Más pequeño es mejor Q8-Chat, una experiencia eficiente de IA generativa en Xeon
Q8-Chat es una eficiente experiencia de IA generativa en Xeon, donde lo más pequeño es mejor.
Los modelos de lenguaje grandes (LLM) están revolucionando el mundo del aprendizaje automático. Gracias a su arquitectura Transformer, los LLM tienen una capacidad sorprendente para aprender a partir de grandes cantidades de datos no estructurados, como texto, imágenes, video o audio. Se desempeñan muy bien en muchos tipos de tareas, ya sean extractivas, como la clasificación de texto, o generativas, como la generación de resúmenes de texto y texto a imagen.
Como su nombre lo indica, los LLM son modelos grandes que a menudo superan los 10 mil millones de parámetros. Algunos tienen más de 100 mil millones de parámetros, como el modelo BLOOM. Los LLM requieren mucha potencia informática, que generalmente se encuentra en GPUs de alta gama, para predecir lo suficientemente rápido para casos de uso de baja latencia, como la búsqueda o aplicaciones de conversación. Desafortunadamente, para muchas organizaciones, los costos asociados pueden ser prohibitivos y dificultan el uso de LLM de última generación en sus aplicaciones.
En esta publicación, discutiremos técnicas de optimización que ayudan a reducir el tamaño y la latencia de inferencia de los LLM, lo que les permite ejecutarse eficientemente en CPUs de Intel.
Una introducción a la cuantización
Los LLM generalmente se entrenan con parámetros de punto flotante de 16 bits (también conocidos como FP16/BF16). Por lo tanto, almacenar el valor de un solo peso o valor de activación requiere 2 bytes de memoria. Además, la aritmética de punto flotante es más compleja y más lenta que la aritmética de enteros y requiere más potencia informática.
- Deduplicación a gran escala detrás de BigCode
- 🐶Safetensors auditados como realmente seguros y convirtiéndose en la opción predeterminada
- Hugging Face y IBM se unen en watsonx.ai, el estudio empresarial de próxima generación para desarrolladores de IA.
La cuantización es una técnica de compresión de modelos que tiene como objetivo resolver ambos problemas al reducir el rango de valores únicos que pueden tomar los parámetros del modelo. Por ejemplo, puede cuantizar modelos a una precisión más baja, como enteros de 8 bits (INT8), para reducir su tamaño y reemplazar las operaciones de punto flotante complejas con operaciones de enteros más simples y rápidas.
En pocas palabras, la cuantización reescala los parámetros del modelo a rangos de valores más pequeños. Cuando tiene éxito, reduce el tamaño de su modelo al menos 2 veces, sin ningún impacto en la precisión del modelo.
Puede aplicar la cuantización durante el entrenamiento, también conocido como entrenamiento consciente de la cuantización (QAT), que generalmente produce los mejores resultados. Si prefiere cuantizar un modelo existente, puede aplicar la cuantización posterior al entrenamiento (PTQ), una técnica mucho más rápida que requiere muy poca potencia informática.
Existen diferentes herramientas de cuantización disponibles. Por ejemplo, PyTorch tiene soporte incorporado para la cuantización. También puede utilizar la biblioteca Optimum Intel de Hugging Face, que incluye APIs fáciles de usar para QAT y PTQ.
Cuantización de LLMs
Estudios recientes [1] [2] muestran que las técnicas de cuantización actuales no funcionan bien con LLMs. En particular, los LLMs muestran valores atípicos de gran magnitud en canales de activación específicos en todas las capas y tokens. Aquí hay un ejemplo con el modelo OPT-13B. Puede ver que uno de los canales de activación tiene valores mucho más grandes que todos los demás en todos los tokens. Este fenómeno es visible en todas las capas de Transformer del modelo.
