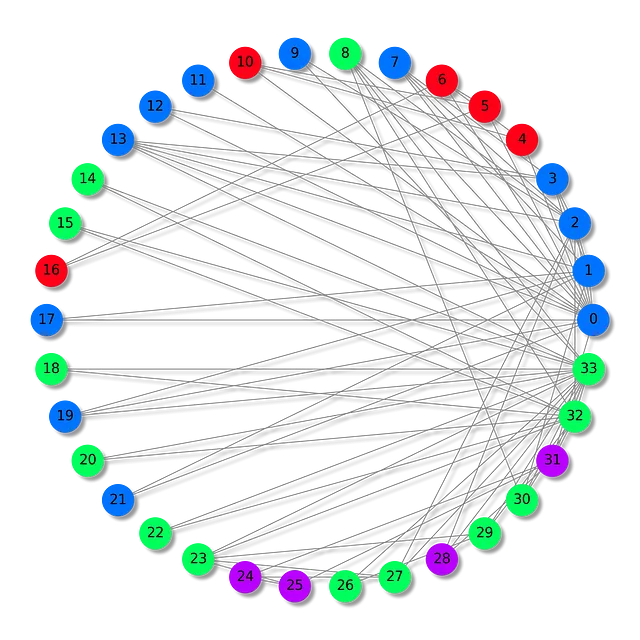
El conjunto de datos del club de karate de Zachary representa las relaciones formadas dentro de un club de karate, tal como fue observado por Wayne W. Zachary durante la década de 1970. Es una especie de red social, donde cada nodo representa un miembro del club, y las aristas entre nodos representan interacciones que ocurrieron fuera del entorno del club.
En este escenario particular, los miembros del club se dividen en cuatro grupos distintos. Nuestra tarea es asignar el grupo correcto a cada miembro (clasificación de nodos), basándonos en el patrón de sus interacciones.
Importemos el conjunto de datos con la función incorporada de PyG y tratemos de entender el objeto Datasets que utiliza.
from torch_geometric.datasets import KarateClub
# Importar conjunto de datos de PyTorch Geometricdataset = KarateClub()# Imprimir informaciónprint(dataset)print('------------')print(f'Número de gráficos: {len(dataset)}')print(f'Número de características: {dataset.num_features}')print(f'Número de clases: {dataset.num_classes}')
KarateClub()------------Número de gráficos: 1Número de características: 34Número de clases: 4Este conjunto de datos solo tiene 1 gráfico, donde cada nodo tiene un vector de características de 34 dimensiones y pertenece a una de las cuatro clases (nuestros cuatro grupos). En realidad, el objeto Datasets se puede ver como una colección de objetos Data (gráfico).
Podemos inspeccionar aún más nuestro único gráfico para obtener más información al respecto.
# Imprimir primer elementoprint(f'Gráfico: {dataset[0]}')
Gráfico: Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])El objeto Data es particularmente interesante. Imprimirlo ofrece un buen resumen del gráfico que estamos estudiando:
x=[34, 34]es la matriz de características de los nodos con forma (número de nodos, número de características). En nuestro caso, esto significa que tenemos 34 nodos (nuestros 34 miembros), cada nodo está asociado a un vector de características de 34 dimensiones.edge_index=[2, 156]representa la conectividad del grafo (cómo están conectados los nodos) con forma (2, número de aristas dirigidas).y=[34]son las etiquetas verdaderas de los nodos. En este problema, cada nodo está asignado a una clase (grupo), por lo que tenemos un valor para cada nodo.train_mask=[34]es un atributo opcional que indica qué nodos se deben usar para entrenar con una lista de afirmacionesTrueoFalse.
Imprimamos cada uno de estos tensores para entender qué almacenan. Comencemos con las características de los nodos.
data = dataset[0]
print(f'x = {data.x.shape}')print(data.x)
x = torch.Size([34, 34])tensor([[1., 0., 0., ..., 0., 0., 0.], [0., 1., 0., ..., 0., 0., 0.], [0., 0., 1., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 1., 0., 0.], [0., 0., 0., ..., 0., 1., 0.], [0., 0., 0., ..., 0., 0., 1.]])Aquí, la matriz de características de los nodos x es una matriz identidad: no contiene ninguna información relevante acerca de los nodos. Podría contener información como edad, nivel de habilidad, etc., pero ese no es el caso en este conjunto de datos. Esto significa que tendremos que clasificar nuestros nodos solo mirando sus conexiones.
Ahora, imprimamos el índice de las aristas.
print(f'edge_index = {data.edge_index.shape}')print(data.edge_index)
edge_index = torch.Size([2, 156])tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8, 8, 9, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 23, 23, 23, 23, 23, 24, 24, 24, 25, 25, 25, 26, 26, 27, 27, 27, 27, 28, 28, 28, 29, 29, 29, 29, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33], [ 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 17, 19, 21, 31, 0, 2, 3, 7, 13, 17, 19, 21, 30, 0, 1, 3, 7, 8, 9, 13, 27, 28, 32, 0, 1, 2, 7, 12, 13, 0, 6, 10, 0, 6, 10, 16, 0, 4, 5, 16, 0, 1, 2, 3, 0, 2, 30, 32, 33, 2, 33, 0, 4, 5, 0, 0, 3, 0, 1, 2, 3, 33, 32, 33, 32, 33, 5, 6, 0, 1, 32, 33, 0, 1, 33, 32, 33, 0, 1, 32, 33, 25, 27, 29, 32, 33, 25, 27, 31, 23, 24, 31, 29, 33, 2, 23, 24, 33, 2, 31, 33, 23, 26, 32, 33, 1, 8, 32, 33, 0, 24, 25, 28, 32, 33, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 33, 8, 9, 13, 14, 15, 18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]])En teoría de grafos y análisis de redes, la conectividad entre nodos se almacena utilizando una variedad de estructuras de datos. El edge_index es una de esas estructuras de datos, donde las conexiones del grafo se almacenan en dos listas (156 aristas dirigidas, que equivalen a 78 aristas bidireccionales). La razón de estas dos listas es que una lista almacena los nodos de origen, mientras que la segunda identifica los nodos de destino.
Este método se conoce como formato de lista de coordenadas (COO), que es esencialmente una forma de almacenar eficientemente una matriz dispersa. Las matrices dispersas son estructuras de datos que almacenan eficientemente matrices con una mayoría de elementos cero. En el formato COO, solo se almacenan los elementos no cero, lo que ahorra memoria y recursos computacionales.
Por el contrario, una forma más intuitiva y directa de representar la conectividad de un grafo es a través de una matriz de adyacencia A. Esta es una matriz cuadrada donde cada elemento Aᵢⱼ especifica la presencia o ausencia de una arista desde el nodo i al nodo j en el grafo. En otras palabras, un elemento no cero Aᵢⱼ implica una conexión desde el nodo i al nodo j, y un cero indica que no hay una conexión directa.
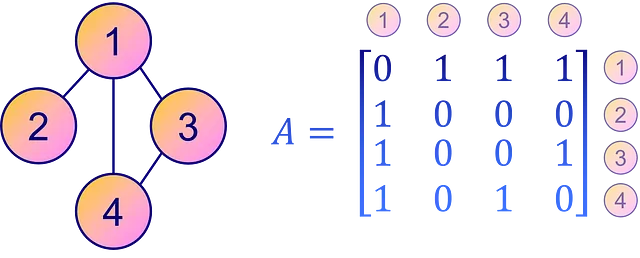
Una matriz de adyacencia, sin embargo, no es tan eficiente en cuanto al espacio como el formato COO para matrices dispersas o grafos con menos aristas. Sin embargo, por claridad y facilidad de interpretación, la matriz de adyacencia sigue siendo una opción popular para representar la conectividad de un grafo.
