Predicciones en tiempo real de aglomeraciones para los viajeros en tren
'Real-time predictions of crowds for train travelers'
Usando la tecnología Azure serverless para proporcionar predicciones en vivo a nuestra aplicación de planificación de viajes
Con Wessel Radstok

Los viajeros en los Ferrocarriles Holandeses pueden usar la aplicación de la agencia ferroviaria holandesa para planificar su viaje. Mientras planean el viaje, la aplicación muestra una predicción de la aglomeración del tren en cuestión. Esto se muestra en tres categorías: baja ocupación, VoAGI o alta. El viajero puede utilizar esta información para decidir si desea tomar un tren diferente que pueda estar un poco menos lleno.
Estas predicciones se realizan mediante un proceso por lotes. Se entrena regularmente un modelo de aprendizaje automático con datos históricos y cada mañana se ejecuta un proceso para predecir la aglomeración de los trenes en los próximos días. Esto se hace prediciendo cuántos pasajeros se esperan y combinándolo con la capacidad del tren planificado para la ruta.
Sin embargo, durante el día pueden ocurrir incidentes que provoquen la cancelación o desvío de trenes, o puede suceder que se planifique un tren de dos pisos pero solo haya disponible uno de un solo piso. Como resultado, el viajero verá información desactualizada sobre la aglomeración. Alrededor del 20% de los trenes que parten cambian de capacidad el día del viaje, a menudo poco antes de partir.
- Desplegando Falcon-7B en Producción
- Aprendizaje de operadores a través de DeepONet informado por física Vamos a implementarlo desde cero
- Lo que me han enseñado más de 50 entrevistas de Machine Learning (como entrevistador)
En este blog, explicamos cómo construimos un flujo de trabajo de transmisión que toma información en tiempo real sobre la longitud y el tipo de tren que se planea para una ruta y actualiza la aglomeración esperada en la aplicación. Seguimos una arquitectura Lambda donde nuestras predicciones nocturnas implementan la capa por lotes y el proceso de actualización implementa la capa de transmisión. Este flujo de trabajo se está ejecutando actualmente en producción, proporcionando a todos los viajeros de tren en los Países Bajos que utilizan nuestra aplicación una vista más en tiempo real de la aglomeración esperada en su viaje.
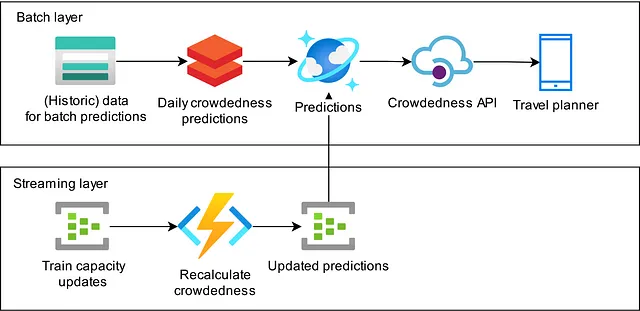
Describimos el enfoque que tomamos para implementar esta arquitectura. Nuestra primera implementación se realizó utilizando Spark Structured Streaming, lo cual no funcionó como esperábamos. Basándonos en nuestra experiencia, que discutiremos, decidimos tomar un enfoque diferente utilizando recursos sin servidor en la nube de Azure.
Primer intento: Spark Structured Streaming
Nuestras predicciones diarias de aglomeración se ejecutan en Databricks utilizando Spark para el procesamiento de datos. Como Spark tiene soporte para el procesamiento de datos en tiempo real, parece una opción lógica implementar las actualizaciones en tiempo real de nuestras predicciones en Spark Structured Streaming. Esta decisión nos dio la ventaja de que la plataforma ya estaba disponible y podíamos implementar la lógica utilizando el paradigma de DataFrame con el cual ya teníamos experiencia.
Iniciamos la implementación con una versión por lotes del modelo que queríamos ejecutar en una versión de transmisión y lo convertimos en una implementación pura de Spark Structured Streaming. Terminamos con un pequeño cuaderno para iniciar el trabajo de transmisión y un paquete personalizado de Python que contenía la lógica que necesitábamos.
Durante el proceso de desarrollo aprendimos algunas cosas sobre la programación utilizando Structured Streaming. En primer lugar, la interfaz de programación de SQL DataFrames y Structured Streaming DataFrames no es la misma. Structured Streaming es mucho más limitado en términos de lo que se puede hacer, lo que significaba que no podíamos implementar el modelo por lotes uno a uno de manera fluida y tuvimos que revisar el algoritmo varias veces para que funcionara. La limitada expresividad de la interfaz de Structured Streaming dio lugar a un código ilegible y, por lo tanto, difícil de mantener.
