Reconocimiento del lenguaje hablado en Mozilla Common Voice Transformaciones de audio.
Reconocimiento del lenguaje hablado en Mozilla Common Voice Transformaciones de audio.' -> 'Reconocimiento lenguaje Mozilla Common Voice Transformaciones audio.
Este es el tercer artículo sobre el reconocimiento del lenguaje hablado basado en el conjunto de datos de Mozilla Common Voice. En la Parte I, discutimos la selección de datos y el preprocesamiento de datos, y en la Parte II analizamos el rendimiento de varios clasificadores de redes neuronales.
El modelo final alcanzó una precisión del 92% y una precisión de parejas del 97%. Dado que este modelo sufre de una variabilidad algo alta, la precisión podría mejorar potencialmente al agregar más datos. Una forma muy común de obtener datos adicionales es sintetizarlos realizando diversas transformaciones en el conjunto de datos disponible.
En este artículo, consideraremos 5 transformaciones populares para la ampliación de datos de audio: agregar ruido, cambiar la velocidad, cambiar el tono, enmascaramiento de tiempo y cortar y empalmar.
Puede encontrar el cuaderno de tutorial aquí.
- Conoce a PUG una nueva investigación de IA de Meta AI sobre conjuntos de datos fotorrealistas y semánticamente controlables utilizando Unreal Engine para una evaluación de modelos robusta
- Investigadores de Salesforce presentan XGen-Image-1 un modelo de difusión latente de texto a imagen entrenado para reutilizar varios componentes preentrenados.
- Investigadores de UC Santa Cruz proponen una nueva herramienta de prueba de asociación de texto a imagen que cuantifica los estereotipos implícitos entre conceptos y valencia y los presentes en las imágenes
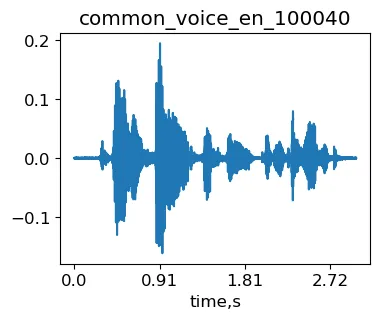
Con fines ilustrativos, utilizaremos la muestra common_voice_en_100040 del conjunto de datos de Mozilla Common Voice (MCV). Esta es la frase “El fuego ardiente había sido extinguido”.
import librosa as lrimport IPythonsignal, sr = lr.load('./transformed/common_voice_en_100040.wav', res_type='kaiser_fast') #cargar señalIPython.display.Audio(signal, rate=sr)Muestra original common_voice_en_100040 de MCV.
Agregar ruido
Agregar ruido es la forma más sencilla de ampliar el audio. La cantidad de ruido se caracteriza por la relación señal-ruido (SNR), que es la relación entre la amplitud máxima de la señal y la desviación estándar del ruido. Generaremos varios niveles de ruido, definidos con SNR, y veremos cómo cambian la señal.
SNRs = (5,10,100,1000) #Relación señal-ruido: amplitud máxima sobre desviación estándar del ruido señal_ruidosa = {}for snr in SNRs: desviacion_estandar_ruido = max(abs(signal))/snr #obtener desviación estándar del ruido ruido = desviacion_estandar_ruido*np.random.randn(len(signal),) #generar ruido con la desviación estándar dada señal_ruidosa[snr] = señal+ruidoIPython.display.display(IPython.display.Audio(señal_ruidosa[5], rate=sr))IPython.display.display(IPython.display.Audio(señal_ruidosa[1000], rate=sr))Señales obtenidas superponiendo ruido con SNR=5 y SNR=1000 en la muestra original common_voice_en_100040 de MCV (generado por el autor).