La matriz de adyacencia se puede inferir a partir del edge_index con una función de utilidad to_dense_adj().
from torch_geometric.utils import to_dense_adj
A = to_dense_adj(data.edge_index)[0].numpy().astype(int)print(f'A = {A.shape}')print(A)
A = (34, 34)[[0 1 1 ... 1 0 0] [1 0 1 ... 0 0 0] [1 1 0 ... 0 1 0] ... [1 0 0 ... 0 1 1] [0 0 1 ... 1 0 1] [0 0 0 ... 1 1 0]]Con datos de grafo, es relativamente poco común que los nodos estén densamente interconectados. Como puedes ver, nuestra matriz de adyacencia A es dispersa (llena de ceros).
En muchos grafos del mundo real, la mayoría de los nodos están conectados solo a unos pocos otros nodos, lo que resulta en un gran número de ceros en la matriz de adyacencia. Almacenar tantos ceros no es eficiente en absoluto, por lo que el formato COO es adoptado por PyG.
Por el contrario, las etiquetas de verdad del terreno son fáciles de entender.
print(f'y = {data.y.shape}')print(data.y)
y = torch.Size([34])tensor([1, 1, 1, 1, 3, 3, 3, 1, 0, 1, 3, 1, 1, 1, 0, 0, 3, 1, 0, 1, 0, 1, 0, 0, 2, 2, 0, 0, 2, 0, 0, 2, 0, 0])Nuestras etiquetas de verdad de nodo almacenadas en y simplemente codifican el número de grupo (0, 1, 2, 3) para cada nodo, por eso tenemos 34 valores.
Finalmente, imprimamos la máscara de entrenamiento.
print(f'train_mask = {data.train_mask.shape}')print(data.train_mask)
train_mask = torch.Size([34])tensor([ True, False, False, False, True, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, False, False])La máscara de entrenamiento muestra qué nodos se supone que se deben utilizar para el entrenamiento con declaraciones True. Estos nodos representan el conjunto de entrenamiento, mientras que los demás se pueden considerar como el conjunto de prueba. Esta división ayuda en la evaluación del modelo al proporcionar datos no vistos para las pruebas.
¡Pero aún no hemos terminado! El objeto Data tiene mucho más que ofrecer. Proporciona varias funciones de utilidad que permiten investigar varias propiedades del grafo. Por ejemplo:
is_directed()te dice si el grafo es dirigido. Un grafo dirigido significa que la matriz de adyacencia no es simétrica, es decir, la dirección de las aristas importa en las conexiones entre los nodos.isolated_nodes()verifica si algunos nodos no están conectados al resto del grafo. Estos nodos probablemente representen desafíos en tareas como la clasificación debido a su falta de conexiones.has_self_loops()indica si al menos un nodo está conectado a sí mismo. Esto es distinto del concepto de bucles: un bucle implica un camino que comienza y termina en el mismo nodo, atravesando otros nodos en el medio.
En el contexto del conjunto de datos del club de karate de Zachary, todas estas propiedades devuelven False. Esto implica que el grafo no es dirigido, no tiene nodos aislados y ninguno de sus nodos está conectado a sí mismo.
print(f'Las aristas son dirigidas: {data.is_directed()}')print(f'El grafo tiene nodos aislados: {data.has_isolated_nodes()}')print(f'El grafo tiene bucles: {data.has_self_loops()}')
Las aristas son dirigidas: FalseEl grafo tiene nodos aislados: FalseEl grafo tiene bucles: FalseFinalmente, podemos convertir un grafo de PyTorch Geometric a la popular biblioteca de grafos NetworkX usando to_networkx. Esto es particularmente útil para visualizar un grafo pequeño con networkx y matplotlib.
Veamos nuestro conjunto de datos con un color diferente para cada grupo.
from torch_geometric.utils import to_networkx
G = to_networkx(data, to_undirected=True)plt.figure(figsize=(12,12))plt.axis('off')nx.draw_networkx(G, pos=nx.spring_layout(G, seed=0), with_labels=True, node_size=800, node_color=data.y, cmap="hsv", vmin=-2, vmax=3, width=0.8, edge_color="grey", font_size=14 )plt.show()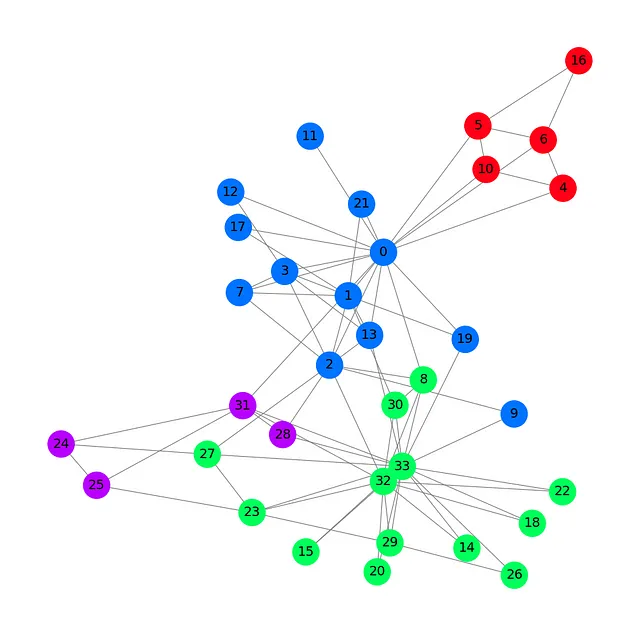
Este gráfico del club de karate de Zachary muestra nuestros 34 nodos, 78 aristas (bidireccionales) y 4 etiquetas con 4 colores diferentes. Ahora que hemos visto lo esencial de cargar y manejar un conjunto de datos con PyTorch Geometric, podemos presentar la arquitectura de la Red Convolucional en Grafos.
✉️ II. Red Convolucional en Grafos
Esta sección tiene como objetivo presentar y construir la capa de convolución en grafos desde cero.
En las redes neuronales tradicionales, las capas lineales aplican una transformación lineal a los datos entrantes. Esta transformación convierte las características de entrada x en vectores ocultos h mediante el uso de una matriz de pesos 𝐖. Ignorando los sesgos por el momento, esto se puede expresar como:
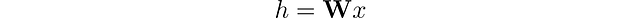
Con datos de grafos, se agrega una capa adicional de complejidad a través de las conexiones entre nodos. Estas conexiones importan porque, típicamente, en las redes se asume que los nodos similares son más propensos a estar vinculados entre sí que los nodos diferentes, un fenómeno conocido como homofilia en redes.
Podemos enriquecer nuestra representación del nodo fusionando sus características con las de sus vecinos. Esta operación se llama convolución o agregación de vecindario. Representemos el vecindario del nodo i incluyéndolo a sí mismo como Ñ.
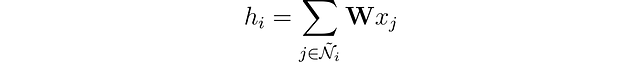
A diferencia de los filtros en las Redes Neuronales Convolucionales (CNNs), nuestra matriz de pesos 𝐖 es única y compartida entre todos los nodos. Pero hay otro problema: los nodos no tienen un número fijo de vecinos como los píxeles.
¿Cómo abordamos los casos en los que un nodo tiene solo un vecino y otro tiene 500? Si simplemente sumamos los vectores de características, la incrustación resultante h sería mucho más grande para el nodo con 500 vecinos. Para garantizar un rango similar de valores para todos los nodos y comparabilidad entre ellos, podemos normalizar el resultado en función del grado de los nodos, donde el grado se refiere al número de conexiones que tiene un nodo.
