Recomendar y filtrar dinámicamente elementos basados en el contexto del usuario en Amazon Personalize
'Recomendar y filtrar elementos en Amazon Personalize basados en el contexto del usuario de manera dinámica.'
Las organizaciones están invirtiendo continuamente tiempo y esfuerzo en desarrollar soluciones de recomendación inteligentes para ofrecer contenido personalizado y relevante a sus usuarios. Los objetivos pueden ser muchos: transformar la experiencia del usuario, generar interacción significativa y aumentar el consumo de contenido. Algunas de estas soluciones utilizan modelos comunes de aprendizaje automático (ML) basados en patrones de interacción históricos, atributos demográficos del usuario, similitudes de productos y comportamiento grupal. Además de estos atributos, el contexto (como el clima, la ubicación, etc.) en el momento de la interacción puede influir en las decisiones de los usuarios al navegar por el contenido.
En esta publicación, mostramos cómo utilizar el tipo de dispositivo actual del usuario como contexto para mejorar la efectividad de las recomendaciones basadas en Amazon Personalize. Además, mostramos cómo utilizar dicho contexto para filtrar dinámicamente las recomendaciones. Aunque esta publicación muestra cómo se puede utilizar Amazon Personalize para un caso de uso de video bajo demanda (VOD), cabe destacar que Amazon Personalize se puede utilizar en múltiples industrias.
¿Qué es Amazon Personalize?
Amazon Personalize permite a los desarrolladores crear aplicaciones impulsadas por el mismo tipo de tecnología de ML utilizada por Amazon.com para recomendaciones personalizadas en tiempo real. Amazon Personalize es capaz de ofrecer una amplia variedad de experiencias de personalización, incluyendo recomendaciones de productos específicos, reordenamiento personalizado de productos y marketing directo personalizado. Además, como un servicio de IA completamente gestionado, Amazon Personalize acelera las transformaciones digitales de los clientes con ML, facilitando la integración de recomendaciones personalizadas en sitios web existentes, aplicaciones, sistemas de marketing por correo electrónico y más.
¿Por qué es importante el contexto?
Utilizar los metadatos contextuales del usuario, como la ubicación, la hora del día, el tipo de dispositivo y el clima, proporciona experiencias personalizadas para los usuarios existentes y ayuda a mejorar la fase de inicio en frío para usuarios nuevos o no identificados. La fase de inicio en frío se refiere al período en el que su motor de recomendación proporciona recomendaciones no personalizadas debido a la falta de información histórica sobre ese usuario. En situaciones en las que existen otros requisitos para filtrar y promocionar elementos (como en noticias y clima), agregar el contexto actual del usuario (temporada o hora del día) ayuda a mejorar la precisión al incluir y excluir recomendaciones.
- 5 Formas de Ganar Dinero con ChatGPT
- Generación segura de imágenes y modelos de difusión con los servicios de moderación de contenido de Amazon AI
- Utilice modelos de base propietarios de Amazon SageMaker JumpStart en Amazon SageMaker Studio.
Tomemos el ejemplo de una plataforma de VOD que recomienda programas, documentales y películas al usuario. Según el análisis del comportamiento, sabemos que los usuarios de VOD tienden a consumir contenido de duración más corta, como sitcoms, en dispositivos móviles, y contenido de mayor duración, como películas, en su televisor o computadora de escritorio.
Visión general de la solución
Ampliando el ejemplo de considerar el tipo de dispositivo del usuario, mostramos cómo proporcionar esta información como contexto para que Amazon Personalize pueda aprender automáticamente la influencia del dispositivo del usuario en sus tipos de contenido preferidos.
Seguimos el patrón de arquitectura mostrado en el siguiente diagrama para ilustrar cómo el contexto puede pasarse automáticamente a Amazon Personalize. La derivación automática del contexto se logra a través de encabezados de Amazon CloudFront que se incluyen en las solicitudes, como una API de REST en Amazon API Gateway que llama a una función de AWS Lambda para recuperar recomendaciones. Consulte el ejemplo de código completo disponible en nuestro repositorio de GitHub. Proporcionamos una plantilla de AWS CloudFormation para crear los recursos necesarios.