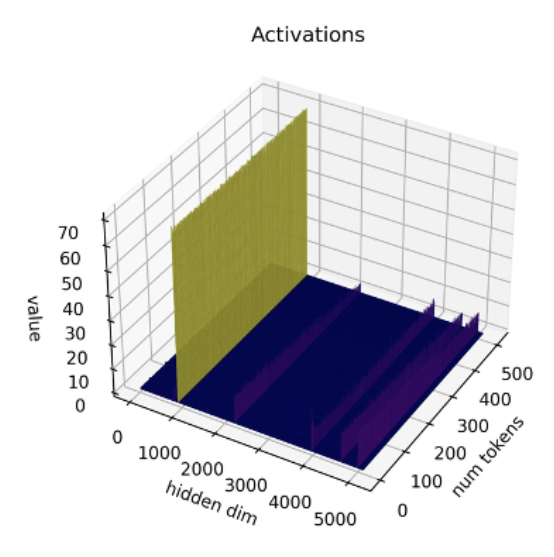 *Fuente: SmoothQuant*
*Fuente: SmoothQuant*
Las mejores técnicas de cuantización hasta la fecha cuantizan las activaciones token por token, lo que provoca valores atípicos truncados o activaciones de baja magnitud que se desbordan. Ambas soluciones afectan significativamente la calidad del modelo. Además, el entrenamiento consciente de la cuantización requiere un entrenamiento adicional del modelo, lo cual no es práctico en la mayoría de los casos debido a la falta de recursos informáticos y datos.
SmoothQuant [3] [4] es una nueva técnica de cuantización que resuelve este problema. Aplica una transformación matemática conjunta a los pesos y activaciones, lo que reduce la relación entre valores atípicos y valores no atípicos para las activaciones a costa de aumentar la relación para los pesos. Esta transformación hace que las capas del Transformer sean “amigables para la cuantización” y permite la cuantización de 8 bits sin afectar la calidad del modelo. Como consecuencia, SmoothQuant produce modelos más pequeños y rápidos que se ejecutan bien en plataformas de CPU de Intel.
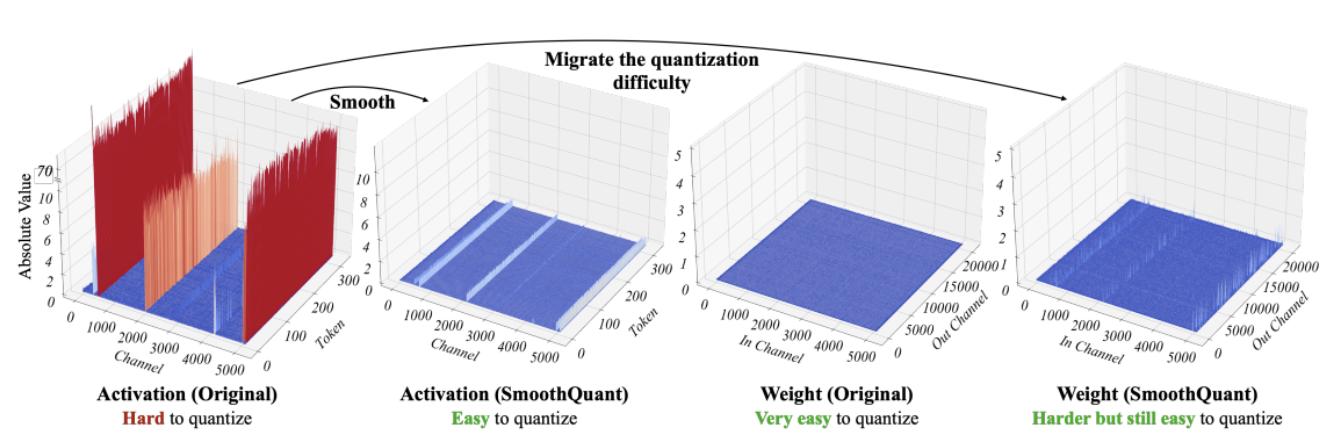 *Fuente: SmoothQuant*
*Fuente: SmoothQuant*
Ahora, veamos cómo funciona SmoothQuant cuando se aplica a LLMs populares.