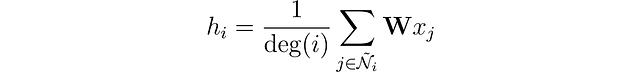
¡Casi estamos allí! Introducido por Kipf et al. (2016), la capa de convolución de gráficos tiene una mejora final.
Los autores observaron que las características de los nodos con numerosos vecinos se propagan mucho más fácilmente que las de los nodos más aislados. Para compensar este efecto, sugirieron asignar pesos mayores a las características de los nodos con menos vecinos, equilibrando así la influencia en todos los nodos. Esta operación se escribe como:
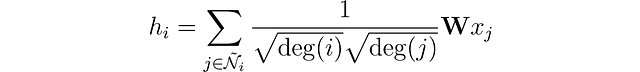
Observa que cuando i y j tienen el mismo número de vecinos, es equivalente a nuestra propia capa. Ahora, veamos cómo implementarlo en Python con PyTorch Geometric.
🧠 III. Implementando un GCN
PyTorch Geometric proporciona la función GCNConv, que implementa directamente la capa de convolución de gráficos.
En este ejemplo, crearemos una red de convolución gráfica básica con una sola capa GCN, una función de activación ReLU y una capa de salida lineal. Esta capa de salida dará cuatro valores correspondientes a nuestras cuatro categorías, siendo el valor más alto el que determine la clase de cada nodo.
En el siguiente bloque de código, definimos la capa GCN con una capa oculta tridimensional.
from torch.nn import Linearfrom torch_geometric.nn import GCNConv
class GCN(torch.nn.Module): def __init__(self): super().__init__() self.gcn = GCNConv(dataset.num_features, 3) self.out = Linear(3, dataset.num_classes) def forward(self, x, edge_index): h = self.gcn(x, edge_index).relu() z = self.out(h) return h, zmodel = GCN()print(model)
GCN( (gcn): GCNConv(34, 3) (out): Linear(in_features=3, out_features=4, bias=True))Si agregáramos una segunda capa GCN, nuestro modelo no solo agregaría vectores de características de los vecinos de cada nodo, sino también de los vecinos de estos vecinos.
Podemos apilar varias capas de gráficos para agregar valores cada vez más distantes, pero hay un problema: si agregamos demasiadas capas, la agregación se vuelve tan intensa que todas las incrustaciones terminan viéndose iguales. Este fenómeno se llama sobre-suavizado y puede ser un problema real cuando tienes demasiadas capas.
Ahora que hemos definido nuestro GNN, escribamos un bucle de entrenamiento simple con PyTorch. Elegí una pérdida de entropía cruzada regular ya que es una tarea de clasificación multiclase, con Adam como optimizador. En este artículo, no implementaremos una división de entrenamiento/prueba para mantener las cosas simples y centrarnos en cómo aprenden los GNN en su lugar.
El bucle de entrenamiento es estándar: intentamos predecir las etiquetas correctas y comparamos los resultados de GCN con los valores almacenados en data.y. El error se calcula mediante la pérdida de entropía cruzada y se retropropaga con Adam para ajustar los pesos y sesgos de nuestro GNN. Finalmente, imprimimos métricas cada 10 épocas.
criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
# Calcular precisióndef accuracy(pred_y, y): return (pred_y == y).sum() / len(y)# Datos para animacionesembeddings = []losses = []accuracies = []outputs = []# Bucle de entrenamientofor epoch in range(201): # Limpiar gradientes optimizer.zero_grad() # Pase hacia adelante h, z = model(data.x, data.edge_index) # Calcular función de pérdida loss = criterion(z, data.y) # Calcular precisión acc = accuracy(z.argmax(dim=1), data.y) # Calcular gradientes loss.backward() # Ajustar parámetros optimizer.step() # Almacenar datos para animaciones embeddings.append(h) losses.append(loss) accuracies.append(acc) outputs.append(z.argmax(dim=1)) # Imprimir métricas cada 10 épocas if epoch % 10 == 0: print(f'Época {epoch:>3} | Pérdida: {loss:.2f} | Precisión: {acc*100:.2f}%')
Época 0 | Pérdida: 1.40 | Precisión: 41.18%Época 10 | Pérdida: 1.21 | Precisión: 47.06%Época 20 | Pérdida: 1.02 | Precisión: 67.65%Época 30 | Pérdida: 0.80 | Precisión: 73.53%Época 40 | Pérdida: 0.59 | Precisión: 73.53%Época 50 | Pérdida: 0.39 | Precisión: 94.12%Época 60 | Pérdida: 0.23 | Precisión: 97.06%Época 70 | Pérdida: 0.13 | Precisión: 100.00%Época 80 | Pérdida: 0.07 | Precisión: 100.00%Época 90 | Pérdida: 0.05 | Precisión: 100.00%Época 100 | Pérdida: 0.03 | Precisión: 100.00%Época 110 | Pérdida: 0.02 | Precisión: 100.00%Época 120 | Pérdida: 0.02 | Precisión: 100.00%Época 130 | Pérdida: 0.02 | Precisión: 100.00%Época 140 | Pérdida: 0.01 | Precisión: 100.00%Época 150 | Pérdida: 0.01 | Precisión: 100.00%Época 160 | Pérdida: 0.01 | Precisión: 100.00%Época 170 | Pérdida: 0.01 | Precisión: 100.00%Época 180 | Pérdida: 0.01 | Precisión: 100.00%Época 190 | Pérdida: 0.01 | Precisión: 100.00%Época 200 | Pérdida: 0.01 | Precisión: 100.00%¡Genial! Sin mucha sorpresa, alcanzamos una precisión del 100% en el conjunto de entrenamiento (conjunto de datos completo). Esto significa que nuestro modelo aprendió a asignar correctamente a cada miembro del club de karate a su grupo correcto.
Podemos producir una visualización ordenada animando el gráfico y ver la evolución de las predicciones del GNN durante el proceso de entrenamiento.