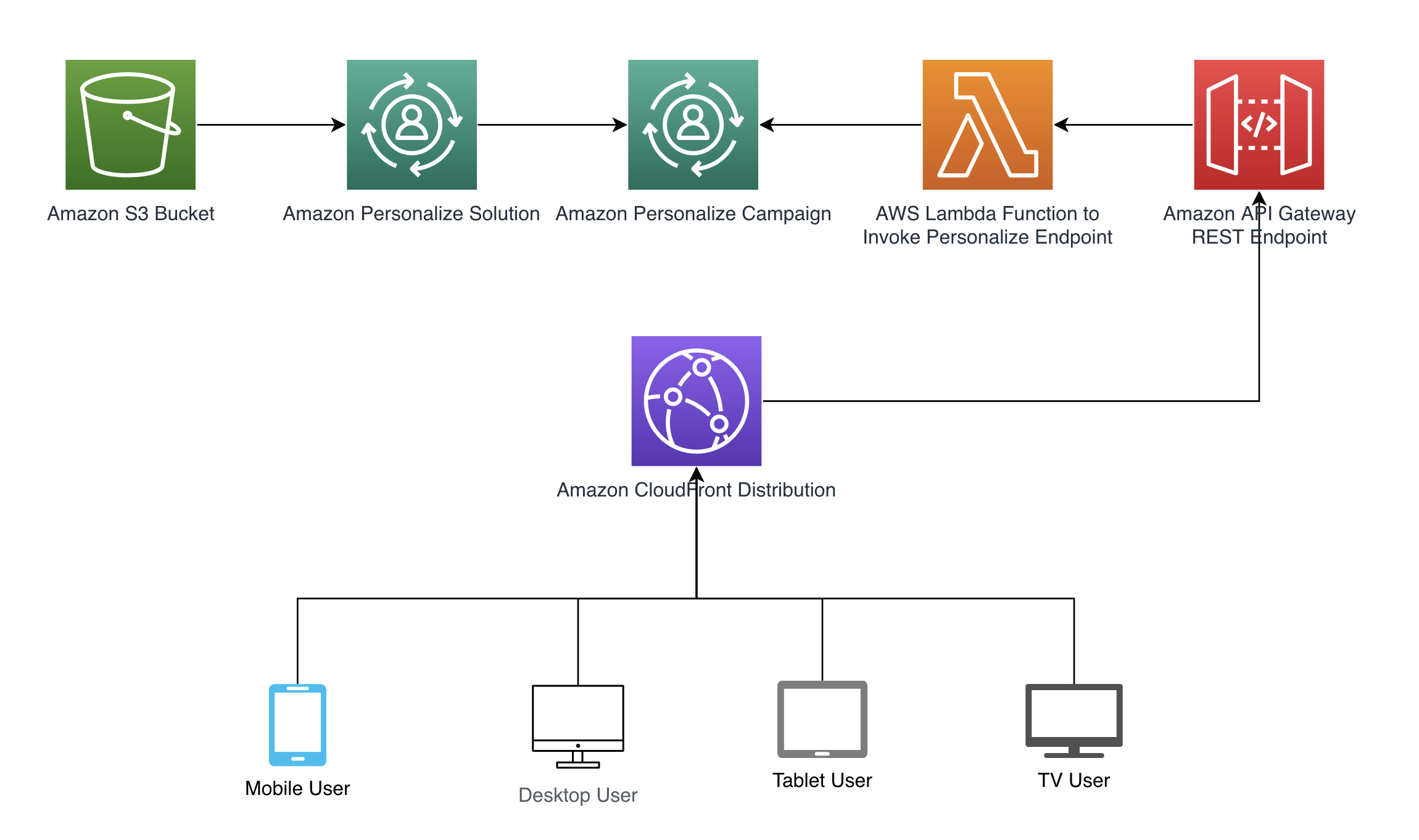
En las secciones siguientes, explicaremos cómo configurar cada paso del patrón de arquitectura de muestra.
Elige una receta
Las recetas son algoritmos de Amazon Personalize preparados para casos de uso específicos. Amazon Personalize proporciona recetas basadas en casos de uso comunes para entrenar modelos. Para nuestro caso de uso, creamos un recomendador personalizado simple de Amazon Personalize utilizando la receta de User-Personalization. Predice los elementos con los que un usuario interactuará en función del conjunto de datos de interacciones. Además, esta receta también utiliza conjuntos de datos de elementos y usuarios para influir en las recomendaciones, si se proporcionan. Para obtener más información sobre cómo funciona esta receta, consulte la receta de User-Personalization.