Un ejemplo simple de esto es que queríamos realizar una unión externa en dos flujos de datos basados en una ventana de tiempo. Sin embargo, Spark Structured Streaming requiere tener una igualdad en la condición de unión y no teníamos dos columnas con los mismos datos. Intentamos agregar dos campos literales con el mismo valor a los dos flujos para la igualdad, pero Spark no es tan fácil de engañar. Terminamos creando un campo “milenario” ya que nuestras marcas de tiempo están todas en el tercer milenio: eso funciona, pero básicamente creamos un error del “Y3K”.
Además, tuvimos que dividir el algoritmo en pasos separados porque teníamos diferentes restricciones de tiempo en diferentes partes del modelo que no podíamos implementar en un solo trabajo de Structured Streaming. Elegimos dividir el modelo en varias partes, acopladas entre sí usando Azure Event Hubs como capa de almacenamiento persistente en el medio. Esto tenía la ventaja de que cada parte del procesamiento tenía un objetivo claro y podía ser probada individualmente.
Probamos nuestro flujo de dos maneras. Para las pruebas unitarias, simplemente tomamos la lógica de transmisión y la alimentamos con DataFrames de Spark SQL en lotes creados a mano para las pruebas. Esto significa que pudimos probar partes del flujo de transmisión sin iniciar realmente un trabajo de transmisión. Este enfoque captura gran parte de los requisitos funcionales, pero no captura problemas de sincronización. El segundo paso de prueba utilizó los sumideros de memoria de Spark Structured Streaming para ejecutar la consulta en modo de transmisión y capturar algunos efectos de sincronización también.
Finalmente, implementamos nuestro código y vimos que nuestra factura en la nube aumentó drásticamente. Identificamos dos razones para esto: en primer lugar, Databricks es una gran solución para trabajos de análisis por lotes, pero es costoso mantenerlo en funcionamiento continuo para trabajos de transmisión. En segundo lugar, la política de seguridad de acceso a datos de nuestro empleador nos obliga a registrar el acceso a los datos. Como el almacén de estado de Structured Streaming puede contener datos, también tuvimos que registrar esto. Sin embargo, el almacén de estado se actualiza con mucha frecuencia y contiene muchos archivos pequeños, lo que genera un conjunto enorme de registros que es costoso de capturar.
Finalmente, decidimos abandonar este enfoque. Nuestros costos en la nube eran demasiado altos para el problema que intentamos abordar. Además, la implementación del modelo era muy difícil de entender y mantener debido a la limitada expresividad de Spark Structured Streaming, lo que nos llevó a la conclusión de que no queríamos invertir más para mejorar este enfoque, sino ver si podíamos abordarlo de manera diferente.
Rediseño utilizando tecnologías sin servidor
Observando que muchas partes del flujo no requieren estado, llegamos a un sistema que utiliza Azure Functions como plataforma de cómputo para que cada mensaje pueda ser manejado por separado. Cuando se necesita estado, usamos Stream Analytics. Esto nos permite comparar mensajes, reproducir mensajes o unirlos con otro flujo. Para permitir un acceso rápido a los datos auxiliares, utilizamos una base de datos de Cosmos. Aún utilizamos Azure Event Hubs para unir todas las partes.

Azure Functions
Azure Functions es un método fácil para aplicar operaciones a un flujo de eventos. Se invocan por separado para cada evento en el flujo, lo que facilita razonar sobre la lógica empresarial. Tienen soporte nativo para Python, lo que facilita escribir operaciones mantenibles. Debido a que la plataforma gestiona toda la puesta en marcha de conectividad en la nube, se pueden desarrollar y probar fácilmente en un entorno local. Los utilizamos en varias partes del flujo:
- Algunas funciones simplemente filtran los mensajes entrantes, reduciendo la carga de cómputo de los pasos posteriores y, por lo tanto, reduciendo la capacidad y el costo;
- Varias funciones enriquecen los mensajes uniéndolos con otras fuentes de datos disponibles, por ejemplo, en Cosmos DB;
- Otras funciones transforman el mensaje de un formato a, por ejemplo, el formato de salida final;
- Finalmente, utilizamos Azure Functions para ingresar datos desde la capa por lotes a la capa de transmisión.
Filtrado, enriquecimiento y transformaciones
Las funciones que realizan estos pasos son código Python sencillo. Como ejemplo, la parte principal de la función de filtrado es solo unas pocas líneas:
def main(event: func.EventHubEvent, evh: func.Out[bytes]) -> None: """ Filtra mensajes para enviar solo los mensajes relevantes para nuestro flujo de transmisión. """ message = json.loads(event.get_body().decode("utf-8")) if _is_ns_operator(message): message = _remove_keys(message) message = _add_build_id(message) evh.set(str.encode(json.dumps(message)))Lista 1: Ejemplo de código de función de Azure que filtra y transforma mensajes.