%%capturefrom IPython.display import HTMLfrom matplotlib import animationplt.rcParams["animation.bitrate"] = 3000
def animate(i): G = to_networkx(data, to_undirected=True) nx.draw_networkx(G, pos=nx.spring_layout(G, seed=0), with_labels=True, node_size=800, node_color=outputs[i], cmap="hsv", vmin=-2, vmax=3, width=0.8, edge_color="grey", font_size=14 ) plt.title(f'Época {i} | Pérdida: {losses[i]:.2f} | Precisión: {accuracies[i]*100:.2f}%', fontsize=18, pad=20)fig = plt.figure(figsize=(12, 12))plt.axis('off')anim = animation.FuncAnimation(fig, animate, \ np.arange(0, 200, 10), interval=500, repeat=True)html = HTML(anim.to_html5_video())display(html)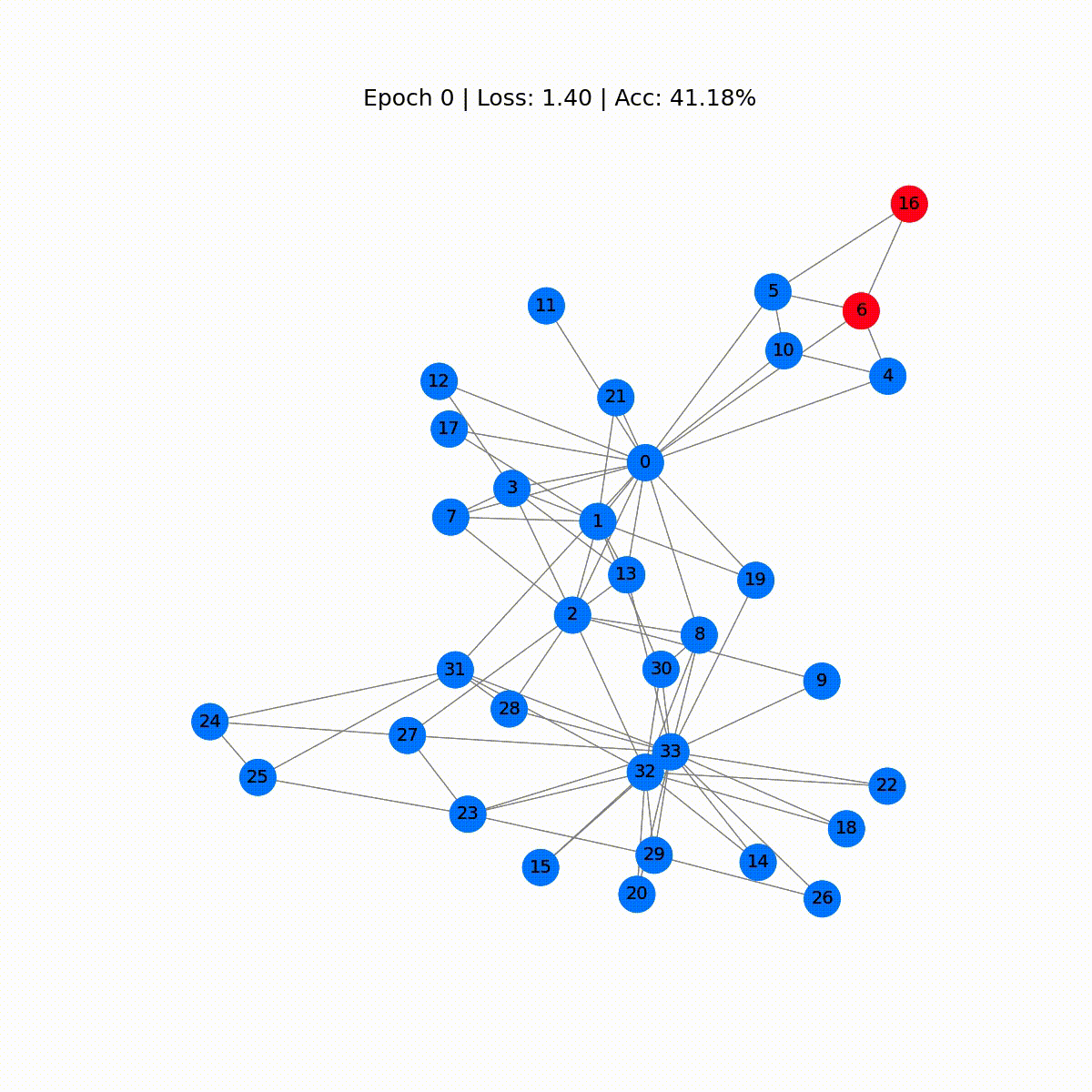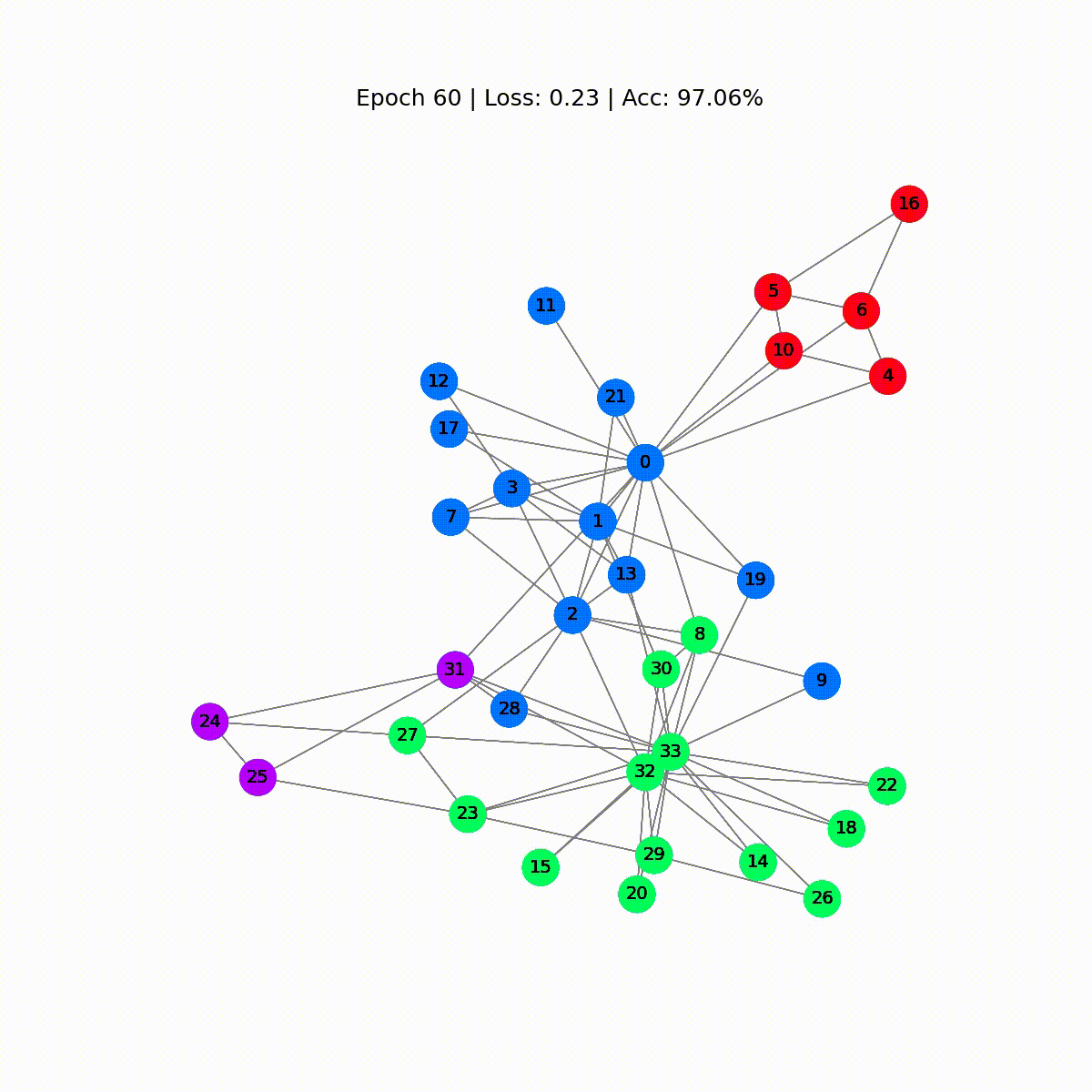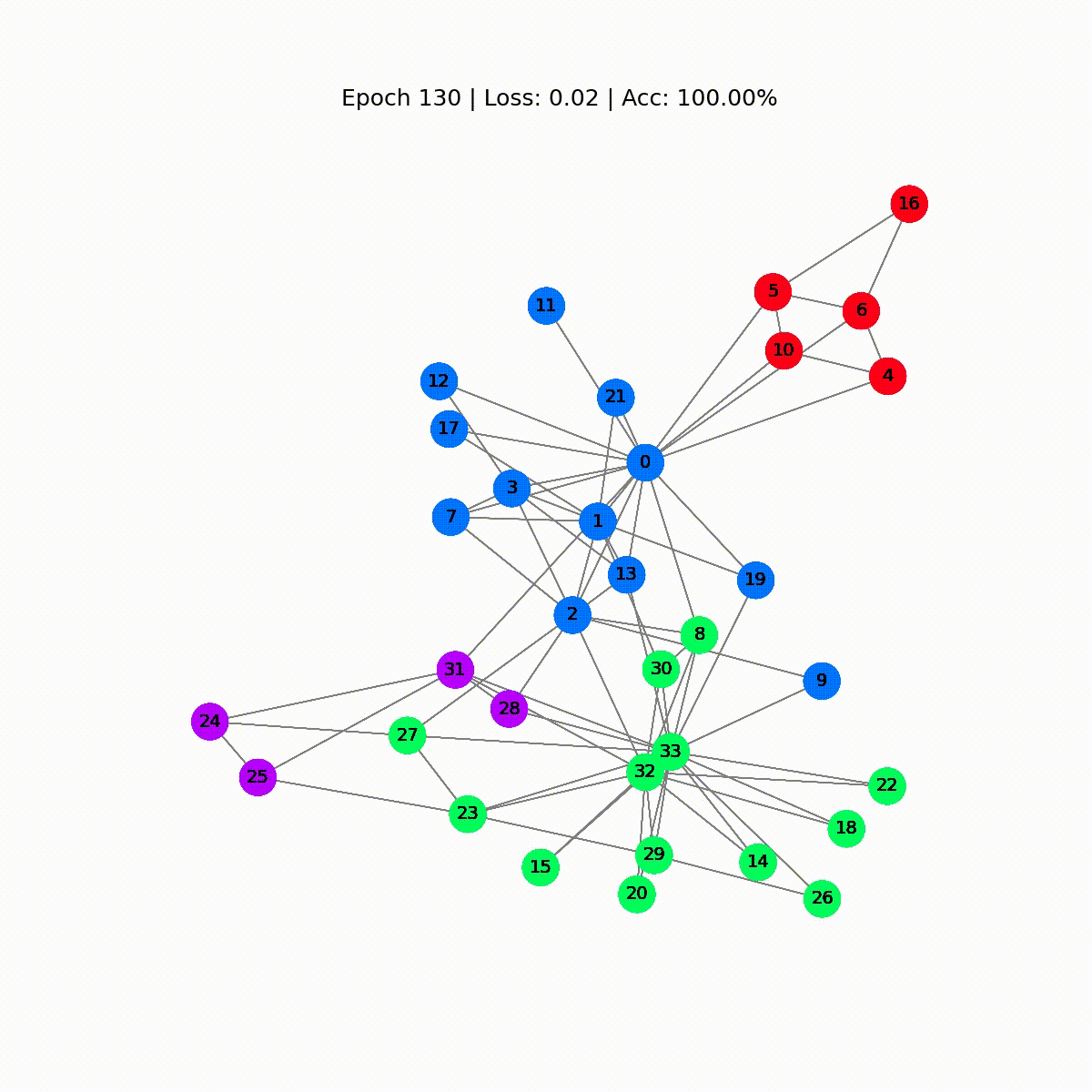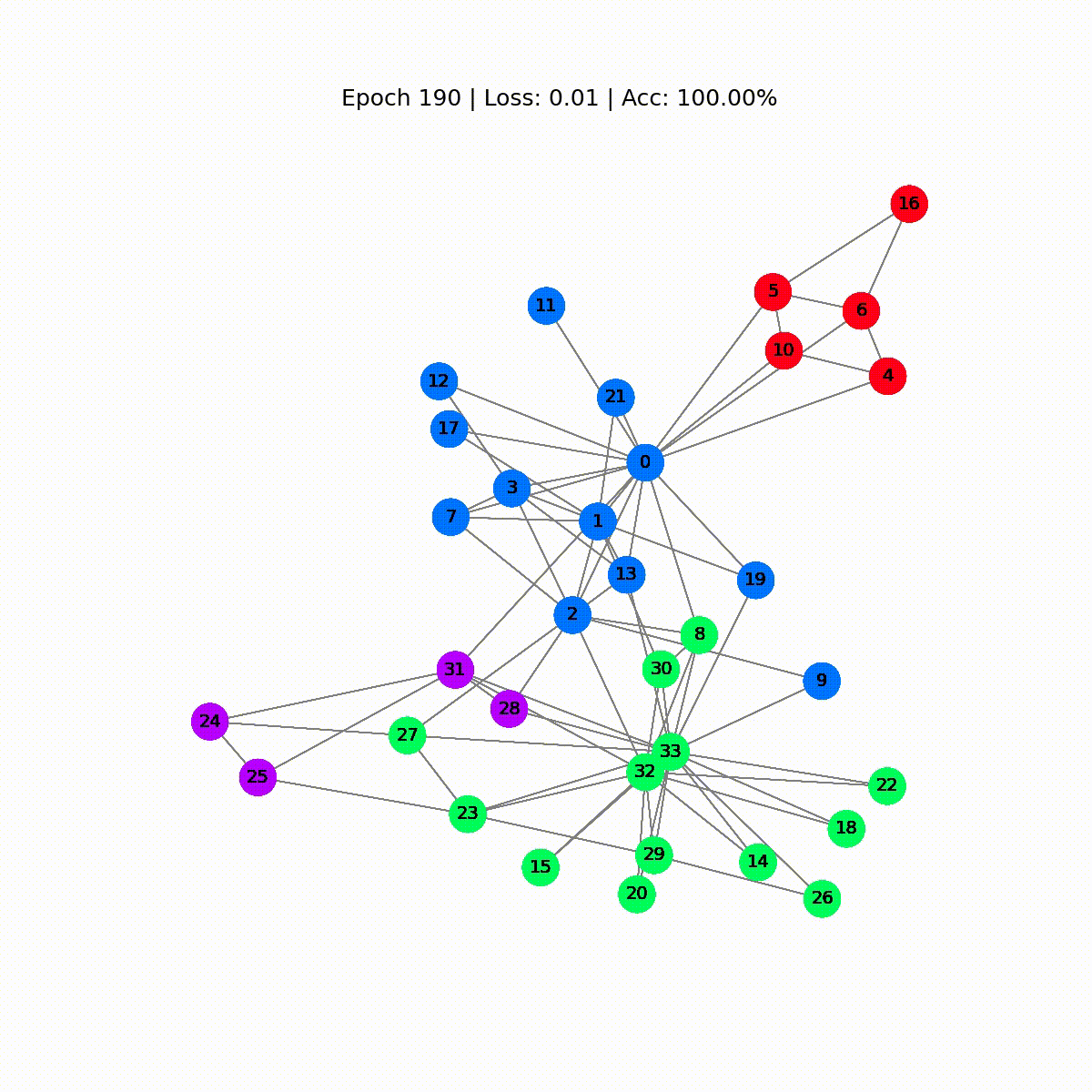
Las primeras predicciones son aleatorias, pero el GCN etiqueta perfectamente cada nodo después de un tiempo. De hecho, el gráfico final es el mismo que el que trazamos al final de la primera sección. Pero, ¿qué aprende realmente el GCN?
Al agregar características de nodos vecinos, el GNN aprende una representación vectorial (o embedding) de cada nodo en la red. En nuestro modelo, la capa final solo aprende cómo utilizar estas representaciones para producir las mejores clasificaciones. Sin embargo, los embeddings son los verdaderos productos de los GNN.
Imprimamos los embeddings aprendidos por nuestro modelo.