Crear e importar un conjunto de datos
Aprovechar el contexto requiere especificar valores de contexto con las interacciones para que los recomendadores puedan utilizar el contexto como características durante el entrenamiento de los modelos. También debemos proporcionar el contexto actual del usuario en el momento de la inferencia. El esquema de interacciones (consulte el siguiente código) define la estructura de los datos de interacción históricos y en tiempo real entre usuarios y elementos. Los campos USER_ID, ITEM_ID y TIMESTAMP son requeridos por Amazon Personalize para este conjunto de datos. DEVICE_TYPE es un campo categórico personalizado que agregamos para este ejemplo para capturar el contexto actual del usuario e incluirlo en el entrenamiento del modelo. Amazon Personalize utiliza este conjunto de datos de interacciones para entrenar modelos y crear campañas de recomendación.
{
"type": "record",
"name": "Interacciones",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ID_USUARIO",
"type": "string"
},
{
"name": "ID_ITEM",
"type": "string"
},
{
"name": "TIPO_DISPOSITIVO",
"type": "string",
"categorical": true
},
{
"name": "FECHA_HORA",
"type": "long"
}
],
"version": "1.0"
}De manera similar, el esquema de ítems (ver el siguiente código) define la estructura de los datos del catálogo de productos y videos. Se requiere el ID_ITEM por parte de Amazon Personalize para este conjunto de datos. FECHA_HORA_CREACION es un nombre de columna reservado pero no es requerido. GENERO y PAISES_PERMITIDOS son campos personalizados que estamos agregando para este ejemplo, para capturar el género del video y los países donde se permite reproducir los videos. Amazon Personalize utiliza este conjunto de datos de ítems para entrenar modelos y crear campañas de recomendación.
{
"type": "record",
"name": "Ítems",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ID_ITEM",
"type": "string"
},
{
"name": "GENERO",
"type": "string",
"categorical": true
},
{
"name": "PAISES_PERMITIDOS",
"type": "string",
"categorical": true
},
{
"name": "FECHA_HORA_CREACION",
"type": "long"
}
],
"version": "1.0"
}En nuestro contexto, los datos históricos se refieren al historial de interacciones de los usuarios finales con videos e ítems en la plataforma VOD. Estos datos generalmente se recopilan y almacenan en la base de datos de la aplicación.
Para fines de demostración, utilizamos la biblioteca Faker de Python para generar algunos datos de prueba que simulan el conjunto de datos de interacciones con diferentes ítems, usuarios y tipos de dispositivos durante un período de 3 meses. Después de definir el esquema y la ubicación del archivo de interacciones de entrada, los siguientes pasos son crear un grupo de conjuntos de datos, incluir el conjunto de datos de interacciones dentro del grupo de conjuntos de datos y finalmente importar los datos de entrenamiento en el conjunto de datos, como se ilustra en los siguientes fragmentos de código:
create_dataset_group_response = personalize.create_dataset_group(
name = "personalize-auto-context-demo-grupo-conjunto-datos"
)
create_interactions_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-conjunto-datos-interacciones",
datasetType = 'INTERACTIONS',
datasetGroupArn = arn_grupo_conjunto_datos_interacciones,
schemaArn = arn_esquema_interacciones
)
create_interactions_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-importacion-datos-conjunto",
datasetArn = arn_conjunto_datos_interacciones,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, nombre_archivo_interacciones)
},
roleArn = arn_rol
)
create_items_dataset_response = personalize.create_dataset(
name = "personalize-auto-context-demo-conjunto-datos-items",
datasetType = 'ITEMS',
datasetGroupArn = arn_grupo_conjunto_datos_items,
schemaArn = arn_esquema_items
)
create_items_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = "personalize-auto-context-demo-importacion-datos-items",
datasetArn = arn_conjunto_datos_items,
dataSource = {
"dataLocation": "s3://{}/{}".format(bucket, nombre_archivo_items)
},
roleArn = arn_rol
)Recopilar datos históricos y entrenar el modelo