Aquí, tomamos cada mensaje, filtramos solo los mensajes relacionados con los trenes que opera nuestra empresa y eliminamos claves (campos de datos) del mensaje en los que no estamos interesados. Finalmente, agregamos una identificación de compilación al mensaje para tener información de seguimiento con fines de depuración. Para el lector interesado, la cadena JSON se codifica como un objeto de bytes usando str.encode(). Si se envía una cadena regular al Event Hub, se imprime de forma legible automáticamente, lo que introduce mucho espacio en blanco en el mensaje. Un objeto de bytes se envía sin cambios.
Ingestión de datos en una base de datos Cosmos rápida
Para volver a calcular la aglomeración de trenes, se requiere acceso rápido al número predicho de viajeros en el tren, la capacidad del nuevo material rodante y los límites de clasificación baja, VoAGI y alta. Estos datos se generan diariamente como parte de nuestro proceso por lotes y se escriben en nuestro lago de datos en formato parquet. Cargar estos datos desde el lago de datos para cada acción de recálculo es demasiado lento. Utilizamos Azure Cosmos Database como almacén de clave-valor para hacer que los datos estáticos necesarios estén disponibles con baja latencia para las funciones de Azure que recalculan la aglomeración de trenes.
El escenario ideal es que activemos la ingestión desde nuestro proceso por lotes nocturno y también podamos recibir si la ingestión tuvo éxito o falló. El proceso de ingestión también debe poder leer archivos parquet con tipos complejos, lo cual no es compatible con la actividad de copia de Azure Data Factory. Nuestra solución fue aprovechar las Azure Durable Functions. Esta es una extensión de la plataforma estándar de Azure Functions que permite funciones con estado y de larga duración. Específicamente, las funciones duraderas admiten webhooks que nos permiten comunicar de vuelta si la ingestión tuvo éxito al orquestador.
La ingestión funciona de la siguiente manera. Nuestro proceso por lotes nocturno activa una función duradera. Esta función duradera selecciona la Función de Actividad correcta para la fuente de datos que debe ser ingestada y activa esta Actividad para cada archivo parquet disponible. Luego utilizamos pandas para leer cada archivo, realizar algunas transformaciones simples y insertar los registros en la base de datos Cosmos en forma masiva. La función duradera realiza un seguimiento automático de cualquier falla y volverá a intentar esa función.
Azure Stream Analytics
Algunas operaciones no se pueden realizar fácilmente con Azure Functions. Esto es especialmente cierto para operaciones con estado o para operaciones que combinan mensajes en ventanas de tiempo.
Nuestras predicciones diarias de aglomeración se realizan en un proceso por lotes que no calcula las predicciones de manera instantánea. Toma tiempo, tiempo durante el cual pueden producirse nuevas actualizaciones en la capacidad del tren. Si eso sucede, deseamos actualizar la aglomeración dos veces: primero en la predicción anterior más reciente y luego en las nuevas predicciones cuando estén disponibles. Aquí utilizamos Azure Stream Analytics para mantener el estado de los mensajes de actualización y reproducirlos desde una marca de tiempo determinada cuando hay una nueva predicción por lotes disponible.
Las consultas de Azure Stream Analytics se escriben en un dialecto SQL. Es relativamente sencillo implementar transformaciones. Sin embargo, se deben tener precauciones cuando la velocidad de transferencia de mensajes debe ser alta. En nuestro caso, una implementación directa no pudo mantenerse al día con el flujo de entrada y tuvimos que asegurarnos de que la consulta de análisis de transmisión pudiera ejecutarse de manera paralela de forma embarazosa.
Las consultas embarazosamente paralelas tienen algunos requisitos y limitaciones. Deben procesar datos particionados y deben realizar operaciones con estado (por ejemplo, uniones) contenidas dentro de una partición. Esto significa que, al unir dos flujos de Event Hub, deben tener el mismo número de particiones y los datos de la partición 1 en el primer Event Hub solo se pueden unir a los datos de la partición 1 en el segundo.