Cuantización de LLMs con SmoothQuant
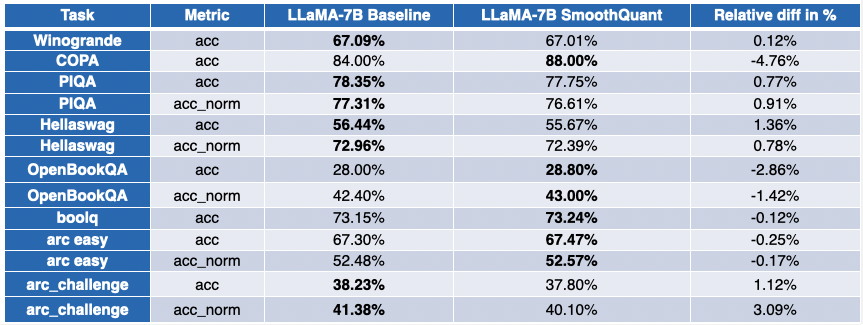
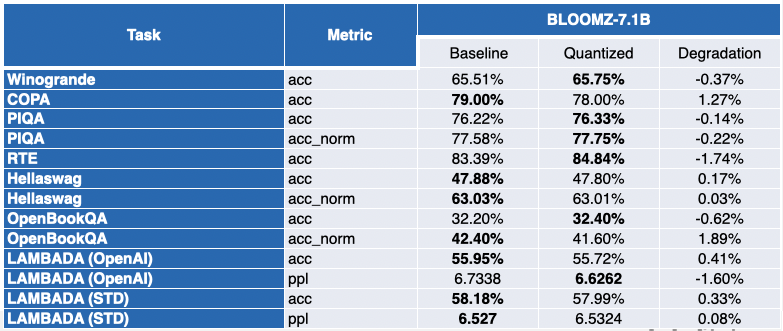
Nuestros amigos de Intel han cuantizado varios LLMs con SmoothQuant-O3: OPT 2.7B y 6.7B [5], LLaMA 7B [6], Alpaca 7B [7], Vicuna 7B [8], BloomZ 7.1B [9] y MPT-7B-chat [10]. También evaluaron la precisión de los modelos cuantizados utilizando Language Model Evaluation Harness.
La tabla a continuación presenta un resumen de sus hallazgos. La segunda columna muestra la proporción de pruebas de referencia que han mejorado después de la cuantización. La tercera columna contiene la degradación promedio media (*un valor negativo indica que la prueba de referencia ha mejorado). Puede encontrar los resultados detallados al final de esta publicación.
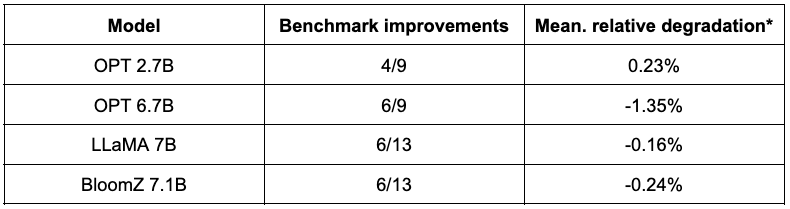
Como puede ver, los modelos OPT son excelentes candidatos para la cuantización SmoothQuant. Los modelos son ~2 veces más pequeños en comparación con los modelos de 16 bits pre-entrenados. La mayoría de las métricas mejoran, y aquellos que no lo hacen solo se ven penalizados marginalmente.
La situación es un poco más contrastada para LLaMA 7B y BloomZ 7.1B. Los modelos se comprimen en un factor de ~2 veces, con aproximadamente la mitad de las tareas que muestran mejoras en las métricas. Nuevamente, la otra mitad se ve afectada marginalmente, con una sola tarea que muestra una degradación relativa de más del 3%.
El beneficio obvio de trabajar con modelos más pequeños es una reducción significativa en la latencia de inferencia. Aquí hay un video que muestra la generación de texto en tiempo real con el modelo MPT-7B-chat en un solo socket Intel Sapphire Rapids CPU con 32 núcleos y un tamaño de lote de 1.