# Imprimir embeddingsprint(f'Embeddings finales = {h.shape}')print(h)
Embeddings finales = torch.Size([34, 3])tensor([[1.9099e+00, 2.3584e+00, 7.4027e-01], [2.6203e+00, 2.7997e+00, 0.0000e+00], [2.2567e+00, 2.2962e+00, 6.4663e-01], [2.0802e+00, 2.8785e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 2.9694e+00], [0.0000e+00, 0.0000e+00, 3.3817e+00], [0.0000e+00, 1.5008e-04, 3.4246e+00], [1.7593e+00, 2.4292e+00, 2.4551e-01], [1.9757e+00, 6.1032e-01, 1.8986e+00], [1.7770e+00, 1.9950e+00, 6.7018e-01], [0.0000e+00, 1.1683e-04, 2.9738e+00], [1.8988e+00, 2.0512e+00, 2.6225e-01], [1.7081e+00, 2.3618e+00, 1.9609e-01], [1.8303e+00, 2.1591e+00, 3.5906e-01], [2.0755e+00, 2.7468e-01, 1.9804e+00], [1.9676e+00, 3.7185e-01, 2.0011e+00], [0.0000e+00, 0.0000e+00, 3.4787e+00], [1.6945e+00, 2.0350e+00, 1.9789e-01], [1.9808e+00, 3.2633e-01, 2.1349e+00], [1.7846e+00, 1.9585e+00, 4.8021e-01], [2.0420e+00, 2.7512e-01, 1.9810e+00], [1.7665e+00, 2.1357e+00, 4.0325e-01], [1.9870e+00, 3.3886e-01, 2.0421e+00], [2.0614e+00, 5.1042e-01, 2.4872e+00],... [2.1778e+00, 4.4730e-01, 2.0077e+00], [3.8906e-02, 2.3443e+00, 1.9195e+00], [3.0748e+00, 0.0000e+00, 3.0789e+00], [3.4316e+00, 1.9716e-01, 2.5231e+00]], grad_fn=<ReluBackward0>)Como puedes ver, las incrustaciones no necesitan tener las mismas dimensiones que los vectores de características. Aquí, elegí reducir el número de dimensiones de 34 (dataset.num_features) a tres para obtener una visualización agradable en 3D.
Veamos estas incrustaciones antes de que ocurra cualquier entrenamiento, en la época 0.
# Obtener la primera incrustación en la época = 0embed = h.detach().cpu().numpy()
fig = plt.figure(figsize=(12, 12))ax = fig.add_subplot(projection='3d')ax.patch.set_alpha(0)plt.tick_params(left=False, bottom=False, labelleft=False, labelbottom=False)ax.scatter(embed[:, 0], embed[:, 1], embed[:, 2], s=200, c=data.y, cmap="hsv", vmin=-2, vmax=3)plt.show()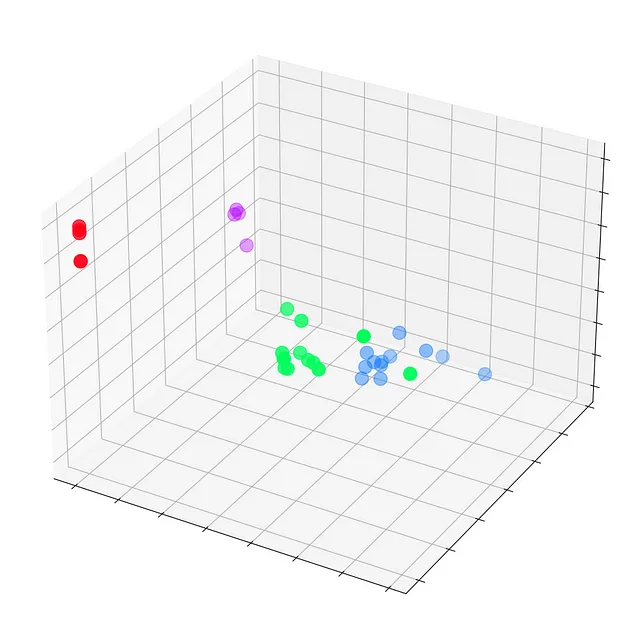
Vemos cada nodo del club de karate de Zachary con sus etiquetas reales (y no las predicciones del modelo). Por ahora, están dispersos por todas partes ya que el GNN aún no está entrenado. Pero si graficamos estas incrustaciones en cada paso del bucle de entrenamiento, podríamos visualizar lo que el GNN realmente aprende.
