¿De quién es la responsabilidad de hacer que la IA generativa sea correcta?
¿Quién es responsable de la IA generativa correcta?

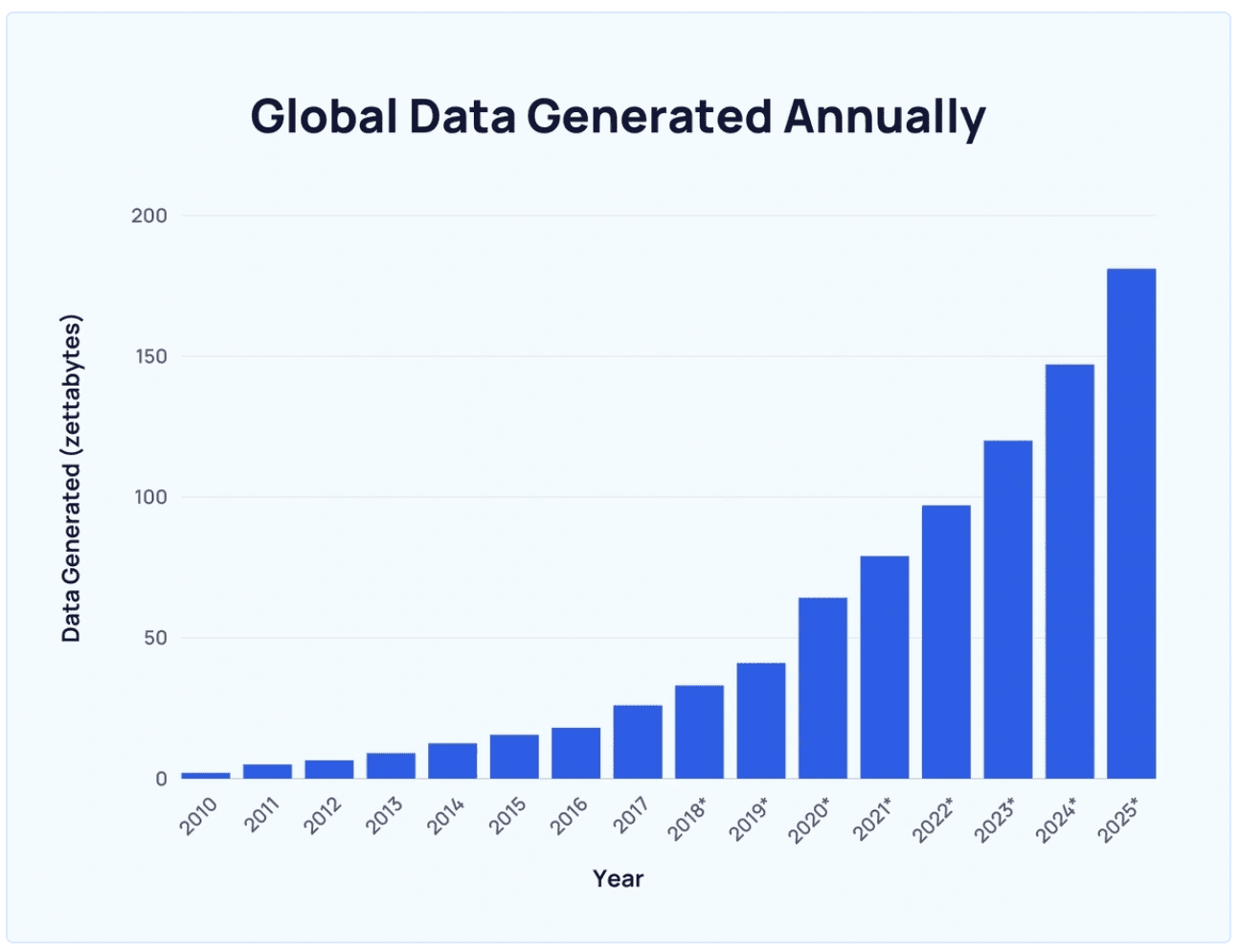
La tasa a la que se ha creado los datos en los últimos años ha sido exponencial, lo que principalmente significa la proliferación creciente del mundo digital.
Se estima que el 90% de los datos del mundo se generaron en los últimos dos años solamente.
Cuanto más interactuamos con Internet en formas variadas, como enviar mensajes de texto, compartir videos o crear música, contribuimos al conjunto de datos de entrenamiento que alimenta las tecnologías de AI generativas (GenAI).
- California acaba de abrir las compuertas para los coches autónomos
- Descifrando los misterios de los modelos de lenguaje grandes un análisis detallado de las funciones de influencia y su escalabilidad
- Google presenta Project IDX un paraíso para desarrolladores basado en navegador impulsado por IA.
En principio, nuestros datos se utilizan como entrada en estos algoritmos de AI avanzados que aprenden y generan nuevos datos.
El Otro Lado de GenAI
No hace falta decir que suena intrigante al principio, pero comienza a plantear riesgos en varias formas a medida que la realidad comienza a establecerse.
El otro lado de estos desarrollos tecnológicos pronto abre la caja de Pandora de problemas en forma de desinformación, mal uso, peligros de información, deep fakes, emisiones de carbono y muchos más.
Además, es crucial tener en cuenta el impacto de estos modelos en la eliminación de muchos trabajos.
Según el informe reciente de McKinsey “Generative AI y el futuro del trabajo en Estados Unidos”, los trabajos que implican una alta proporción de tareas repetitivas, recopilación de datos y procesamiento elemental de datos corren un mayor riesgo de volverse obsoletos.
El informe cita la automatización, incluida GenAI, como una de las razones detrás de la disminución de la demanda de habilidades cognitivas y manuales básicas.
Además, una preocupación vital que ha persistido desde la era anterior a GenAI y continúa planteando desafíos es la privacidad de los datos. Los datos, que constituyen el núcleo de los modelos de GenAI, se recopilan de Internet, lo que incluye una parte fraccionada de nuestras identidades.