En este ejemplo, le preguntamos al modelo: “*¿Cuál es el papel de Hugging Face en la democratización del NLP?*”. Esto envía el siguiente estímulo al modelo: “Un chat entre un usuario curioso y un asistente de inteligencia artificial. El asistente brinda respuestas útiles, detalladas y educadas a las preguntas del usuario. USUARIO: ¿Cuál es el papel de Hugging Face en la democratización del NLP? ASISTENTE: “
El ejemplo muestra los beneficios adicionales que se pueden obtener de la cuantización de 8 bits combinada con el Xeon de 4ta generación, lo que resulta en un tiempo de generación muy bajo para cada token. Este nivel de rendimiento definitivamente hace posible ejecutar LLM en plataformas de CPU, brindando a los clientes más flexibilidad en TI y un mejor rendimiento de costos que nunca antes.
Experiencia de chat en Xeon
Recientemente, Clement, el CEO de HuggingFace, dijo: “*Más empresas se beneficiarían al centrarse en modelos más pequeños y específicos que son más baratos de entrenar y ejecutar.*” La aparición de modelos relativamente más pequeños como Alpaca, BloomZ y Vicuna abre una nueva oportunidad para las empresas de reducir el costo de ajuste fino e inferencia en producción. Como se muestra arriba, la cuantización de alta calidad brinda experiencias de chat de alta calidad a las plataformas de CPU de Intel, sin necesidad de ejecutar LLM enormes y aceleradores de IA complejos.
Junto con Intel, estamos organizando una nueva demostración emocionante en Spaces llamada Q8-Chat (pronunciado “Cute chat”). Q8-Chat le ofrece una experiencia de chat similar a ChatGPT, mientras se ejecuta solo en un solo socket Intel Sapphire Rapids CPU con 32 núcleos y un tamaño de lote de 1.
Próximos pasos
Actualmente estamos trabajando en la integración de estas nuevas técnicas de cuantización en la biblioteca Hugging Face Optimum Intel a través de Intel Neural Compressor. Una vez que hayamos terminado, podrá replicar estas demostraciones con solo unas pocas líneas de código.
Manténgase atento. ¡El futuro es de 8 bits!
Esta publicación está garantizada 100% libre de ChatGPT.
Agradecimientos
Este blog se realizó en conjunto con Ofir Zafrir, Igor Margulis, Guy Boudoukh y Moshe Wasserblat de Intel Labs. Un agradecimiento especial a ellos por sus excelentes comentarios y colaboración.
Apéndice: resultados detallados
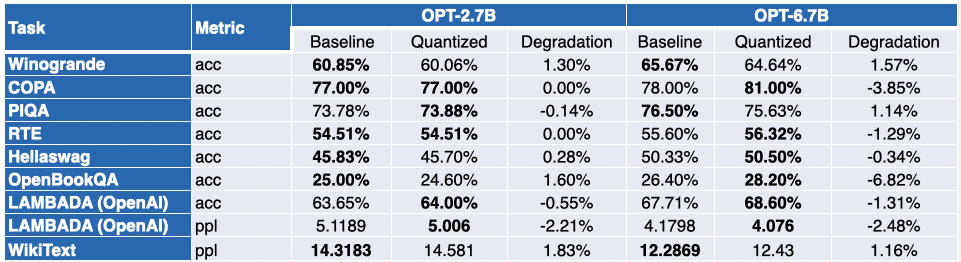
Un valor negativo indica que la prueba de referencia ha mejorado.

We will continue to update Zepes; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Optimizando la Difusión Estable para CPUs de Intel con NNCF y 🤗 Optimum
- Anunciando la Jam de Juegos de Inteligencia Artificial de Código Abierto 🎮
- Reconocimiento de Voz de IA en Unity
- DuckDB analiza más de 50,000 conjuntos de datos almacenados en el Hugging Face Hub
- El Hub de Hugging Face para Galerías, Bibliotecas, Archivos y Museos
- ¿Qué está pasando con el Open LLM Leaderboard?
- Política de IA en @🤗 Respuesta a la solicitud de comentarios de la NTIA de EE.UU. sobre la responsabilidad de la IA