Veamos cómo evolucionan con el tiempo, a medida que el GCN mejora cada vez más en la clasificación de nodos.
%%capture
def animate(i): embed = embeddings[i].detach().cpu().numpy() ax.clear() ax.scatter(embed[:, 0], embed[:, 1], embed[:, 2], s=200, c=data.y, cmap="hsv", vmin=-2, vmax=3) plt.title(f'Época {i} | Pérdida: {losses[i]:.2f} | Precisión: {accuracies[i]*100:.2f}%', fontsize=18, pad=40)fig = plt.figure(figsize=(12, 12))plt.axis('off')ax = fig.add_subplot(projection='3d')plt.tick_params(left=False, bottom=False, labelleft=False, labelbottom=False)anim = animation.FuncAnimation(fig, animate, \ np.arange(0, 200, 10), interval=800, repeat=True)html = HTML(anim.to_html5_video())display(html)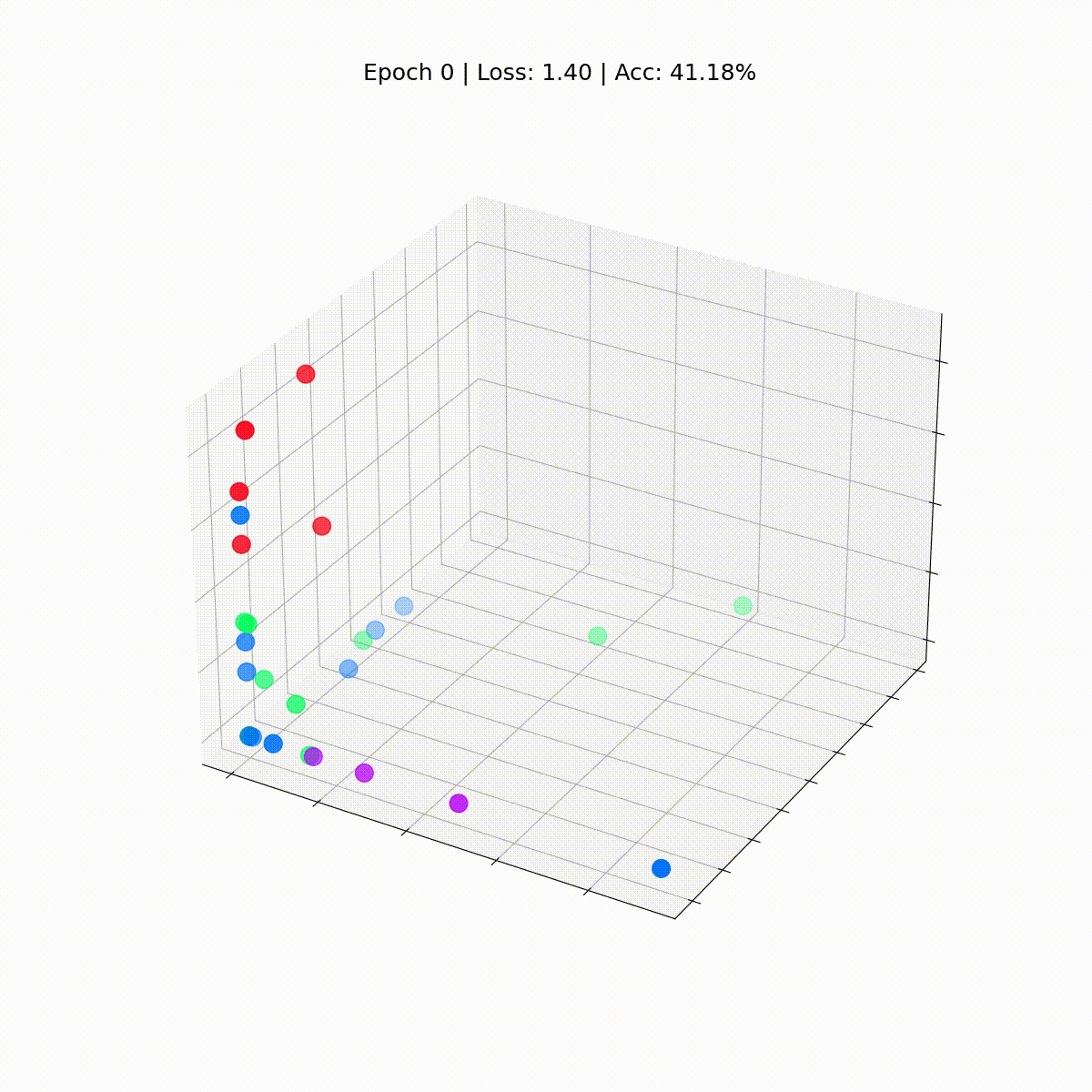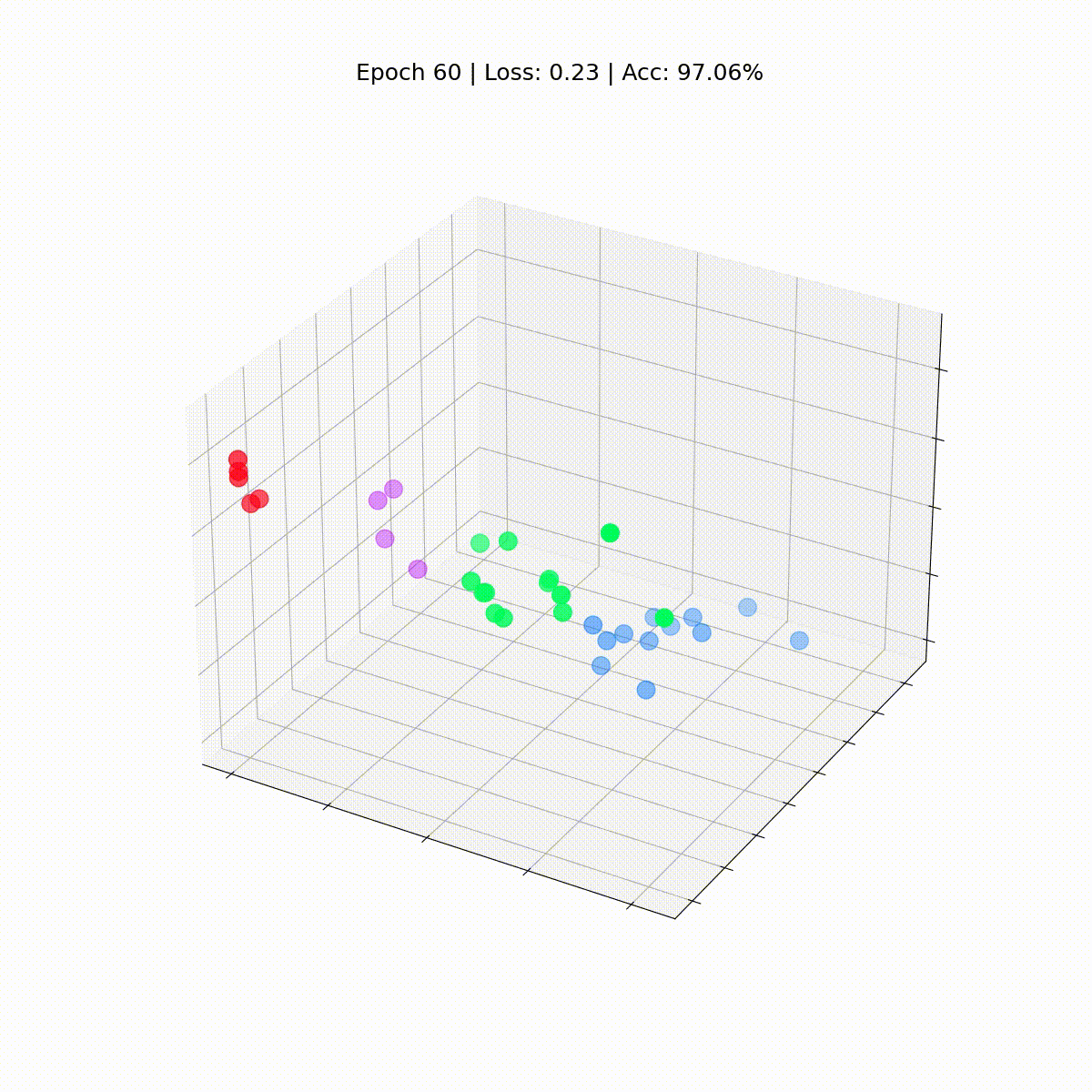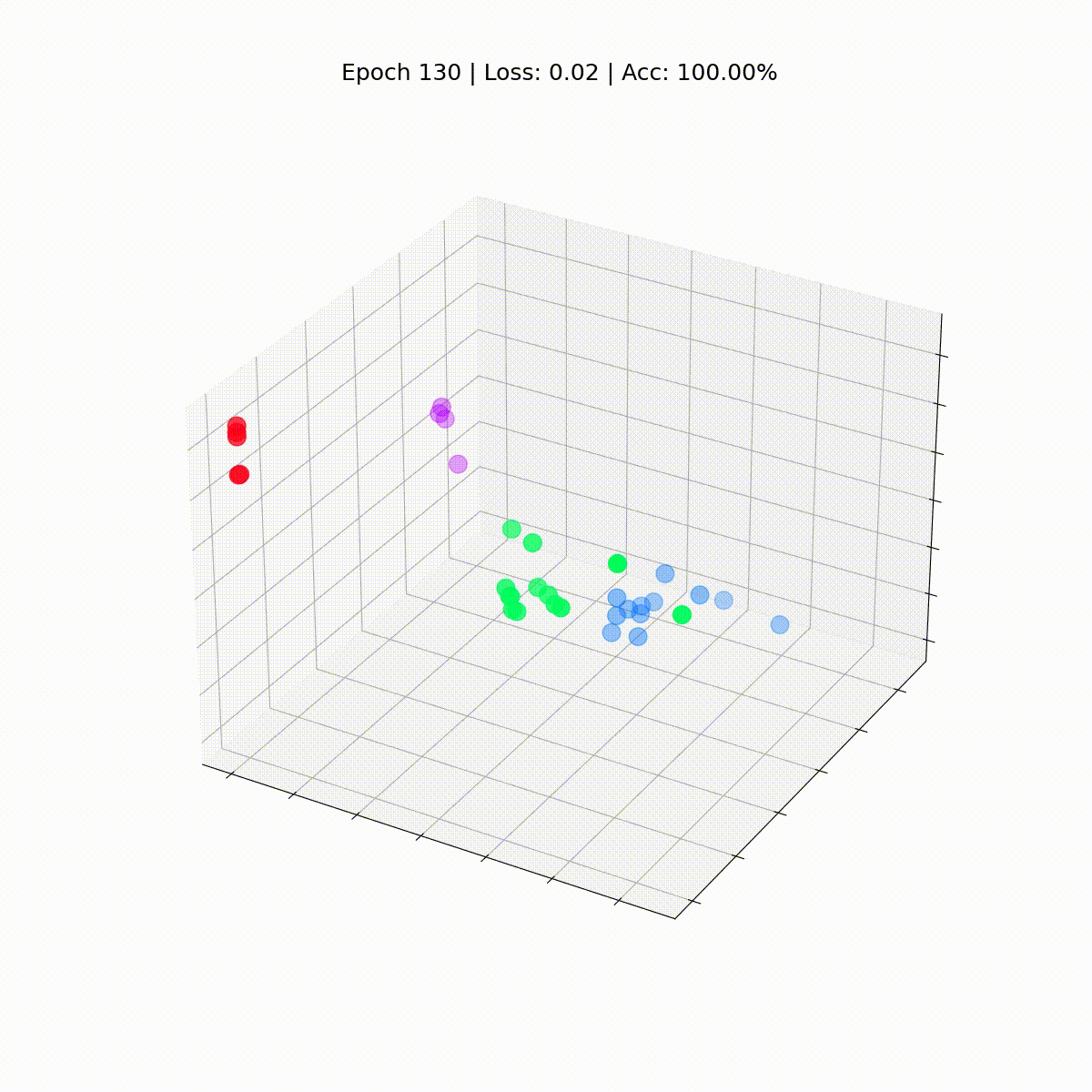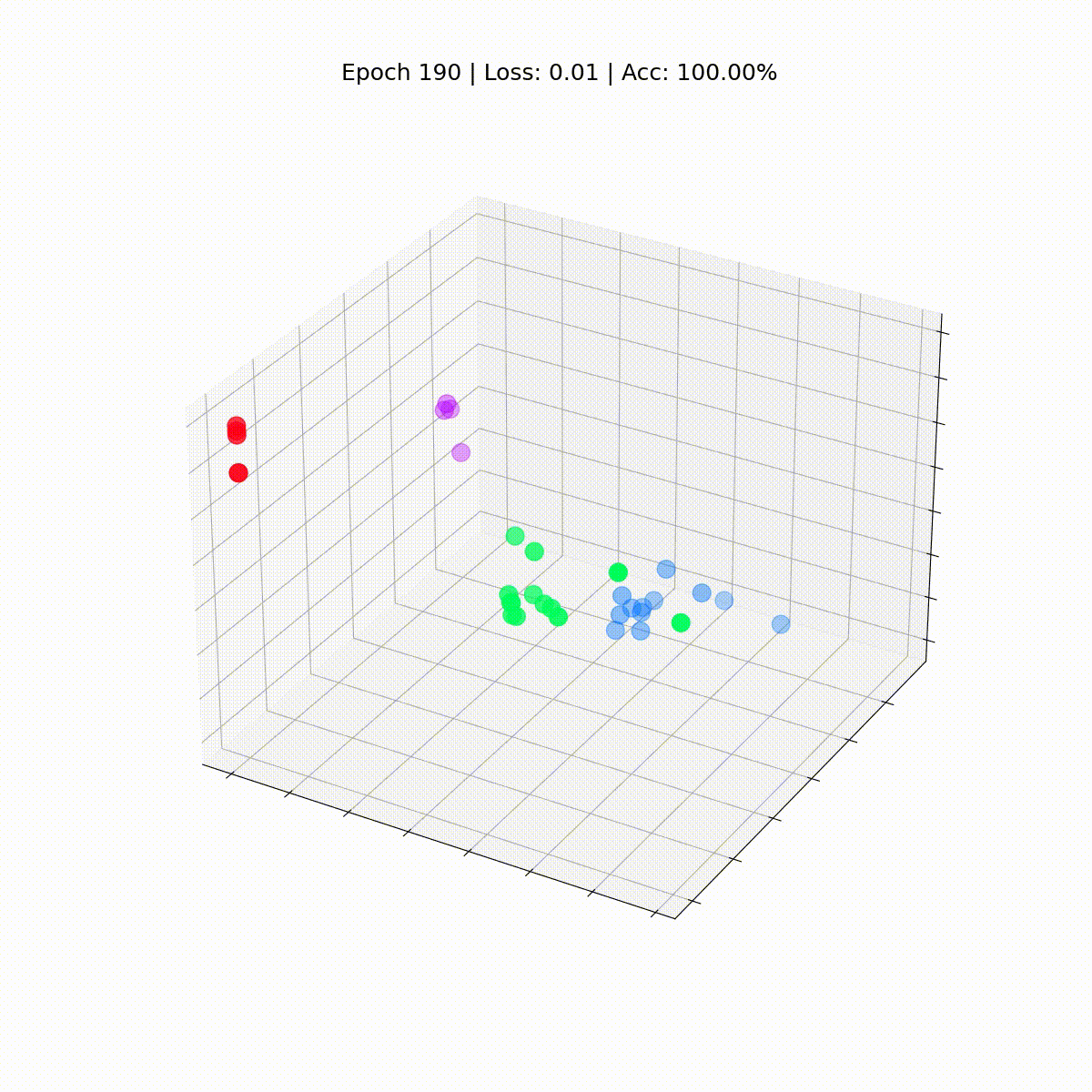
Nuestra Red de Convolución de Grafos (GCN) ha aprendido efectivamente incrustaciones que agrupan nodos similares en clústeres distintos. Esto permite que la capa lineal final los distinga en clases separadas con facilidad.
Las incrustaciones no son exclusivas de las GNN: se pueden encontrar en todas partes del aprendizaje profundo. Tampoco tienen que ser en 3D: de hecho, rara vez lo son. Por ejemplo, los modelos de lenguaje como BERT producen incrustaciones con 768 o incluso 1024 dimensiones.
Dimensiones adicionales almacenan más información sobre nodos, texto, imágenes, etc., pero también crean modelos más grandes que son más difíciles de entrenar. Por eso es ventajoso mantener incrustaciones de baja dimensionalidad el mayor tiempo posible.
Conclusión
Las Redes de Convolución de Grafos son una arquitectura increíblemente versátil que se puede aplicar en muchos contextos. En este artículo, nos familiarizamos con la biblioteca PyTorch Geometric y objetos como Datasets y Data. Luego, reconstruimos con éxito una capa de convolución de gráficos desde cero. A continuación, pusimos la teoría en práctica implementando un GCN, lo que nos dio una comprensión de los aspectos prácticos y cómo interactúan los componentes individuales. Finalmente, visualizamos el proceso de entrenamiento y obtuvimos una perspectiva clara de lo que implica para una red de este tipo.