En este paso, definimos la receta elegida y creamos una solución y una versión de solución haciendo referencia al grupo de conjuntos de datos previamente definido. Cuando se crea una solución personalizada, se especifica una receta y se configuran los parámetros de entrenamiento. Cuando se crea una versión de solución para la solución, Amazon Personalize entrena el modelo que respalda la versión de solución basándose en la receta y la configuración de entrenamiento. Consulta el siguiente código:
arn_receta = "arn:aws:personalize:::recipe/aws-user-personalization"
create_solution_response = personalize.create_solution(
name = "personalize-auto-context-demo-solucion",
datasetGroupArn = arn_grupo_conjunto_datos,
recipeArn = arn_receta
)
create_solution_version_response = personalize.create_solution_version(
solutionArn = arn_solucion
)Crear un punto de conexión de la campaña
Después de entrenar su modelo, lo implementa en una campaña. Una campaña crea y gestiona un punto de conexión de autoescalado para su modelo entrenado que puede usar para obtener recomendaciones personalizadas utilizando la API GetRecommendations. En un paso posterior, usamos este punto de conexión de la campaña para pasar automáticamente el tipo de dispositivo como contexto y recibir recomendaciones personalizadas. Vea el siguiente código:
create_campaign_response = personalize.create_campaign(
name = "personalize-auto-context-demo-campaign",
solutionVersionArn = solution_version_arn
)Crear un filtro dinámico
Cuando obtiene recomendaciones de la campaña creada, puede filtrar los resultados en función de criterios personalizados. Para nuestro ejemplo, creamos un filtro para cumplir con el requisito de recomendar videos que solo se pueden reproducir desde el país actual del usuario. La información del país se pasa de forma dinámica desde la cabecera HTTP de CloudFront.
create_filter_response = personalize.create_filter(
name = 'personalize-auto-context-demo-country-filter',
datasetGroupArn = dataset_group_arn,
filterExpression = 'INCLUDE ItemID WHERE Items.ALLOWED_COUNTRIES IN ($CONTEXT_COUNTRY)'
) Crear una función Lambda
El siguiente paso en nuestra arquitectura es crear una función Lambda para procesar las solicitudes de API que provienen de la distribución de CloudFront y responder invocando el punto de conexión de la campaña de Amazon Personalize. En esta función Lambda, definimos la lógica para analizar las siguientes cabeceras HTTP de la solicitud de CloudFront y los parámetros de cadena de consulta para determinar el tipo de dispositivo del usuario y el ID de usuario, respectivamente:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
El código para crear esta función se implementa a través de la plantilla de CloudFormation.
Crear una API REST
Para que la función Lambda y el punto de conexión de la campaña de Amazon Personalize sean accesibles para la distribución de CloudFront, creamos un punto de conexión de API REST configurado como un proxy de Lambda. API Gateway proporciona herramientas para crear y documentar APIs que enrutan las solicitudes HTTP a funciones Lambda. La característica de integración de proxy de Lambda permite que CloudFront llame a una sola función Lambda abstrayendo las solicitudes al punto de conexión de la campaña de Amazon Personalize. El código para crear esta función se implementa a través de la plantilla de CloudFormation.
Crear una distribución de CloudFront
Cuando creamos una distribución de CloudFront, dado que esta es una configuración de demostración, deshabilitamos el almacenamiento en caché mediante una política de almacenamiento en caché personalizada, asegurando que la solicitud vaya al origen cada vez. Además, usamos una política de solicitud de origen que especifica las cabeceras HTTP y los parámetros de cadena de consulta requeridos que se incluyen en una solicitud de origen. El código para crear esta función se implementa a través de la plantilla de CloudFormation.
Probar recomendaciones
Cuando se accede a la URL de la distribución de CloudFront desde diferentes dispositivos (escritorio, tablet, teléfono, etc.), podemos ver recomendaciones de video personalizadas que son más relevantes para su dispositivo. Además, si se presenta un usuario nuevo, se presentan las recomendaciones adaptadas al dispositivo del usuario. En las siguientes salidas de muestra, los nombres de los videos solo se utilizan para representar su género y duración para que sea comprensible.