Se afirma que un modelo de lenguaje de aprendizaje profundo (LLM) ha sido entrenado con alrededor de 300 mil millones de palabras con datos extraídos de Internet, incluidos libros, artículos, sitios web y publicaciones. Lo preocupante es que no éramos conscientes de su recopilación, consumo y uso todo este tiempo.
MIT Technology Review considera “casi imposible que OpenAI cumpla con las normas de protección de datos”.
¿Es el Código Abierto la Solución?
Dado que todos somos contribuyentes fraccionales a estos datos, se espera que el algoritmo sea de código abierto y transparente para que todos lo entiendan.
Mientras que los modelos de acceso abierto proporcionan detalles sobre el código, los datos de entrenamiento, los pesos del modelo, la arquitectura y los resultados de evaluación, básicamente todo lo que necesitas saber.

Pero, ¿podríamos entender la mayoría de nosotros? Probablemente no.
Esto da lugar a la necesidad de compartir estos detalles vitales en el foro adecuado, un comité de expertos que incluya a responsables políticos, profesionales y gobiernos.
Este comité será capaz de decidir lo que es mejor para la humanidad, algo que ningún grupo, gobierno u organización individual puede decidir hoy en día.
Debe considerar el impacto en la sociedad como una alta prioridad y evaluar el efecto de GenAI desde diversos puntos de vista, sociales, económicos, políticos y más allá.
La Gobernanza No Impide la Innovación
Dejando a un lado el componente de datos, los desarrolladores de estos modelos colosales realizan grandes inversiones para proporcionar la potencia informática necesaria para construirlos, por lo que es su prerrogativa mantenerlos de acceso cerrado.
La naturaleza misma de hacer inversiones implica que desean obtener un retorno de esas inversiones utilizándolas con fines comerciales. Ahí es donde comienza la confusión.
Tener un organismo de gobierno que regule el desarrollo y lanzamiento de aplicaciones impulsadas por AI no inhibe la innovación o obstaculiza el crecimiento empresarial.
En cambio, su objetivo principal es establecer límites y políticas que faciliten el crecimiento empresarial a través de la tecnología al tiempo que promueven un enfoque más responsable.
Entonces, ¿quién decide el coeficiente de responsabilidad y cómo se forma ese organismo de gobierno?
Necesidad de un Foro Responsable
Debería haber una entidad independiente formada por expertos en investigación, academia, empresas, formuladores de políticas y gobiernos/países. Para aclarar, independiente significa que sus fondos no deben ser patrocinados por ningún actor que pueda causar un conflicto de intereses.
Su única agenda es pensar, racionalizar y actuar en nombre de los 8 mil millones de personas en este mundo y tomar decisiones basadas en estándares de alta responsabilidad.
Ahora, eso es una afirmación importante, lo que significa que el grupo debe estar enfocado al máximo y tratar la tarea encomendada como lo más importante. Nosotros, el mundo, no podemos permitir que los tomadores de decisiones trabajen en una misión tan crítica como algo secundario o como un proyecto paralelo, lo que también significa que deben estar bien financiados.
El grupo tiene la tarea de ejecutar un plan y una estrategia que pueda abordar los daños sin comprometer la realización de los beneficios de la tecnología.
Ya lo Hemos Hecho Antes
La IA a menudo se ha comparado con la tecnología nuclear. Sus desarrollos de vanguardia han dificultado predecir los riesgos que conlleva.
Citando a Rumman de Wired sobre cómo se formó el Organismo Internacional de Energía Atómica (OIEA): un organismo independiente libre de afiliación gubernamental y corporativa que brinda soluciones a las ramificaciones de alcance mundial y capacidades aparentemente infinitas de las tecnologías nucleares.
Por lo tanto, tenemos ejemplos de cooperación global en el pasado donde el mundo se ha unido para poner orden en el caos. Sé con certeza que llegaremos a ese punto en algún momento. Pero es crucial converger y establecer las pautas lo antes posible para mantenernos al día con el rápido ritmo de implementaciones.
La humanidad no puede permitirse tomar medidas voluntarias de las empresas, esperando un desarrollo y despliegue responsable por parte de las empresas tecnológicas. Vidhi Chugh es una estratega de IA y líder de transformación digital que trabaja en la intersección de productos, ciencias e ingeniería para construir sistemas escalables de aprendizaje automático. Es una líder galardonada en innovación, autora y conferencista internacional. Su misión es democratizar el aprendizaje automático y romper la jerga para que todos puedan formar parte de esta transformación.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 10 Casos de uso notables de IA en la fabricación
- Redefiniendo la robótica la innovadora solución de visión por computadora de la Universidad de Purdue
- Los científicos de datos necesitan especializarse para sobrevivir al invierno tecnológico
- Una guía para científicos de datos para crear y utilizar makefiles
- Una guía para mejorar el rendimiento de tus juegos en máquinas virtuales
- La IA generativa toma protagonismo en la conferencia Ai4 2023
- La adquisición de tierras de LLM cómo AWS, Azure y GCP están luchando por la IA