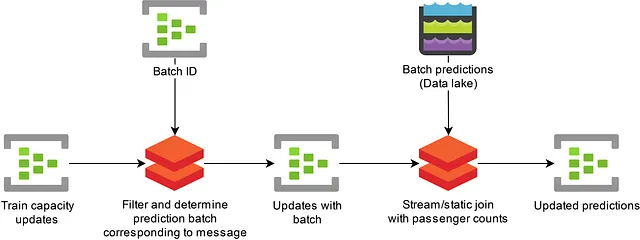
Para solucionar esto, duplicamos algunos de nuestros datos en varias particiones de Event Hub e implementamos esencialmente una operación de unión de transmisión. Ilustramos esto en la siguiente consulta. Aquí, a cada una de nuestras predicciones de aglomeración se le asigna un ID por lotes y una hora de inicio de lote que se utiliza para decidir qué mensaje de actualización de capacidad de tren es aplicable a qué predicción. Un mensaje puede ser aplicable a múltiples predicciones si el mensaje llega durante el cálculo de un nuevo conjunto de predicciones). En este caso, se generan múltiples mensajes. Cada ID de lote se duplica en múltiples particiones de Event Hub.
SELECT batchid.batch_id, batchid.batch_start_time, event.message, event.message_timestamp INTO [Target]FROM [SourceData] event TIMESTAMP BY event.message_timestamp PARTITION BY PartitionId JOIN [BatchId] batchid TIMESTAMP BY batchid.EventEnqueuedUtcTime PARTITION BY PartitionId ON -- Unir si el mensaje del ID de lote fue recibido antes del mensaje (DATEDIFF positivo) y -- volver a reproducir cuando se recibió un mensaje del ID de lote después del mensaje (DATEDIFF negativo), -- pero solo si el mensaje se encoló después de la hora de inicio del lote. -- Para permitir una rápida reingestión de datos, descartamos mensajes que ya no son válidos para el lote. DATEDIFF(HOUR, batchid, event) BETWEEN - 24 AND 24 AND CAST(batchid.batch_start_time AS datetime) <= CAST(event.message_timestamp AS datetime) AND CAST(event.message.valid_until AS datetime) >= CAST(batchid.batch_start_time AS datetime) AND event.PartitionId = batchid.PartitionIdListing 2: Ejemplo de consulta de Azure Stream Analytics que agrega el ID de lote correspondiente a cada mensaje.
Pruebas de integración de extremo a extremo
Desde el compromiso inicial del proyecto, decidimos realizar pruebas automatizadas de integración de extremo a extremo en el flujo de transmisión. Estas pruebas se realizaron sembrando el Event Hubs de entrada con mensajes de muestra que generamos, y luego validando los mensajes creados en los Event Hubs de salida. También incluimos la ingestión de la base de datos Cosmos en este flujo de prueba de integración. Hacer que estas pruebas sean parte de nuestra implementación continua nos dio una gran confianza al realizar cambios a medida que aumentaba el número de componentes en el flujo y aumentaba la complejidad.
Conclusiones y aprendizajes clave
En nuestra búsqueda por brindar a los viajeros de tren las últimas ideas sobre la aglomeración de pasajeros, incluso en situaciones en las que ocurren cambios en el servicio de trenes, adoptamos una arquitectura lambda para actualizar nuestras previsiones cuando cambia la capacidad del tren.
Nuestra implementación inicial utilizando Spark Structured Streaming no funcionó como se esperaba, por lo que cambiamos a una arquitectura sin servidor utilizando Azure Event Hubs, Azure Functions, Azure Stream Analytics y Azure Cosmos DB.
Los principales beneficios de este enfoque incluyen:
- Como desarrollador, tienes control: es claro qué partes funcionan mal y qué partes tienen los costos más altos;
- En contraste con Spark Structured Streaming, el código Python puro en Azure Functions es legible, mantenible y expresivo;
- Las Azure Functions son económicas para operaciones sin estado;
- El análisis de transmisión de Azure es la parte más costosa y solo debe usarse donde sea necesario (operaciones con estado o ventanas de tiempo);
- La nueva solución redujo significativamente los costos de infraestructura en la nube.
Las principales desventajas son:
- El uso de componentes desacoplados como Azure Functions y Azure Cosmos DB puede generar condiciones de carrera si el diseño no se considera muy bien;
- Hay muchos elementos de infraestructura y pequeños fragmentos de código para administrar: la lógica no está concentrada en un solo lugar y requiere pruebas más extensas.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Fundamentos de la detección de anomalías con distribución gaussiana multivariante
- Aprendizaje automático de efectos mixtos para variables categóricas de alta cardinalidad – Parte I una comparación empírica de diferentes métodos.
- Aprendiendo el lenguaje de las moléculas para predecir sus propiedades
- Anunciando el primer Desafío de Desaprendizaje Automático
- ‘Mi aplicación 3D favorita’ Fanático de Blender comparte su escena inspirada en Japón esta semana ‘En el NVIDIA Studio’
- 10 millones se registran en la aplicación rival de Twitter de Meta, Threads.
- Las ventas de automóviles nuevos despegan a medida que se alivia la escasez de chips.