En el siguiente código, se presenta a un usuario conocido que ama la comedia según las interacciones pasadas y está accediendo desde un dispositivo móvil con comedias más cortas:
Recomendaciones para el usuario: 460
ITEM_ID GÉNERO PAÍSES_PERMITIDOS
380 Comedia RU|GR|LT|NO|SZ|VN
540 Sitcom US|PK|NI|JM|IN|DK
860 Comedia RU|GR|LT|NO|SZ|VN
600 Comedia US|PK|NI|JM|IN|DK
580 Comedia US|FI|CN|ES|HK|AE
900 Sátira US|PK|NI|JM|IN|DK
720 Sitcom US|PK|NI|JM|IN|DKEl siguiente usuario conocido se presenta con películas de largometraje al acceder desde un dispositivo de Smart TV según las interacciones pasadas:
Recomendaciones para el usuario: 460
ITEM_ID GÉNERO PAÍSES_PERMITIDOS
780 Romance US|PK|NI|JM|IN|DK
100 Terror US|FI|CN|ES|HK|AE
400 Acción US|FI|CN|ES|HK|AE
660 Terror US|PK|NI|JM|IN|DK
720 Terror US|PK|NI|JM|IN|DK
820 Misterio US|FI|CN|ES|HK|AE
520 Misterio US|FI|CN|ES|HK|AEUn usuario frío (desconocido) que accede desde un teléfono se le presentan programas más cortos pero populares:
Recomendaciones para el usuario: 666
ITEM_ID GÉNERO PAÍSES_PERMITIDOS
940 Sátira US|FI|CN|ES|HK|AE
760 Sátira US|FI|CN|ES|HK|AE
160 Sitcom US|FI|CN|ES|HK|AE
880 Comedia US|FI|CN|ES|HK|AE
360 Sátira US|PK|NI|JM|IN|DK
840 Sátira US|PK|NI|JM|IN|DK
420 Sátira US|PK|NI|JM|IN|DKUn usuario frío (desconocido) que accede desde un escritorio se le presentan las mejores películas de ciencia ficción y documentales:
Recomendaciones para el usuario: 666
ITEM_ID GÉNERO PAÍSES_PERMITIDOS
120 Ciencia Ficción US|PK|NI|JM|IN|DK
160 Ciencia Ficción US|FI|CN|ES|HK|AE
680 Ciencia Ficción RU|GR|LT|NO|SZ|VN
640 Ciencia Ficción US|FI|CN|ES|HK|AE
700 Documental US|FI|CN|ES|HK|AE
760 Ciencia Ficción US|FI|CN|ES|HK|AE
360 Documental US|PK|NI|JM|IN|DKEl siguiente usuario conocido que accede desde un teléfono está obteniendo recomendaciones filtradas basadas en la ubicación (EE. UU.):
Recomendaciones para el usuario: 460
ITEM_ID GÉNERO PAÍSES_PERMITIDOS
300 Sitcom US|PK|NI|JM|IN|DK
480 Sátira US|PK|NI|JM|IN|DK
240 Comedia US|PK|NI|JM|IN|DK
900 Sitcom US|PK|NI|JM|IN|DK
880 Comedia US|FI|CN|ES|HK|AE
220 Sitcom US|FI|CN|ES|HK|AE
940 Sitcom US|FI|CN|ES|HK|AEConclusión
En esta publicación, describimos cómo utilizar el tipo de dispositivo del usuario como datos contextuales para que tus recomendaciones sean más relevantes. El uso de metadatos contextuales para entrenar modelos de Amazon Personalize ayudará a recomendar productos relevantes tanto a usuarios nuevos como existentes, no solo a partir de los datos de perfil, sino también de la plataforma de navegación del dispositivo. Además, el contexto como la ubicación (país, ciudad, región, código postal) y el tiempo (día de la semana, fin de semana, día laboral, estación) abre la oportunidad de hacer recomendaciones relacionadas con el usuario. Puedes ejecutar el ejemplo de código completo utilizando la plantilla de CloudFormation proporcionada en nuestro repositorio de GitHub y clonando los cuadernos en Amazon SageMaker Studio.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Cómo Earth.com y Provectus implementaron su infraestructura de MLOps con Amazon SageMaker.
- La IA puede algún día realizar milagros médicos. Por ahora, ayuda a realizar trabajos administrativos.
- Tecnología de IA para Revolucionar la Atención al Paciente
- Fármaco diseñado por inteligencia artificial listo para ensayos en humanos.
- Cómo usar el plugin de Bardeen ChatGPT
- Traje de Realidad Virtual podría ayudarte a ‘sentir’ cosas en el Metaverso.
- Robot utiliza una frambuesa falsa para practicar la recolección de frutas.