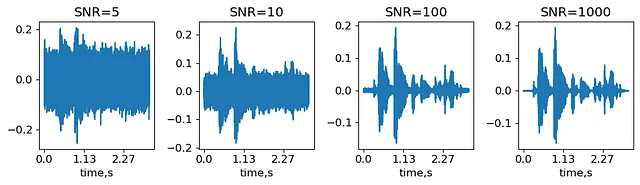
Así, SNR=1000 suena casi como el audio sin alteraciones, mientras que en SNR=5 solo se pueden distinguir las partes más fuertes de la señal. En la práctica, el nivel de SNR es un hiperparámetro que depende del conjunto de datos y del clasificador elegido.
Cambiar la velocidad
La forma más sencilla de cambiar la velocidad es simplemente fingir que la señal tiene una frecuencia de muestreo diferente. Sin embargo, esto también cambiará el tono (cuán bajo/alto en frecuencia suena el audio). Aumentar la frecuencia de muestreo hará que la voz suene más alta. Para ilustrar esto, “aumentaremos” la frecuencia de muestreo para nuestro ejemplo en 1.5:
IPython.display.Audio(señal, rate=sr*1.5)Señal obtenida utilizando una frecuencia de muestreo falsa para la muestra original common_voice_en_100040 de MCV (generado por el autor).
Cambiar la velocidad sin afectar el tono es más desafiante. Se necesita utilizar el algoritmo Phase Vocoder (PV). En resumen, la señal de entrada se divide primero en tramas superpuestas. Luego, se calcula el espectro dentro de cada trama aplicando la Transformada Rápida de Fourier (FFT). La velocidad de reproducción se modifica luego de volver a sintetizar las tramas a una velocidad diferente. Dado que el contenido de frecuencia de cada trama no se ve afectado, el tono permanece igual. El PV interpola entre las tramas y utiliza la información de fase para lograr suavidad.
Para nuestros experimentos, utilizaremos la función de estiramiento de tiempo stretch_wo_loop de esta implementación de PV.
stretching_factor = 1.3
signal_stretched = stretch_wo_loop(signal, stretching_factor)
IPython.display.Audio(signal_stretched, rate=sr)Señal obtenida al variar la velocidad de la muestra original MCV common_voice_en_100040 (generada por el autor).
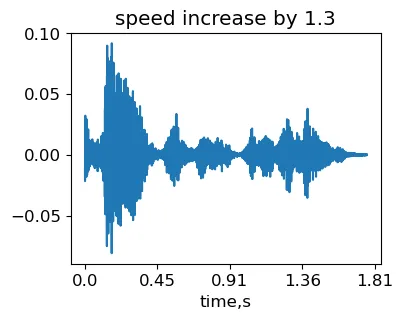
Por lo tanto, la duración de la señal disminuyó ya que aumentamos la velocidad. Sin embargo, se puede escuchar que el tono no ha cambiado. Tenga en cuenta que cuando el factor de estiramiento es considerable, la interpolación de fase entre tramas puede no funcionar bien. Como resultado, pueden aparecer artefactos de eco en el audio transformado.
Cambiando el tono
Para alterar el tono sin afectar la velocidad, podemos usar el mismo estiramiento de tiempo PV pero fingir que la señal tiene una tasa de muestreo diferente de manera que la duración total de la señal permanezca igual:
IPython.display.Audio(signal_stretched, rate=sr/stretching_factor)Señal obtenida al variar el tono de la muestra original MCV common_voice_en_100040 (generada por el autor).
¿Por qué nos molestamos con este PV mientras que librosa ya tiene las funciones time_stretch y pitch_shift? Bueno, estas funciones transforman la señal de vuelta al dominio del tiempo. Cuando necesitas calcular incrustaciones después, perderás tiempo en transformadas de Fourier redundantes. Por otro lado, es fácil modificar la función stretch_wo_loop para que produzca una salida de Fourier sin realizar la transformada inversa. Probablemente también se podría intentar investigar en los códigos de librosa para lograr resultados similares.
