¿Por qué y qué es la ingeniería de características en el aprendizaje automático?
¿Qué es la ingeniería de características en el aprendizaje automático?
Transformación y selección de datos para el aprendizaje automático
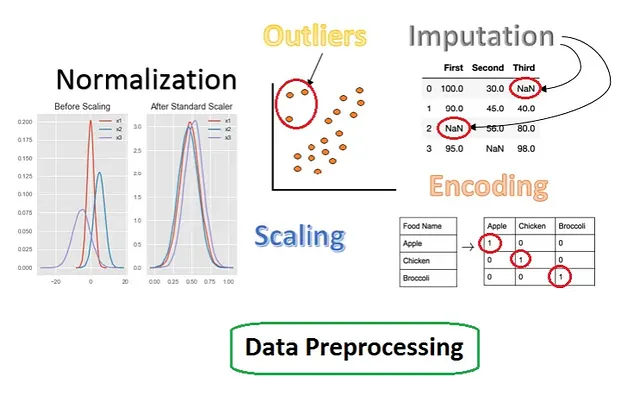
Introducción
Es un proceso de transformación y selección o extracción de características para crear datos mejorados para un modelo de aprendizaje automático. Depende de la persona especializada en ciencia de datos manejar y mejorar los datos para obtener un buen modelo. Diferentes personas pueden tener enfoques diferentes, pero casi todos pasan por técnicas de ingeniería de características. En este artículo, discutiremos diferentes técnicas en ingeniería de características.
La ingeniería de características consta de cuatro partes:
- Transformación de características
- Construcción de características
- Selección de características
- Extracción de características
Este artículo de la Parte 1 discutirá la Transformación de características y sus diferentes técnicas.
Transformación de características
Los métodos y técnicas son el enfoque más utilizado para realizar el preprocesamiento de datos antes de proporcionarlos al modelo. Estos procesos incluyen imputación de datos faltantes, escalado, codificación, detección de valores atípicos, etc.
Escalado:
Este método se utiliza cuando hay variaciones en los números de los datos. Supongamos que en una columna de entrada los valores son muy bajos y en otra columna de entrada los valores son muy altos, por lo que existe la posibilidad de que el modelo se desvíe de un buen rendimiento. Las columnas con valores más grandes dominan en el aprendizaje del modelo y el modelo dará menos importancia a otras características.
Puntos clave:
- Es deseable realizar el escalado después de la división de entrenamiento y prueba.
- Si realizamos el escalado después de otras transformaciones, es posible obtener un mejor rendimiento del modelo.
Tipos de escalado:
- Estandarización:
- En este tipo de escalado, los valores se ajustan a la media y la desviación estándar. Los puntos de datos recién transformados tendrán una media de cero y una desviación estándar de uno.
- Cuando usamos la biblioteca “scalar” en sklearn, devuelve una matriz numpy de una columna recién transformada, pero las necesitamos en un marco de datos.
- Úselo cuando no haya idea de qué modelo aplicar.
We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ¿Cómo puedes mejorar tus métricas y proceso de pronóstico sin algoritmos sofisticados?
- Depuración y Mejora de las Respuestas de ChatGPT 🧐
- Utilizando datos e inteligencia artificial para rastrear el progreso hacia los Objetivos Globales de las Naciones Unidas
- IA generativa y agentes multimodales en AWS La clave para desbloquear nuevo valor en los mercados financieros
- Fetch reduce la latencia de procesamiento de ML en un 50% utilizando Amazon SageMaker y Hugging Face
- Rocket Money x Hugging Face Escalando modelos de aprendizaje automático volátiles en producción
- Conoce al Omnívoro Diseñador Industrial combina el Arte y el OpenUSD para crear Activos 3D para el Entrenamiento de IA