El club de karate de Zachary es un conjunto de datos simplista, pero es lo suficientemente bueno como para comprender los conceptos más importantes en datos de gráficos y GNN. Aunque solo hablamos de clasificación de nodos en este artículo, hay otras tareas que las GNN pueden realizar: predicción de enlaces (por ejemplo, recomendar un amigo), clasificación de gráficos (por ejemplo, etiquetar moléculas), generación de gráficos (por ejemplo, crear nuevas moléculas), y así sucesivamente.
Más allá del GCN, los investigadores han propuesto numerosas capas y arquitecturas de GNN. En el próximo artículo, presentaremos la arquitectura Graph Attention Network (GAT), que calcula dinámicamente el factor de normalización del GCN y la importancia de cada conexión con un mecanismo de atención.
Si quieres saber más sobre las redes neuronales gráficas, sumérgete más en el mundo de las RGN con mi libro, Hands-On Graph Neural Networks.
Siguiente artículo
Capítulo 2: Redes de Atención en Gráficos: Autoatención Explicada
Una guía para las RGN con autoatención usando PyTorch Geometric
towardsdatascience.com
Aprende más sobre el aprendizaje automático y apoya mi trabajo con un solo clic: conviértete en miembro de VoAGI aquí:
Únete a VoAGI con mi enlace de referencia: Maxime Labonne
Como miembro de VoAGI, una parte de tu cuota de membresía se destina a los escritores que lees y obtienes acceso completo a cada historia…
VoAGI.com
Si ya eres miembro, puedes seguirme en VoAGI.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Aprovechando los LLM con Recuperación de Información Una Demostración Simple
- Cómo acelerar la inferencia hasta 9 veces en una CPU x86 con Pytorch
- Dentro de XGen-Imagen-1 Cómo Salesforce Research construyó, entrenó y evaluó un modelo masivo de texto a imagen.
- Anthropic recibe un impulso de $100 millones de SK Telecom para avanzar en la IA específica de las telecomunicaciones
- Bases de datos de vectores y índices de vectores en Python Arquitectura de aplicaciones LLM
- 4 Recursos Esenciales para Ayudar a Mejorar tus Visualizaciones de Datos
- Traducción de imagen a imagen con CycleGAN