Enmascaramiento de tiempo y corte y empalme
Estas dos transformaciones fueron propuestas inicialmente en el dominio de frecuencia (Park et al. 2019). La idea era ahorrar tiempo en la transformada de Fourier utilizando espectros precalculados para las aumentaciones de audio. Para simplificar, demostraremos cómo funcionan estas transformaciones en el dominio del tiempo. Las operaciones enumeradas se pueden transferir fácilmente al dominio de frecuencia reemplazando el eje de tiempo por índices de trama.
Enmascaramiento de tiempo
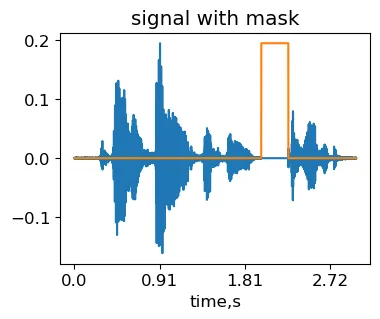
La idea del enmascaramiento de tiempo es cubrir una región aleatoria en la señal. La red neuronal tiene entonces menos posibilidades de aprender variaciones temporales específicas de la señal que no son generalizables.
max_mask_length = 0.3 # duración máxima de la máscara, proporción de la longitud de la señal
L = len(signal)
mask_length = int(L*np.random.rand()*max_mask_length) # elegir aleatoriamente la longitud de la máscara
mask_start = int((L-mask_length)*np.random.rand()) # elegir aleatoriamente la posición de la máscara
masked_signal = signal.copy()
masked_signal[mask_start:mask_start+mask_length] = 0
IPython.display.Audio(masked_signal, rate=sr)Señal obtenida aplicando la transformación de enmascaramiento de tiempo en la muestra original MCV common_voice_en_100040 (generada por el autor).
Corte y empalme
La idea es reemplazar una región seleccionada aleatoriamente de la señal con un fragmento aleatorio de otra señal que tenga la misma etiqueta. La implementación es casi la misma que para el enmascaramiento de tiempo, excepto que se coloca una parte de otra señal en lugar de la máscara.
other_signal, sr = lr.load('./common_voice_en_100038.wav', res_type='kaiser_fast') # cargar segunda señal
max_fragment_length = 0.3 # duración máxima del fragmento, proporción de la longitud de la señal
L = min(len(signal), len(other_signal))
mask_length = int(L*np.random.rand()*max_fragment_length) # elegir aleatoriamente la longitud del fragmento
mask_start = int((L-mask_length)*np.random.rand()) # elegir aleatoriamente la posición del fragmento
synth_signal = signal.copy()
synth_signal[mask_start:mask_start+mask_length] = other_signal[mask_start:mask_start+mask_length]
IPython.display.Audio(synth_signal, rate=sr)Señal sintética obtenida aplicando la transformación de corte y empalme en la muestra original del MCV common_voice_en_100040 (generada por el autor).
La tabla a continuación muestra la precisión del modelo AttNN en el conjunto de validación para cada una de estas transformaciones con valores típicos de parámetros:

Como se puede observar, ninguna de las transformaciones cambió significativamente la precisión de nuestra configuración de reconocimiento de voz basada en MCV. Sin embargo, es posible que estas transformaciones puedan mejorar el rendimiento en otros conjuntos de datos. Por último, al buscar hiperparámetros óptimos, tiene sentido probar estas transformaciones una por una en lugar de una búsqueda aleatoria o en cuadrícula. Después de eso, las transformaciones efectivas se pueden combinar.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Combinando los datos reales y las previsiones en una línea continua en Power BI
- Herramientas de IA para tu equipo de desarrollo ¿Adoptar o no adoptar?
- Una guía para construir modelos de datos en tiempo real con alto rendimiento
- Google AI presenta Visually Rich Document Understanding (VRDU) un conjunto de datos para un mejor seguimiento del progreso de la tarea de comprensión de documentos
- Scikit-Learn vs TensorFlow ¿Cuál elegir?
- Integrando la Medición de la Actividad Cerebral con la Realidad Virtual
- Accediendo a tus datos personales






